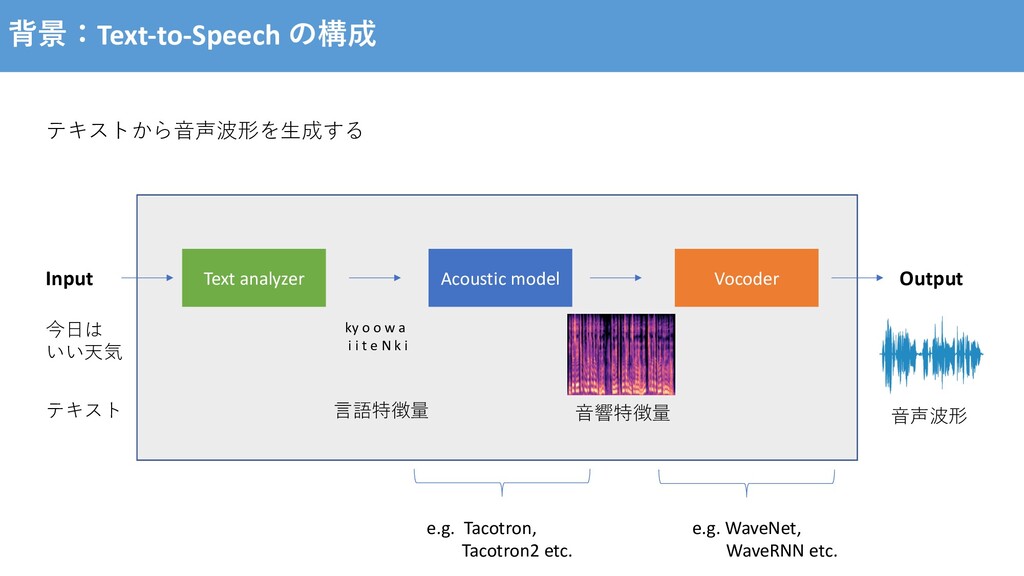
for Expressive Speech Synthesis with Tacotron https://arxiv.org/pdf/1803.09047.pdf Prosodyに関連する⾳響的な要因 - ピッチ - ⾳声の⻑さ - ラウドネス - 声質 イントネーション、強勢、リズム、話し⽅ [RJ Skerry-Ryan et al., 2018] “The prosody of language covers all aspects of speech that are not related directly to the articulation for the linguistic expression” [T. Raitio et al., 2020]
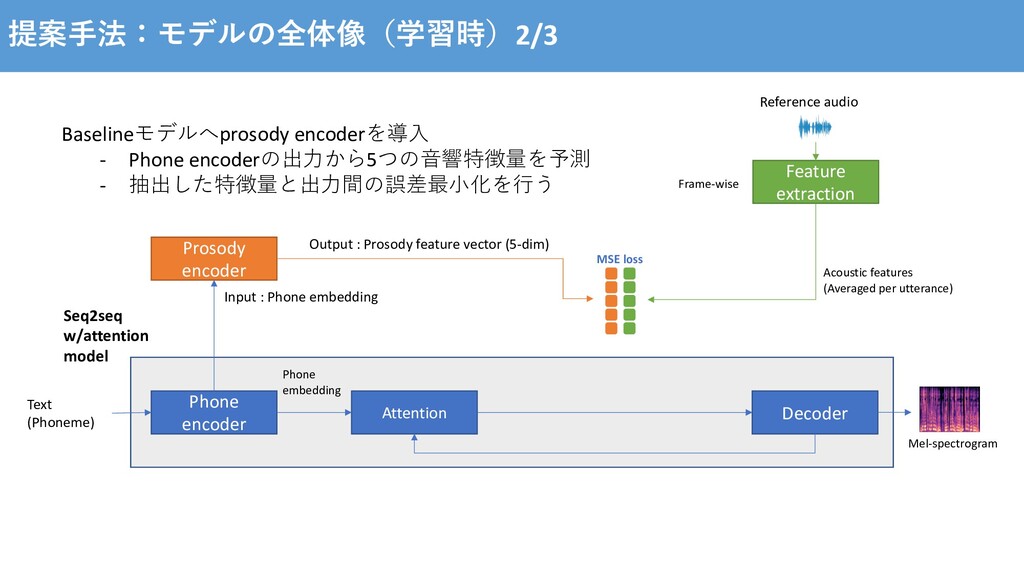
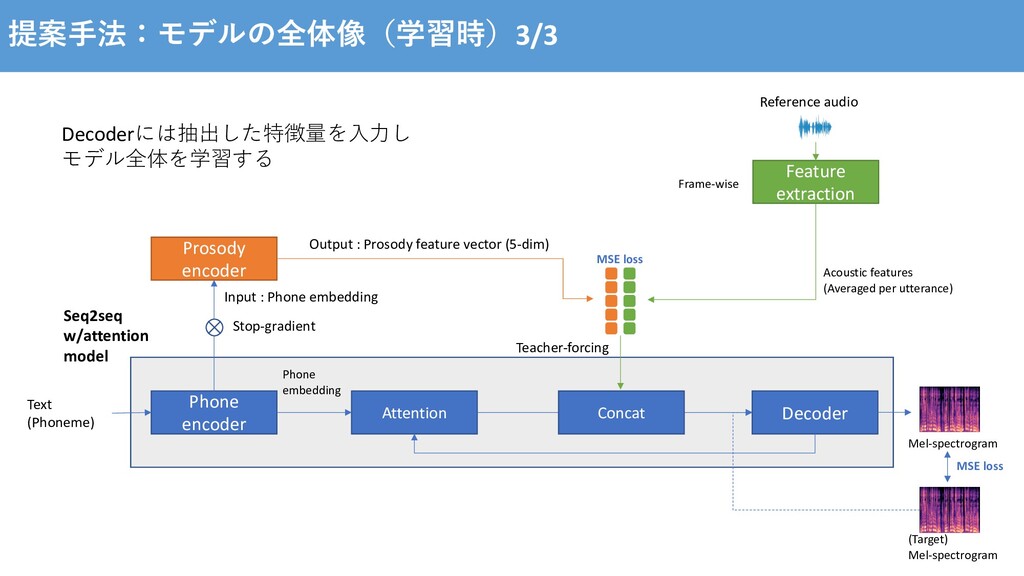
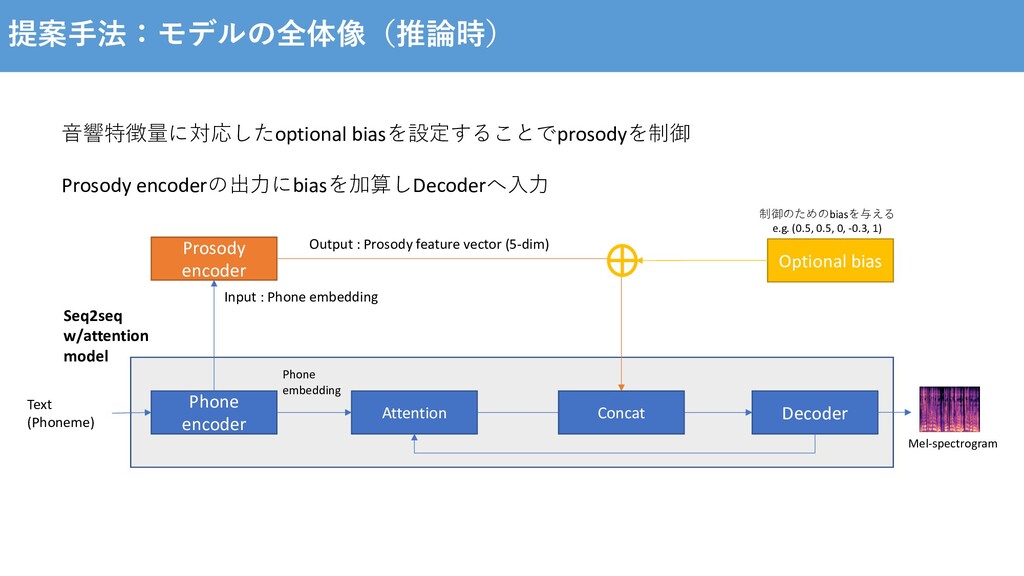
⽣成された⾳声のprosodyは、学習データの平均に近づいてしまう - ⼊⼒した⽂章でprosodyが決まるので、同じ⽂章で異なったprosodyの⾳声を出⼒できない Prosody modelingに関する研究 - Tacotron GST [Y. Wang et al., 2018] - Global Style Token (GST) と呼ばれるprosodyの潜在空間をラベルなしで学習 - GSTから話者のスタイルの埋め込みベクトルを⽣成し、Tacotronを条件付け - 