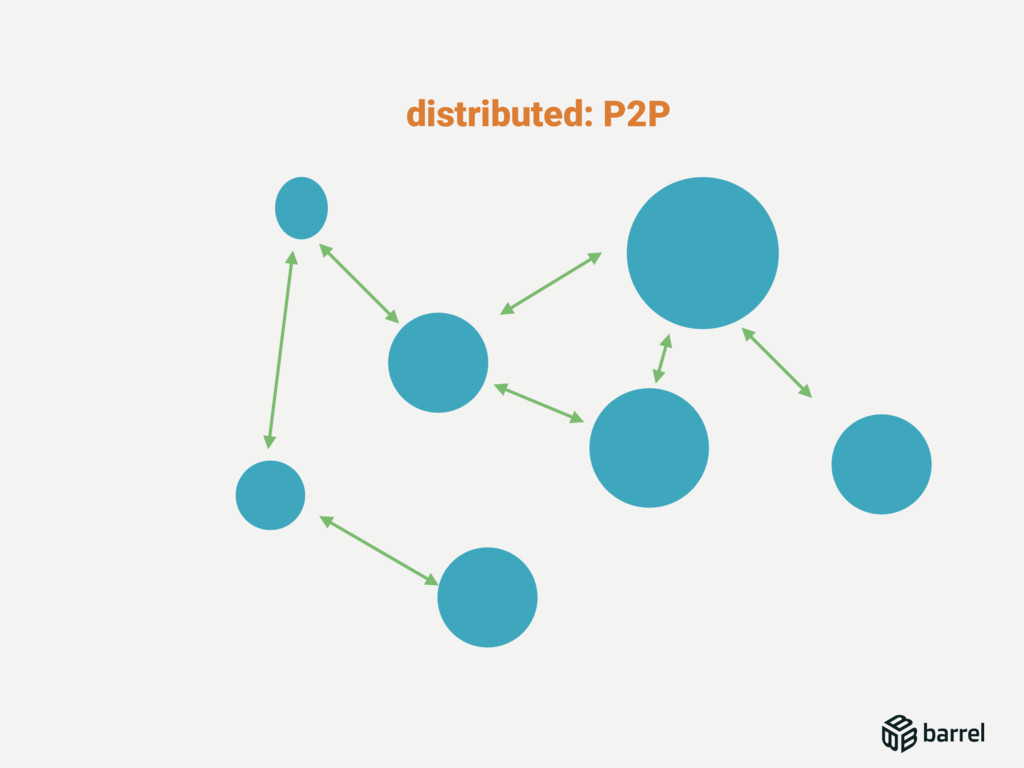
Last year I presented a preliminary version of Barrel, 7 months later the first stable version was available for all. Barrel is a modern document-oriented database with master-master replication targeting