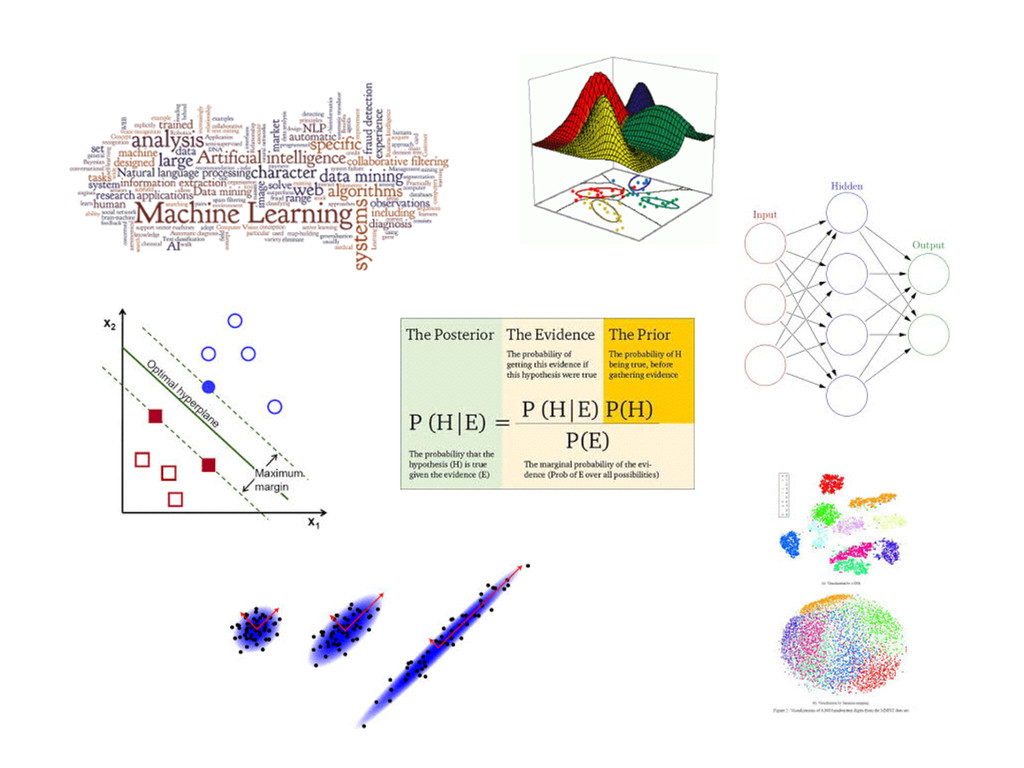
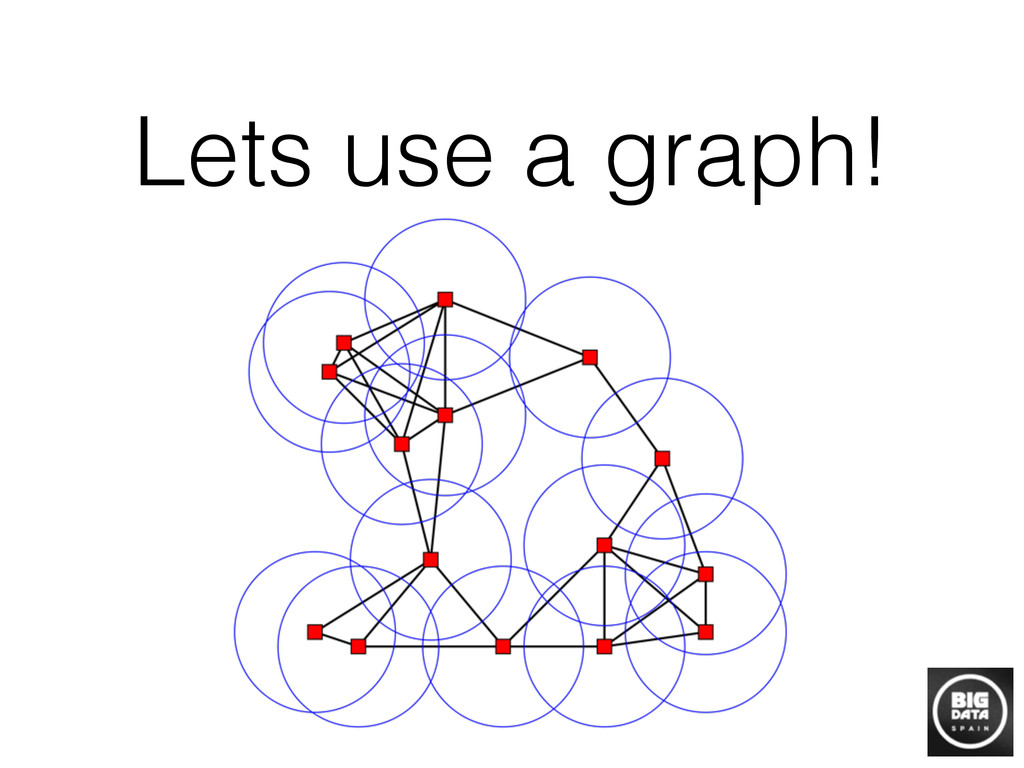
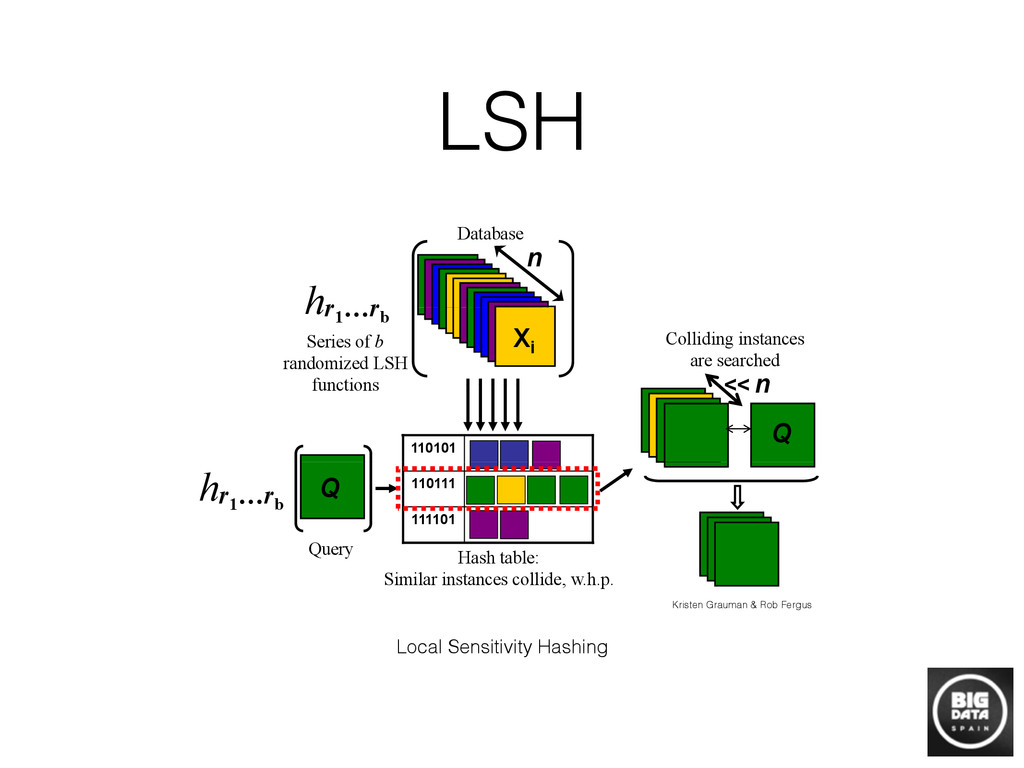
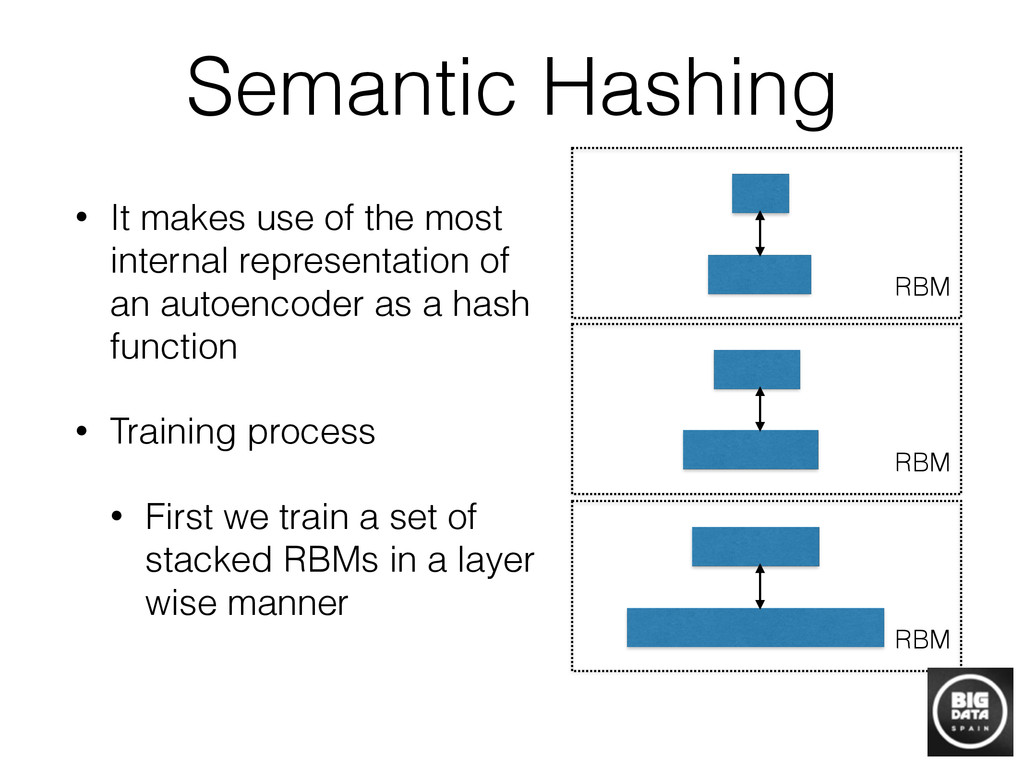
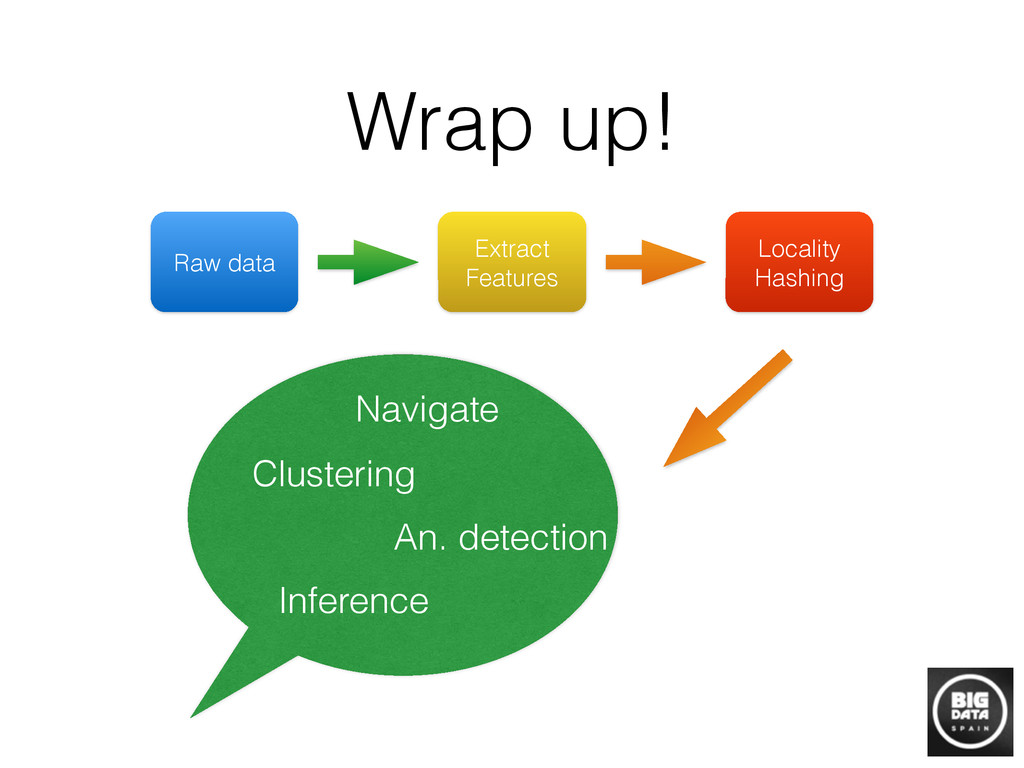
The basic challenge of a data scientist is to unveil information from raw data. Traditional machine learning algorithms have treated “pure” data analytics situations that should comply with a set of restrictions, such as access to labels, a clear prediction objective… However, the reality in practice shows that, due to the wide spread of data science nowadays, the exception is the norm and it is usual to encounter situations that depend on gathering information from raw data which lacks any kind of structure, or objective that classic approaches assume. In these situations, building a graph that encodes the information we are trying to unveil is the most intuitive place to start or even the only one feasible when we lack any field knowledge or previously stated aim. Unfortunately, building a graph when the number of nodes is huge from scratch is a challenging task computationally, and requires some approximations to make it feasible. In this review, we will talk about the most standard way of building those graphs in practice, and how to exploit them to solve data science tasks.
Session presented at Big Data Spain 2015 Conference
15th Oct 2015
Kinépolis Madrid
http://www.bigdataspain.org
Event promoted by: http://www.paradigmatecnologico.com
Abstract: http://www.bigdataspain.org/program/thu/slot-11.html#spch11.2
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}