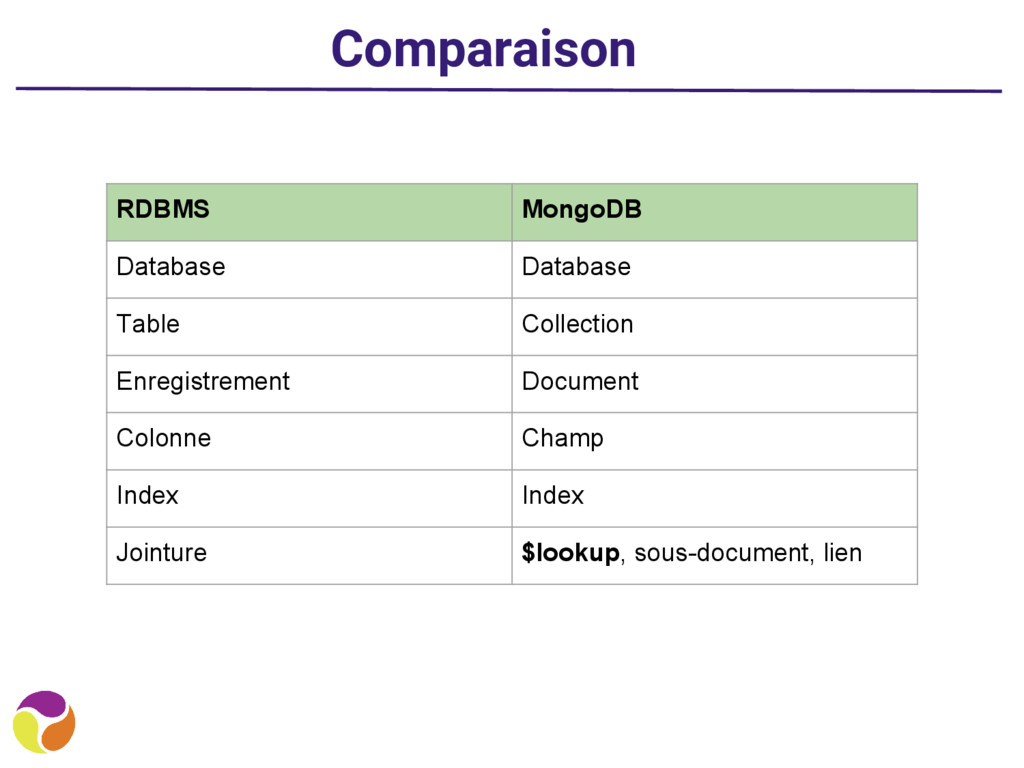
cases, pas de redondance de l’information ◦ C’est beau, c’est carré ! • Mais, attention aux performances lors des recherches sur les disques de l’info dans les différentes tables
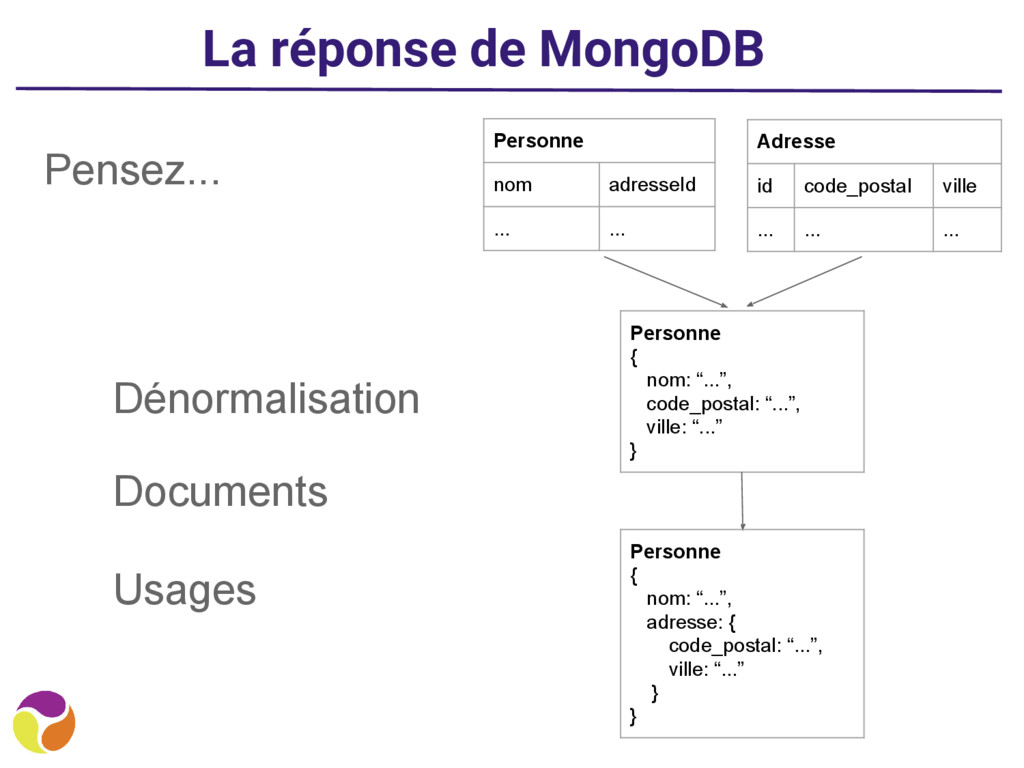
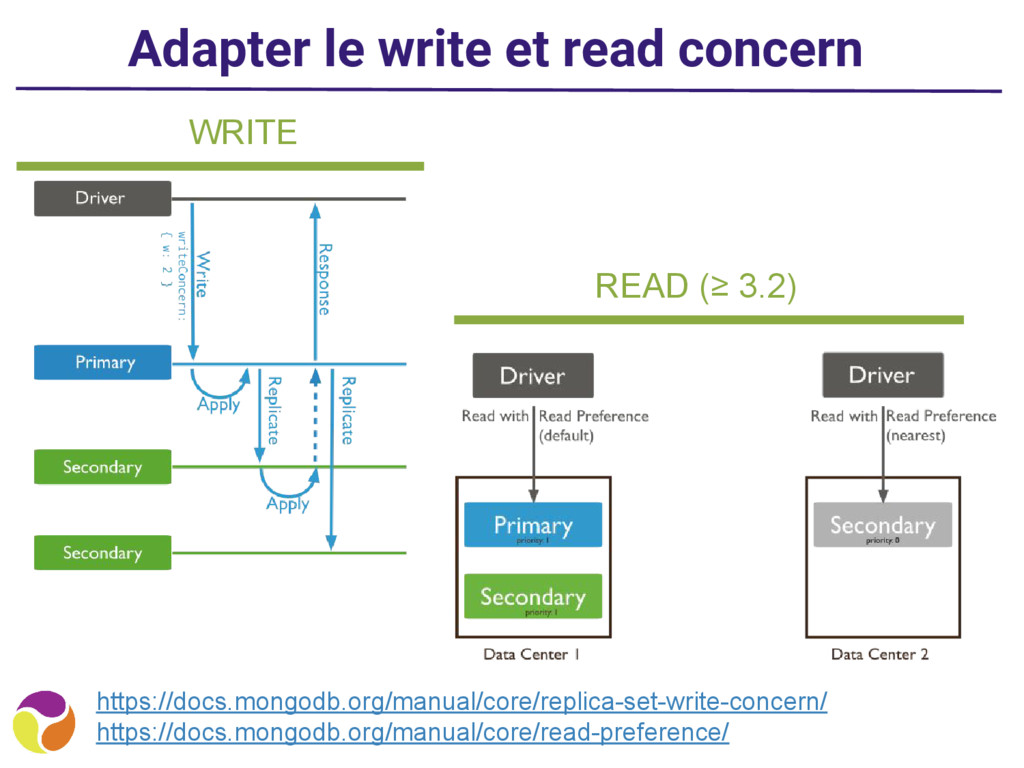
? • locality : stockage de toute l’info au même endroit sur le disque • consistency : comme il n’y pas de transaction, MongoDB assure que l’update d’un doc est atomique
