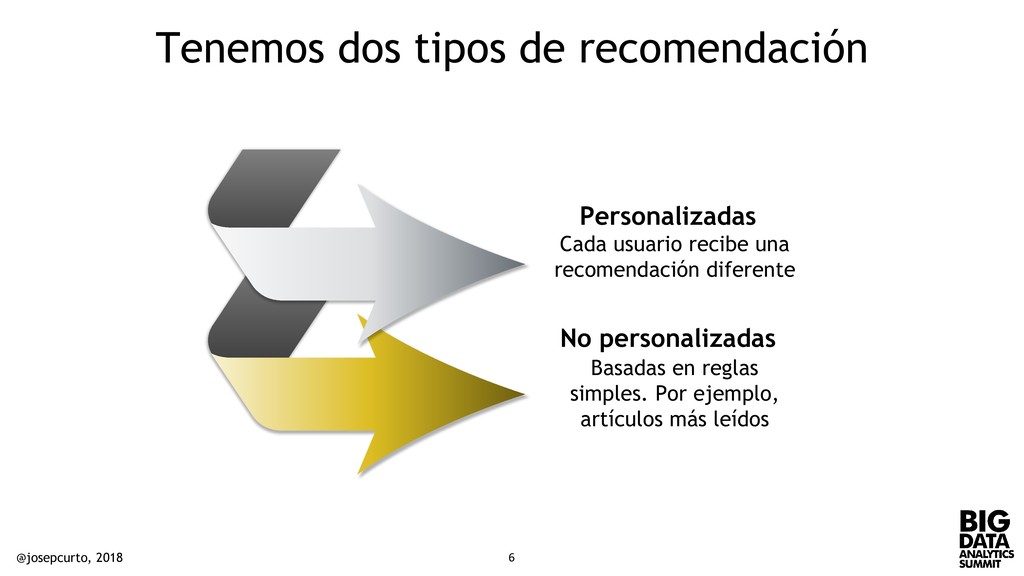
que automaticamente haga una predicción respecto las preferencias de los usuarios La meta • Comportamiento pasado • Relaciones otros usuarios • Atributos productos/servicios • Similitud productos/servicios • Contexto Fundamentado en @josepcurto, 2018
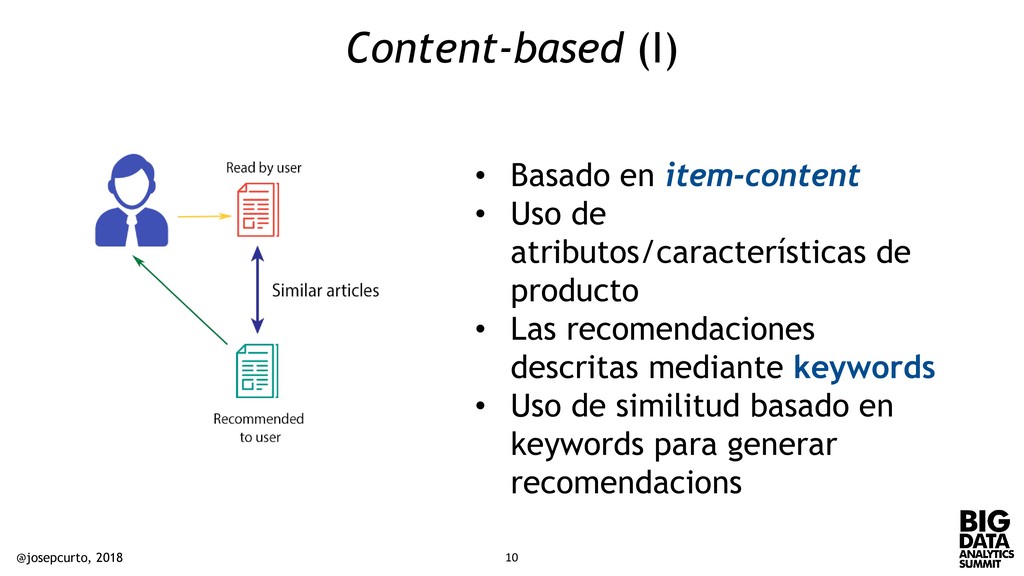
atributos/características de producto • Las recomendaciones descritas mediante keywords • Uso de similitud basado en keywords para generar recomendacions @josepcurto, 2018
• No cold-start o sparsity • Posible recomendar novedad, popularidad o unicidad • Proporciona explicaciones Inconvenientes • Requiere atributos por producto codificados de forma adecuada • La extracción de atributos puedes ser complicada • No vinculada a los gustos reales • Overfitting @josepcurto, 2018
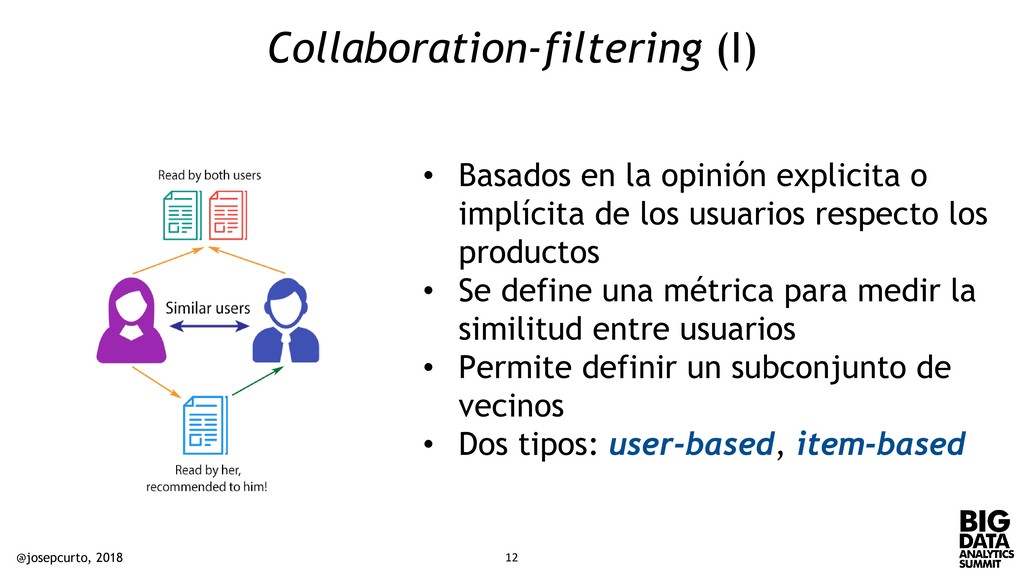
