Barrel is a database Benoit wrote from scratch over the past two years that can be embedded in an Erlang or Elixir application like Mnesia. With Barrel, you can easily bring and keep a view (complete or partial) of your data inside your application and replicate it between your different machines.
This talk will describe how you can use Barrel to quickly create your own peer-to-peer data platform with different storage and replication strategies
{kind=link}
{kind=link}
{kind=link}
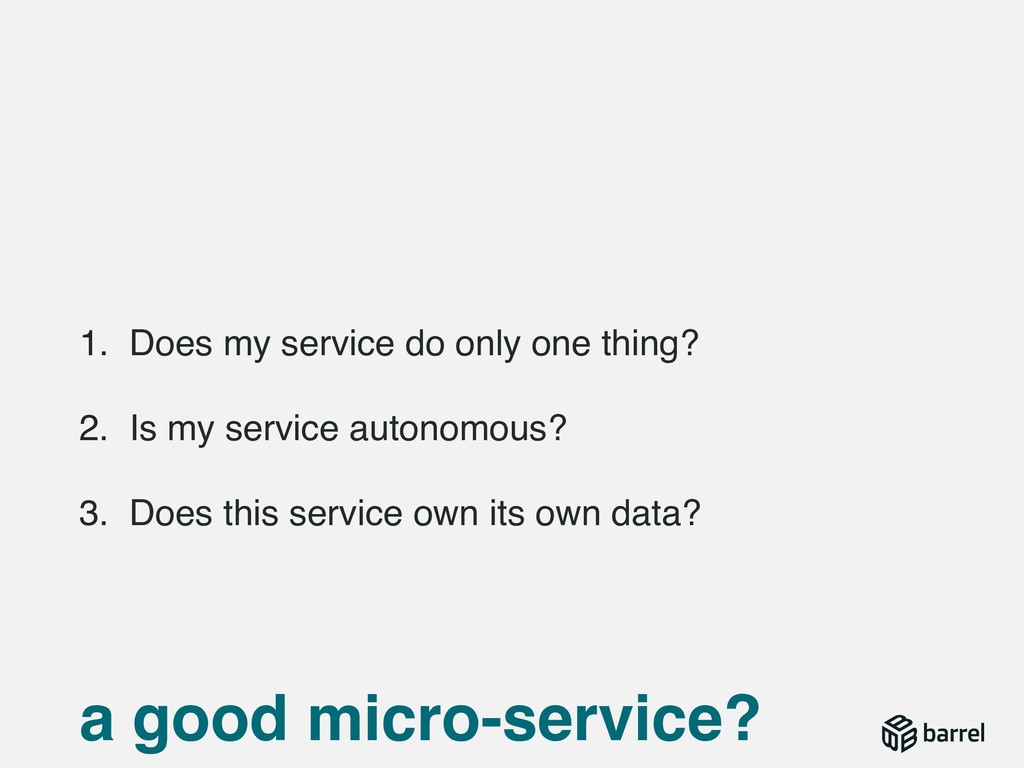{kind=link}
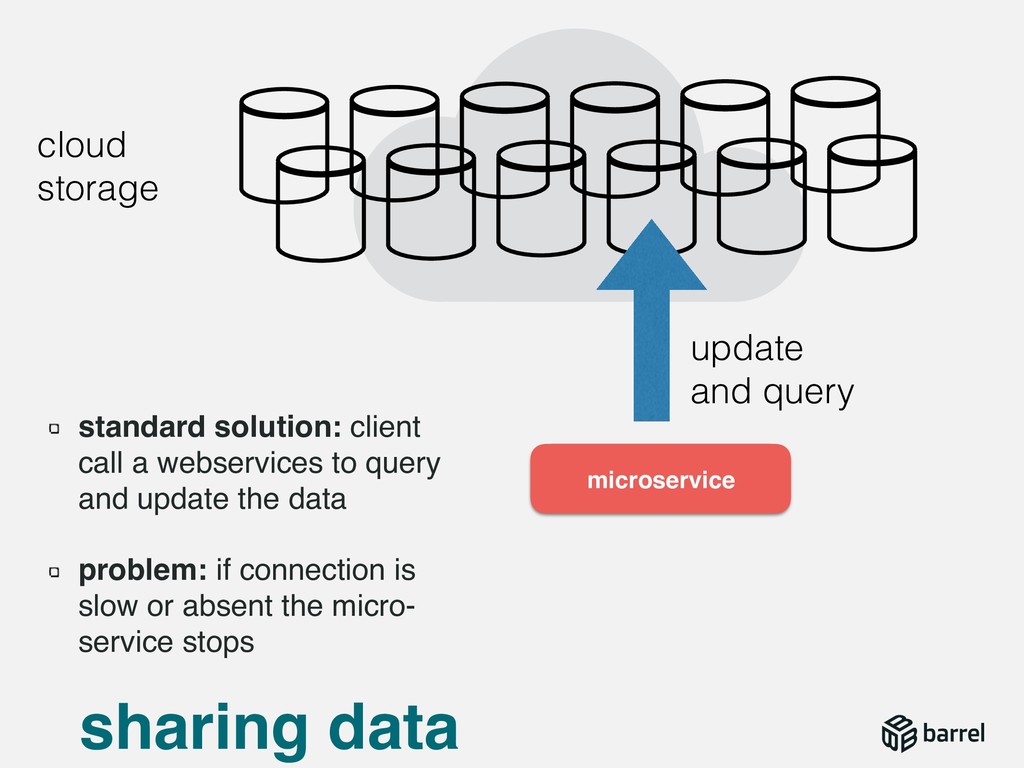{kind=link}
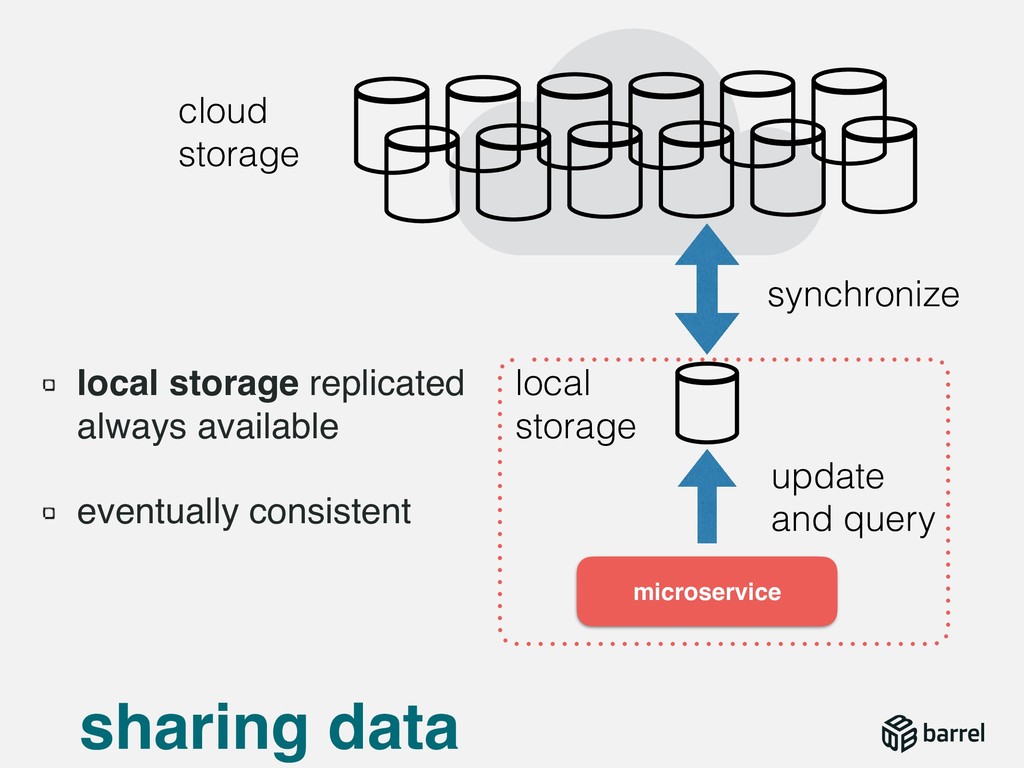{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