seul doc ? • On peut récupérer plus d’info qu’on n’en a réellement besoin ◦ on peut utiliser les projections dans les queries (ok d’un point de vue réseau), ◦ mais cela n’empêche le document d’ être entirèrement présent en mémoire avant d’être retourné au client
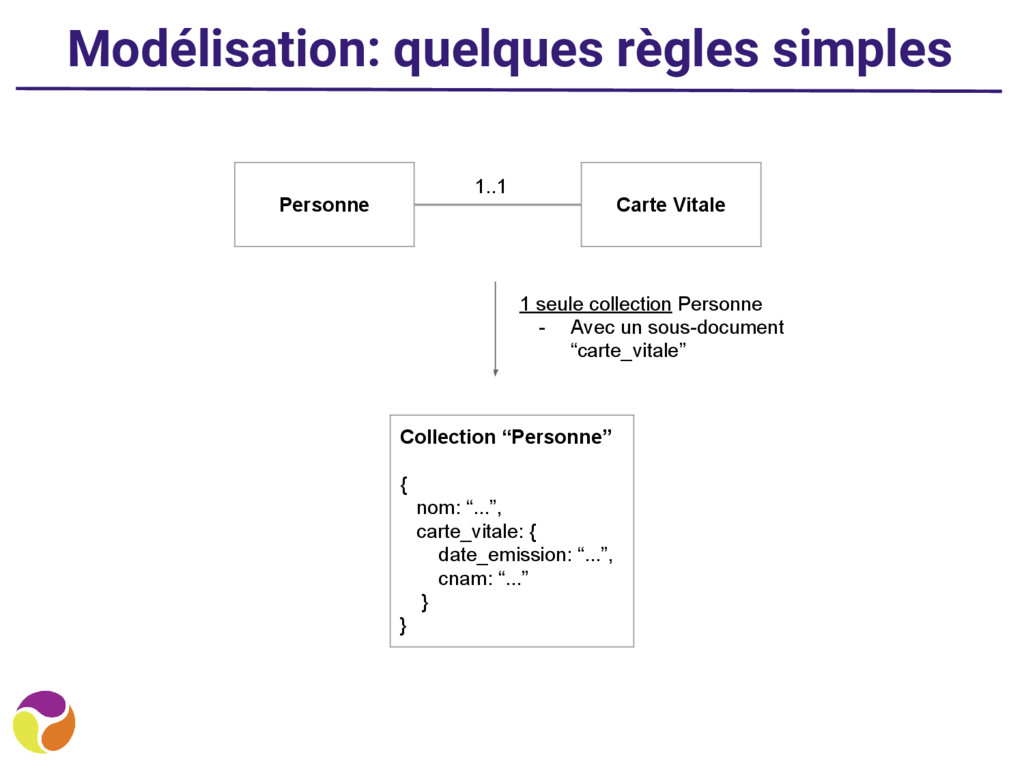
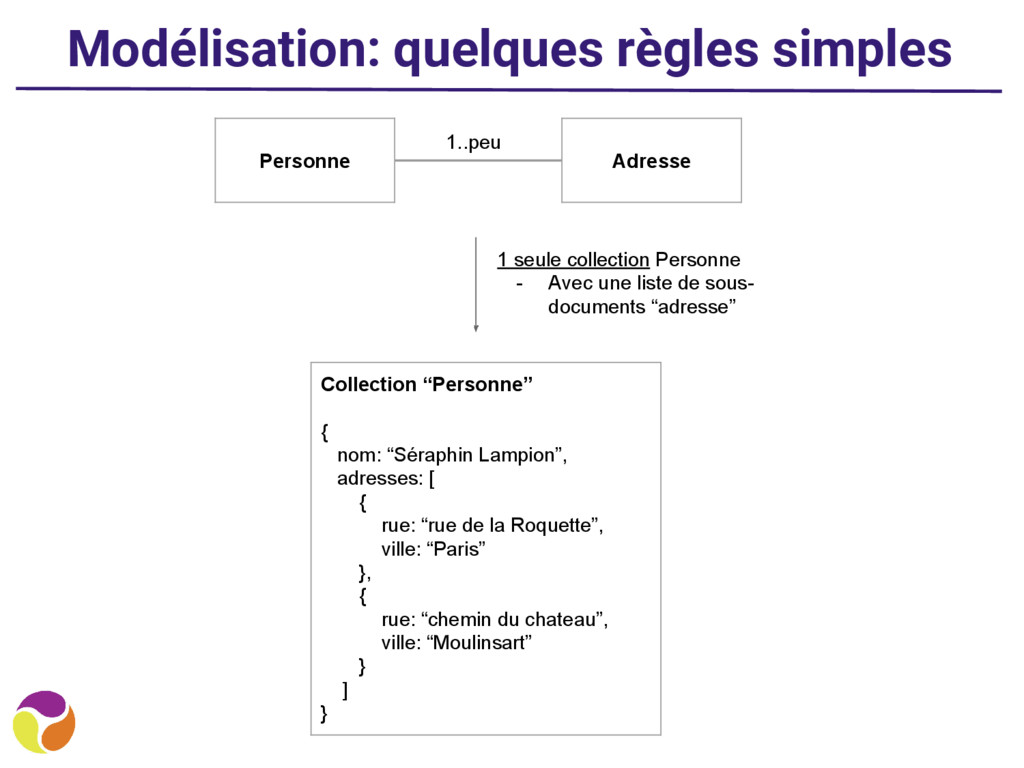
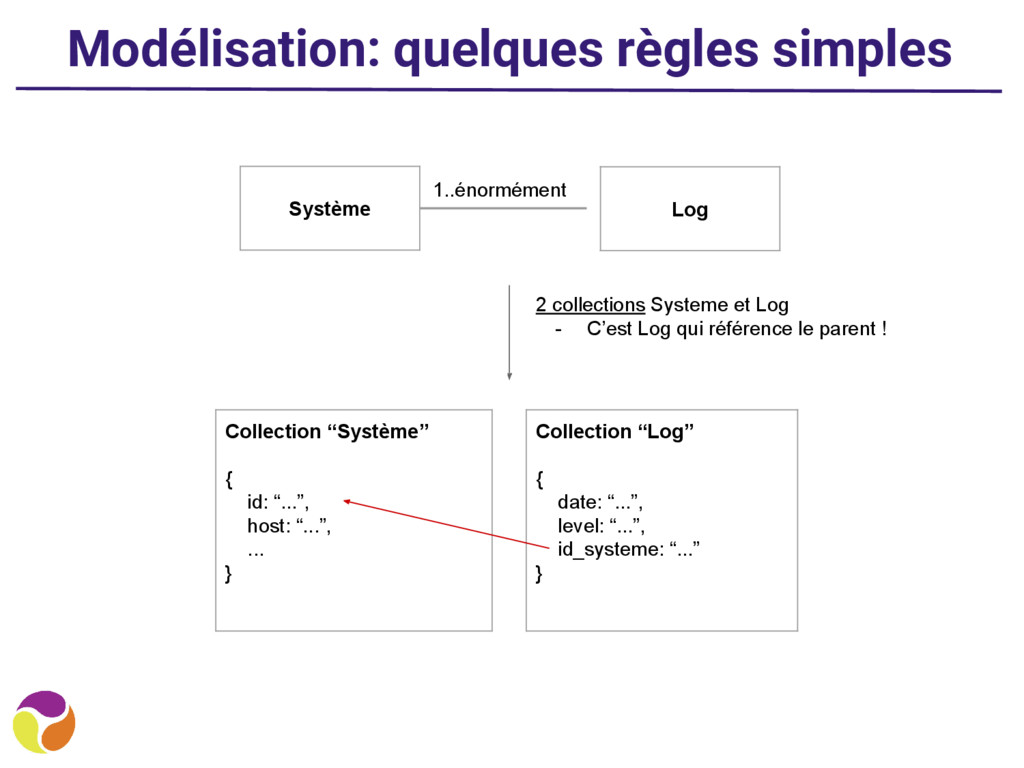
• “J’ai besoin de l’ensemble des données à chaque requête” ◦ Mettez tout dans une seule collection • “J’ai besoin d’en avoir seulement une partie” ◦ Faites plusieurs collections et des références ◦ Ex: les posts d’un blog et leurs commentaires : ▪ 2 besoins : affichage liste des posts + affichage post avec commentaires ▪ Modélisation avec 2 collections (posts, comments)
pour compter collections, documents et indexes ◦ Alias pour aggrégations gcount, gavg, gsum • Toujours nécessaire notamment quand la base n’est pas accessible directement https://github.com/TylerBrock/mongo-hacker
et on ne développe qu’en Java ! • Driver Java ◦ Évolue bien, mais bas niveau • Morphia ◦ Intéressant • Spring Data MongoDB ◦ C’est Spring... • Hibernate OGM ◦ Heu... • Jongo ◦ Fun !
