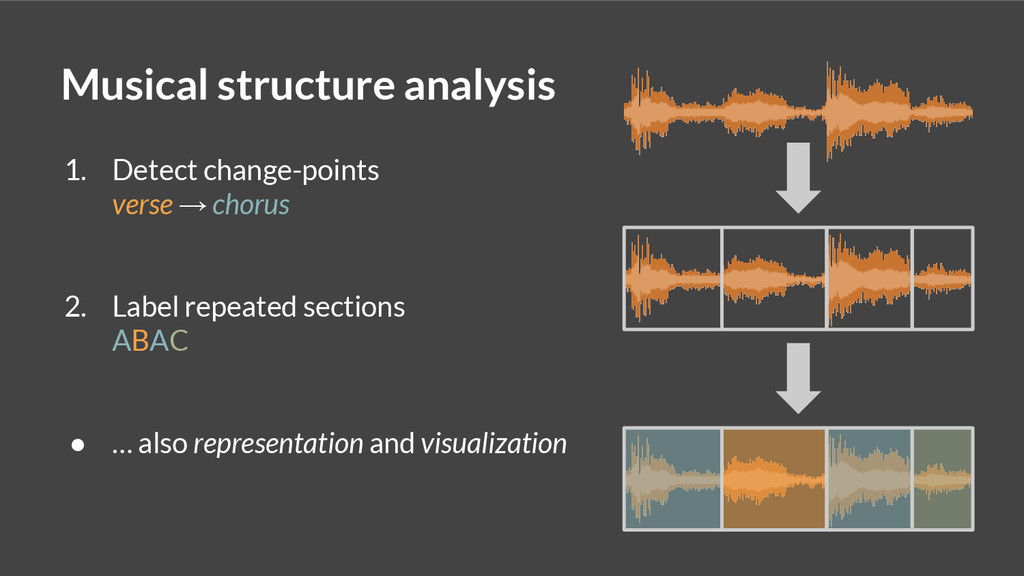
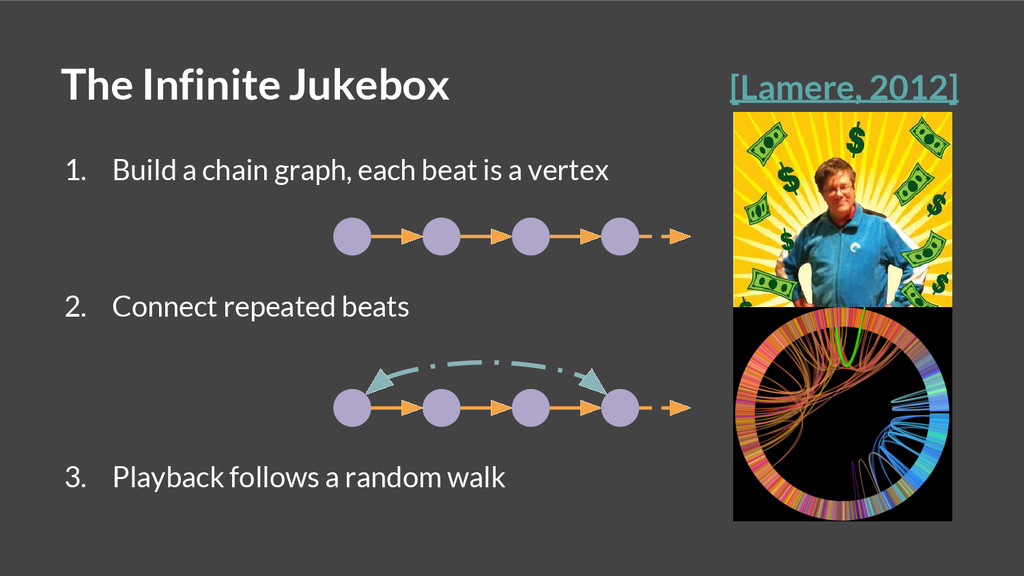
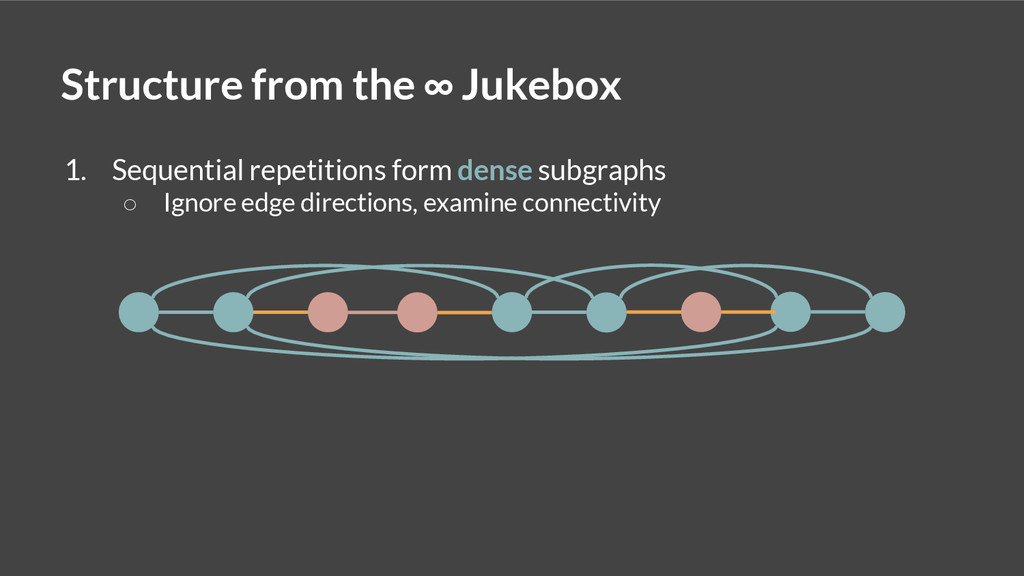
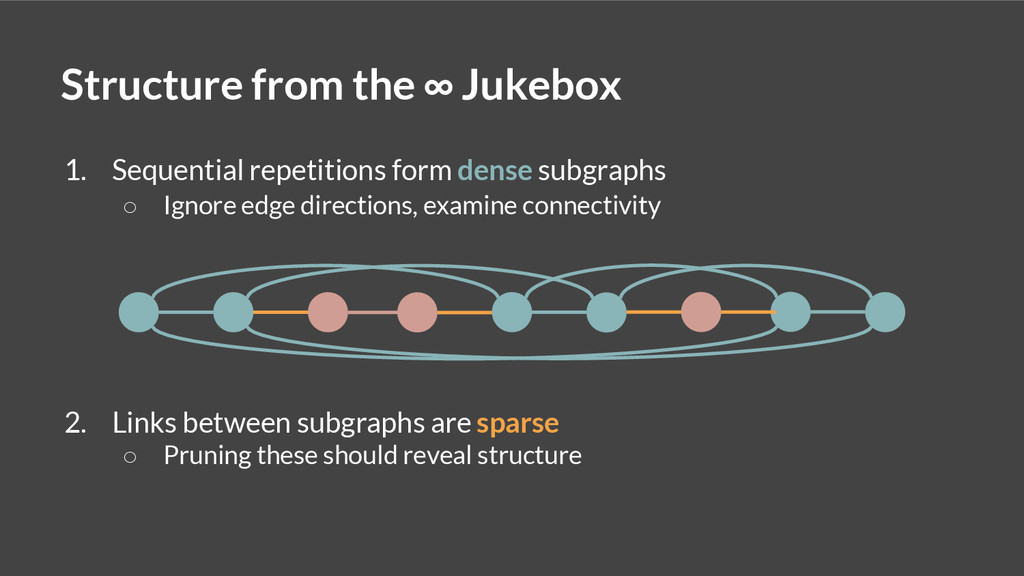
This talk describes a spectral clustering algorithm, based upon a theoretical model of the Infinite Jukebox, which can encode and expose musical structure at multiple levels of granularity.
