Automatically replicates data (default, n = 3) • Designed for availability and operational ease • Inspired by architectural principles from Amazon and Akamai • Open source (Apache 2 license) • Key-value model • Features for full-text search, querying metadata and MapReduce
• “Design for failure” architecture “enStratus relies on Riak to ensure that our cloud infrastructure management platform scales seamlessly, without interruption and performance bottlenecks, while meeting and exceeding internal requirements for high availability and data durability.”
the node takes over its share of partitions until data distribution is even again • Does not require manual intervention – data is automatically handed off • Simple stage, preview and commit workflow
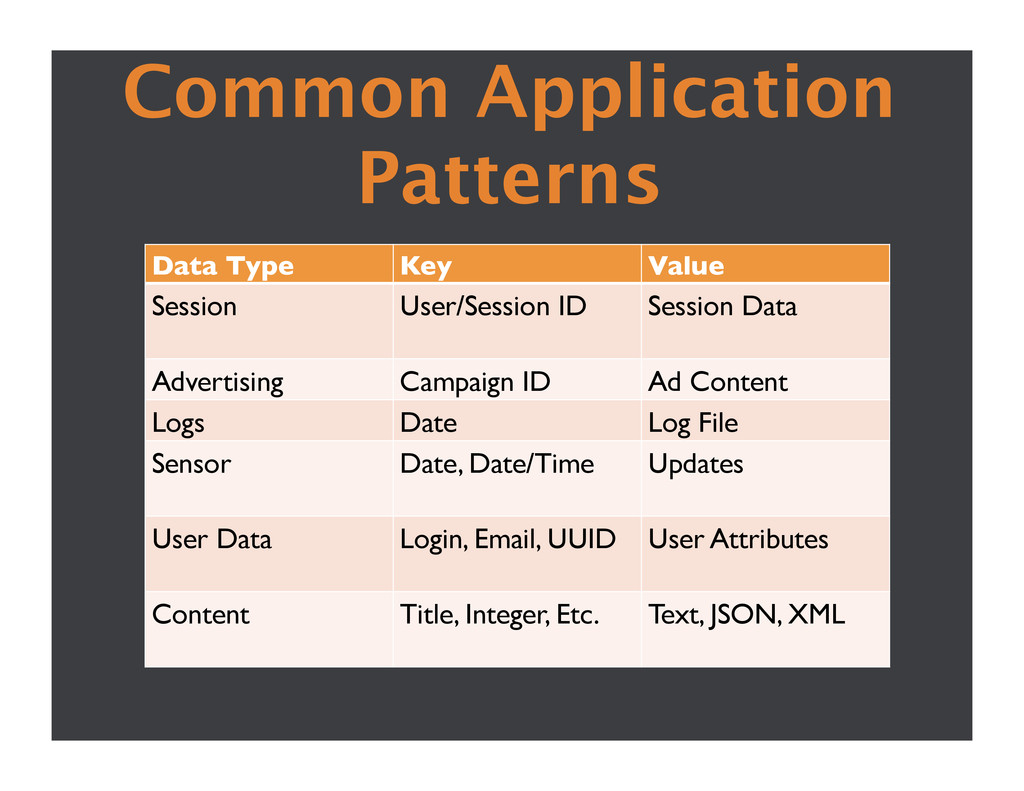
Session Data Advertising Campaign ID Ad Content Logs Date Log File Sensor Date, Date/Time Updates User Data