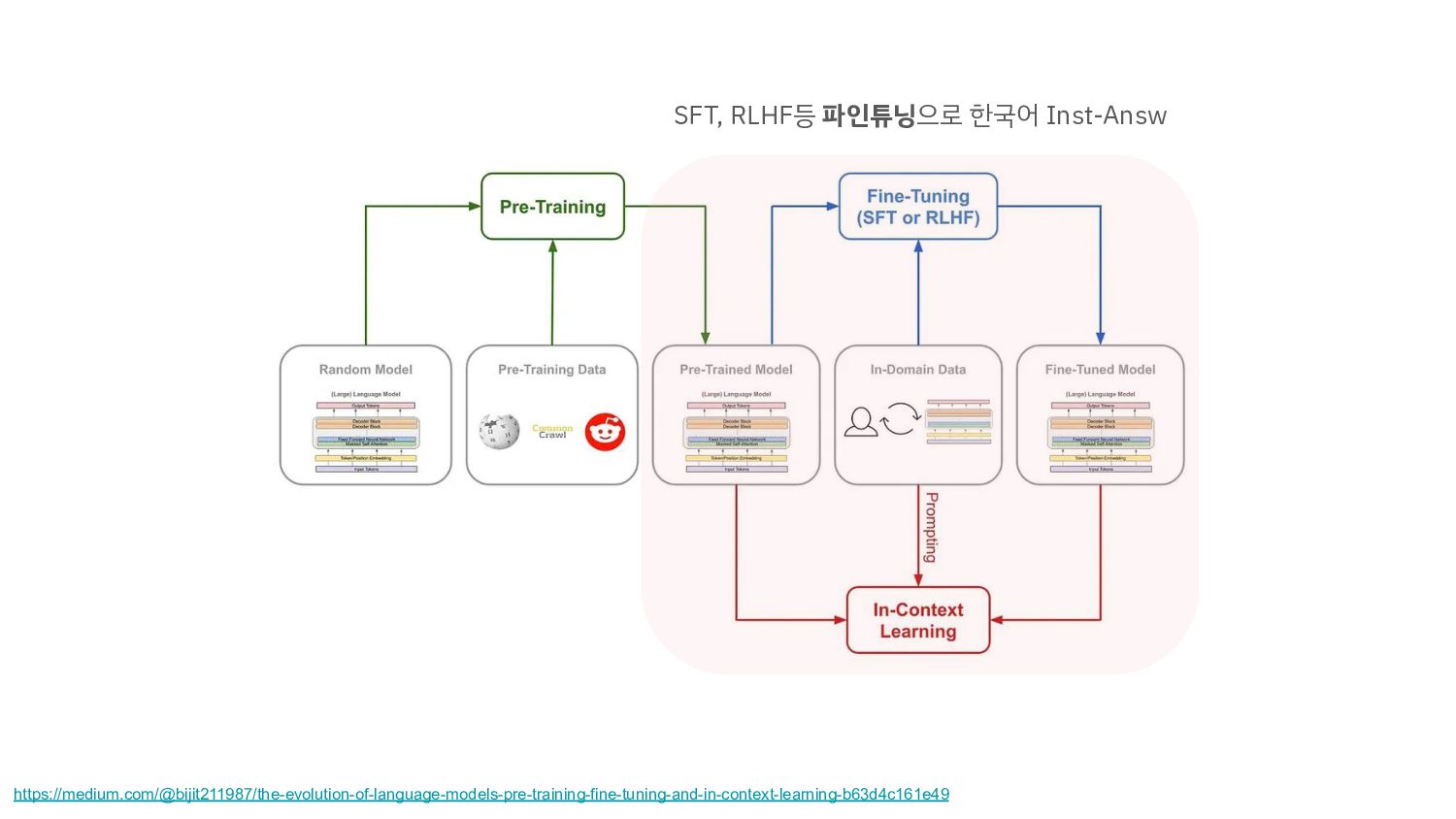
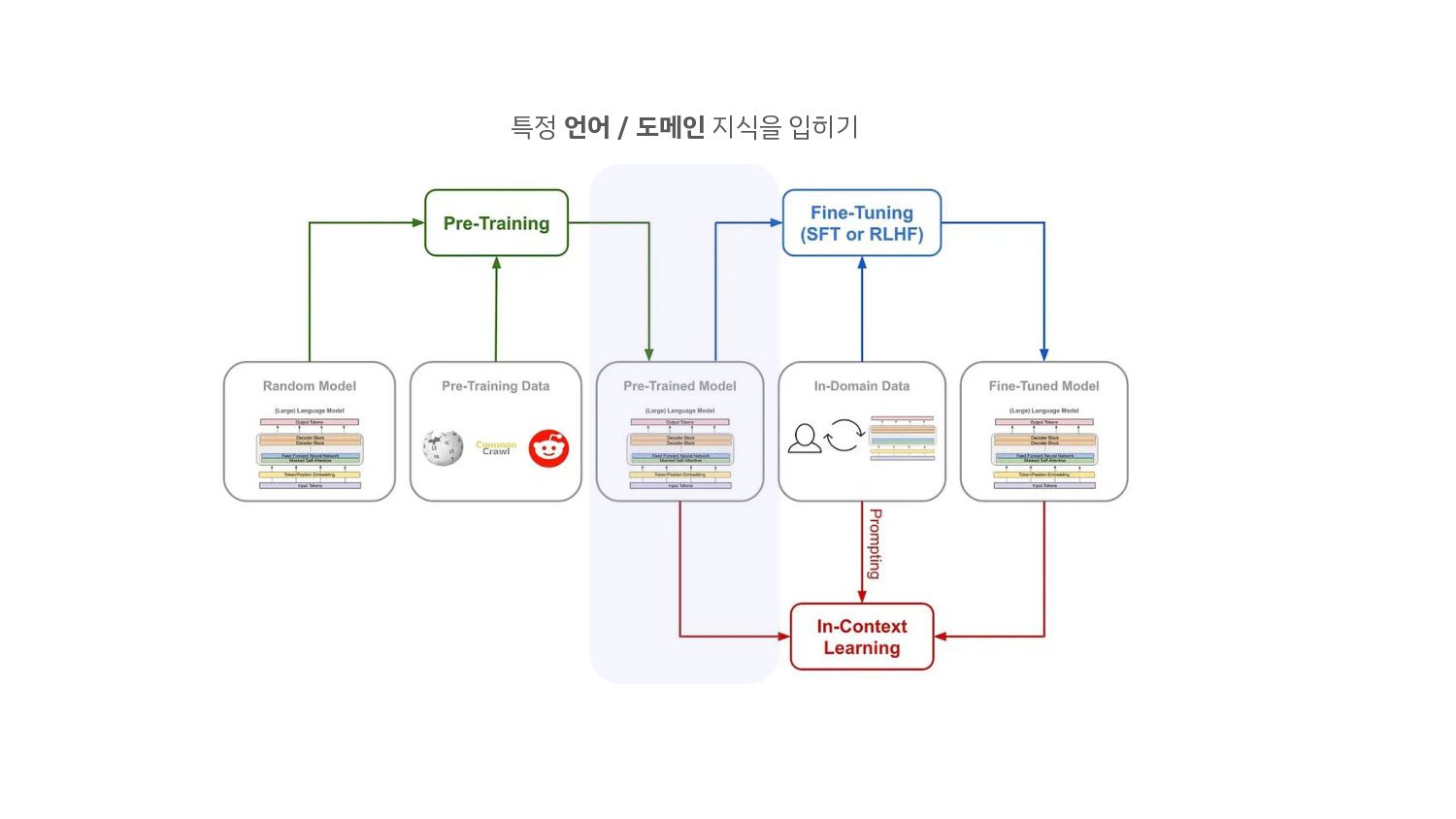
→ 모델이 한국을 잘 모르니까(배운 적이 없으니), 한국 데이터를 넣어주자. 2. 영어 모델에 저장된 지식을 "한국어로 자연스럽게 말하게" 만들기 → 좋은 영어 성능을 보이는 모델을 지식과 지능을 "한국어로" 말하게 하자. 