参照する⾳声のスタイルを転移させたり、重みの変更でスタイルの制御が可能に [Y. Wang et al., 2017] Tacotron: Towards end-to-end speech synthesis https://arxiv.org/pdf/1703.10135.pdf [Y. Wang et al., 2018] Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis https://arxiv.org/pdf/1803.09047.pdf
al., 2018], [RJ Skerry-Ryan et al., 2018] Pros - Prosodyに関する情報をラベルなしで学習できる Cons - prosody以外の⾳響的要因も含めて学習してしまう(e.g. 録⾳環境) - どのstyle tokenを使うか、所望のスタイルが学習されているのか⼈が聞かないと分からない [Y. Wang et al., 2018] Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis https://arxiv.org/pdf/1803.09047.pdf [RJ Skerry-Ryan et al., 2018] Towards End-to-End Prosody Transfer for Expressive Speech Synthesis with Tacotron https://arxiv.org/pdf/1803.09047.pdf Prosodyに関する⾳響特徴量を⽤いたsupervised methodを提案 より直感的な制御を可能に
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![背景:Prosodyとは [RJ Skerry-Ryan et al., 2018] Towards End-to-End Prosody Transfer](https://files.speakerdeck.com/presentations/2016fa7384b44123af3dacdef28986bf/slide_4.jpg){kind=link}
{kind=link}
![背景:課題 近年のE2E⾳声合成システムの課題 (e.g. Tacotron [Y. Wang et al., 2017]) -](https://files.speakerdeck.com/presentations/2016fa7384b44123af3dacdef28986bf/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
![提案⼿法:ベースライン Baseline [S. Achanta et al., 2020] Acoustic model -](https://files.speakerdeck.com/presentations/2016fa7384b44123af3dacdef28986bf/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
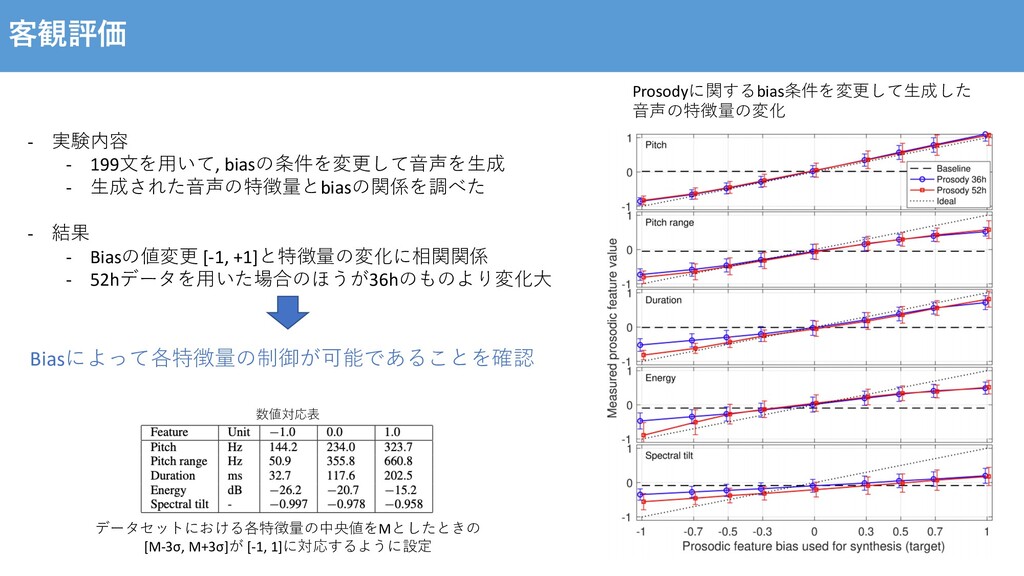{kind=link}
{kind=link}
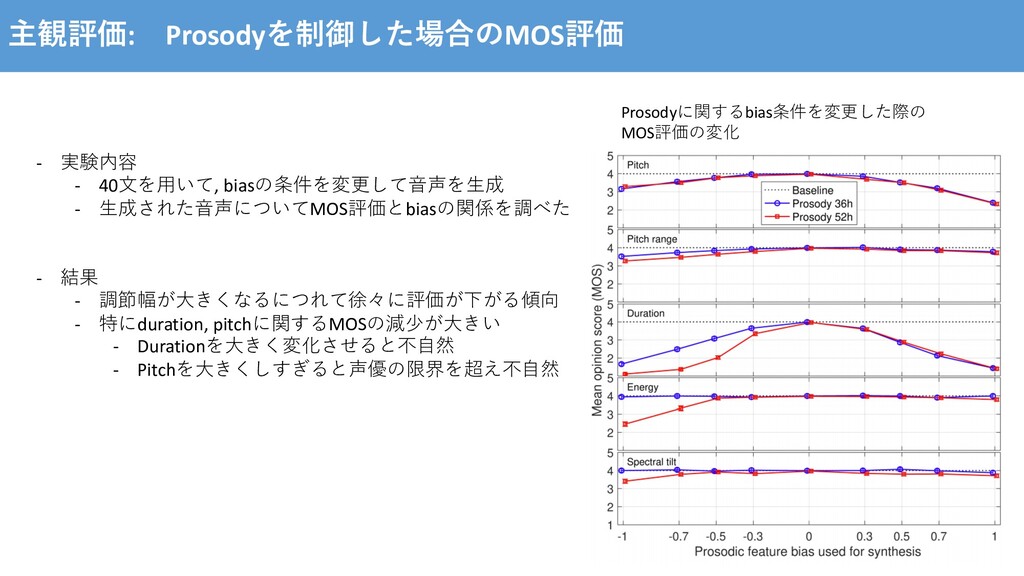{kind=link}
{kind=link}
{kind=link}