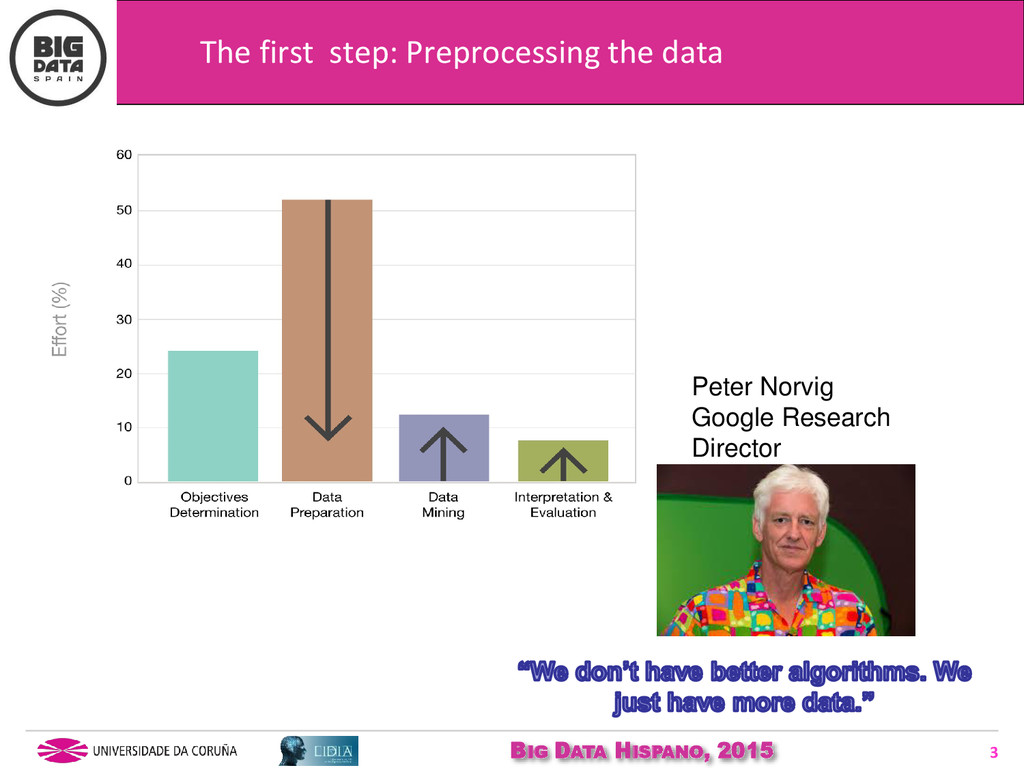
Preprocessing data is one of the most effort consuming tasks in Machine Learning (ML). In the Big Data context, the models automatically derived from data should be as simple as possible, interpretable and fast, and for achieving that we will need to use the best variables, that is, use the best features of such data.
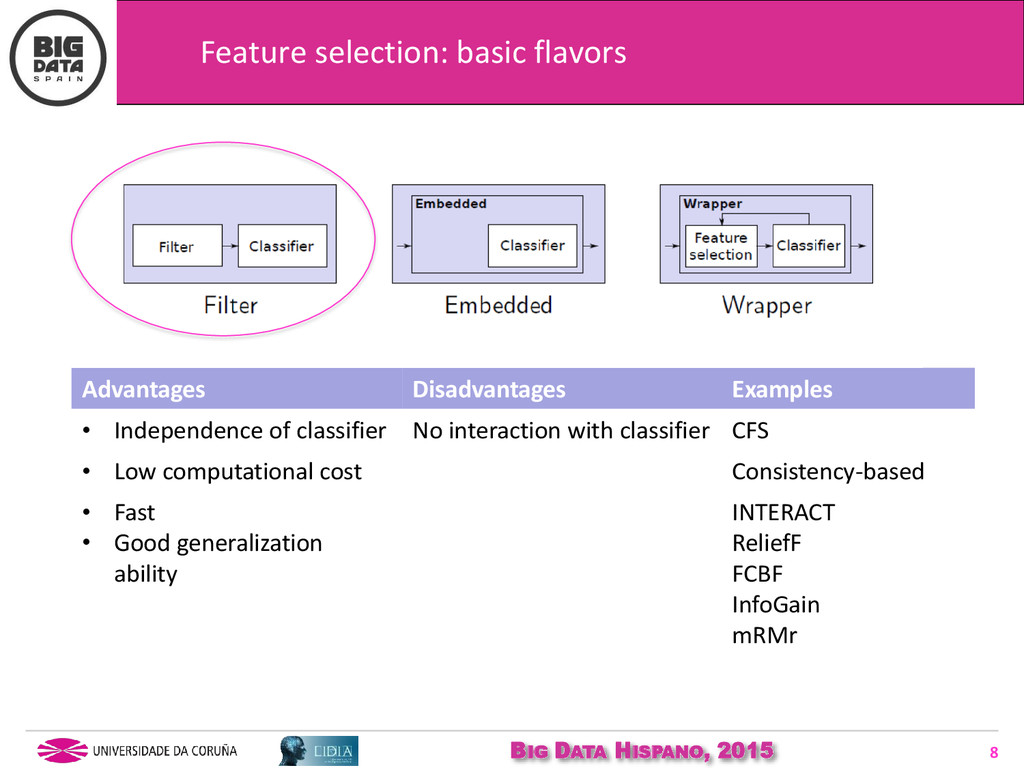
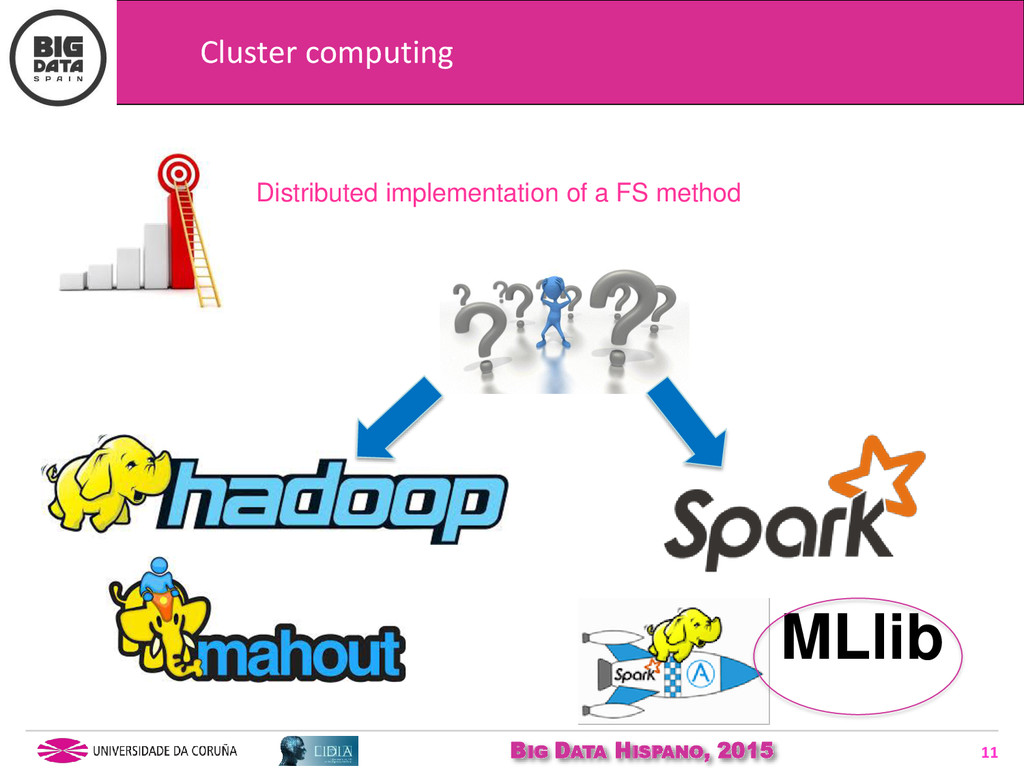
Although there are already several libraries available which approach ML tasks in Big Data, that is not the case for FS algorithms yet, and other preprocessing techniques such as discretization. However, the existing FS methods do not scale well when dealing with Big Data. In this presentation, we show our efforts and new ideas for parallelizing standard FS methods for its use on Big Data environments.
