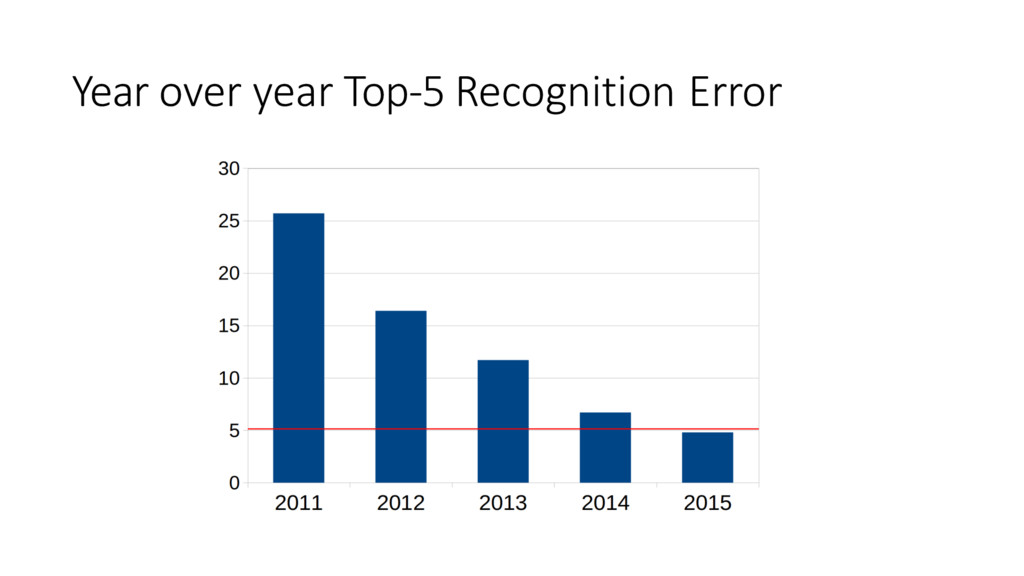
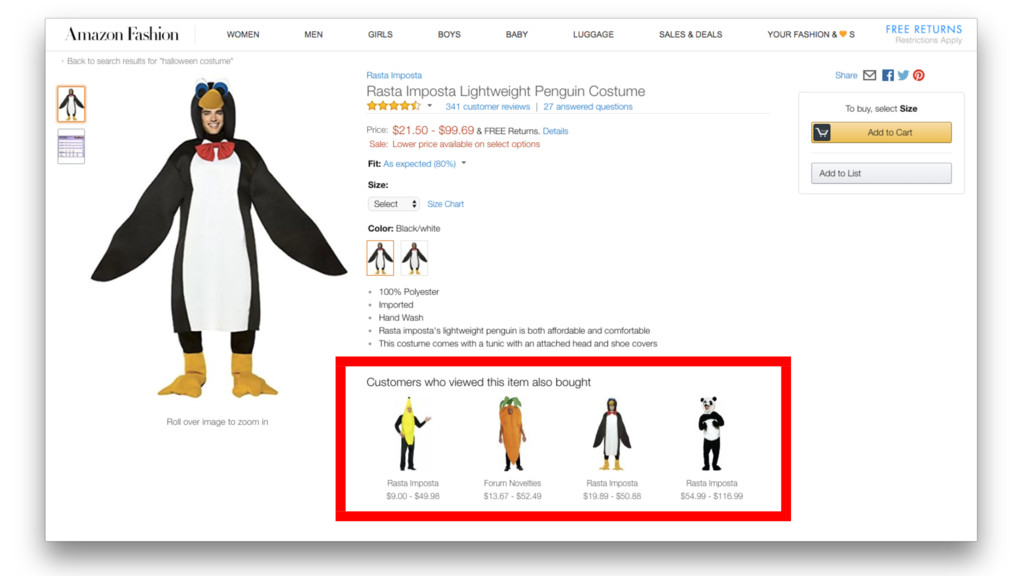
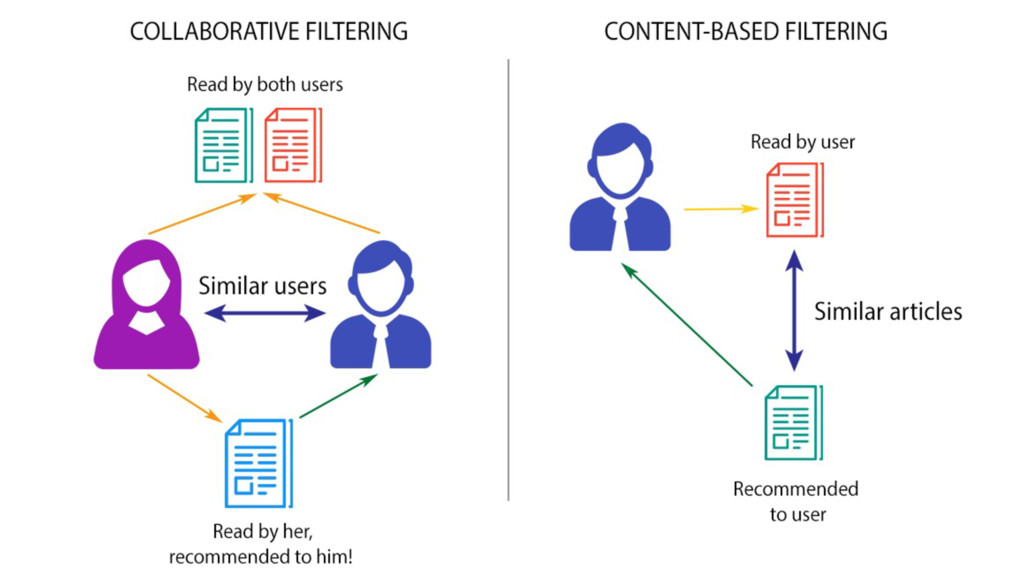
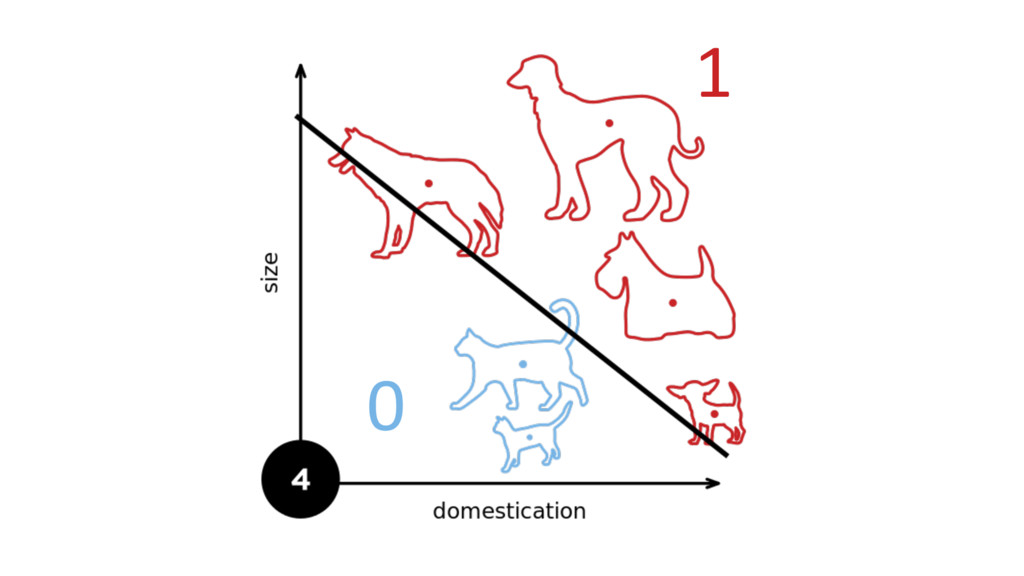
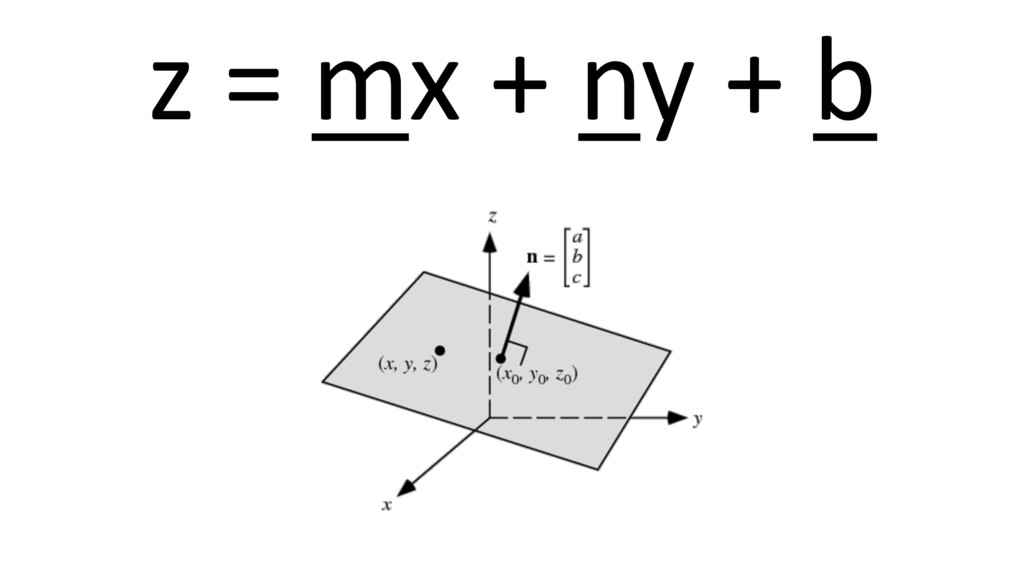
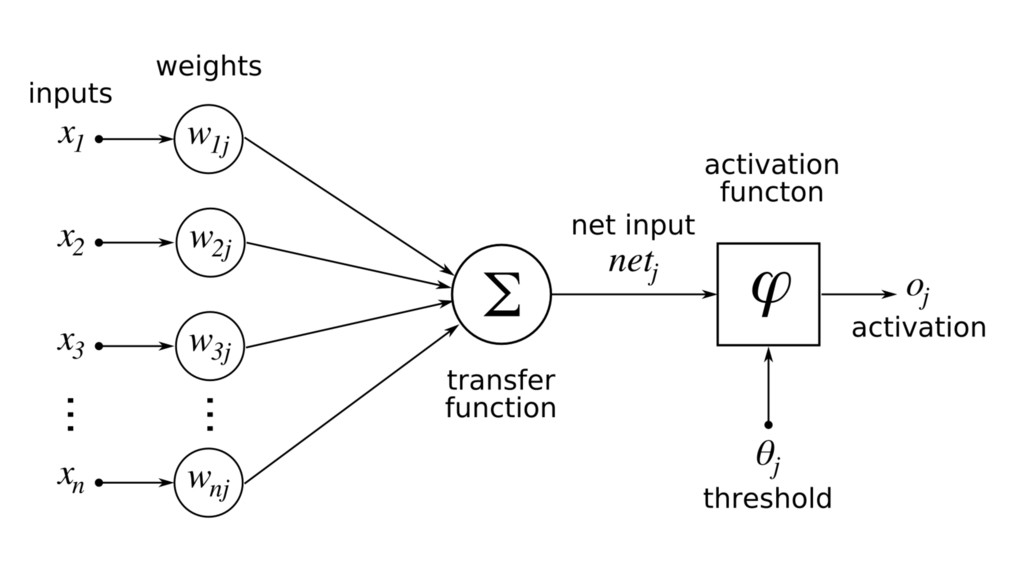
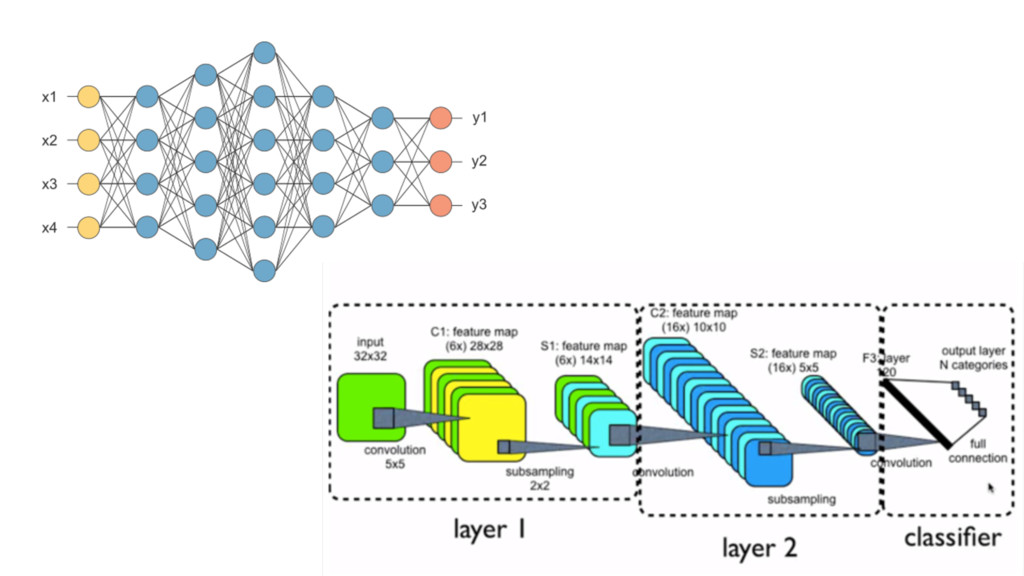
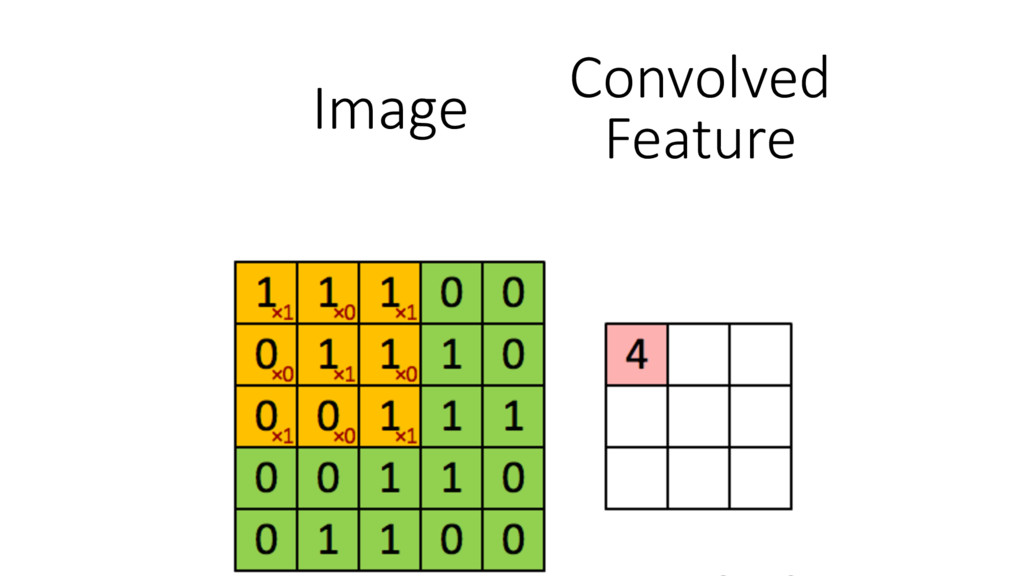
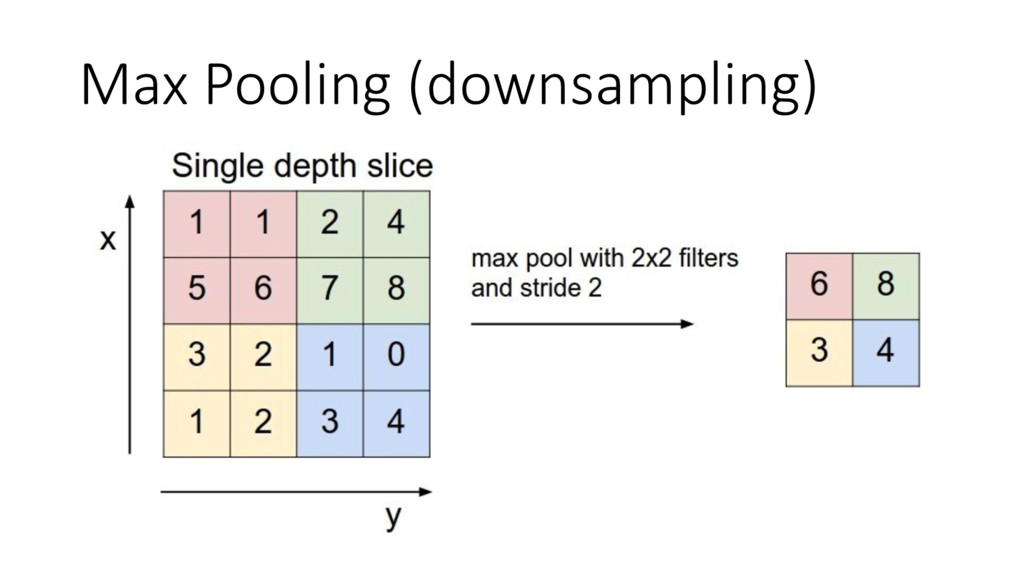
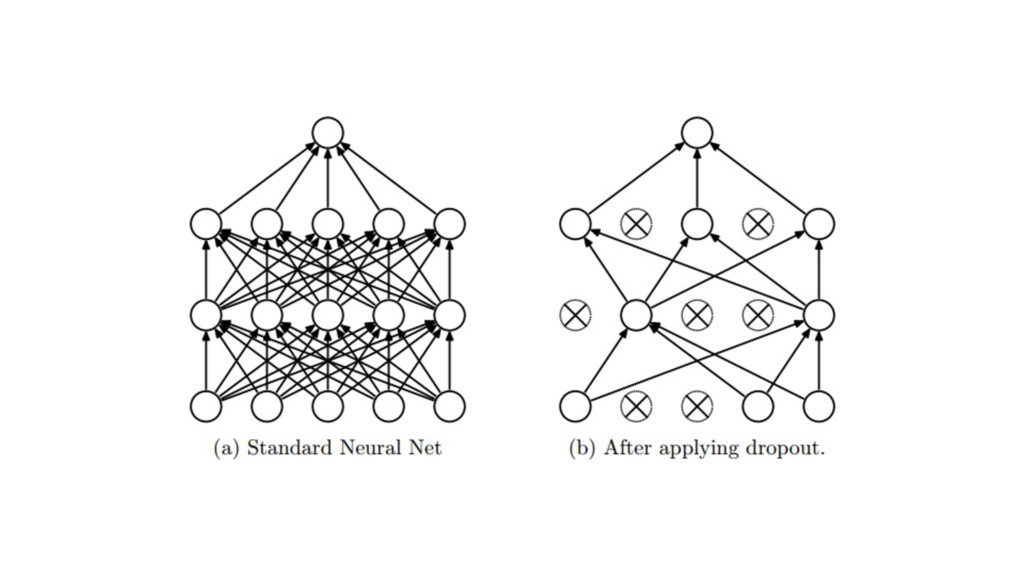
