Software Engineer at Localytics • Localytics o Real time analytics for mobile applications o 100M+ datapoints a day o More than 2x growth over the past 4 months o Heavy users of Scala, MongoDB and AWS • This Talk o Revised and updated from MongoNYC 2011
o De-duplication of incoming data • Scale today o Hundreds of GBs of data per shard o Thousands of ops per second per shard • History o In production for ~8 months o Increased load 10x in that time o Reduced shard count by more than a half
{u:BinData(0, "..."), k:BinData(0, "def")} After {u:BinData(0, "abc"), c:2} {u:BinData(0, "def"), c:1} • Actually kept data in both forms • Fewer records meant smaller indexes
"...") // prefix of k, indexed s:BinData(0, "...") // suffix of k, not indexed } • Reduced index size • Warning: Prefix must be sufficiently unique • Would be nice to have it built in - SERVER-3260
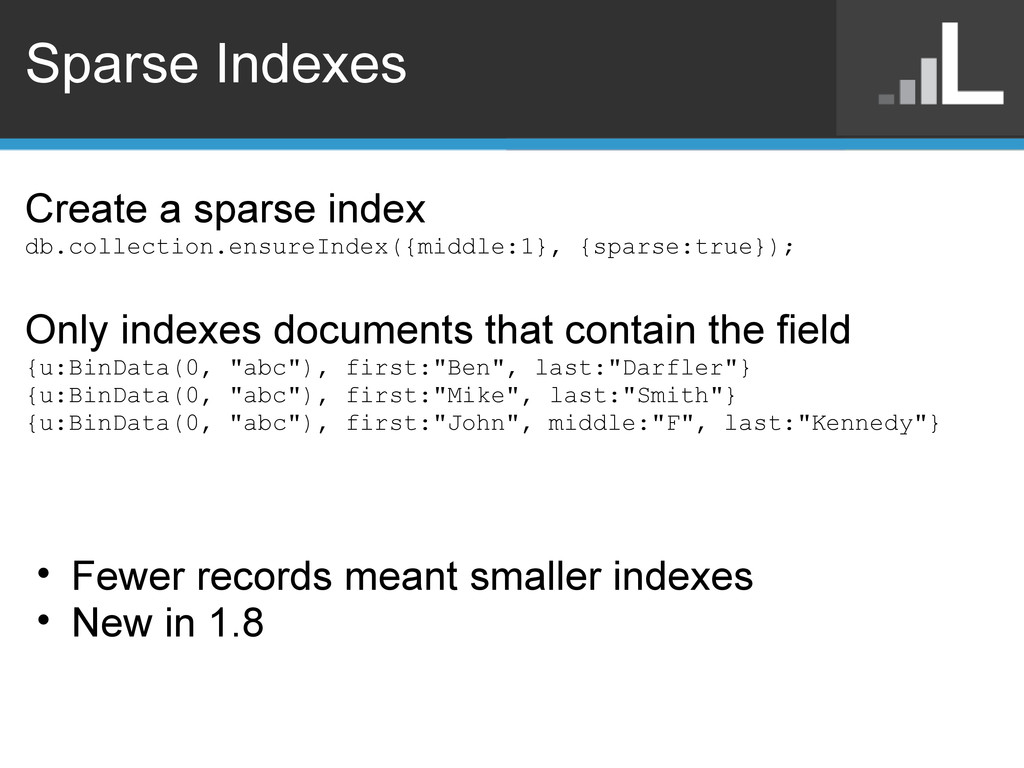
documents that contain the field {u:BinData(0, "abc"), first:"Ben", last:"Darfler"} {u:BinData(0, "abc"), first:"Mike", last:"Smith"} {u:BinData(0, "abc"), first:"John", middle:"F", last:"Kennedy"} • Fewer records meant smaller indexes • New in 1.8
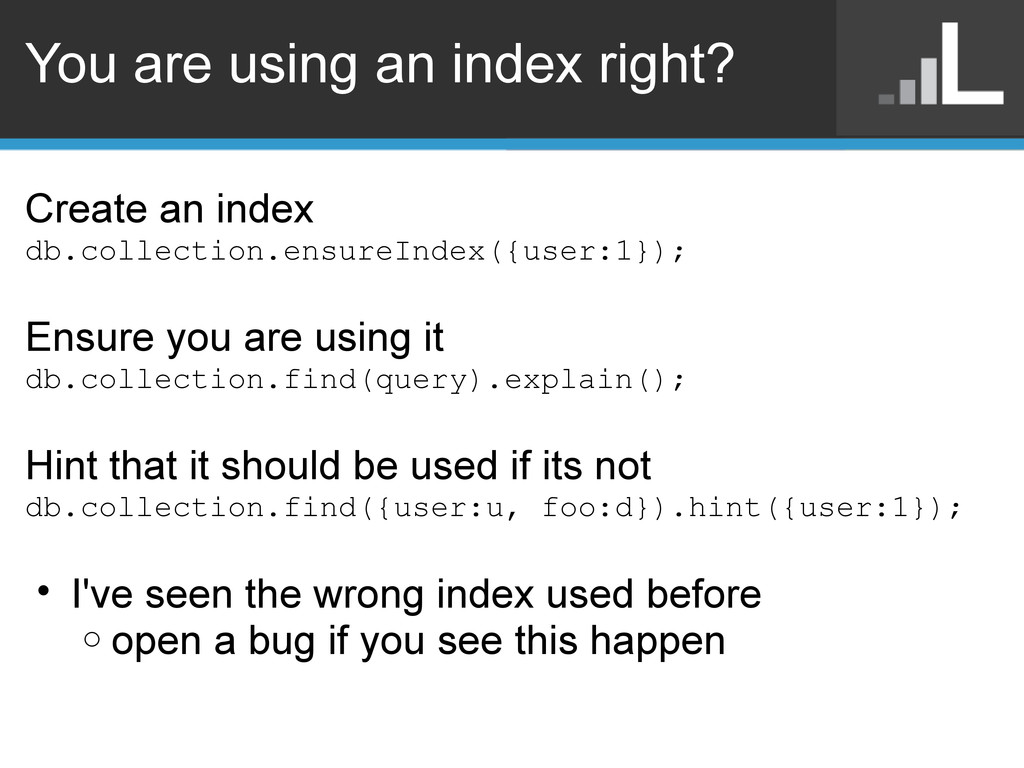
Ensure you are using it db.collection.find(query).explain(); Hint that it should be used if its not db.collection.find({user:u, foo:d}).hint({user:1}); • I've seen the wrong index used before o open a bug if you see this happen