hélas…) // A OUBLIER !!!! DB db = mongoClient.getDB("breizhcamp2016"); DBCollection dbCollection = db.getCollection("conferences"); Iterator<DBObject> confIter = dbCollection.find().iterator(); // Utilisation d’un mapper pour convertir les DBObjects en objets métier MongoDatabase db = mongoClient.getDatabase("breizhcamp2016"); MongoCollection<Document> dbCollection = db.getCollection("conferences"); // Ou en utilisation directe de la classe métier MongoCollection<Conference> dbCollection = db.getCollection("conferences", Conference.class); MongoCursor<Conference> conferences = confCollection.find().iterator(); // Il ne faut pas oublier de déclarer un codec pour la classe Conference
le même package) // Async Database et Collection // MongoDatabase db = client.getDatabase("breizhcamp2016"); MongoCollection<Conference> collection = db.getCollection("conferences", Conference.class); Conference conference = new Conference( "Framework TrucMachinChoseJS et Dockerification de mes microservices", "C'est trop cool !", new Speaker("JsAndDockerAndMicroServicesManiac")); // Insertion d’un élément => il faut fournir une callback // collection.insertOne(conference, (final Void result, final Throwable t) -> { System.out.println("Conference inserée"); });
méthodes findAndXXX permettant d’exécuter des actions de manière atomique FindOneAndUpdateOptions options = new FindOneAndUpdateOptions().returnDocument(ReturnDocument.AFTER); // UpdatedConf contient les données de la conférence suite à la modif Conference updatedConf = confCollection.findOneAndUpdate( new Document(), // Query new Document("$push", new Document("speakerIds", "pad")), // Update options);
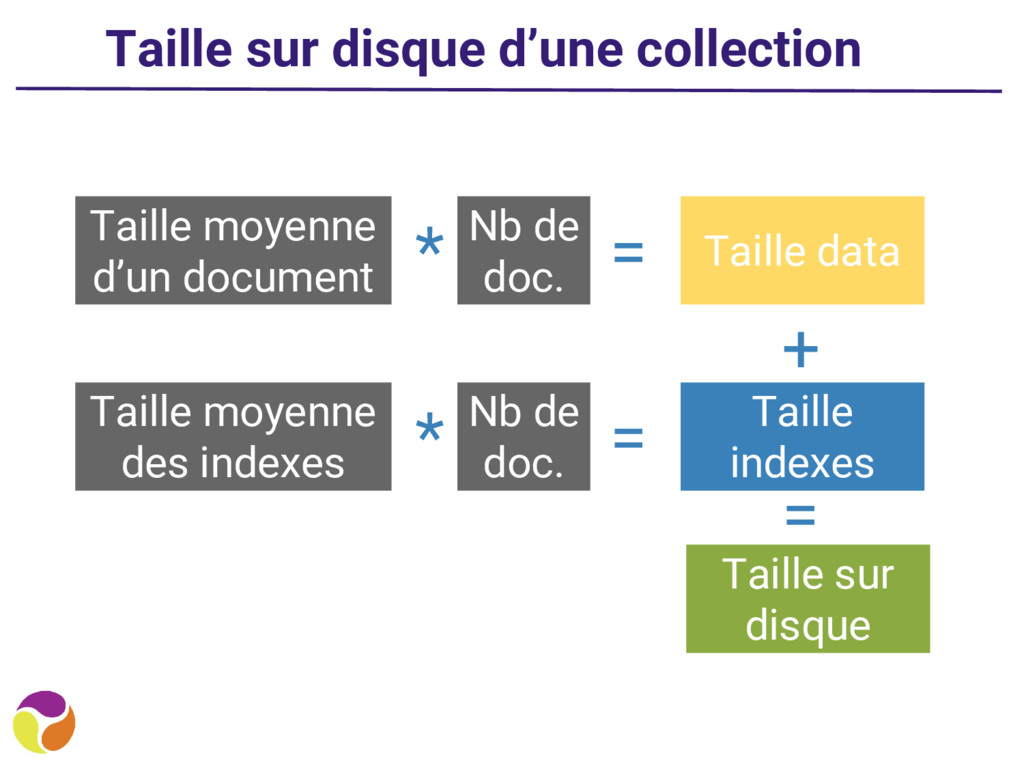
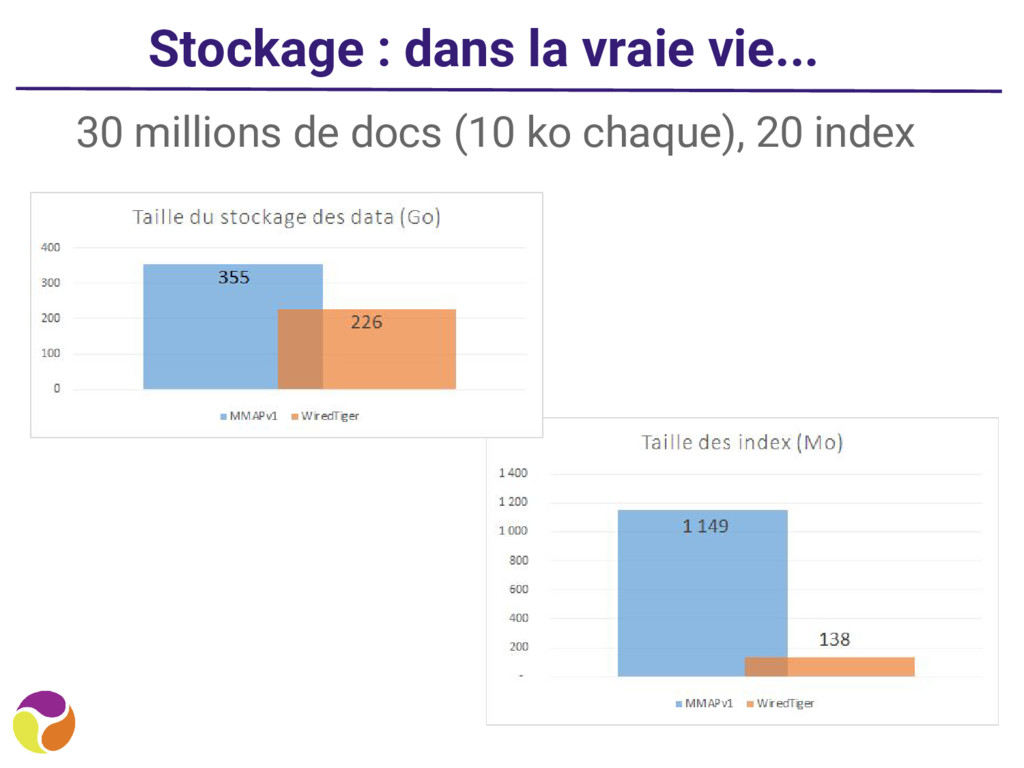
du schéma 2. Extraire les statistiques de taille de chaque collection pour les datas et les index a. taille moyenne des datas b. taille moyenne des indexes 3. Pour chaque collection, estimer un nombre de documents 4. Appliquer un coefficient multiplicateur (un conseil, à cacher le dans une formule d’excel)
Permet de copier depuis MongoDB vers : ◦ ElasticSearch ◦ Solr ◦ Mongodb ◦ Postgresql • Peut permettre de synchroniser une base de préproduction avec la production simplement • Idéal pour des duplications sans transformation https://github.com/mongodb-labs/mongo-connector
plusieurs moteurs de stockage • MMAPv1: présent depuis le début • WiredTiger : depuis la 3.0 et par défaut à partir de la 3.2 • In memory (beta) • Autres futurs moteurs Pour un noeud donné, on ne peut pas changer de type, mais on peut avoir des nodes avec diff. engines