micro-services with a RESTful API written in Erlang.
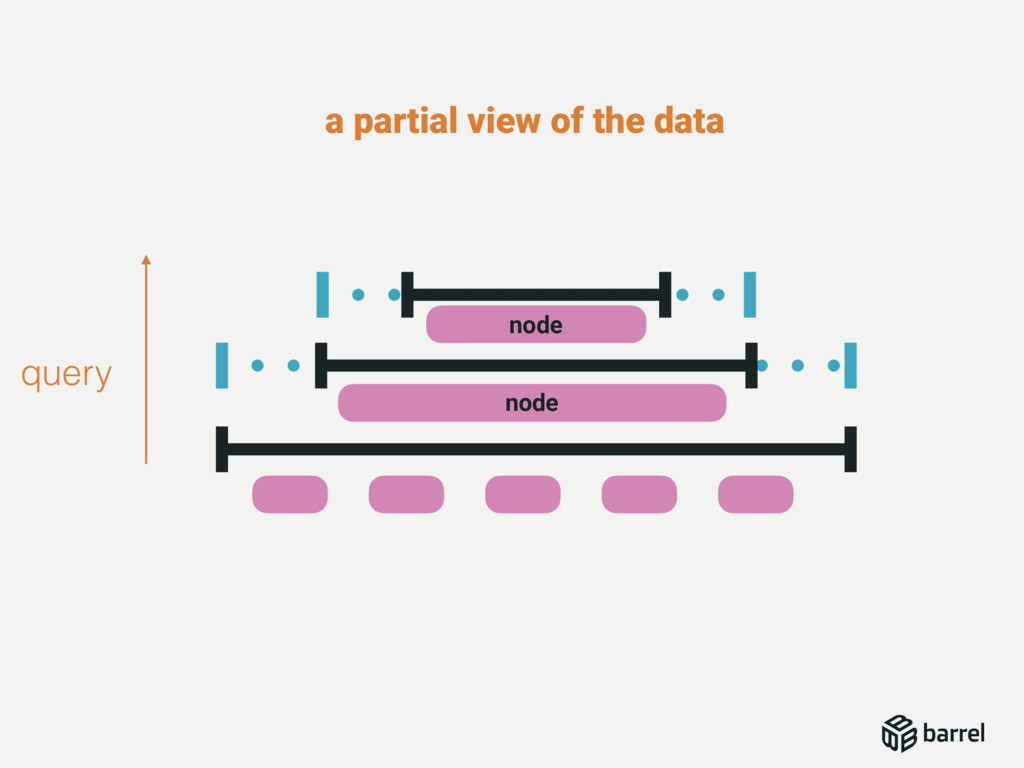
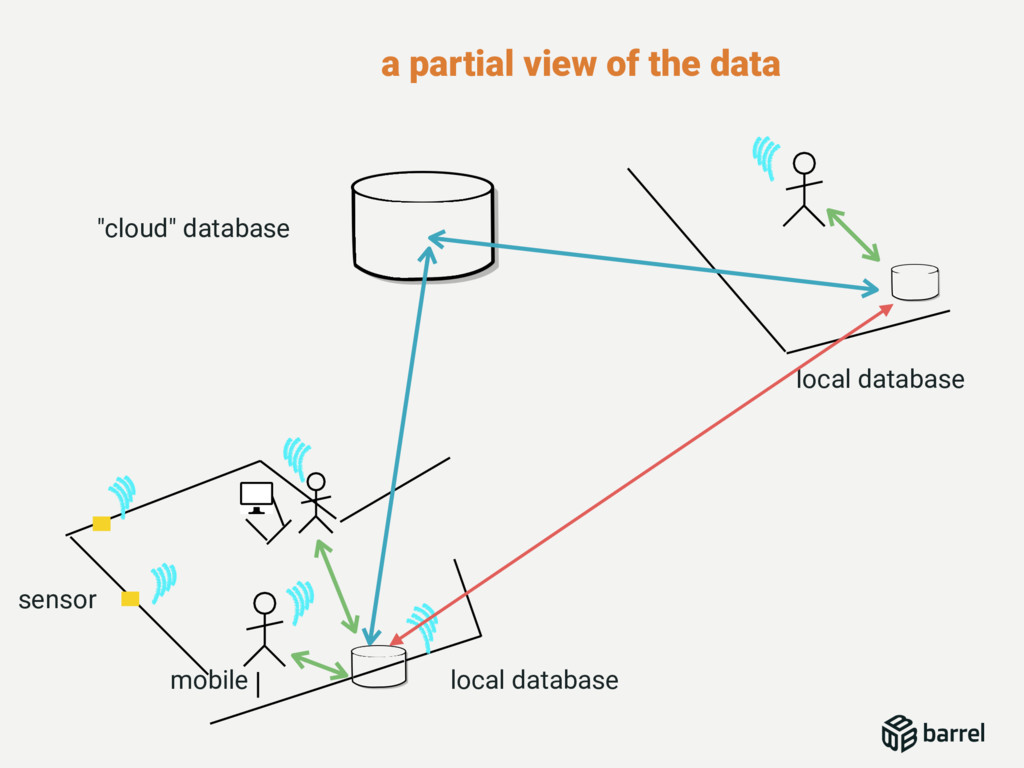
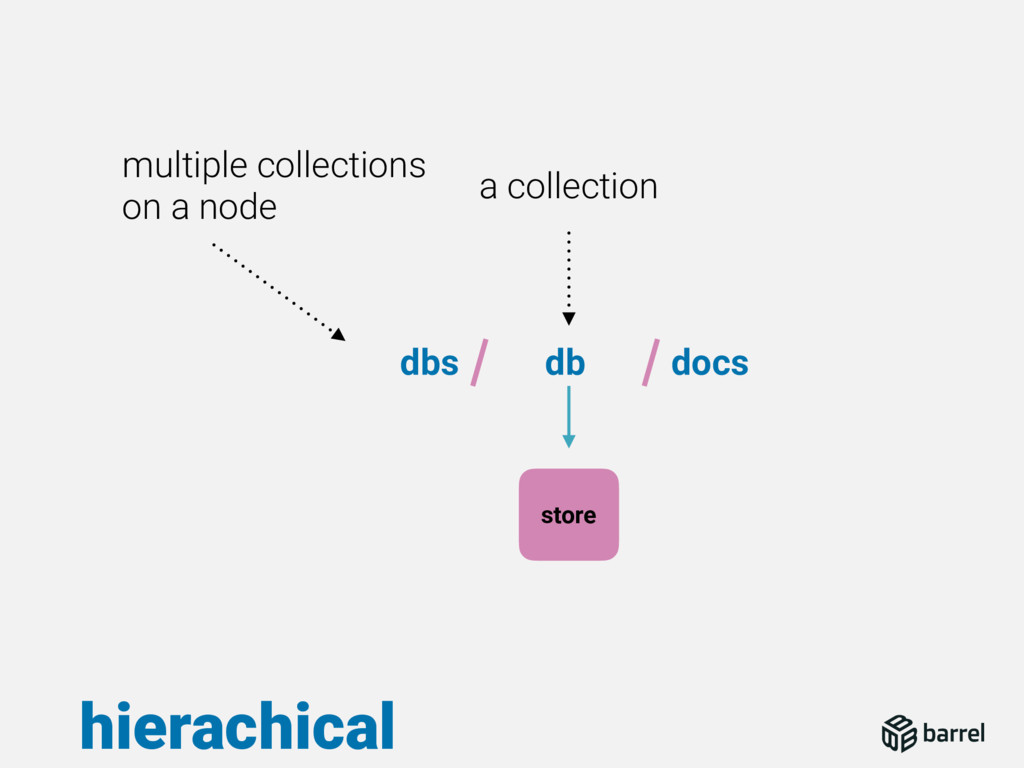
This talk will describe the different challenges we faced in writing