only in the index db.collection.find({last:"Darfler"}, {_id:0, first:1, last:1}); • Can service the query entirely from the index • Eliminates having to read the data extent • Explicitly exclude _id if its not in the index • New in 1.8
{$inc:{c:1}}); • Prevents holding a write lock while paging in data • Most updates fit this pattern anyhow • Less necessary with yield improvements in 2.0
Manual tuning scheduled for 2.2 • Manual Padding o Pad arrays that are known to grow o Pad with a BinData field, then remove it • Free list improvement in 2.0 and scheduled in 2.2
swap with primary o Requires 2x disk space • Compact o db.collection.runCommand( "compact" ); o Run on secondary, swap with primary o Faster than repair o Requires minimal extra disk space o New in 2.0 • Repair, compact and import remove padding
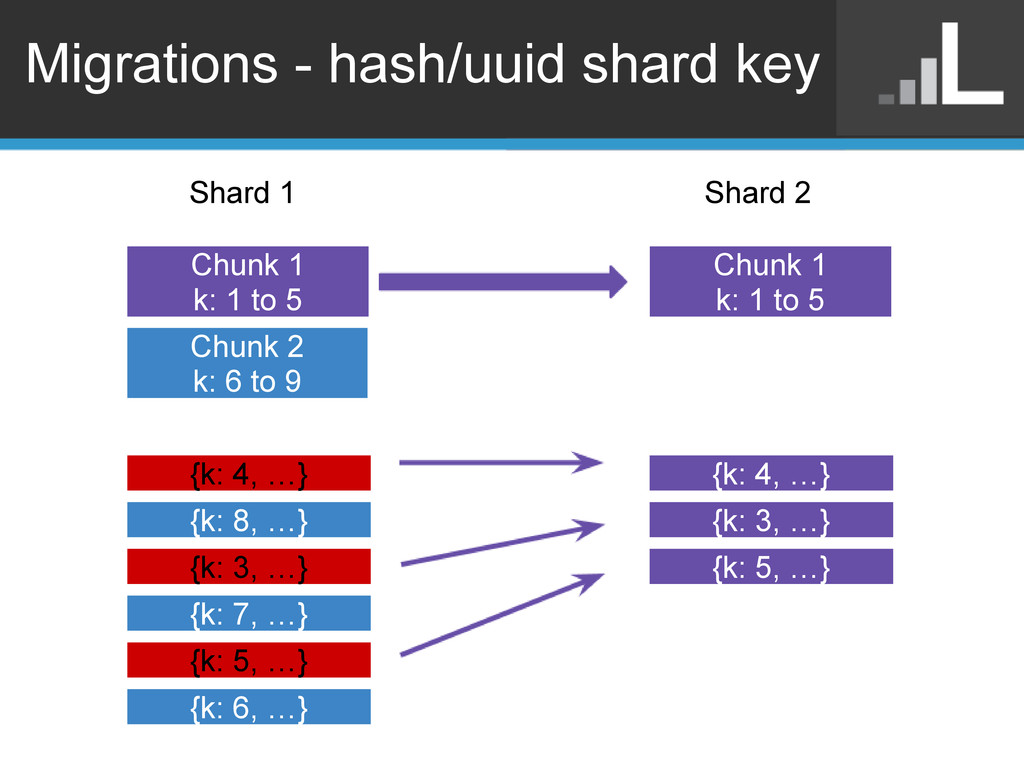
• Migrations cause random I/O and fragmentation o Makes it harder to add new shards • Pre-split o db.runCommand({split:"db.collection", middle:{_id:99}}); • Pre-move o db.adminCommand({moveChunk:"db.collection", find:{_id:5}, to:"s2"}); • Turn off balancer o db.settings.update({_id:"balancer"}, {$set:{stopped:true}}, true});
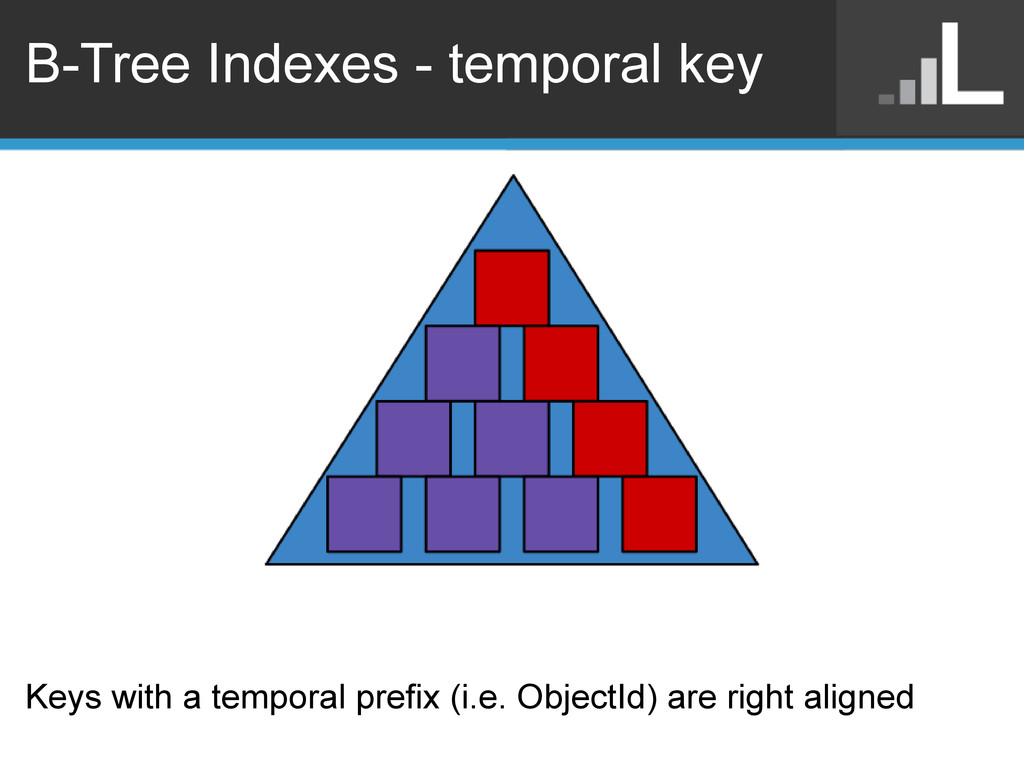
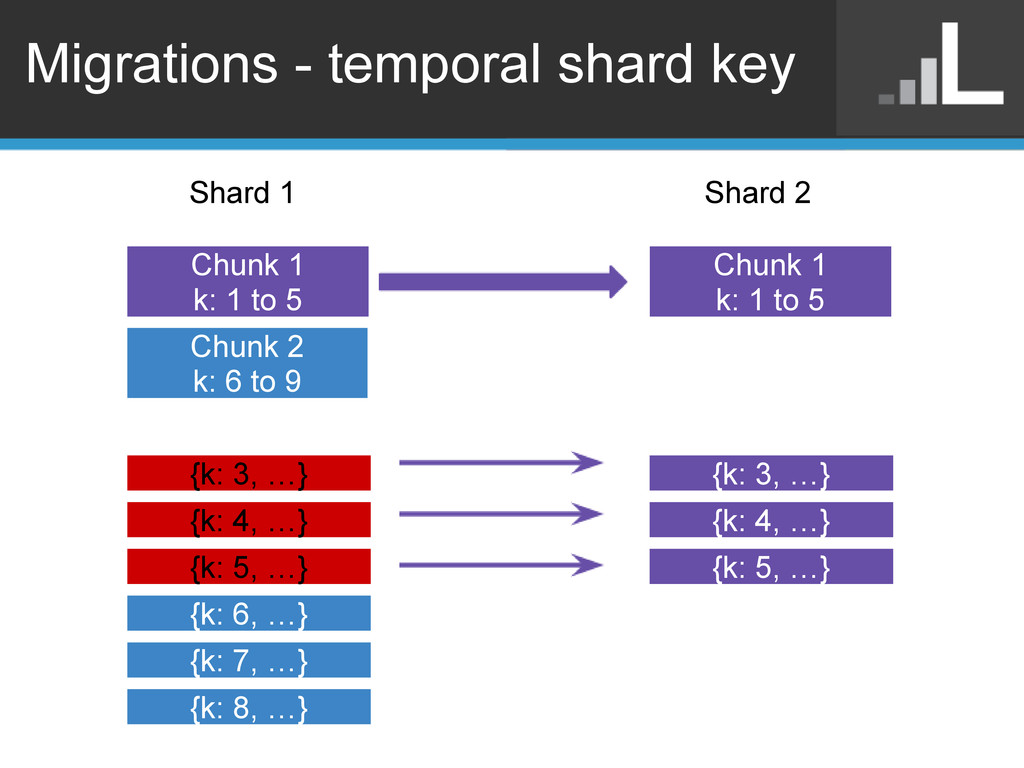
are less destructive o Makes it easier to add new shards • Include a temporal prefix in your shard key o {day: ..., id: ...} • Choose prefix granularity based on insert rate o low 100s of chunks (64MB) per "unit" of prefix o i.e. 10 GB per day => ~150 chunks per day