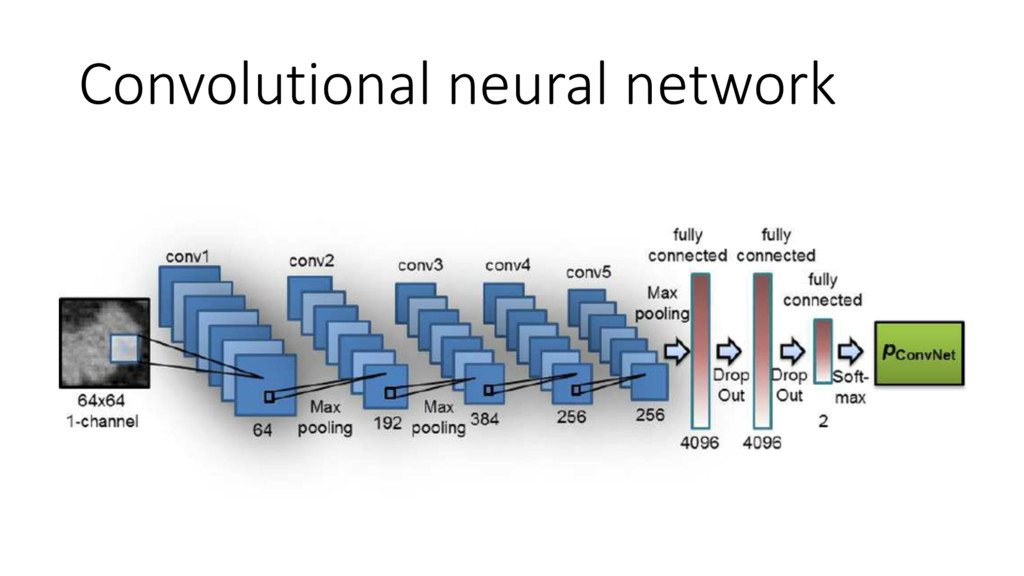
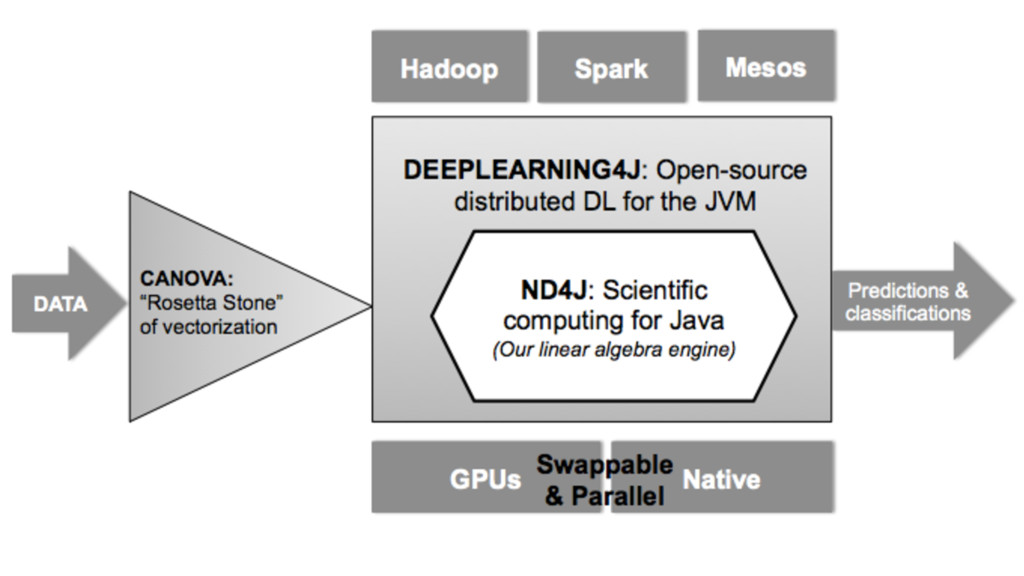
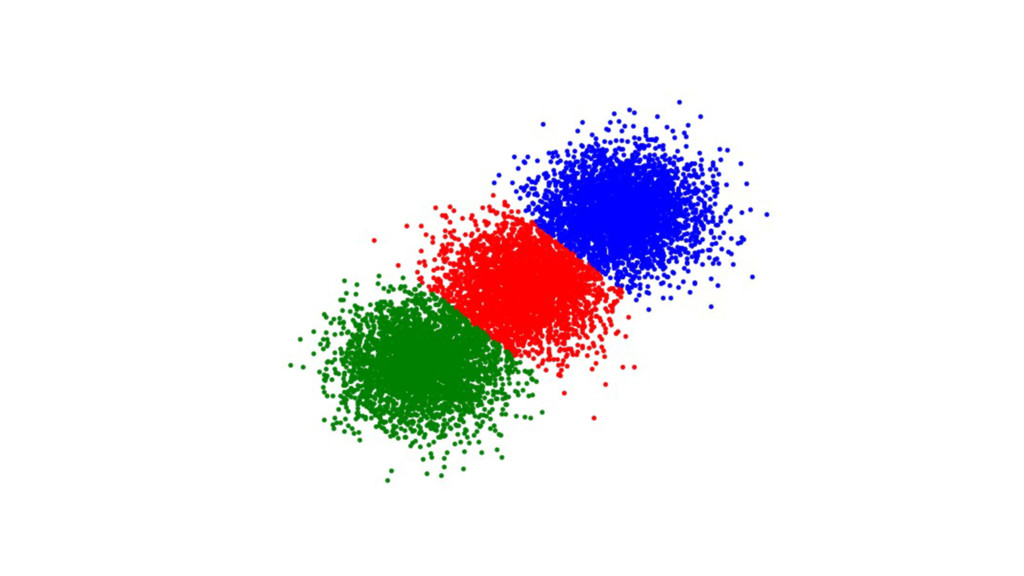
Machine learning has recently made enormous progress in a variety of real-world applications, such as computer vision, speech recognition and language processing. And now, Java has the libraries to help you apply these techniques to large data sets, with new Spark-based tools like deeplearning4java (DL4J). In this workshop, you will learn the basic building blocks for deep learning: gradient descent, backpropogation, model training and evaluation. We'll cover how to build and train supervised machine learning models, give you an overview of deep learning and show you how to recognize handwritten digits. You will gain an intuition for how to develop custom models to discover new insights and untapped patterns big data. No prior experience in machine learning is required.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
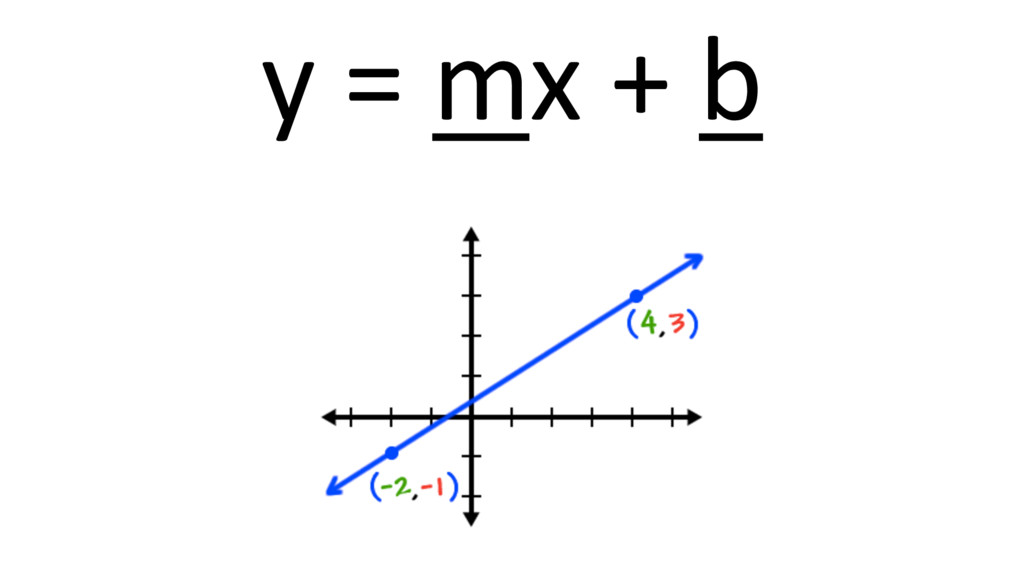{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
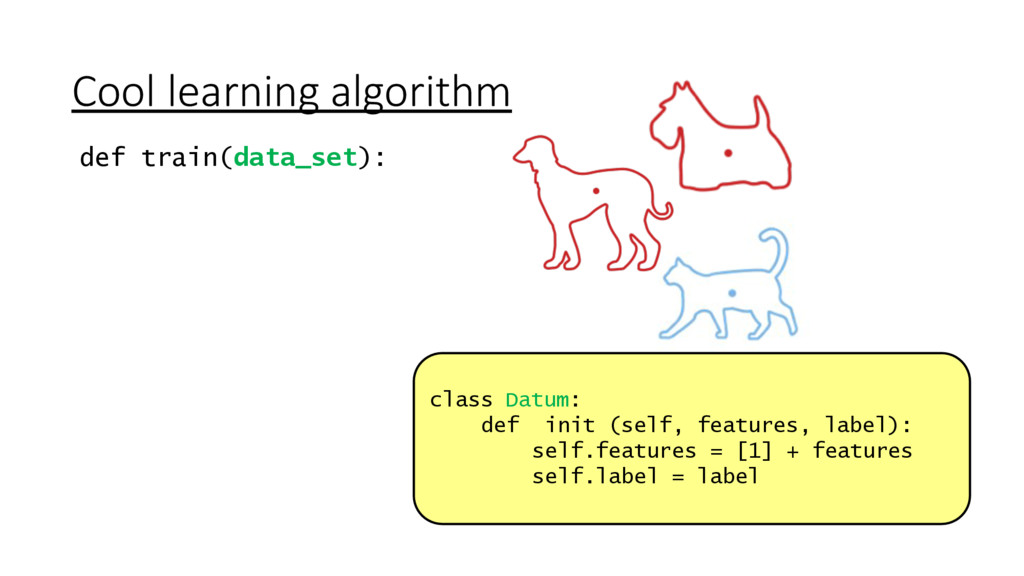{kind=link}
![Cool learning algorithm def train(data_set): weights = [0] * len(data_set[0].features)](https://files.speakerdeck.com/presentations/89353c80832a4d37a6a8d35a53ff3453/slide_59.jpg){kind=link}
