Slides from my talk at Washington DC Elasticsearch meetup on Dec 11th 2014, about scaling Elasticsearch for production scale data.
Event Details :-
http://www.meetup.com/Elasticsearch-Washington-DC/events/218806074/
Video of the Talk :
http://www.elasticsearch.org/videos/washington-d-c-meetup-december-11-2014/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
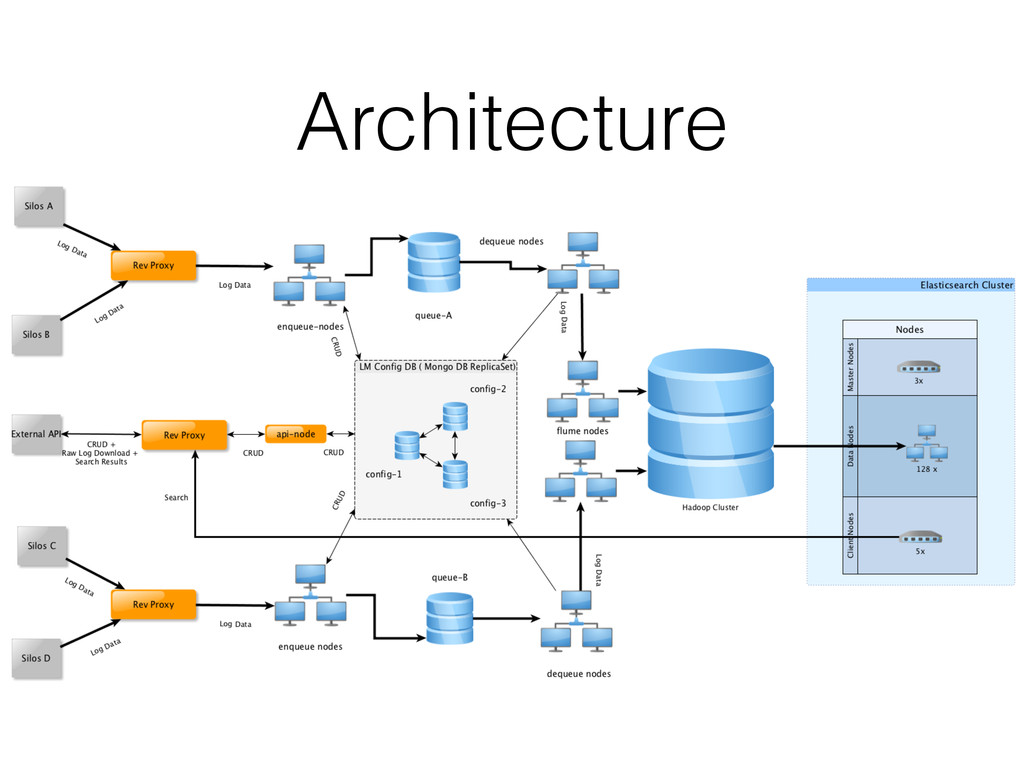{kind=link}
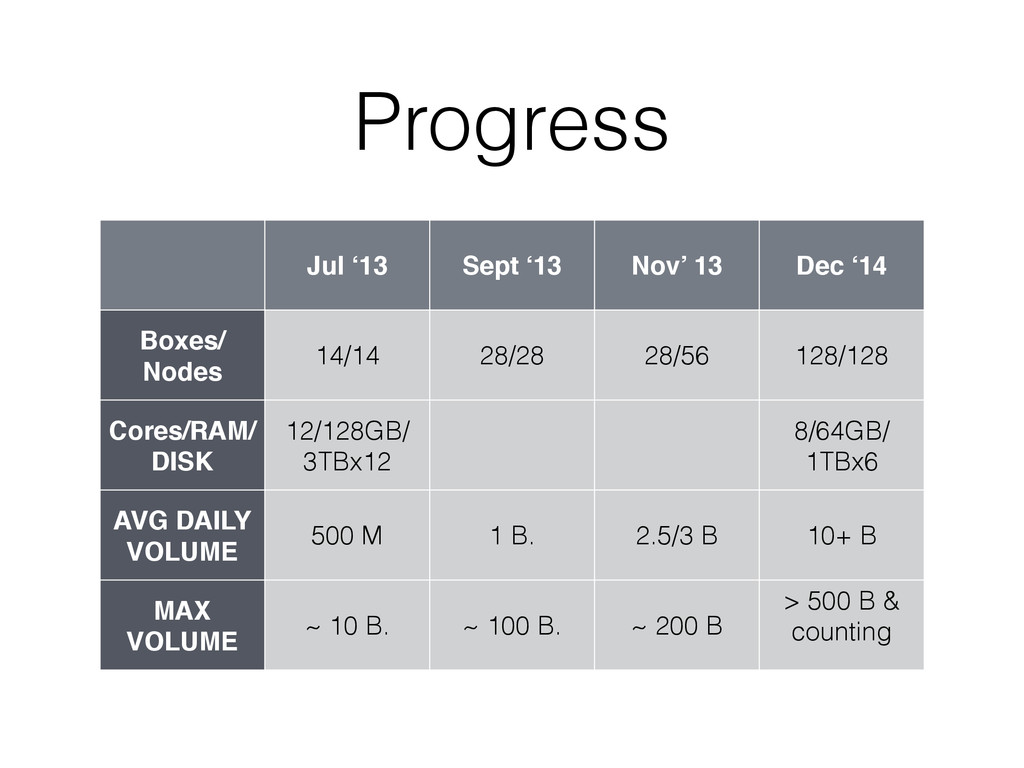{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}