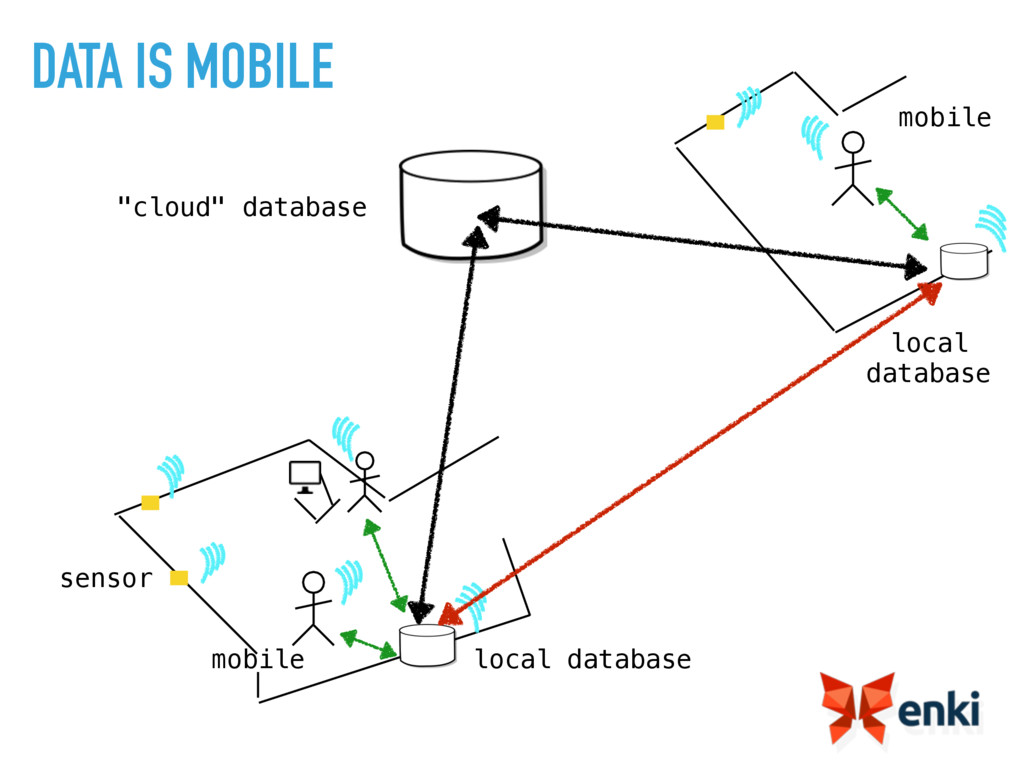
Barrel (https://barrel-db.org) is a modern document-oriented database in Erlang focusing on data locality (put/match the data next to you) and P2P with an effort to maintain a compatibility with the Apache CouchDB API.
Barrel started as a fork of Apache CouchDB, another database in Erlang, but it quickly appeared that we needed to go further. Building a database in Erlang is indeed challenging. I/Os are handled differently from the other VM for example. Performance is always a trade-off versus the concurrency and the fault tolerance. On the other hand, Erlang, its vm, the OTP framework offer many competitive advantages that can help you to build a very effective database. So Barrel has then been rewritten to benefit from them.
