on disks. • No easy way to fetch/search logs. • Hard to scale. • Untapped potential in log data DRUM ROLLS…… Log Management. 3 Before Elasticsearch Disks RDBMS Logs Events Incidents Tickets
store massive amounts of data. • Must be able to get data in at a very high rate and get data out at an acceptable rate. • Should be schema agnostic. • Must be able to search/filter/analyze data. • Must support MULTI-TENANCY. • Distributed/fault-tolerant/load-balanced/etc. 4
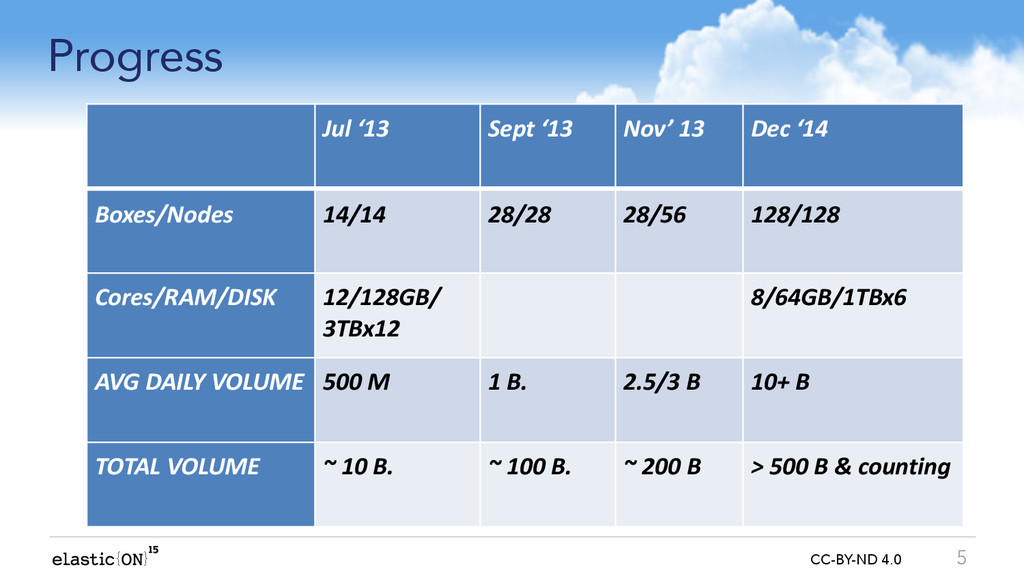
Nov’ 13 Dec ‘14 Boxes/Nodes 14/14 28/28 28/56 128/128 Cores/RAM/DISK 12/128GB/ 3TBx12 8/64GB/1TBx6 AVG DAILY VOLUME 500 M 1 B. 2.5/3 B 10+ B TOTAL VOLUME ~ 10 B. ~ 100 B. ~ 200 B > 500 B & counting
Volume / Velocity / Variety / Veracity will affect your choices and their interactions even more so. • Select a proper base config for your nodes. Get the CPU- Cores x RAM x Disk ratio right. • Decide on self hosted vs. cloud hosted. • Prefer JBODs for data disks over RAID, SAN/NAS. • Virtualization vs. bare metal: know the tradeoffs. • SSDs vs. Spinning Disks, (Speed vs. Capacity). 6
name. • Dedicated Master, Data and Client nodes. • Use Aliases from get go. • Keep all nodes in same subnet. Use unicast discovery. • Have enough memory for JVM heap + FS Cache. • Tune kernel parameters, user/process/file/network limits. • Always CHECK JVM version compatibility. Also, stick to Oracle JVM. • Learn Query DSL and Elasticsearch APIs. 7
params, but avoid going overboard. • Tune network/connectivity parameters. • Tune recovery parameters. • Configure gateway parameters. • Tune thread pools: Bulk/Index/Search. • Prefer bulk indexing. • Tune caching parameters, especially field data. • In general don’t be afraid to tweak-n-tune till you hit performance sweet spot. • Having a knowledge of text analytics in the team will go a long way. 8
Elasticsearch along with another service on the same box. • Avoid vertical scaling i.e. avoid 2+ nodes per box. • Don’t grow cluster beyond ~150 nodes. Deploy multiple clusters and use Tribe node. • Don’t allow unrestricted/unsupervised querying unless you know the user base. • Never send data for indexing or search queries to Master nodes. 9
interval = -1. Send data directly to data nodes. • Set aside more resources for bulk thread pool. • We saw slight performance gain when using raw TCP over HTTP. • Build new index per month/week/day/hour(?) and use aliases. • Number of Indexes x Shards x Replicas not only affects storage but also Memory. 11
lot of “types” in a single index. • Use mappings/templates for pre-defining field types. • Disable ‘_all’ field unless really needed. Avoid ‘storing’ fields outside of ‘_source’. • Know which fields to NOT analyze. Decide which analyzer/token-filter/char-filter works best. 12
‘query string’ query. • Know difference between “bool” and ‘and/or/not’ filters. • Know the impact of faceting/aggregations/sorting on field data cache for high cardinality fields like “timestamp”. • For bulk searching use ‘scroll’. • Rely on explain/validate queries for performance tuning. • Search Templates for simplified queries. • Send searches to client nodes. Not to data nodes and never ever to Master nodes. 13
we prefer Nagios, but Marvel works really well too. • Use automated deployment / configuration management via Chef/Puppet/Salt/Ansible. • Prefer to share a single config file for all node types. • We retain raw data in HDFS for a year in case of data loss / re- indexing required. Data in Elasticsearch retained for max 90 days. • Know when to use rolling upgrades vs full upgrades. 14
Attribution-NoDerivatives 4.0 International License. To view a copy of this license, visit: http://creativecommons.org/licenses/by-nd/4.0/ or send a letter to: Creative Commons PO Box 1866 Mountain View, CA 94042 USA CC-BY-ND 4.0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}