The paper corresponding to this talk was first presented at ISMIR 2014 in Taipei.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
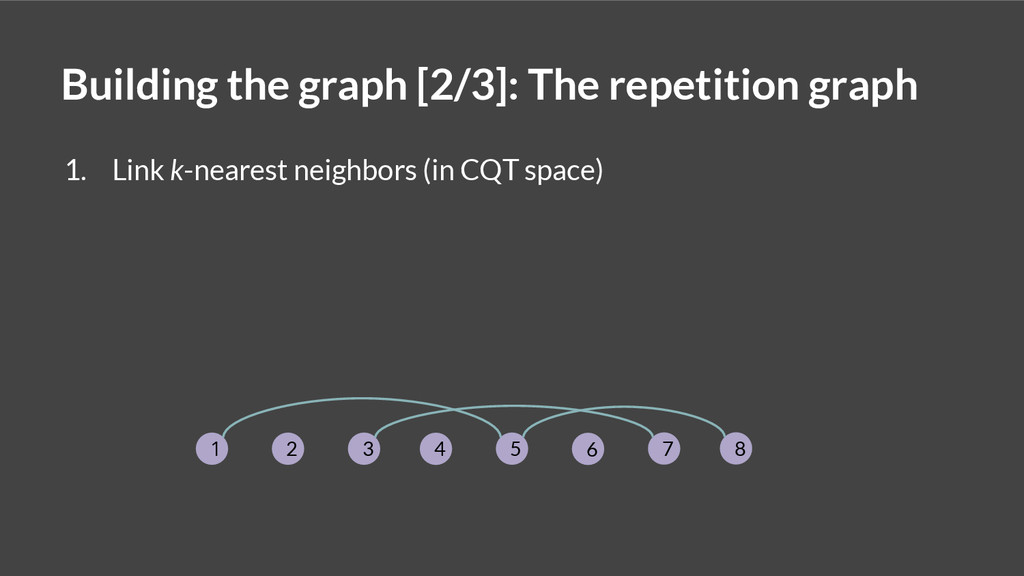
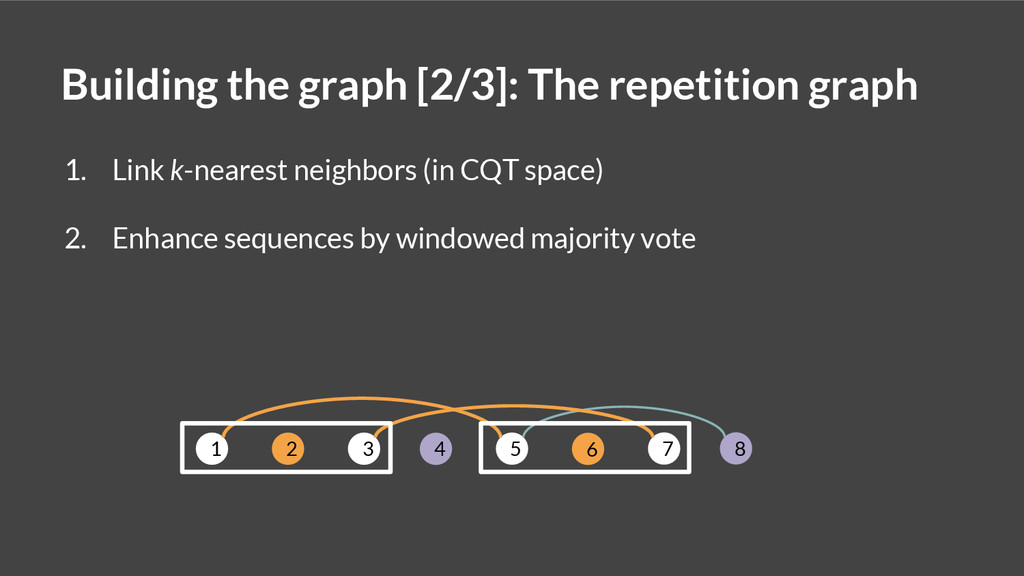
![Building the graph [1/3]: The local graph 1. Add a](https://files.speakerdeck.com/presentations/11bc6a1041f001324e426a6eabfd15bd/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Building the graph [3/3]: The combination 1. Take a