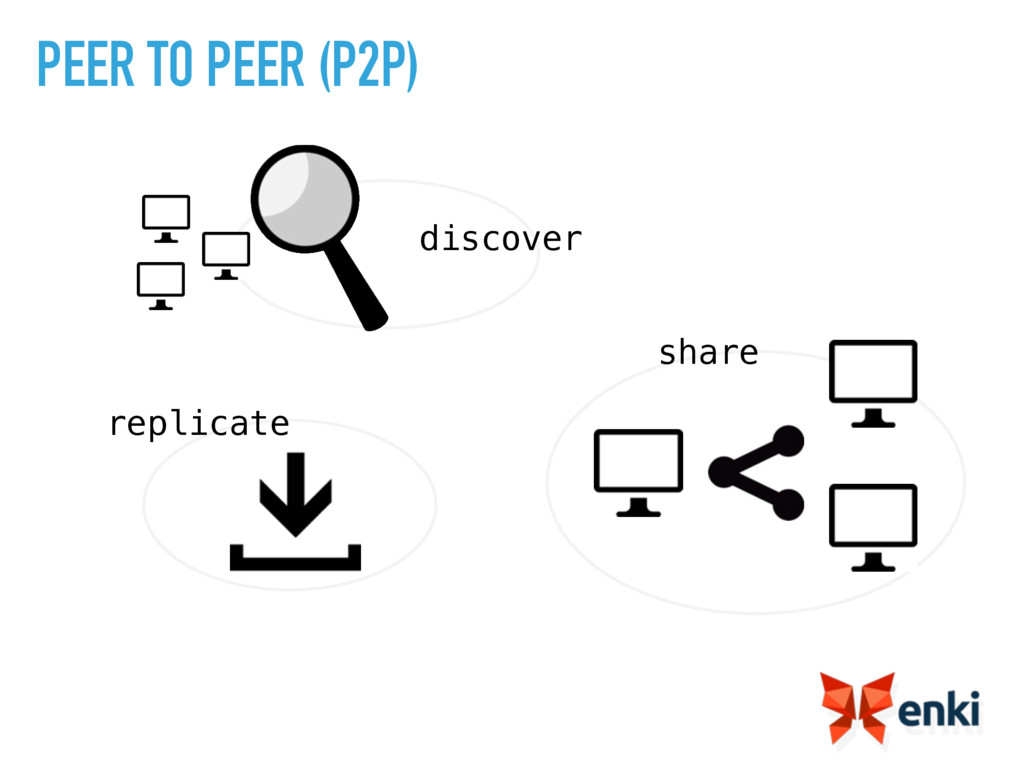
This talk will first deconstruct a database and then focus how we can build one in Erlang using Barrel as an example. We will see which part probably needs to be in C, which one really fit well in Erlang… It