Login, Email, UUID User Attributes Content Title, Integer, Etc. Text, JSON, XML
proportion of requests due to exactly concurrent writes, laggy nodes and certain failure modes • Riak has mechanisms for detecting and resolving data conflicts
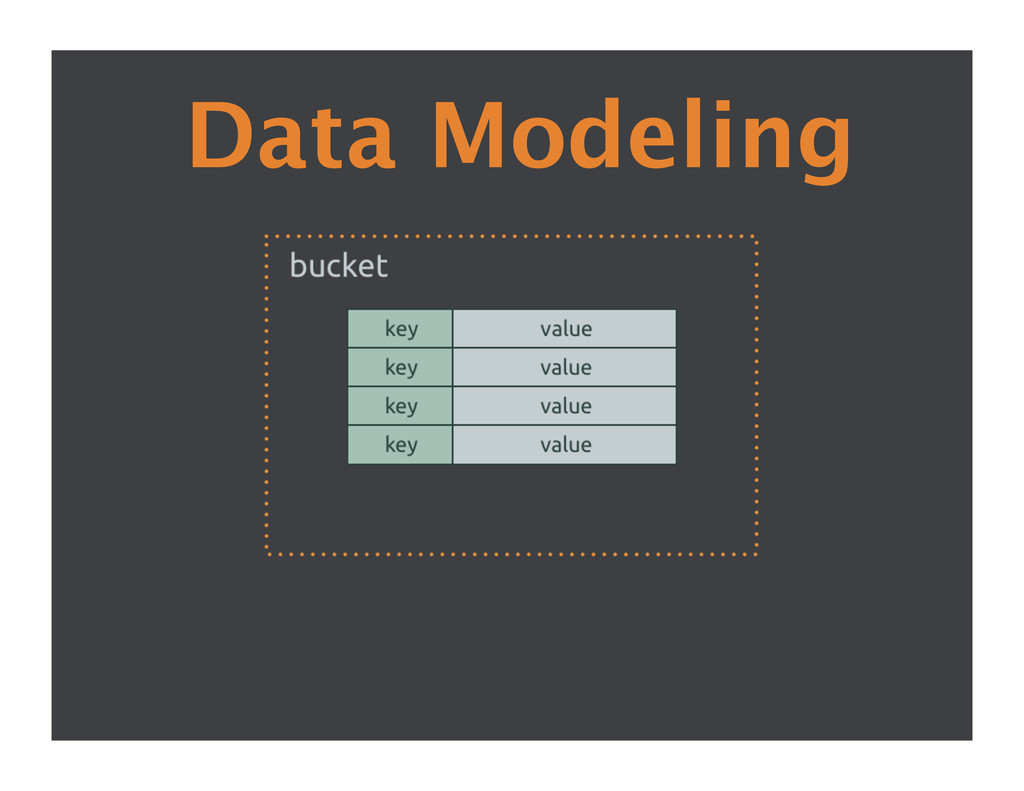
data • Start with 1:1 relationships • Areas that can be modeled as key/value operations • Use Riak client APIs • Docs.basho.com, mailing list or proserv team
{kind=link}