weighted](https://files.speakerdeck.com/presentations/11bc6a1041f001324e426a6eabfd15bd/slide_13.jpg){kind=link}
![Building the graph [3/3]: The combination 1. Take a weighted](https://files.speakerdeck.com/presentations/11bc6a1041f001324e426a6eabfd15bd/slide_14.jpg){kind=link}
![Building the graph [3/3]: The combination 1. Take a weighted](https://files.speakerdeck.com/presentations/11bc6a1041f001324e426a6eabfd15bd/slide_15.jpg){kind=link}
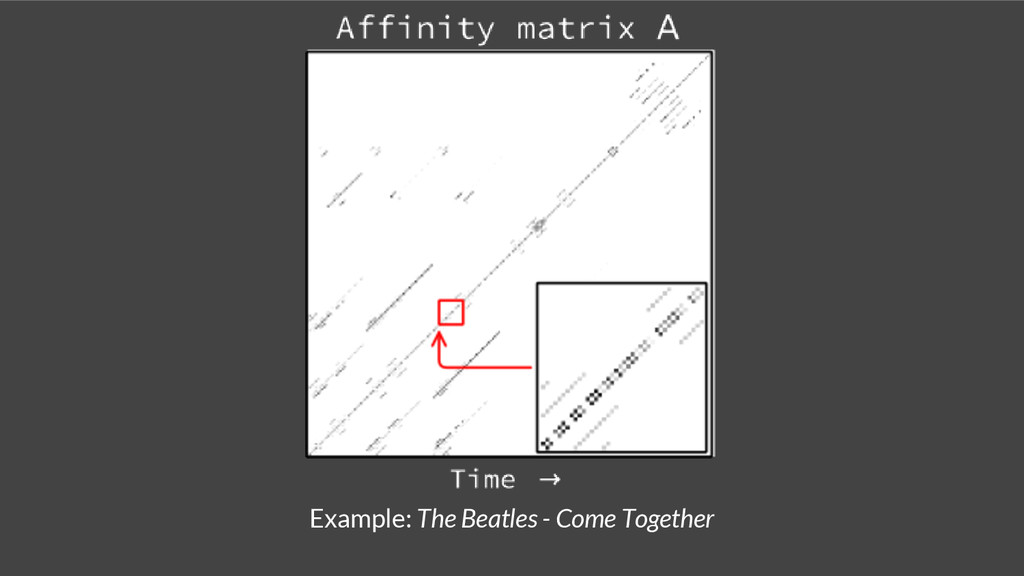{kind=link}
{kind=link}