a database, from binding C code in Erlang, to write a complete document storage engine with its SQL Engine. This talk will also describe the different patterns used for Reads and Writes concurrency but also continuous automated indexation of the documents.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
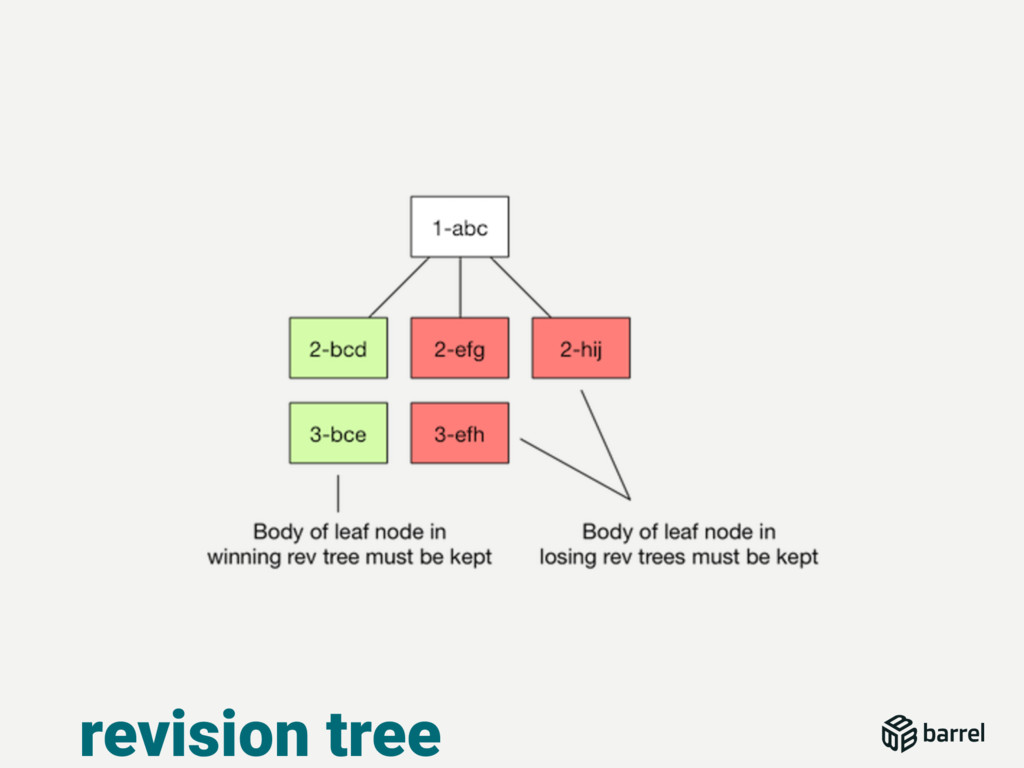{kind=link}
{kind=link}
{kind=link}
{kind=link}
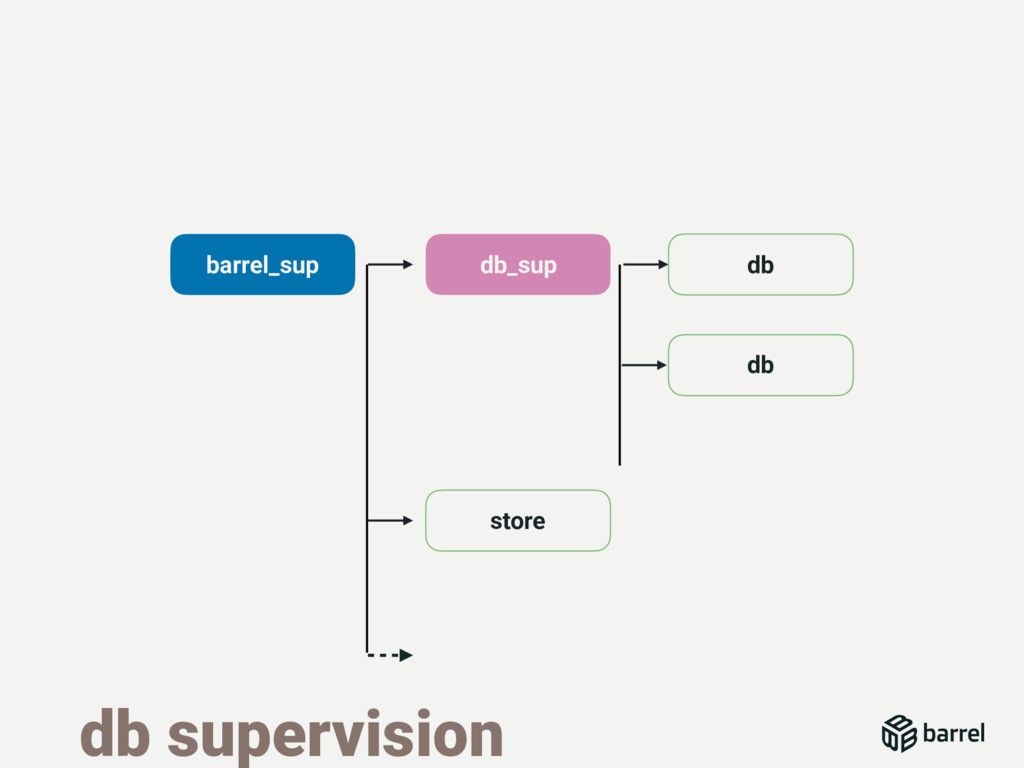{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}