현재 Gemma-Ko 학습의 방향: (1)번 앞으로 언어 특화 Continued Train의 방향: (2)번
모두의 말뭉치 모두 모으면 약 50GB 웹 사이트 커뮤니티 데이터, 블로그나 카페 등 수백GB 쇼핑몰 리뷰, 네이버 댓글 등 데이터 수십GB 네이버 뉴스 댓글 KcBERT 데이터 ~100GB ... 이렇게 모두 모아 텍스트만 찾아서 EleutherAI/DPS 로 Document 단위 중복제거 약 350GB+a 수준의 한국어 데이터셋
Gemini pro, GPT4o, …)으로 체크 → 만약 LLM API로 불가능하면 서비스 자체를 재고려 2. LLM API 중에서 가벼운 모델로 바꾸기 + Prompt → 작은 모델에 더 긴 prompt 가격 vs 큰 모델 가격 3. 작은 모델에서는 안되고 큰 모델에서만 되면.. → 큰 모델에서 생성된 데이터셋으로 작은모델 파인튠 4. 작은 모델에서 가능하면… → 오픈 모델 중에서 큰 모델을 LoRA 학습 5. 오픈 모델 중 큰 모델에서 되면… → 같은 계열의 작은 모델에 데이터셋 넣어 파인튠 6. 도메인 지식이 부족하다고 느끼면… → 최대한 관련 지식의 정확한 질문답변 셋 학습 7. 