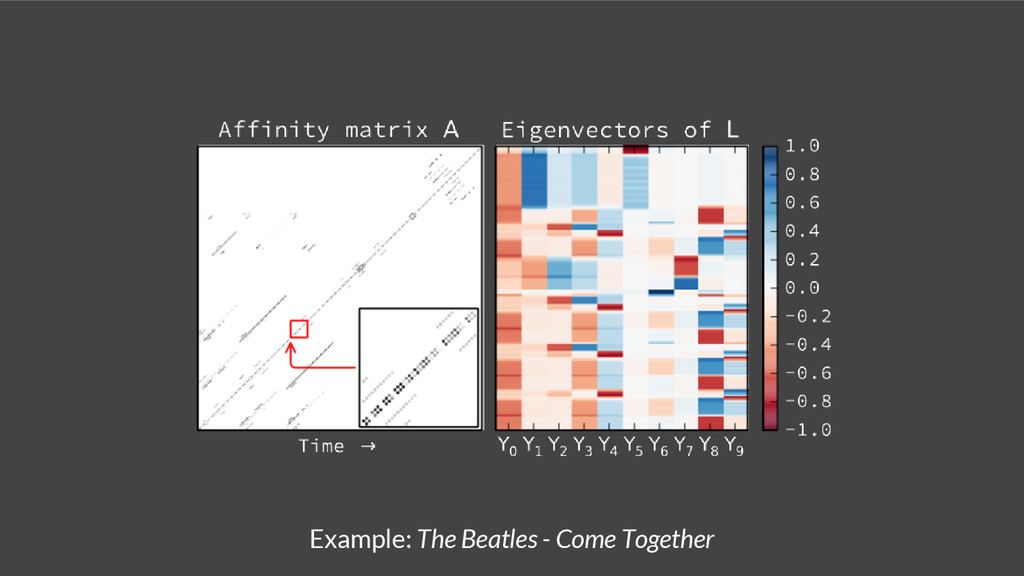{kind=link}
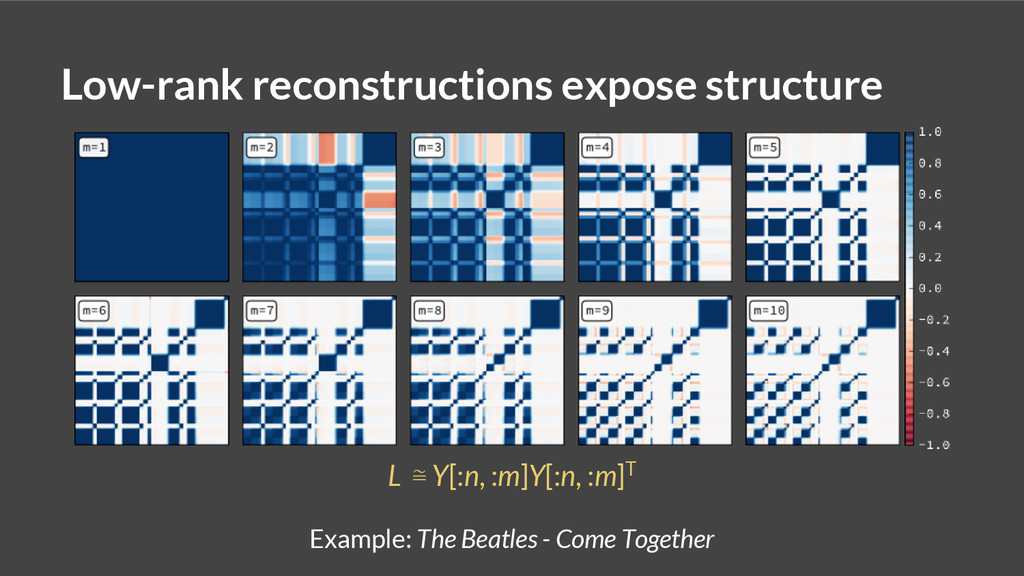{kind=link}
{kind=link}
{kind=link}
{kind=link}
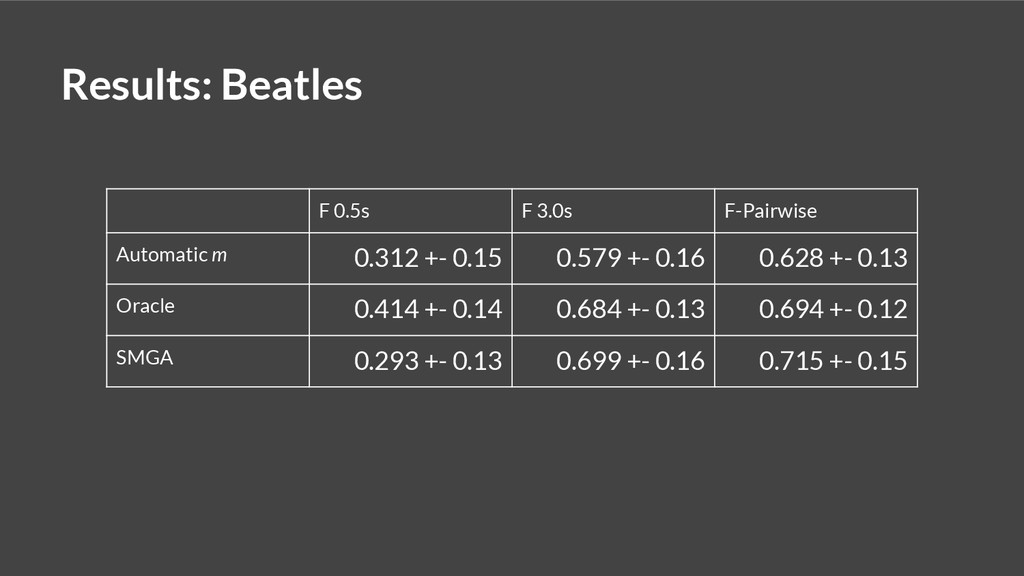{kind=link}
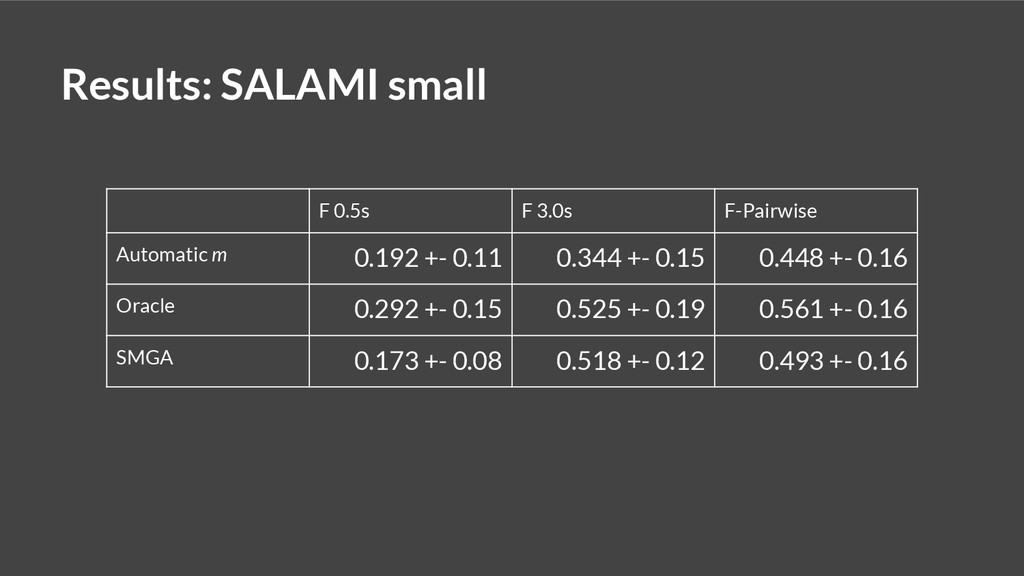{kind=link}
{kind=link}
{kind=link}
![Thanks! [email protected] https://github.com/bmcfee/laplacian_segmentation https://github.com/urinieto/msaf](https://files.speakerdeck.com/presentations/11bc6a1041f001324e426a6eabfd15bd/slide_27.jpg){kind=link}