! ➔ Lock au niveau du document (et plus au niveau de la collection) Gain de place: ➔ Support de la compression pour les collections, les index, les journaux ◦ Snappy: par défaut pour les docs et les journaux ▪ 70% de taux de compression, peu de surcoût en CPU ◦ Zlib: meilleure compression (mais surcoût de CPU) Sécurité: ➔ Support du chiffrement au niveau du stockage (uniquement pour MongoDB enterprise)
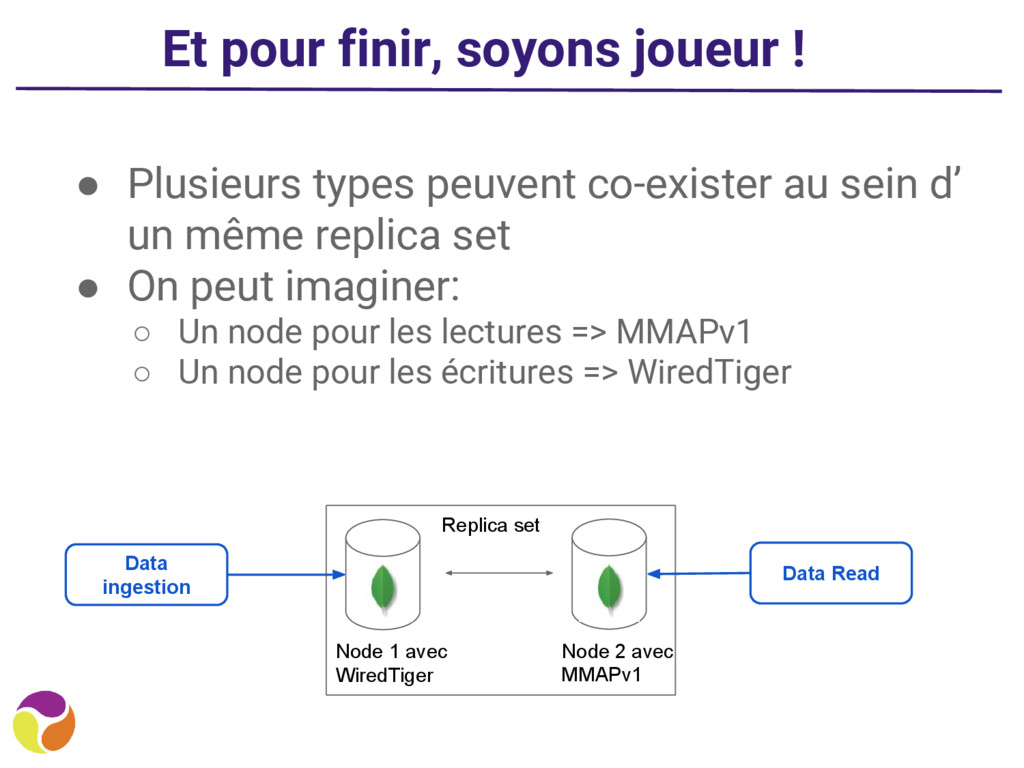
co-exister au sein d’ un même replica set • On peut imaginer: ◦ Un node pour les lectures => MMAPv1 ◦ Un node pour les écritures => WiredTiger Node 1 avec WiredTiger Node 2 avec MMAPv1 Data ingestion Data Read Replica set
la clé de sharding • La lecture sur les secondaires est à éviter tant que possible (orphans) • Limites sur l’aggrégation ◦ pas de join depuis une collection shardée ◦ optimisation largement dépendante des données
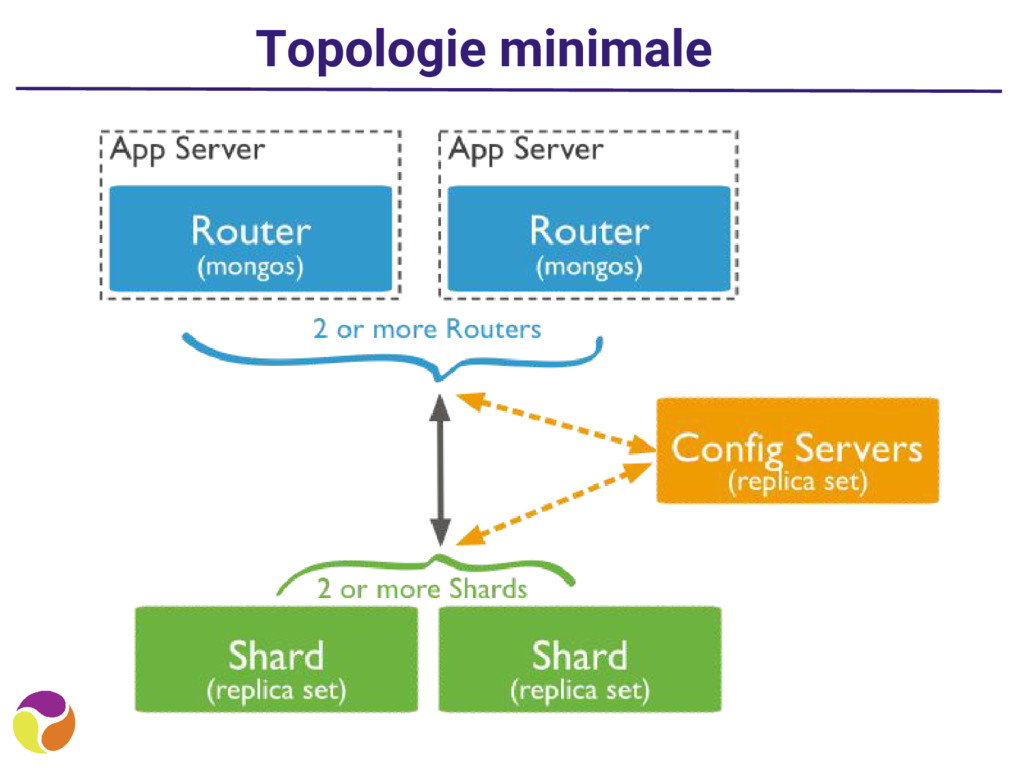
point de salut • Colocaliser les MongoS avec vos applications • N’oubliez pas de sauvegarder les MongoS (pas de reconstruction possible simplement) • Faites vérifier votre architecture par un ami
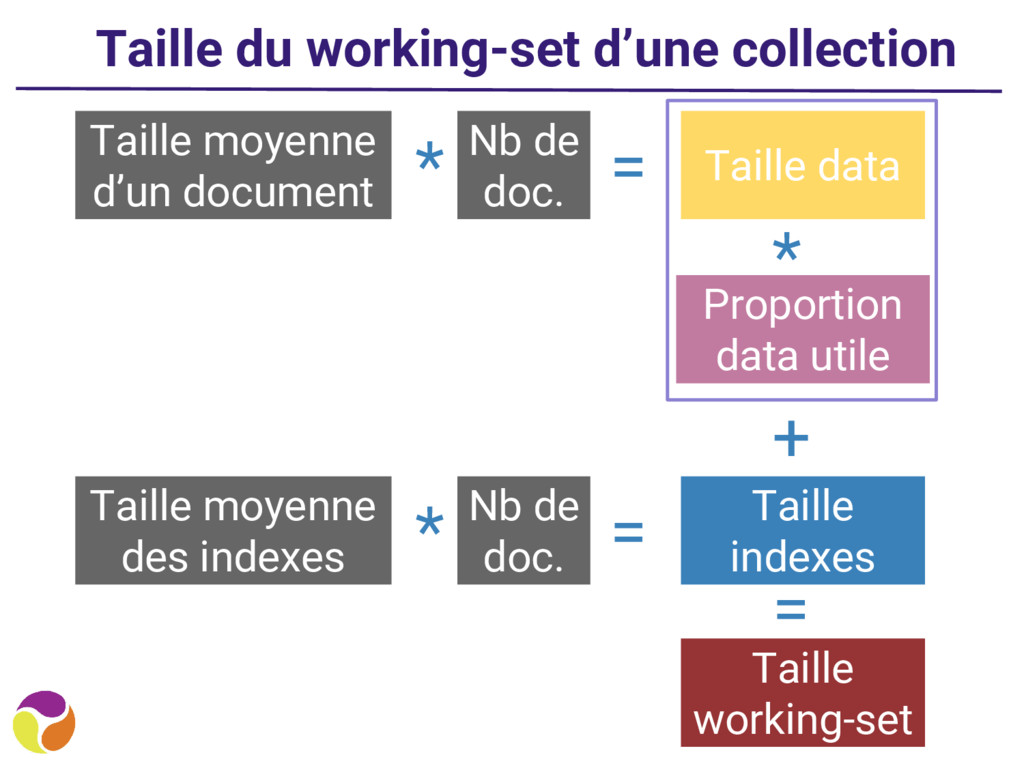
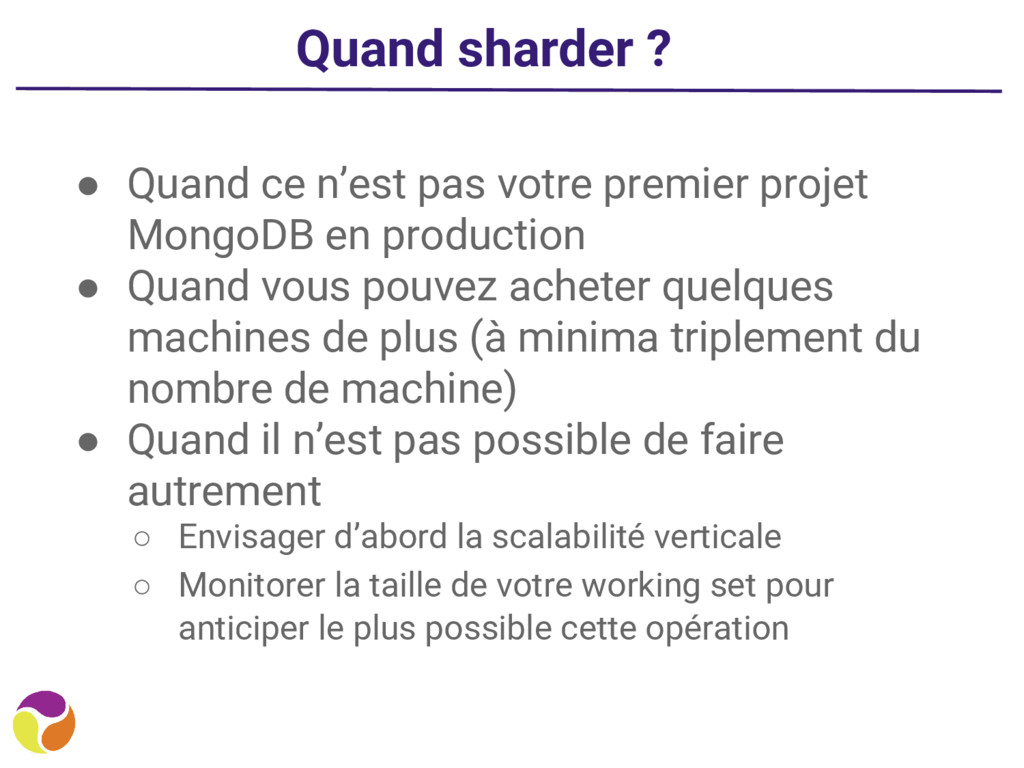
projet MongoDB en production • Quand vous pouvez acheter quelques machines de plus (à minima triplement du nombre de machine) • Quand il n’est pas possible de faire autrement ◦ Envisager d’abord la scalabilité verticale ◦ Monitorer la taille de votre working set pour anticiper le plus possible cette opération
