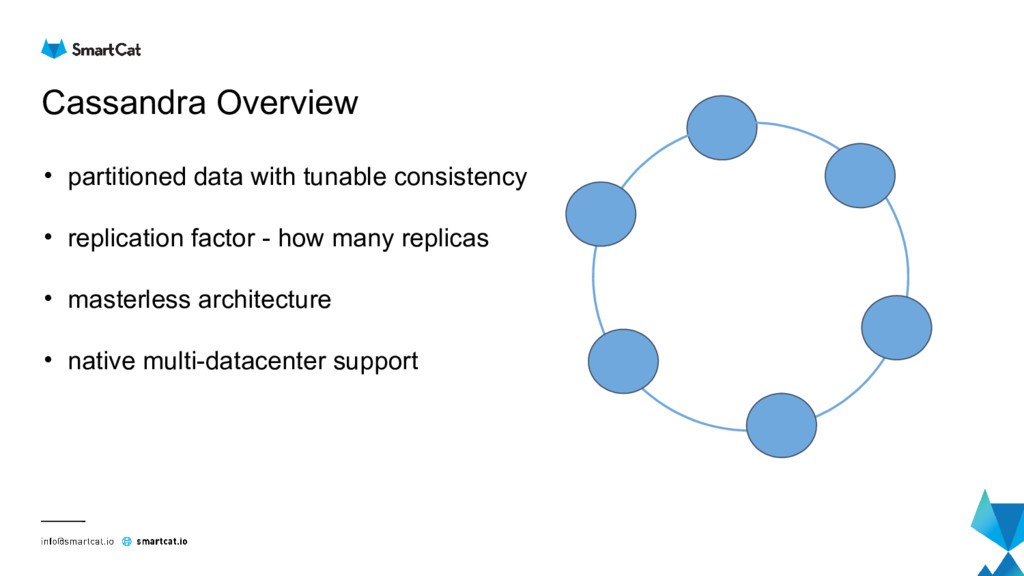
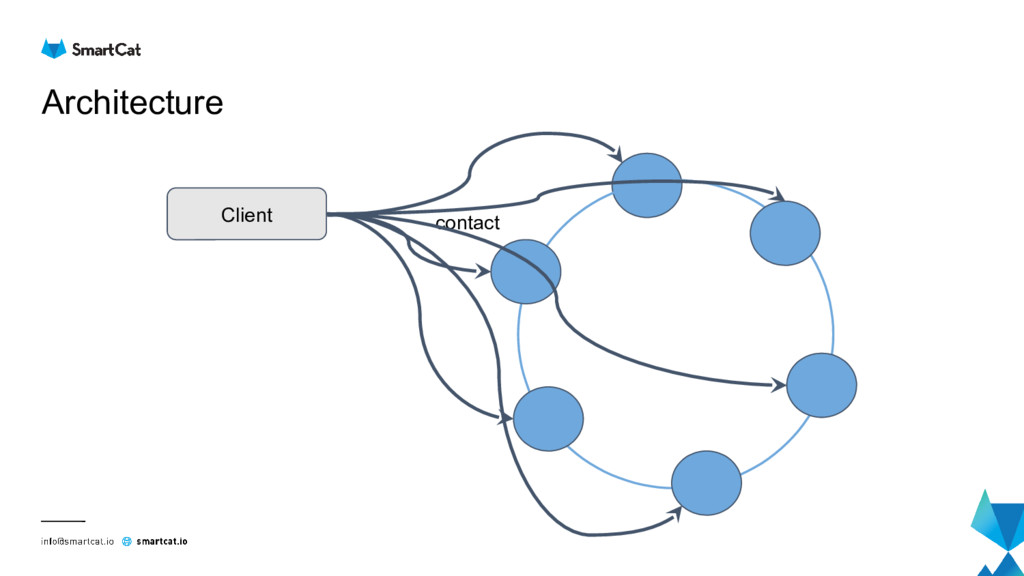
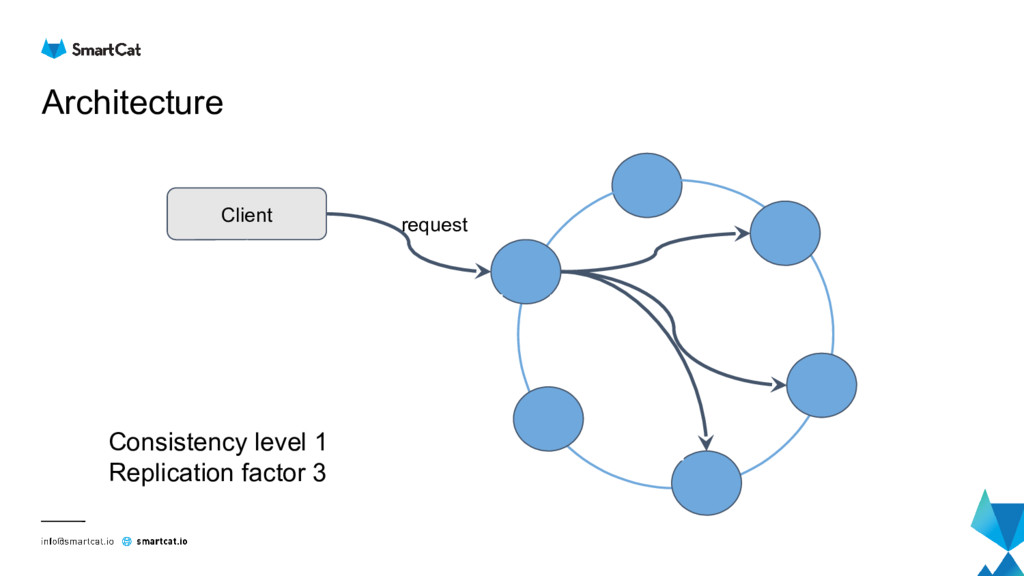
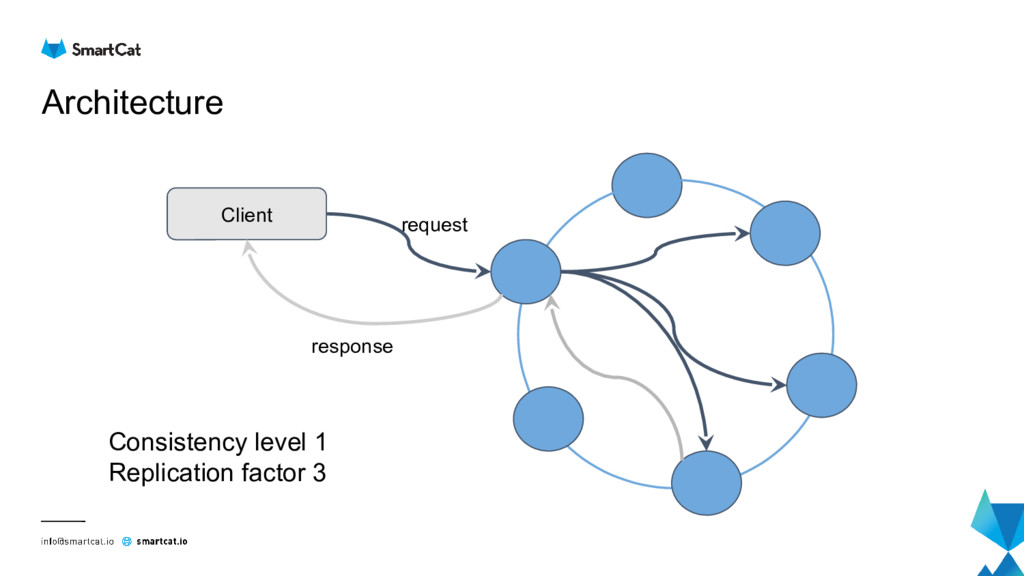
Apache Cassandra is distributed masterless column store database which is becoming mainstream for analytics and IoT data.