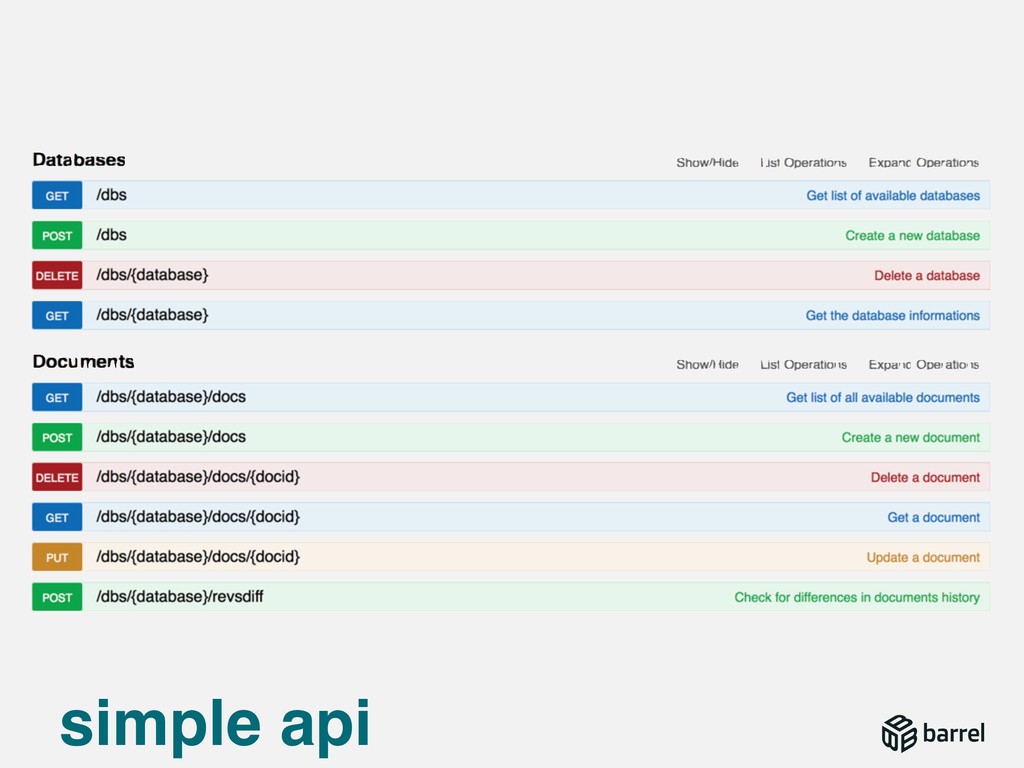{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
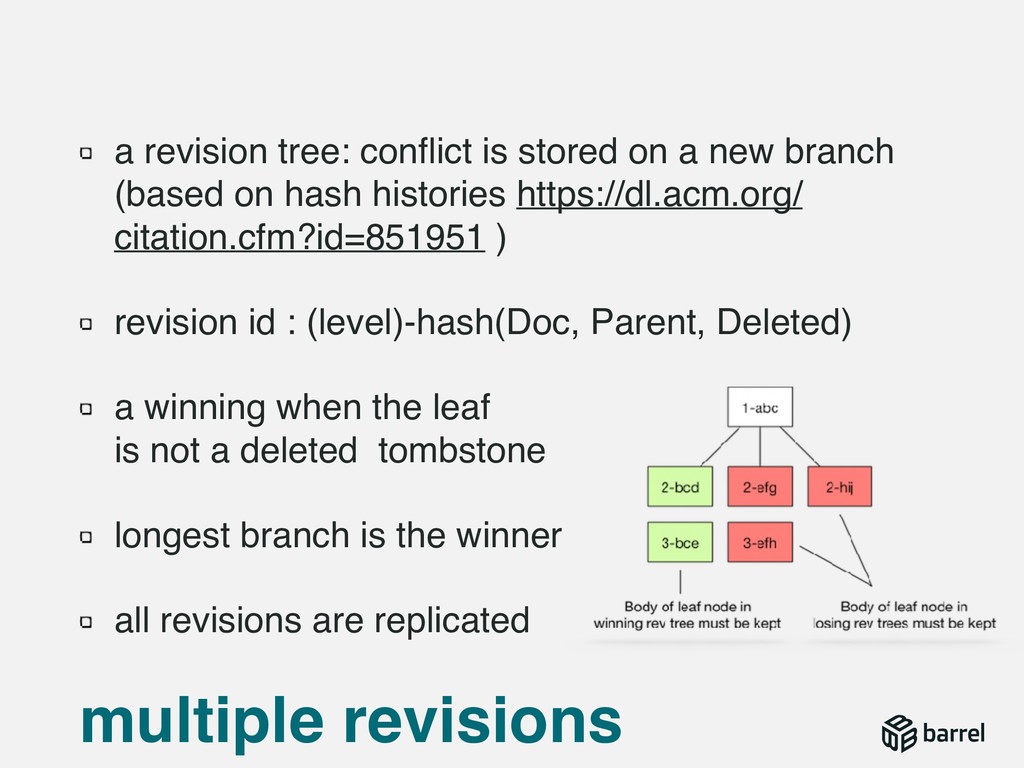{kind=link}
{kind=link}
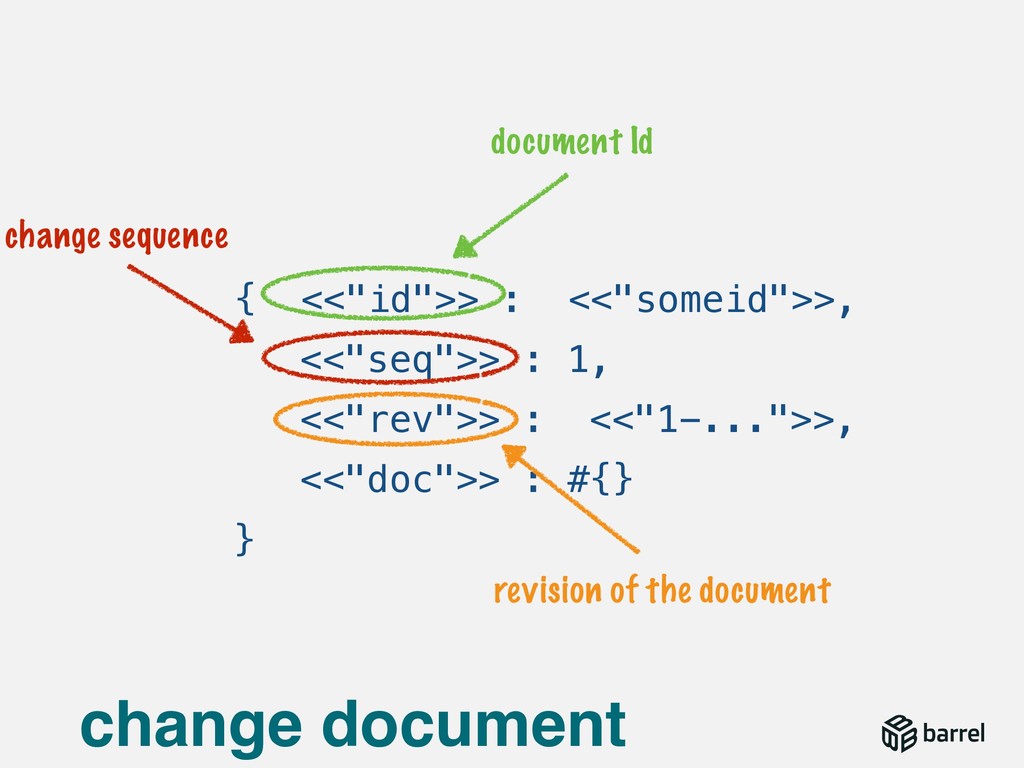{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}