implícita de los usuarios respecto los productos • Se define una métrica para medir la similitud entre usuarios • Permite definir un subconjunto de vecinos • Dos tipos: user-based, item-based @josepcurto, 2018
sin estructura interna • Produce en la mayoría de casos resultados suficientemente buenos Inconvenientes • Es necesaria una cantidad importante de opiniones (cold start) • Requiere que los productos estén estandarizados • Asume que el comportamiento previo define el actual @josepcurto, 2018
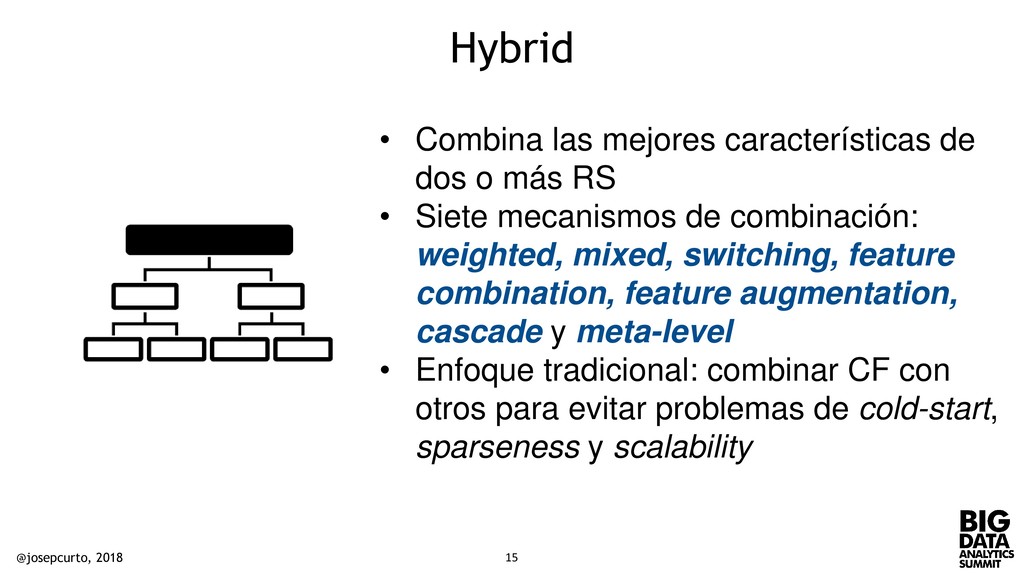
más RS • Siete mecanismos de combinación: weighted, mixed, switching, feature combination, feature augmentation, cascade y meta-level • Enfoque tradicional: combinar CF con otros para evitar problemas de cold-start, sparseness y scalability @josepcurto, 2018
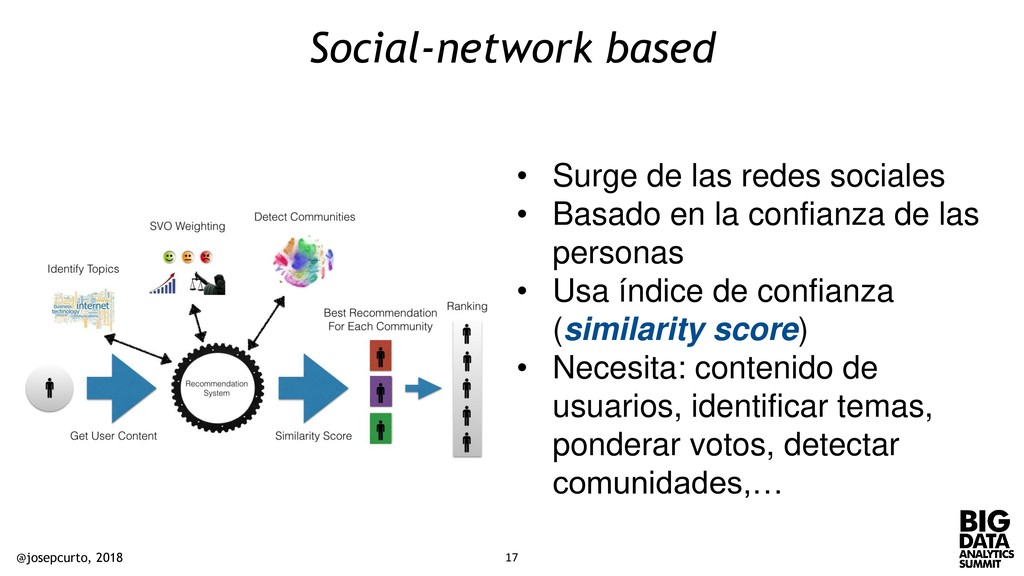
Basado en la confianza de las personas • Usa índice de confianza (similarity score) • Necesita: contenido de usuarios, identificar temas, ponderar votos, detectar comunidades,… @josepcurto, 2018
escoger la mejor elección para el grupo? • Dos estrategias: Profiles aggregation, Recommendations aggregation • Teorema de Arrows: there is no fair voting system • Uso frequente de Kemeny- Optimal aggregation/heuristics: Borda count, Spearman footrule distance, Average, Least misery, Random
es la major opción independiente • Depende del dominio y del problema • Hybrid se está imponiendo para mejorar CF, CB y KB • Lo importante: data processing, outliers, denoising, borrar resultados obvios, reducción de dimensionalidad,… @josepcurto, 2018
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Gracias! Josep Curto | @josepcurto | [email protected]](https://files.speakerdeck.com/presentations/87ad9b2bddbe401a91c03ddd20f40c19/slide_21.jpg){kind=link}