will show you also how building a P2P protocol in Erlang is easy and help us to make barrel a true P2P database.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
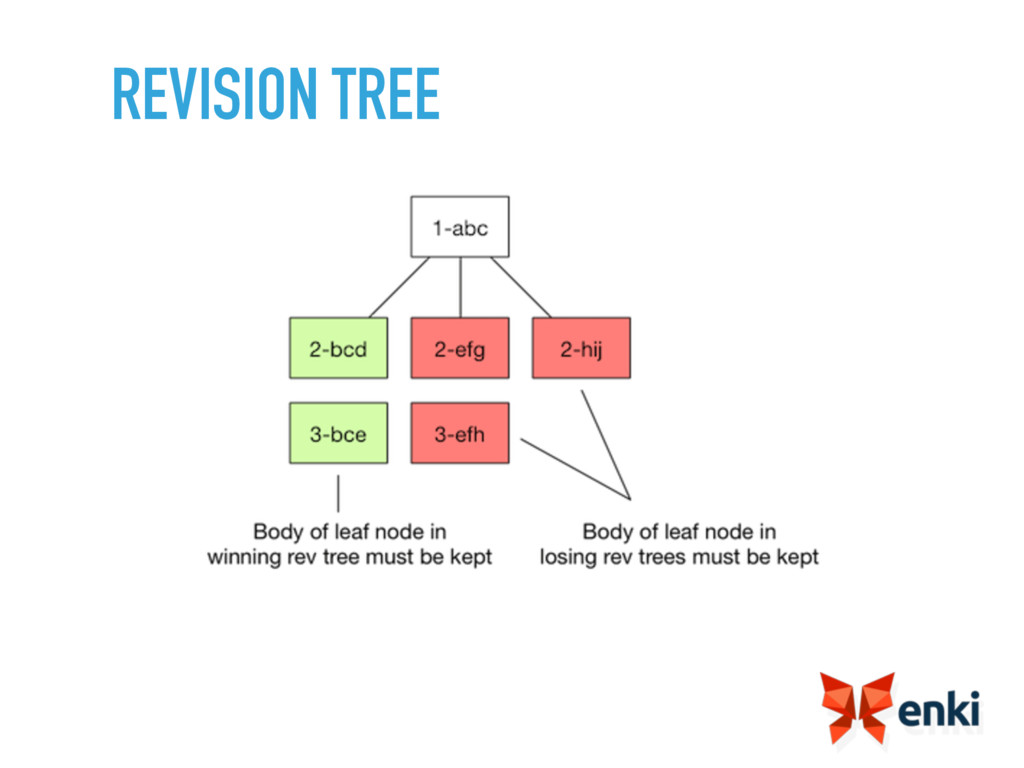{kind=link}
{kind=link}
{kind=link}