Session presented at Big Data Spain 2015 Conference
15th Oct 2015
Kinépolis Madrid
http://www.bigdataspain.org
Event promoted by: http://www.paradigmatecnologico.com
Abstract: http://www.bigdataspain.org/program/thu/slot-11.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
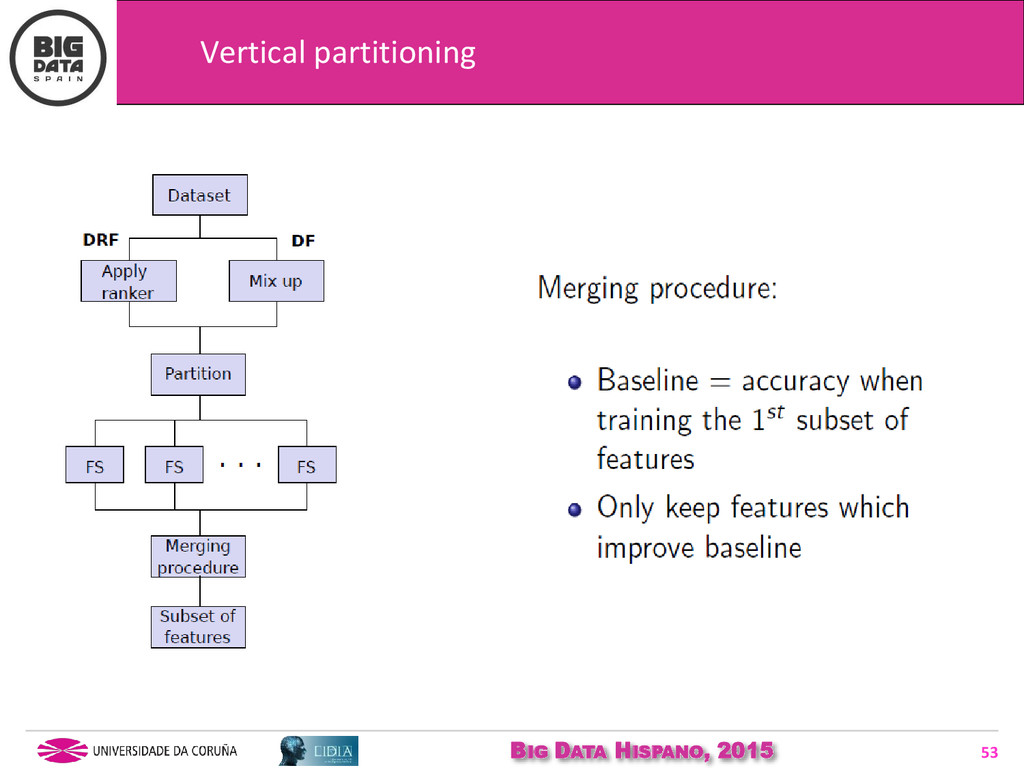{kind=link}
{kind=link}
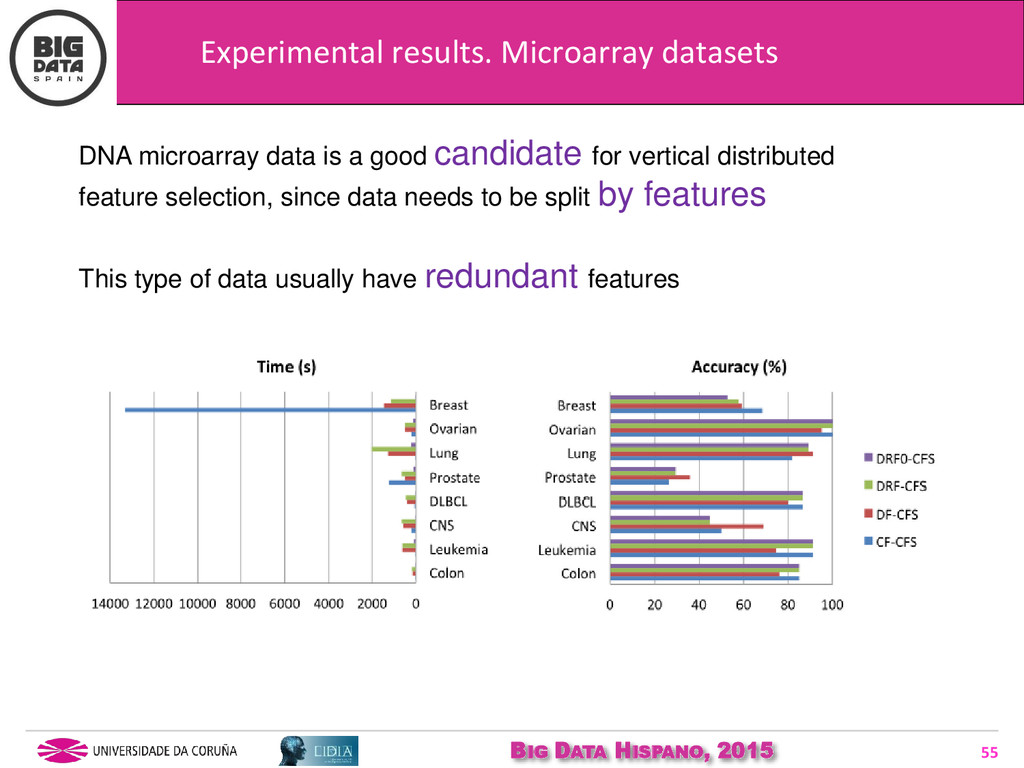{kind=link}
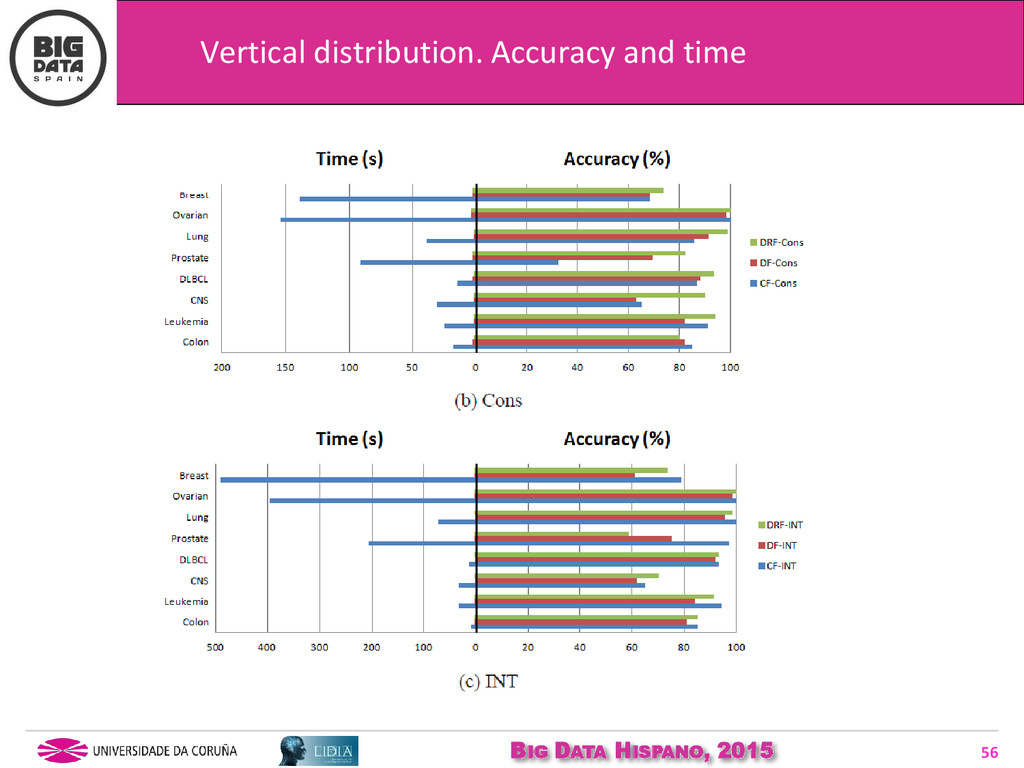{kind=link}
{kind=link}
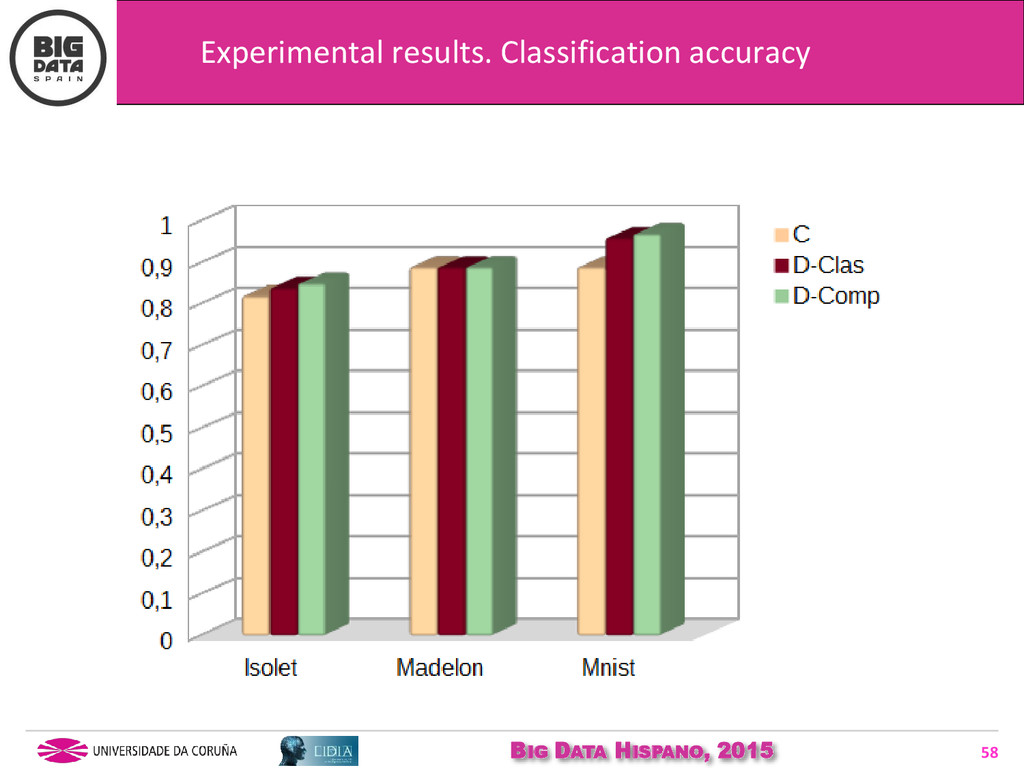{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}