그래도 부족하거나 / 데이터셋 생성이 어려우면.. → 이때 Continued Pretrain 준비
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
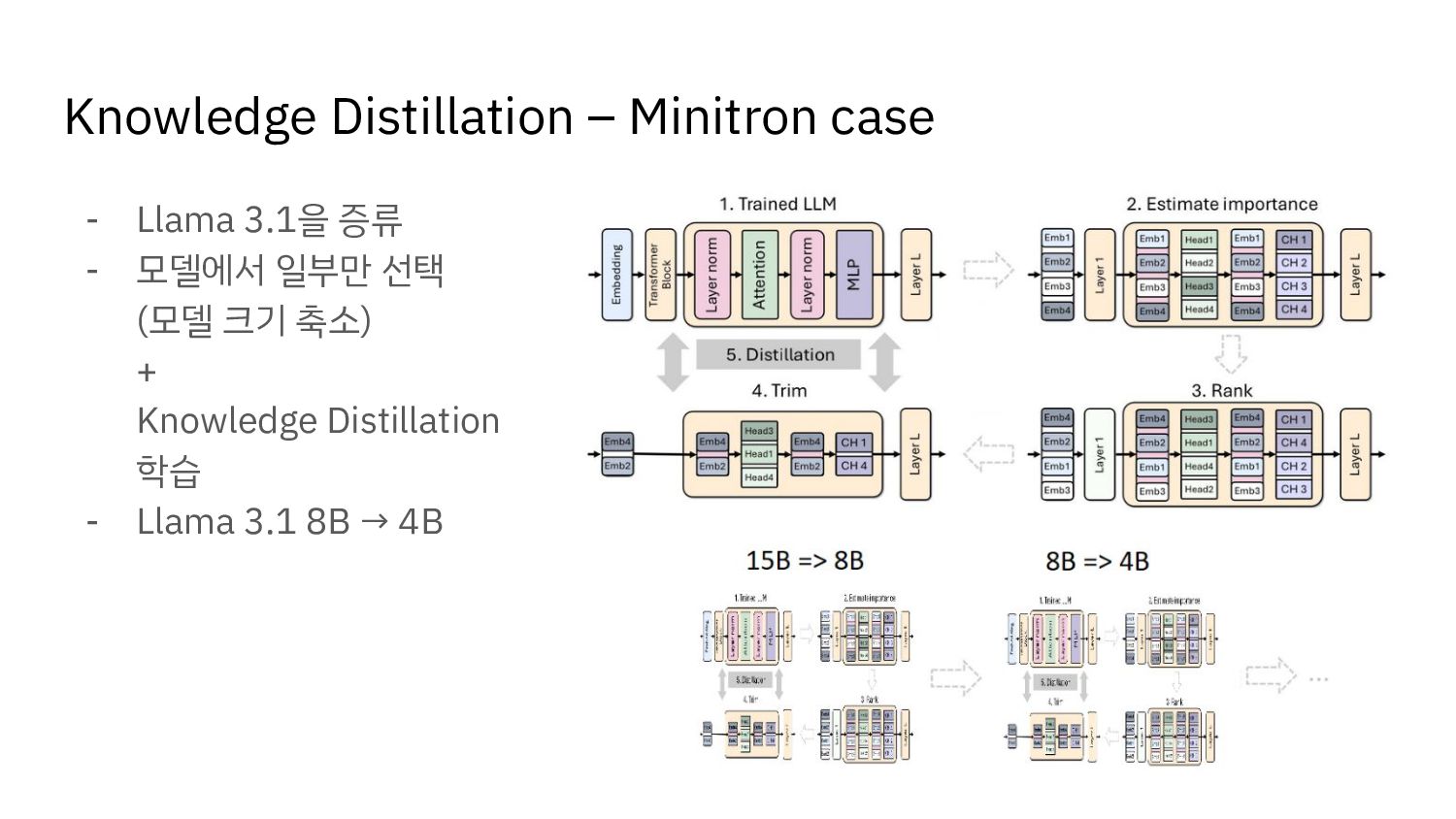{kind=link}
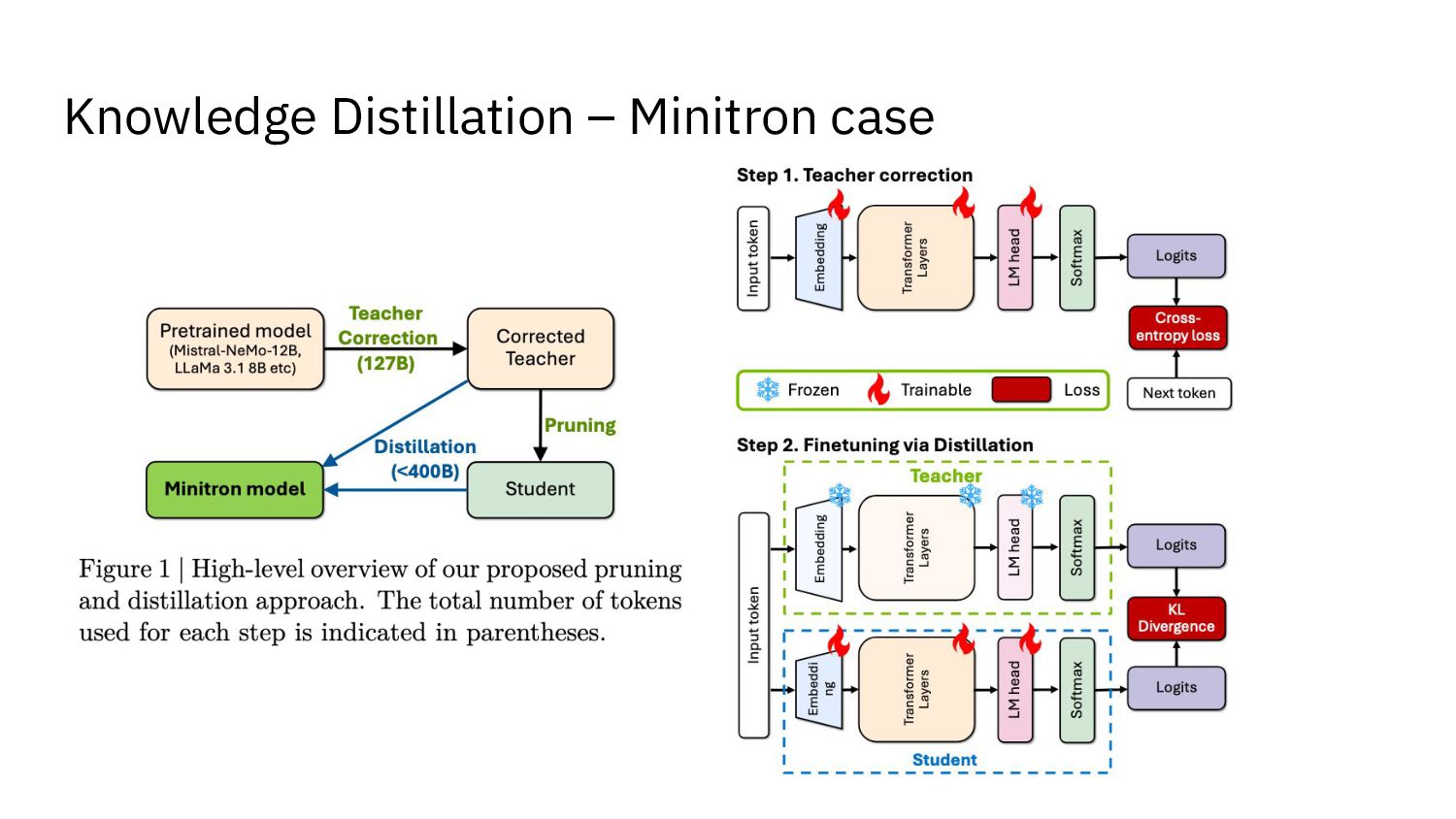{kind=link}