only use 1TB disks • RAID'ed our disks o Minimum of 4-8 disks o Recommended 8-16 disks o RAID0 for write heavy workload o RAID10 for read heavy workload
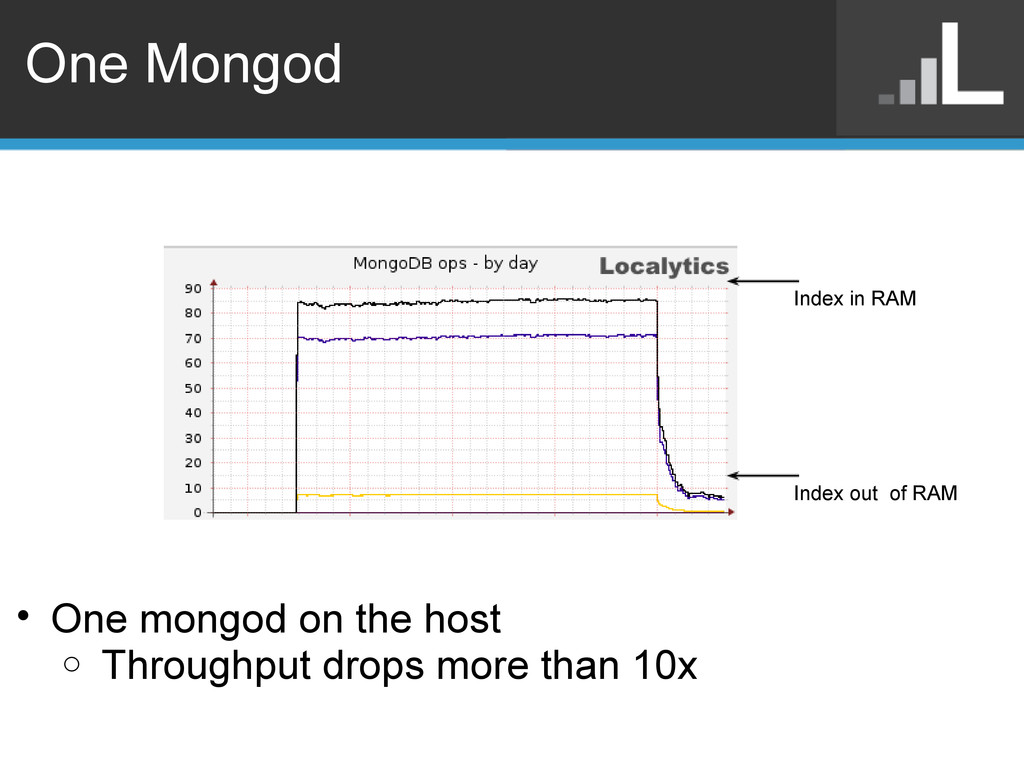
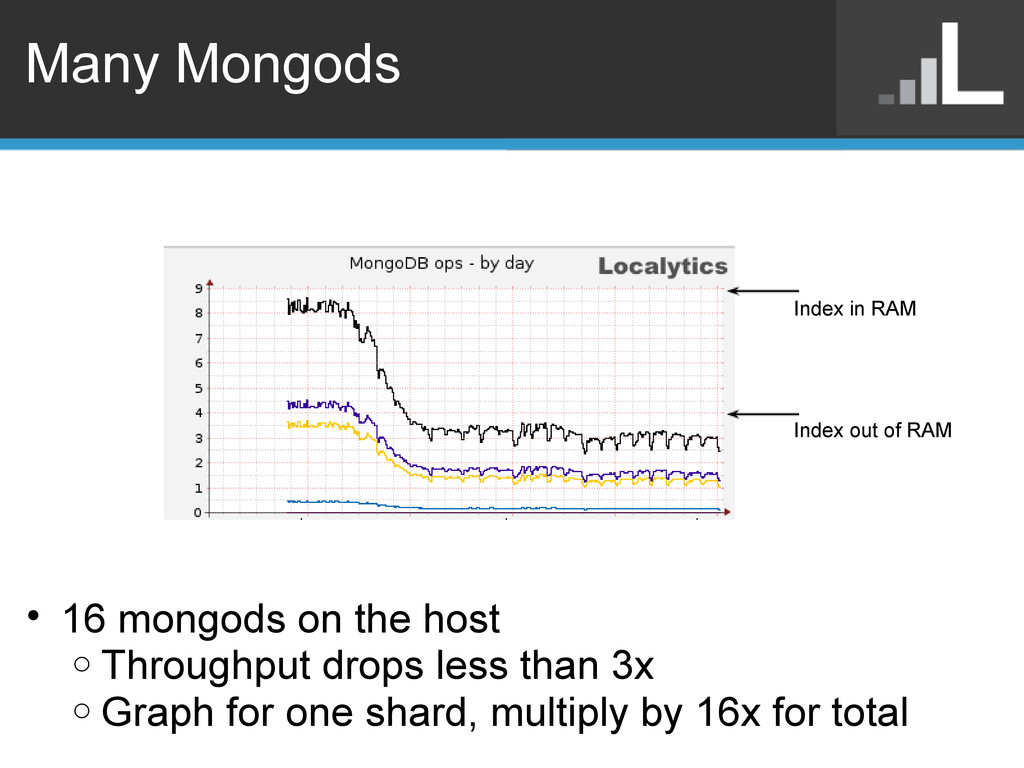
o Ticket for lock per collection - SERVER-1240 o Ticket for lock per extent - SERVER-1241 • For in memory work load o Shard per core • For out of memory work load o Shard per disk • Warning: Must have shard key in every query o Otherwise scatter gather across all shards o Requires manually managing secondary keys • Less necessary in 2.0 with yield improvements
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}