![Shanley Kane Director of Product Management @shanley [email protected]](https://files.speakerdeck.com/presentations/38a7b1d0380d0130a8c822000a8f9a2d/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
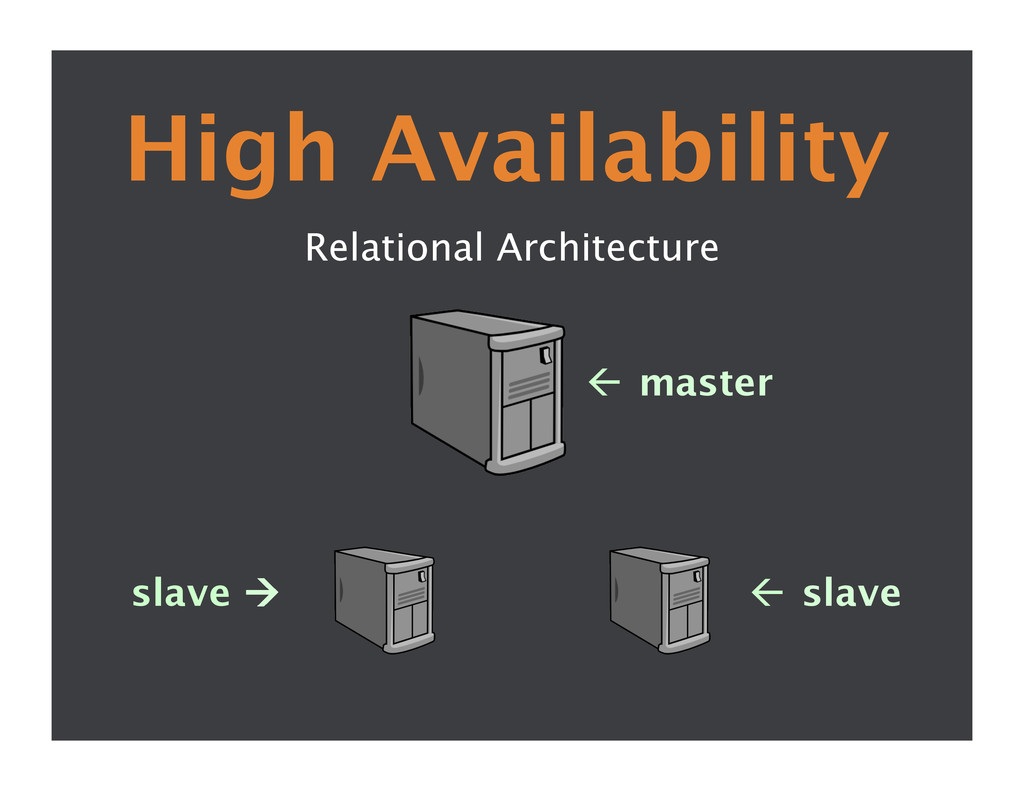{kind=link}
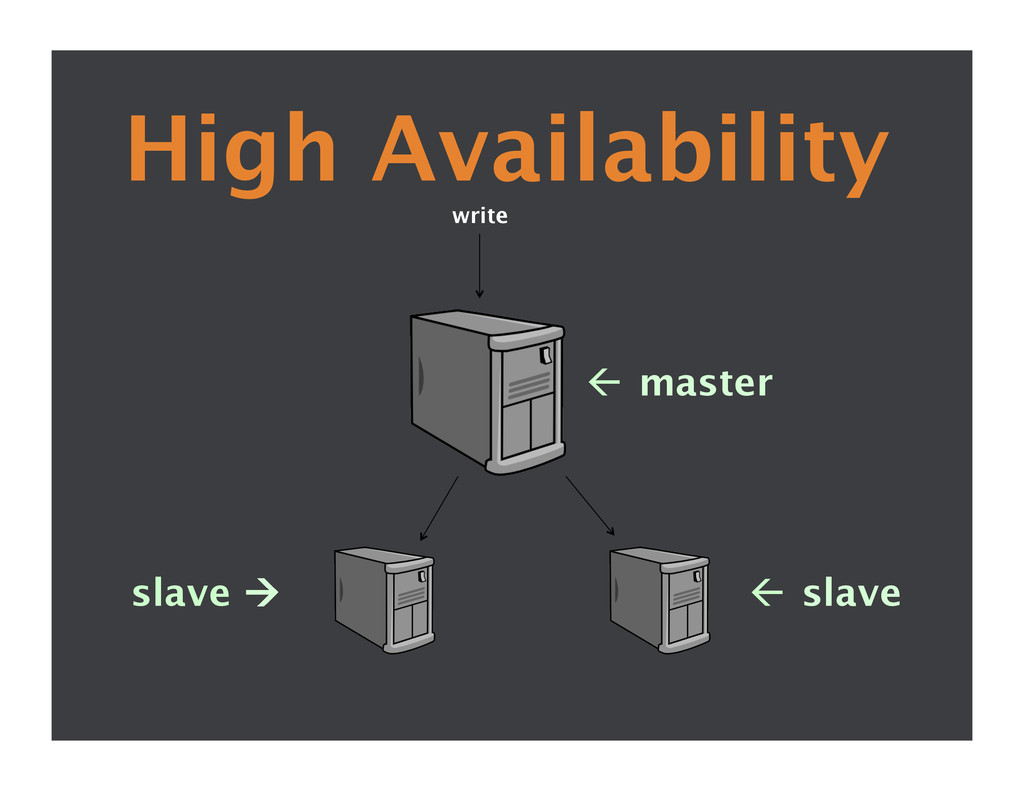{kind=link}
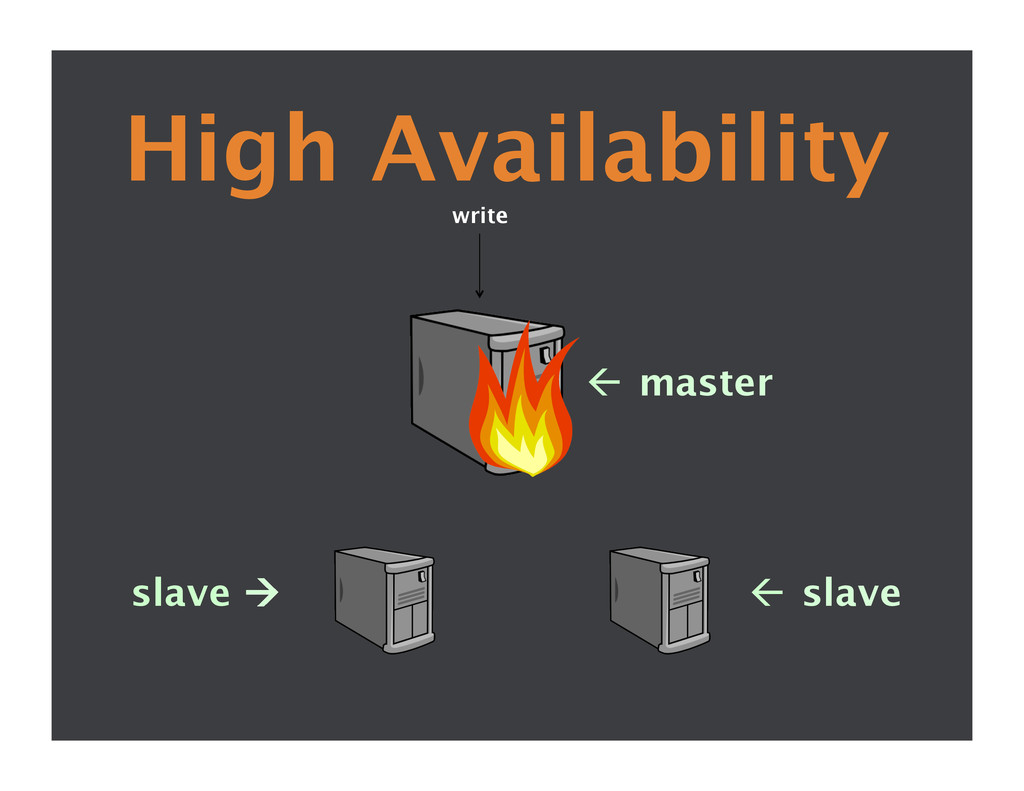{kind=link}
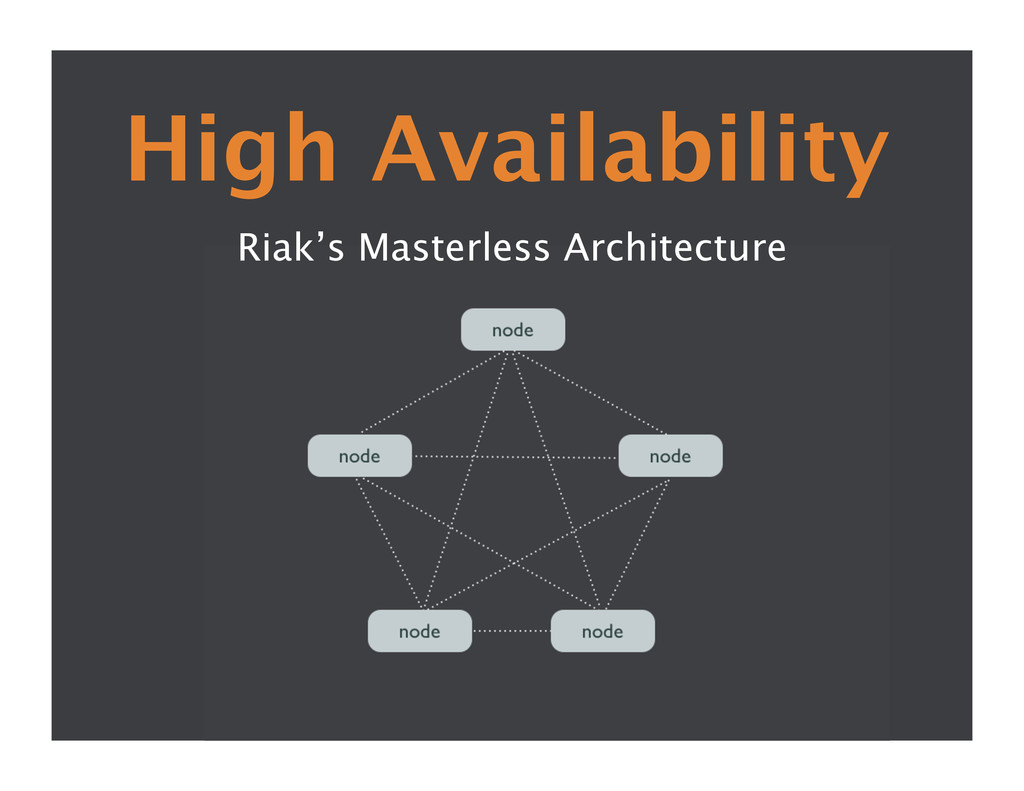{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}