{kind=link}
{kind=link}
{kind=link}
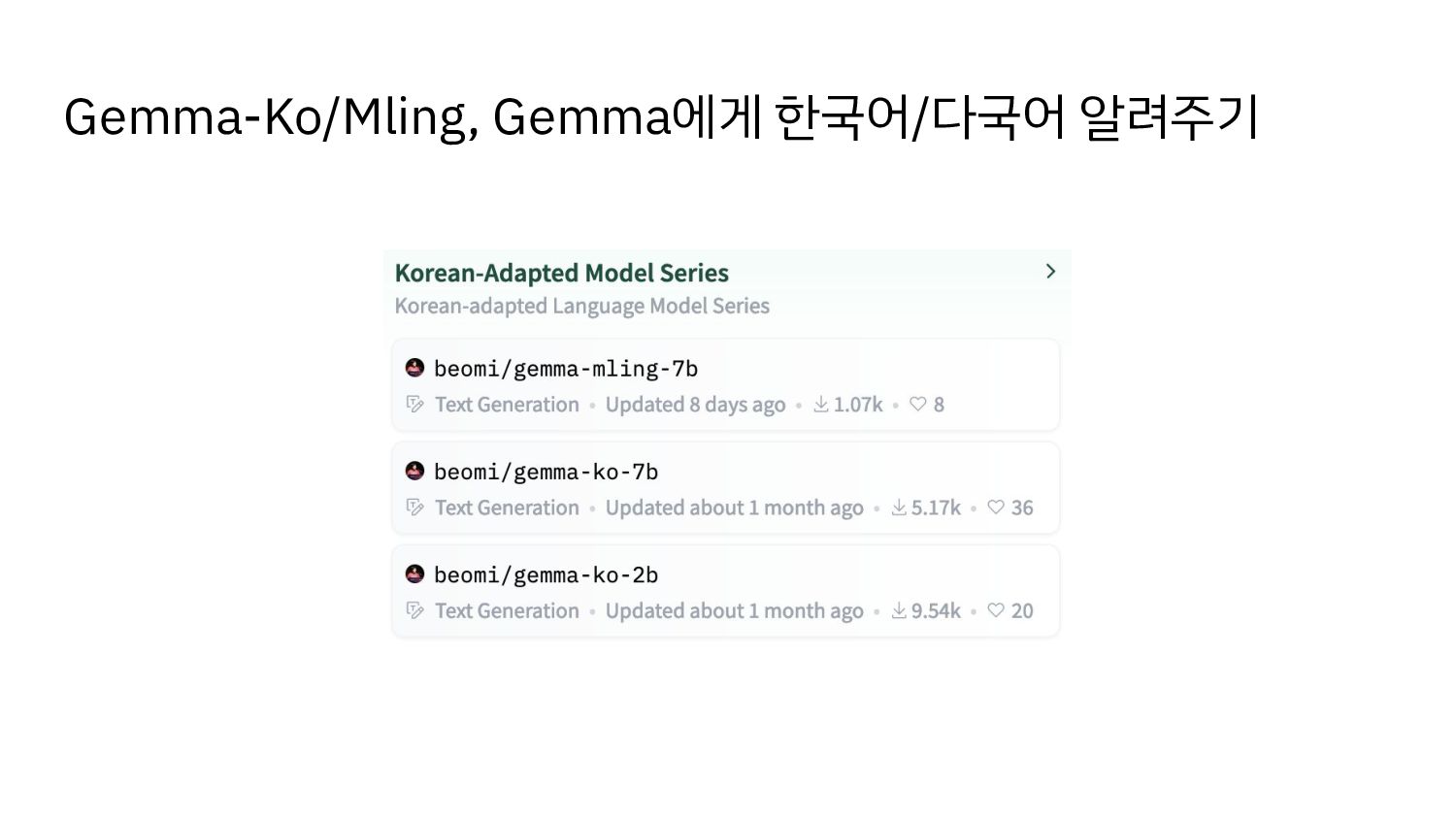{kind=link}
{kind=link}
{kind=link}
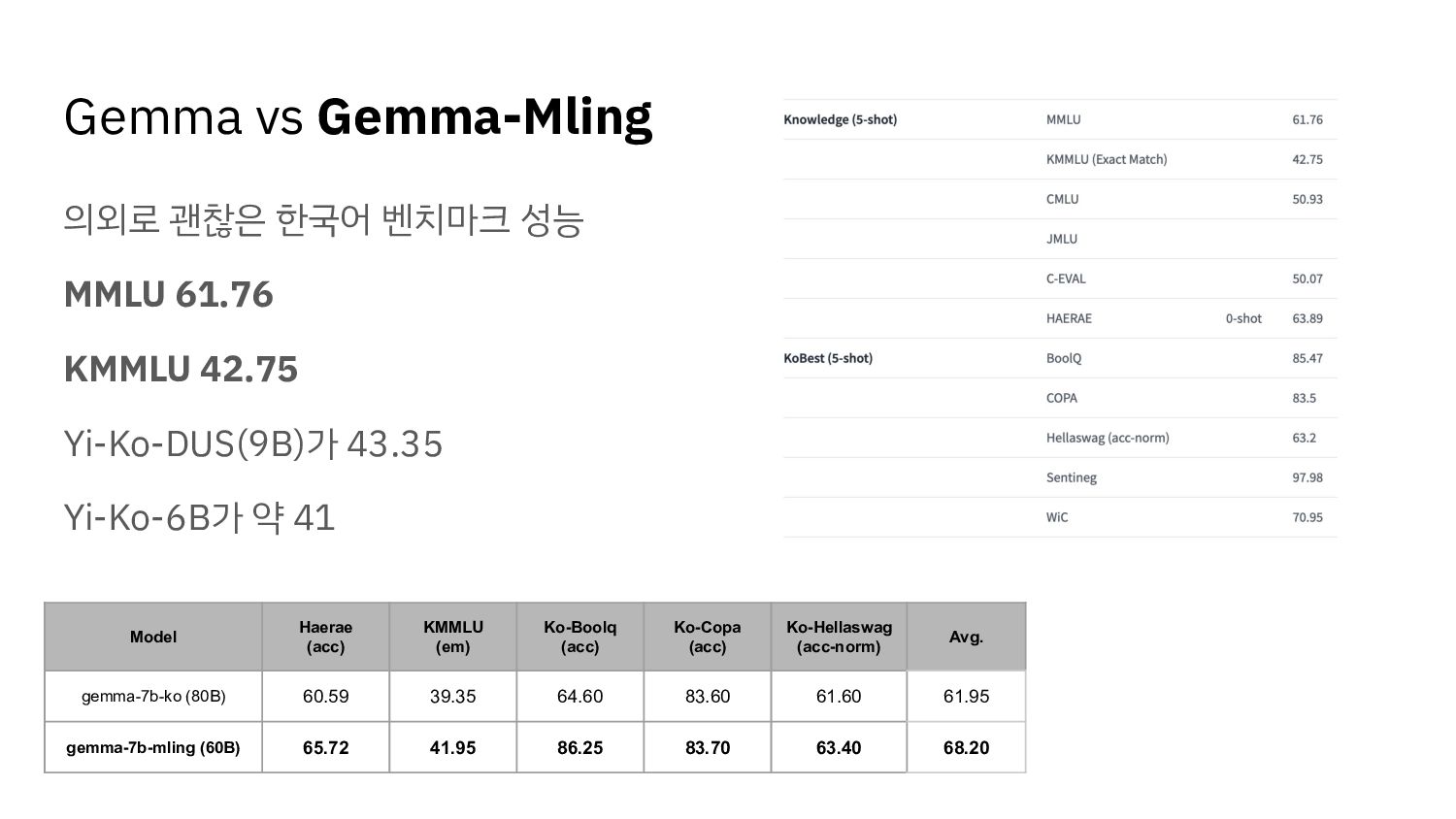{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}