la Física Experimental, concretamente la Astrofísica • Ingeniería de software desde hace mas de 20 años • En los últimos 8 años nuevas arquitecturas de datos basadas en tecnología Big Data. • 5 años en los ecosistemas de innovación y emprendimiento donde cree una startup en Big Data & Analytics • Actualmente en Accenture como manager y arquitecto Big Data y de soluciones analíticas • En este último año estoy liderando el área de Inteligencia Artificial en Digital Delivery Me puedes encontrar como [email protected]
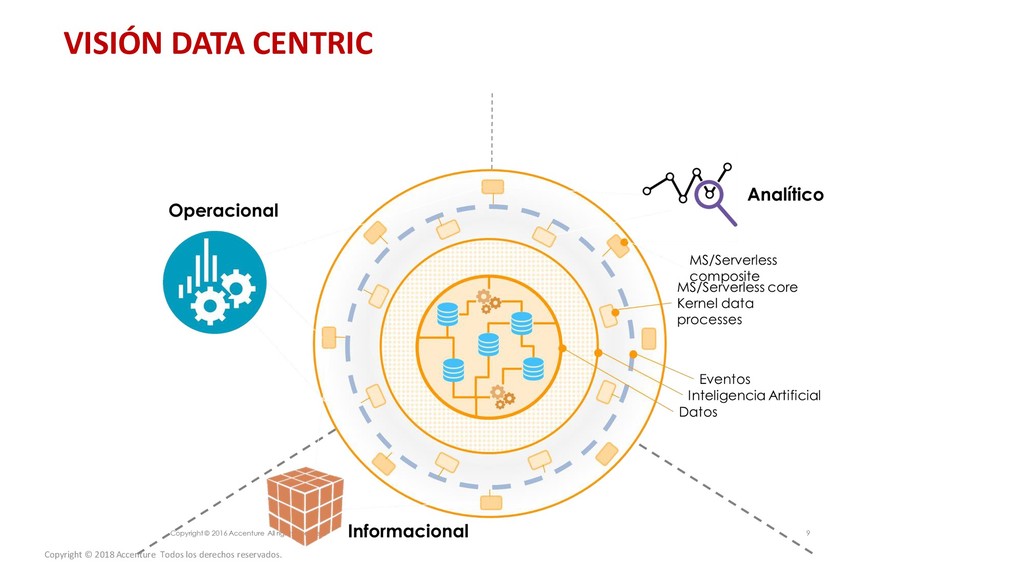
de las arquitecturas de datos no siempre sigue las mejores prácticas en cuanto a modelado y arquitectura. Las herramientas de exploración de datos proporcionan funcionalidades que permiten a los