https://www.bigdataspain.org/2017/talk/tuning-java-driver-for-apache-cassandra
Big Data Spain 2017
November 16th - 17th Kinépolis Madrid
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
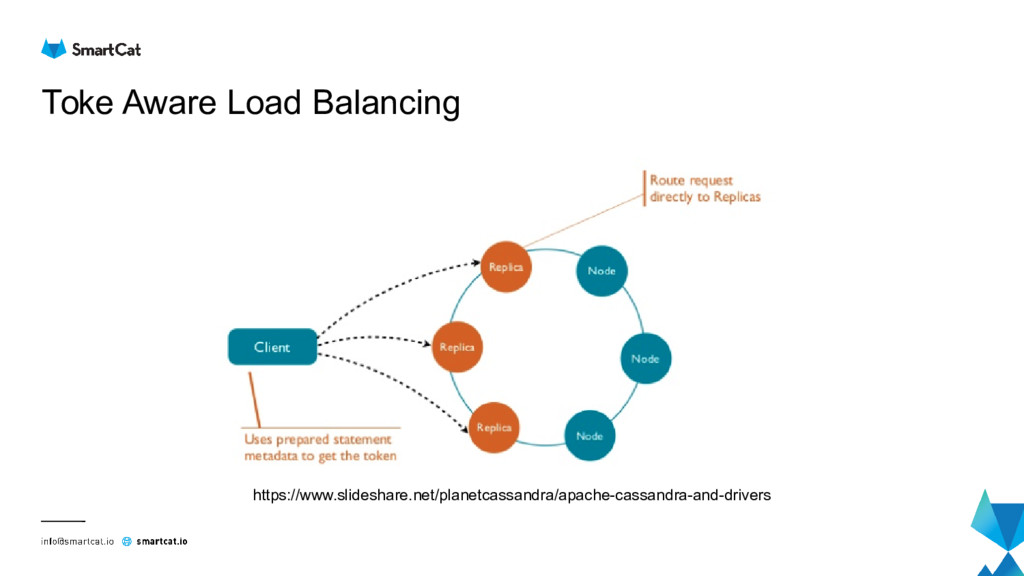{kind=link}
{kind=link}
{kind=link}
{kind=link}
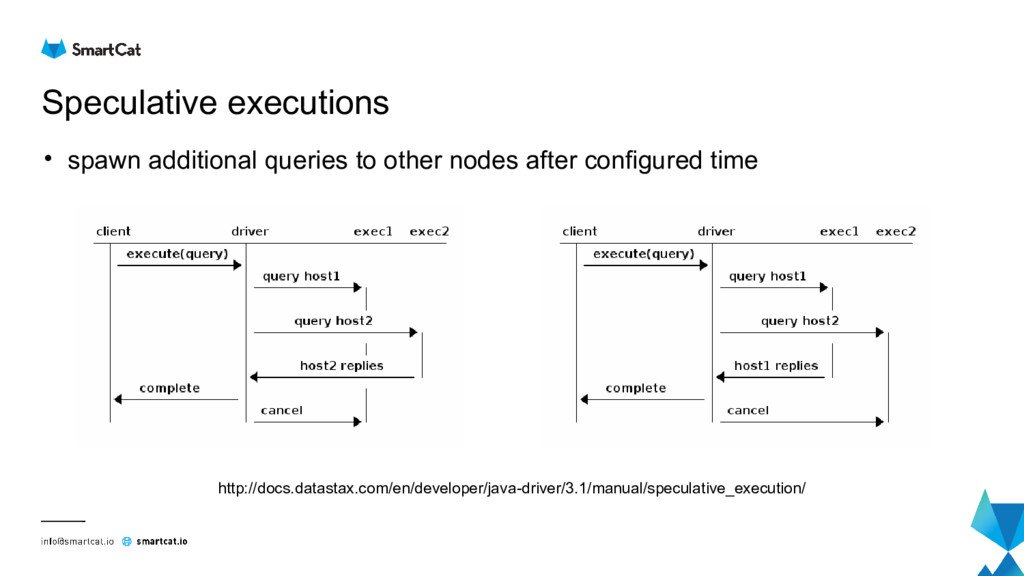{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
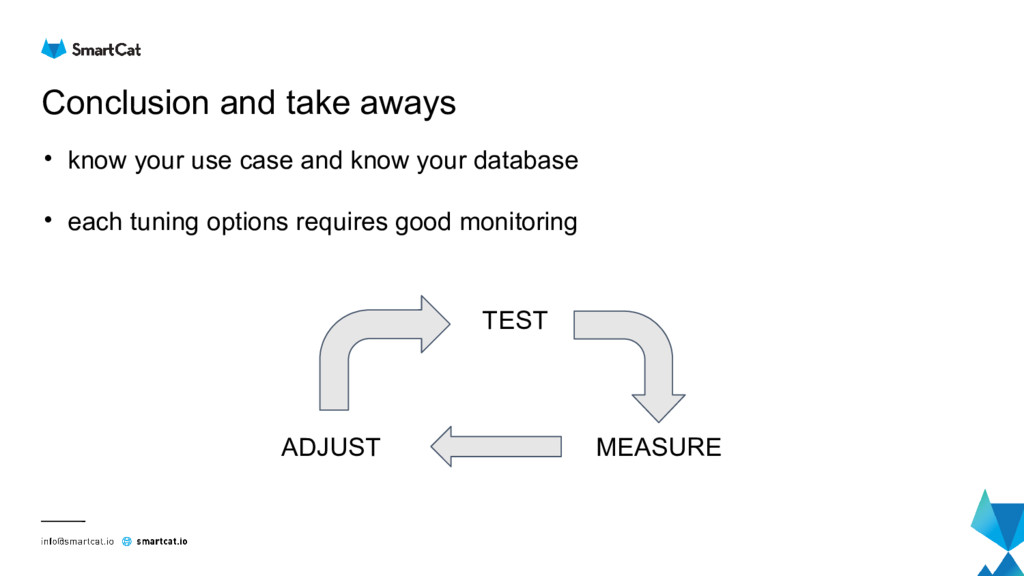{kind=link}
{kind=link}
{kind=link}
{kind=link}