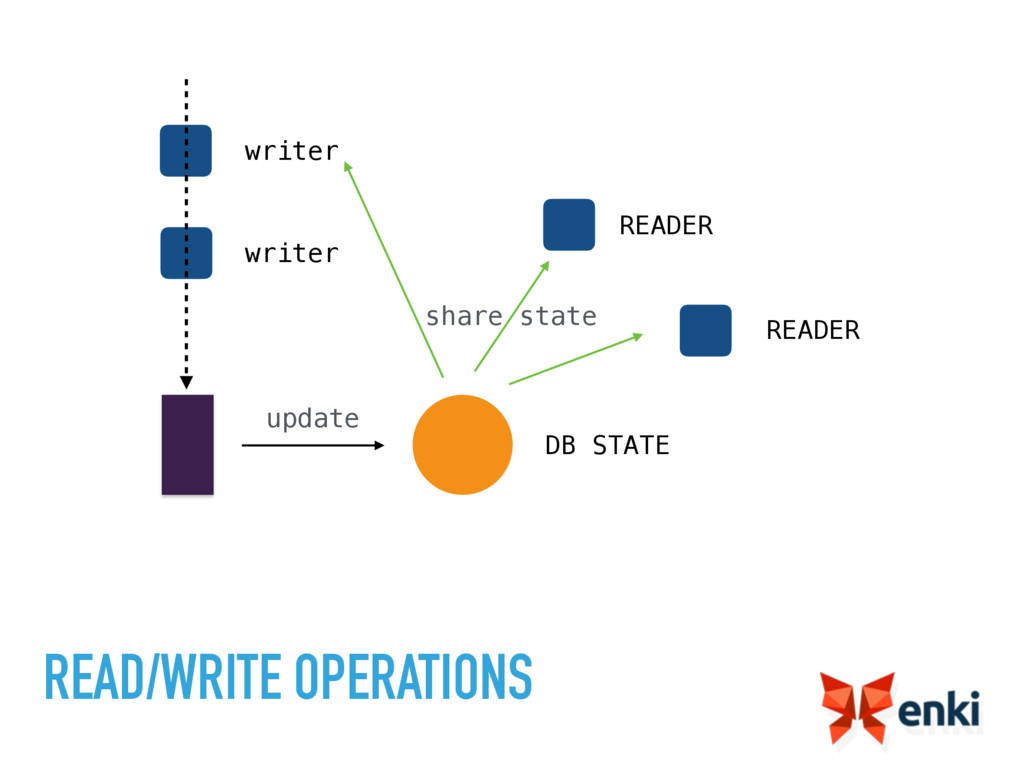{kind=link}
{kind=link}
{kind=link}
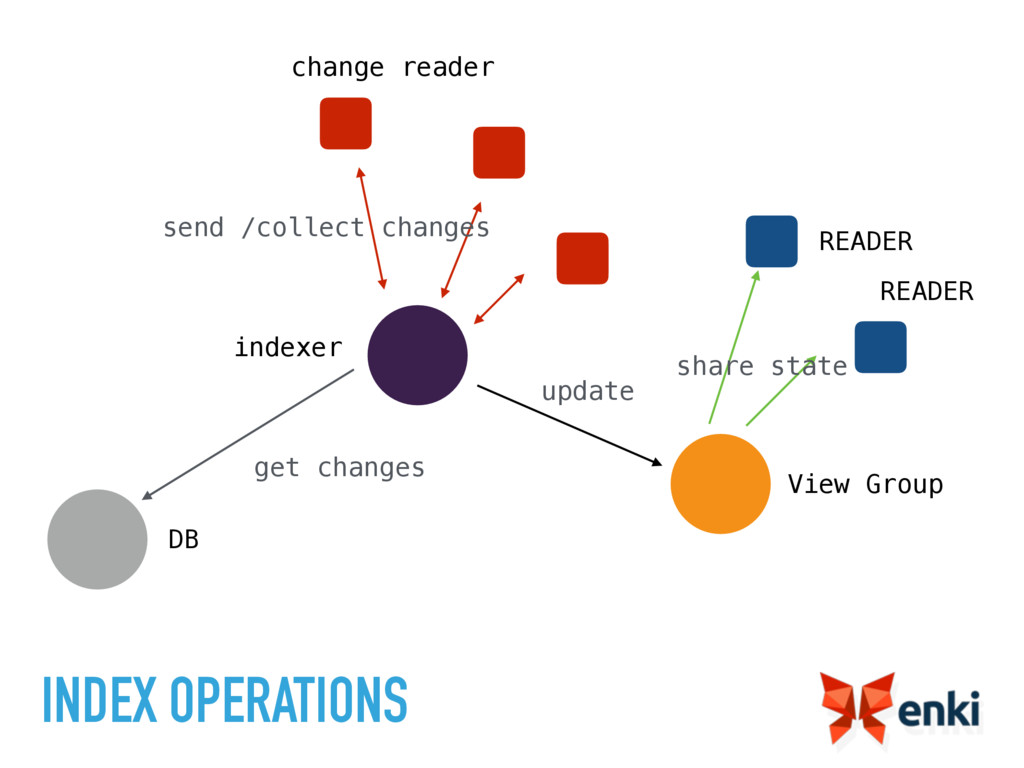{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
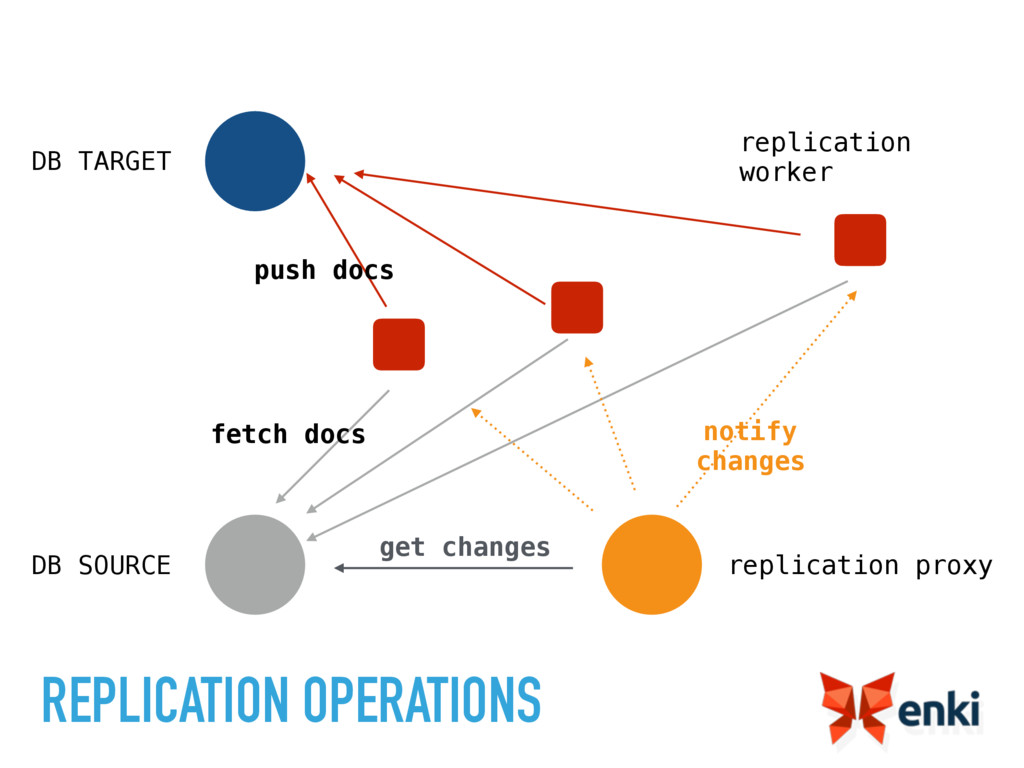{kind=link}
{kind=link}
{kind=link}
{kind=link}