analistas buscar y analizar, pero requieren un conocimiento detallado del modelo de datos. Las mejoras en la interacción usuario-herramienta pueden suponer un cambio radical en la productividad y eficiencia de las compañías con un objetivo “Data Centric”. El uso del lenguaje natural es actualmente la forma más directa de comunicación, haciendo mas preciso y productivo el análisis de datos
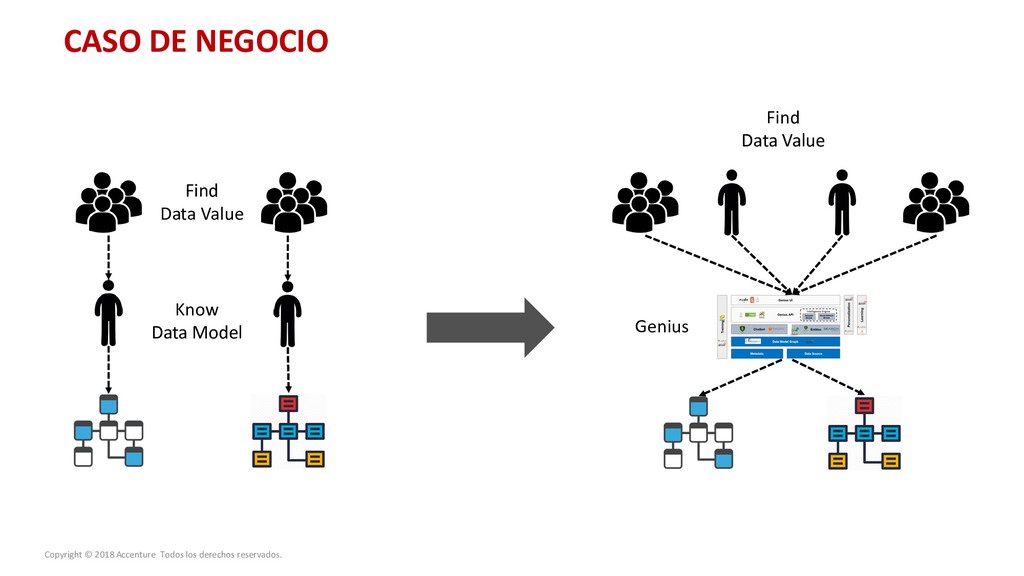
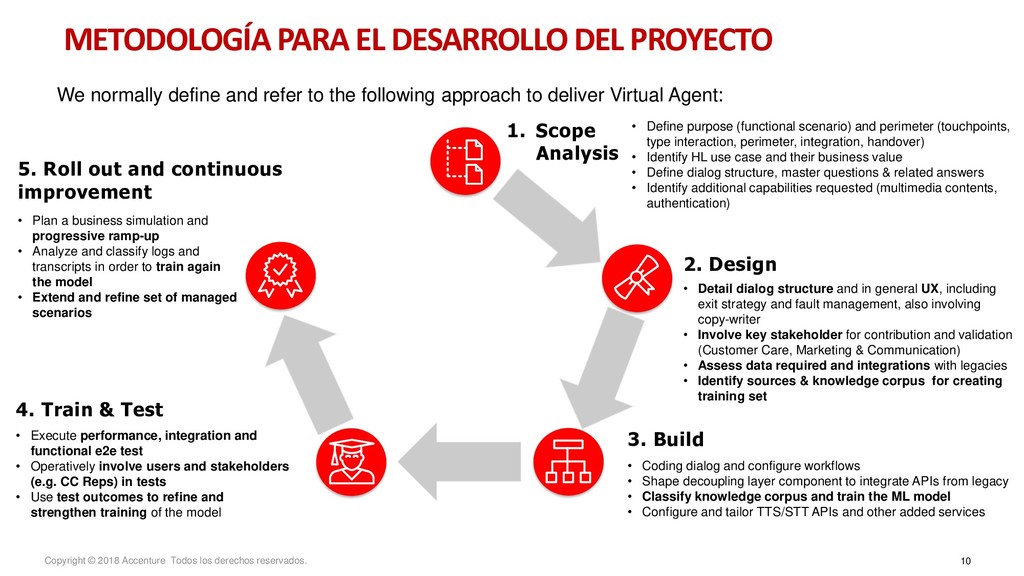
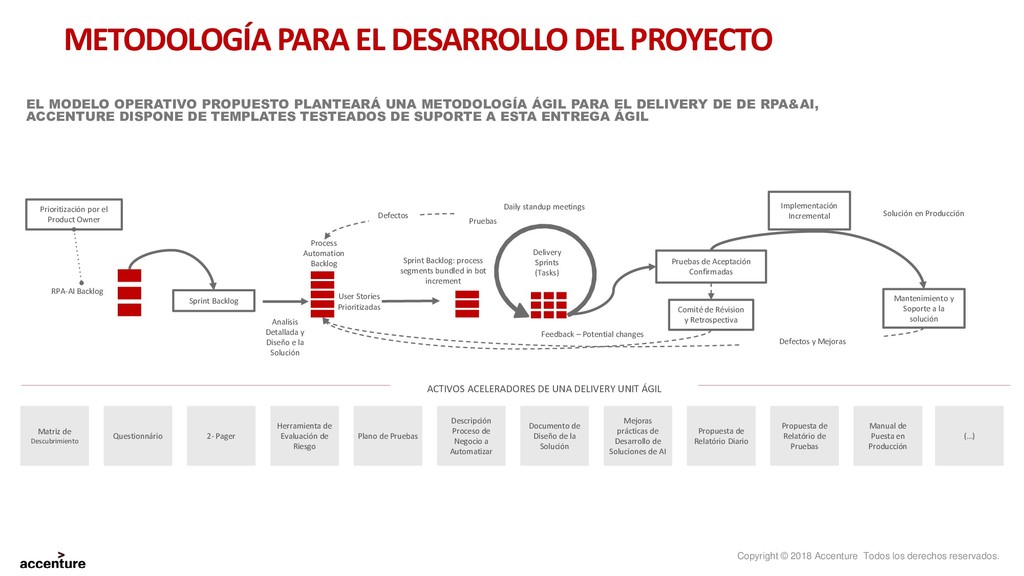
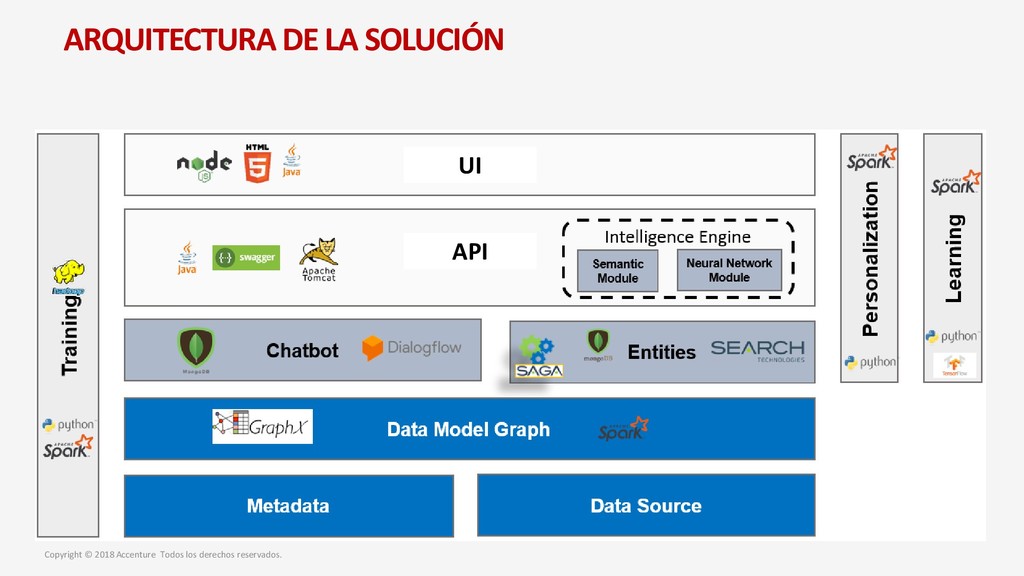
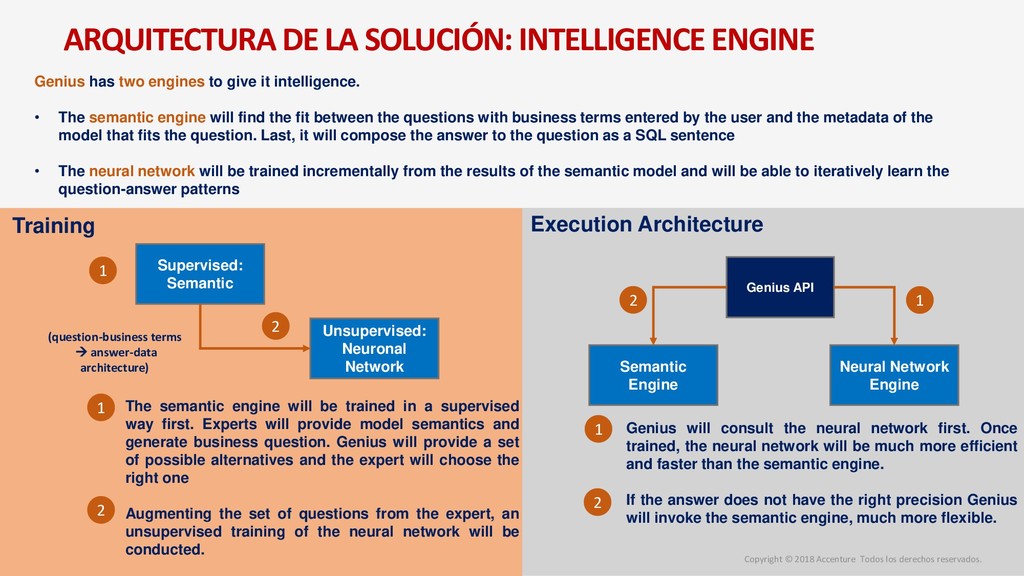
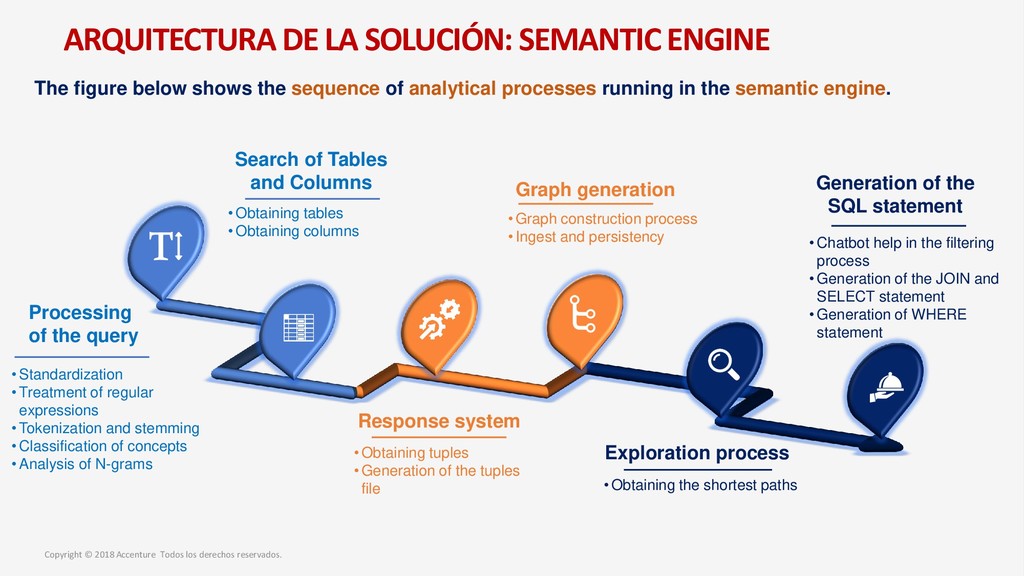
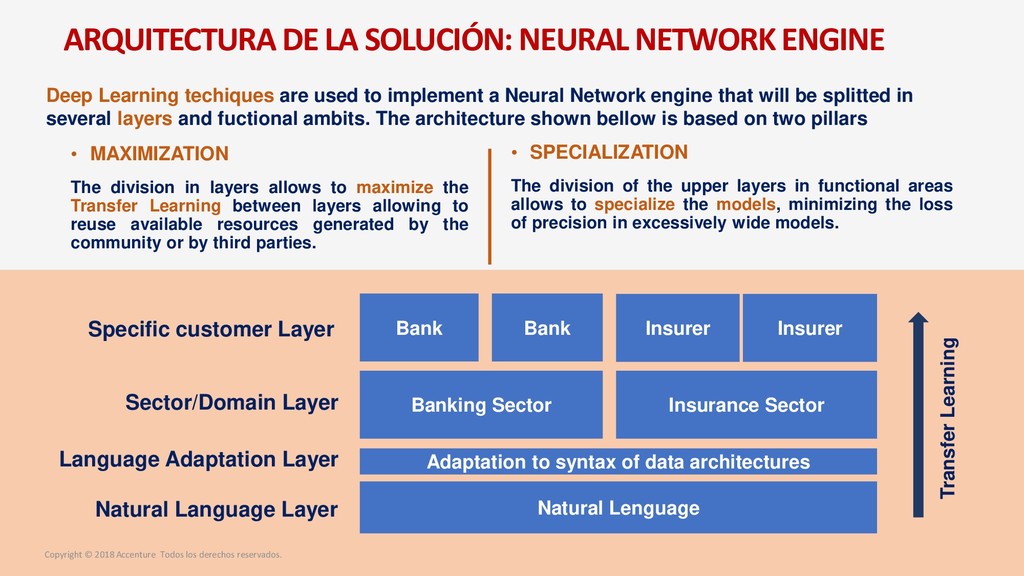
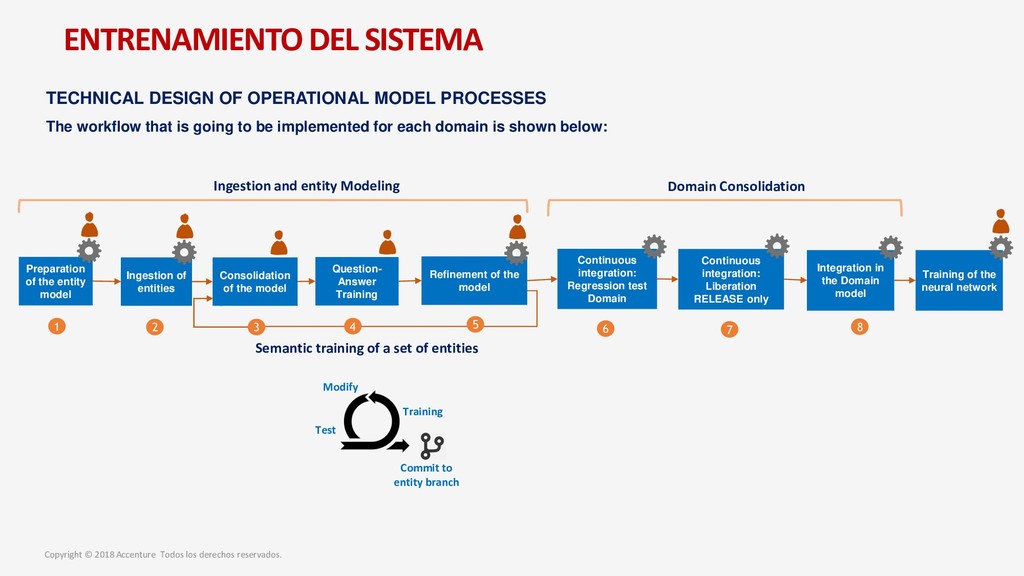
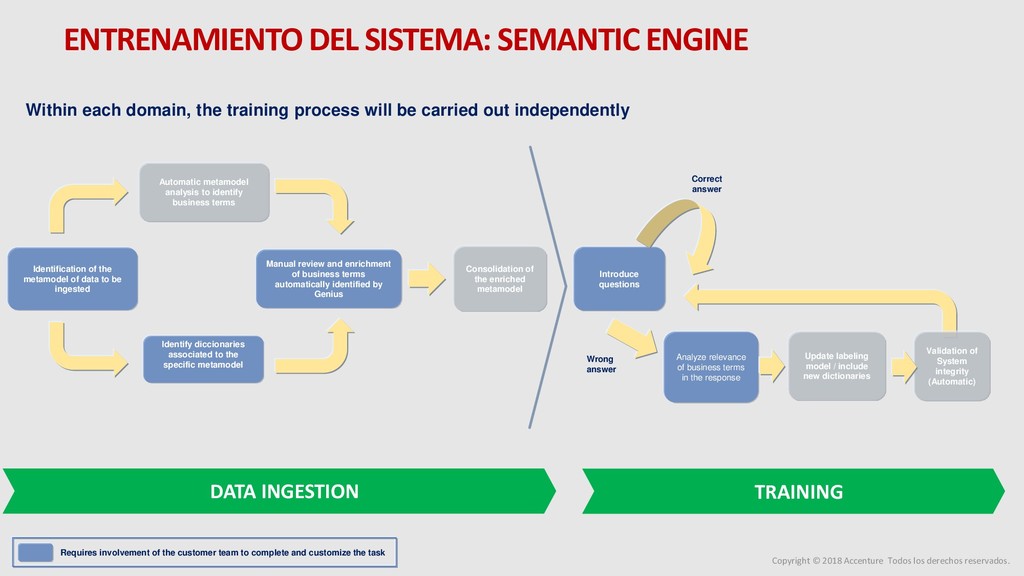
para un nuevo Data Discovey Caso de Negocio Metodología para el desarrollo del proyecto Arquitectura de la solución Entrenamiento del sistema Modelo Operativo
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![GRACIAS! ALGUNA PREGUNTA? Puedes encontrarme como: [email protected]](https://files.speakerdeck.com/presentations/edba4bec44f54dd19a70ee3e2117ad53/slide_18.jpg){kind=link}