haché • Surveiller les plages de lancement du balancer • Nettoyer régulièrement les orphans • Ne jamais lire sur un secondary si l’ exactitude de la donnée est critique https://docs.mongodb. org/manual/reference/command/cleanupOrphaned/
de connexions réseau • Nombre de fichiers ouverts • Mémoire utilisée Dans le cas d’un replica-set : • Statut dans le replica-set • Présence de fichiers dans le répertoire rollbacks https://docs.mongodb.org/manual/core/replica-set-rollbacks/
Zabbix ◦ Set de graph et d’alarmes préconfigurées ◦ Il faudra mettre les mains dans PHP • Nagios ◦ Nombreux check à ajouter ◦ Accompagné du plugin CACTI il est aisé de se construire une métrologie ◦ Il faudra mettre les mains dans Python • Votre script dans votre langage de prédiletion https://github.com/nightw/mikoomi-zabbix-mongodb-monitoring https://github.com/mzupan/nagios-plugin-mongodb
• Dans le cas d’un replica set utiliser l’option -- oplog à la sauvegarde et la restauration pour backuper un maximum d’ enregistrement • Il est nécessaire d’avoir la place disponible et peut prendre beaucoup de temps
copie des fichiers • Dans le cas de NMAP il est indispensable d’ activer le journal et que celui ci soit présent sur le même volume que les données • Dans le cas d’un replica set préférer la sauvegarde sur le primary ou alors s’assurer que le secondary source de la sauvegarde n’ est pas en retard • Si vous pouvez vous le permettre préférer stopper l’instance
vous avez un oplog couvrant l'intervalle de temps entre une sauvegarde et le moment auquel vous pouvez restaurer il est possible de ne pas perdre de données • Commencer par isoler un membre puis sauvegarder l’oplog • http://www.codepimp.org/2014/08/replay- the-oplog-in-mongodb/ • A tester absolument dans un environnement non cible la première fois
plus simple mais nécessite une souscription • Fonctionne par lecture de l’oplog en continue • Permet le point in time recovery • Disponible dans le cloud ou dans votre réseau • Si auo-herbergé la machine de backup doit être aussi puissante avec encore plus de stockage que vos autres machines
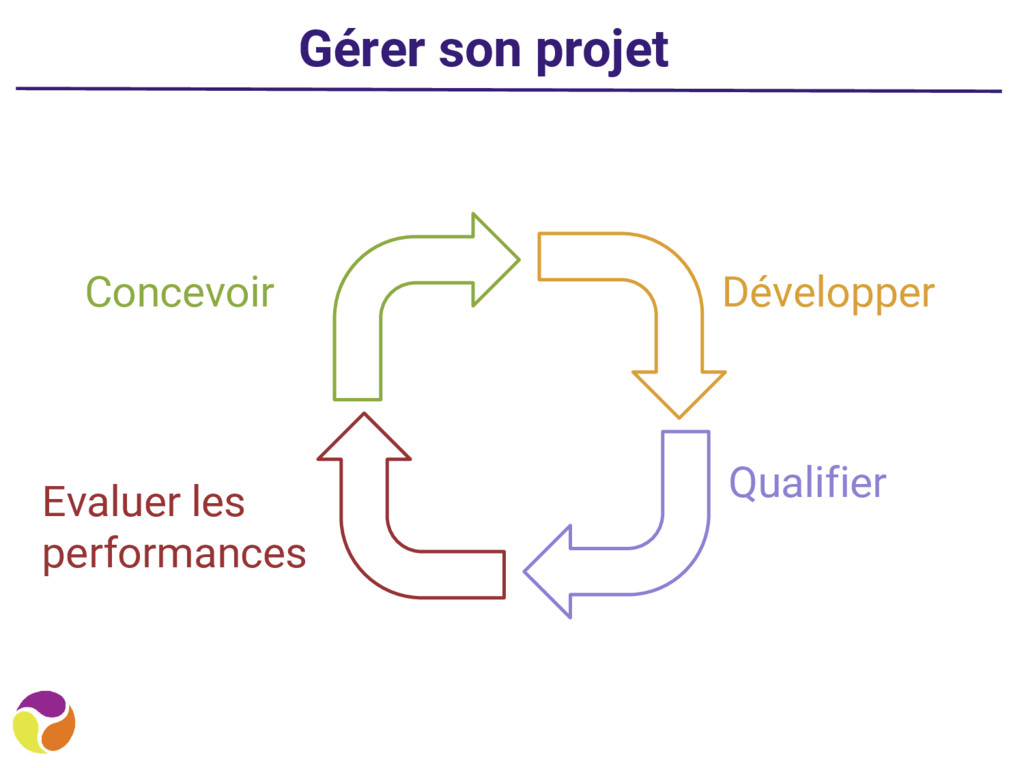
métier ◦ Aux exigences de performance • Pour bien connaitre le besoin, il faut le développer et le tester • Pour savoir si l’application répond aux exigences de performance, il faut la tester • Les tests doivent commencer avec le développement • Pour tester rapidement, il faut déployer rapidement En résumé
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}