![Cool learning algorithm def train(data_set): weights = [0] * len(data_set[0].features)](https://files.speakerdeck.com/presentations/89353c80832a4d37a6a8d35a53ff3453/slide_60.jpg){kind=link}
![Cool learning algorithm def train(data_set): weights = [0] * len(data_set[0].features)](https://files.speakerdeck.com/presentations/89353c80832a4d37a6a8d35a53ff3453/slide_61.jpg){kind=link}
![Cool learning algorithm def train(data_set): weights = [0] * len(data_set[0].features)](https://files.speakerdeck.com/presentations/89353c80832a4d37a6a8d35a53ff3453/slide_62.jpg){kind=link}
![Cool learning algorithm def train(data_set): weights = [0] * len(data_set[0].features)](https://files.speakerdeck.com/presentations/89353c80832a4d37a6a8d35a53ff3453/slide_63.jpg){kind=link}
![weights zip(weights, item.features)] Cool learning algorithm 1 i1 i2 in](https://files.speakerdeck.com/presentations/89353c80832a4d37a6a8d35a53ff3453/slide_64.jpg){kind=link}
![Cool learning algorithm def train(data_set): weights = [0] * len(data_set[0].features)](https://files.speakerdeck.com/presentations/89353c80832a4d37a6a8d35a53ff3453/slide_65.jpg){kind=link}
![Cool learning algorithm def train(data_set): weights = [0] * len(data_set[0].features)](https://files.speakerdeck.com/presentations/89353c80832a4d37a6a8d35a53ff3453/slide_66.jpg){kind=link}
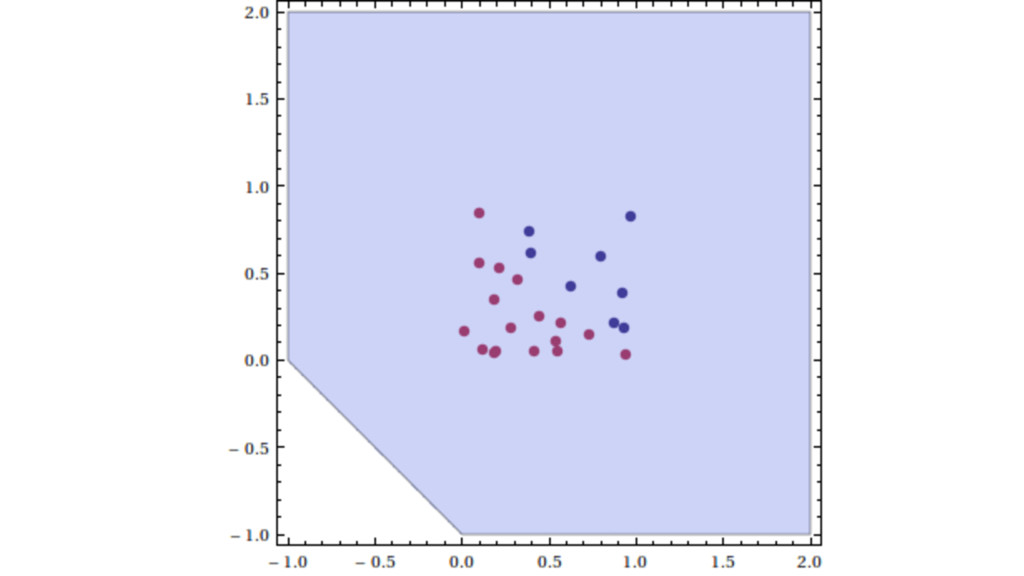{kind=link}
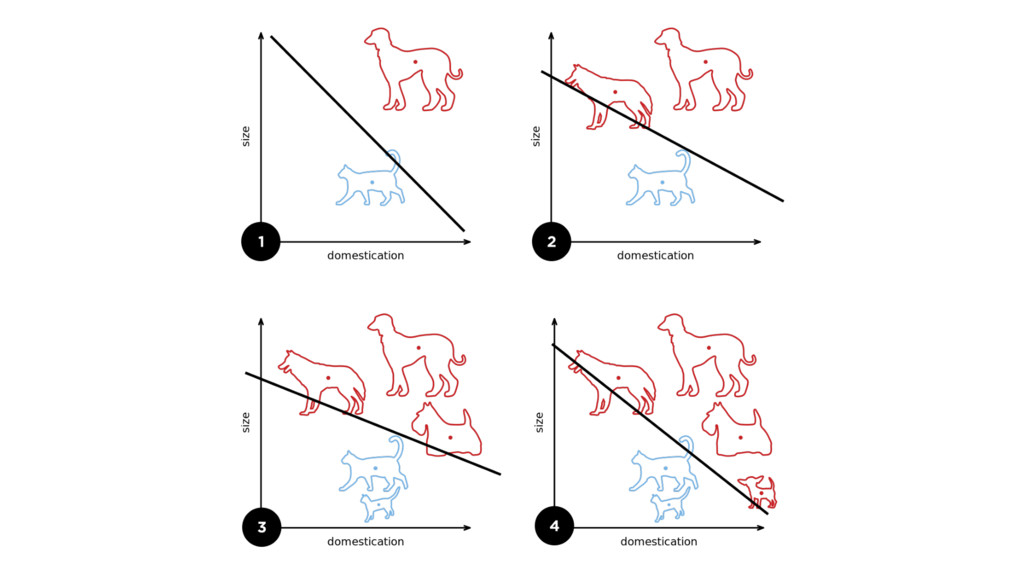{kind=link}
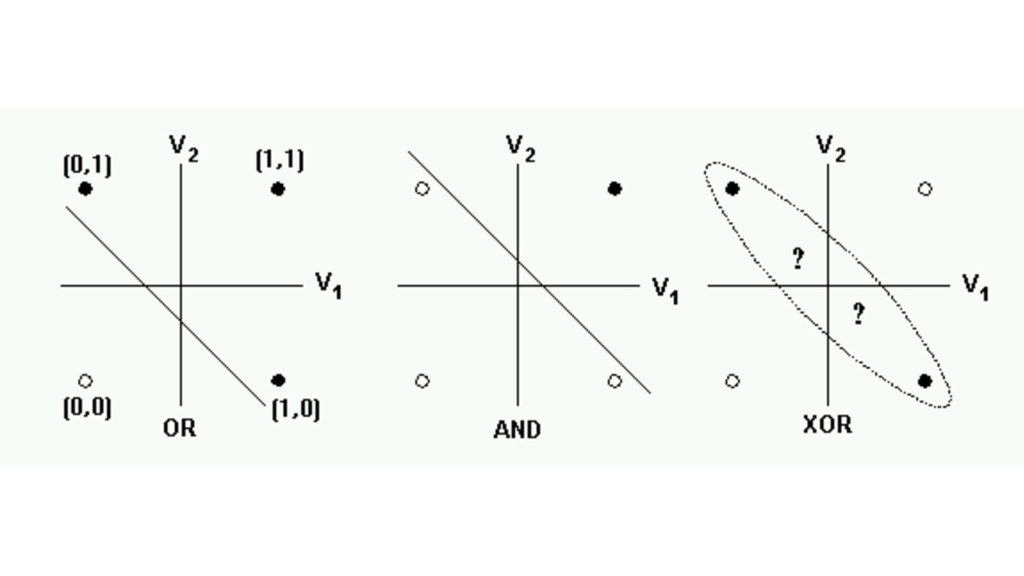{kind=link}
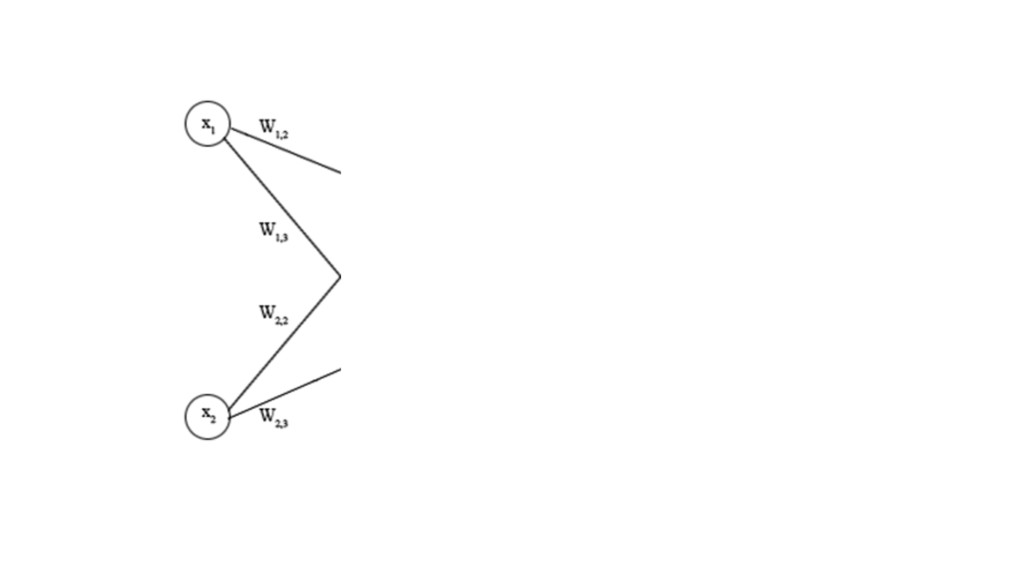{kind=link}
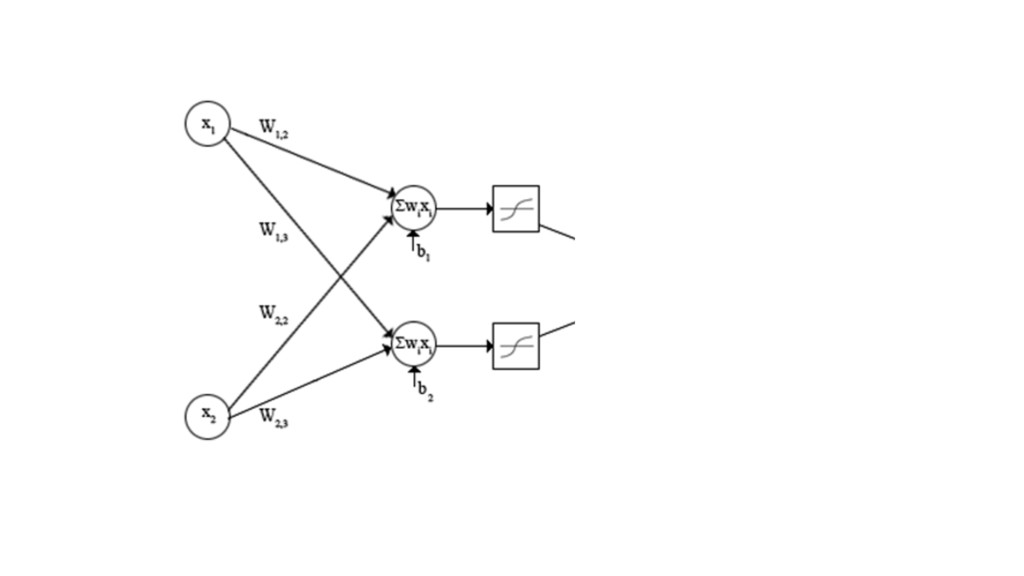{kind=link}
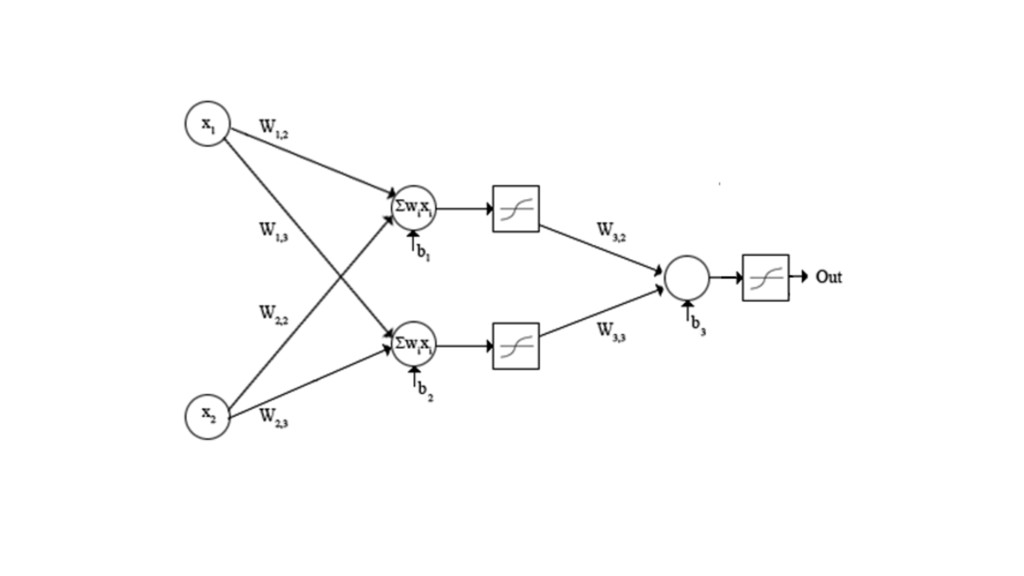{kind=link}
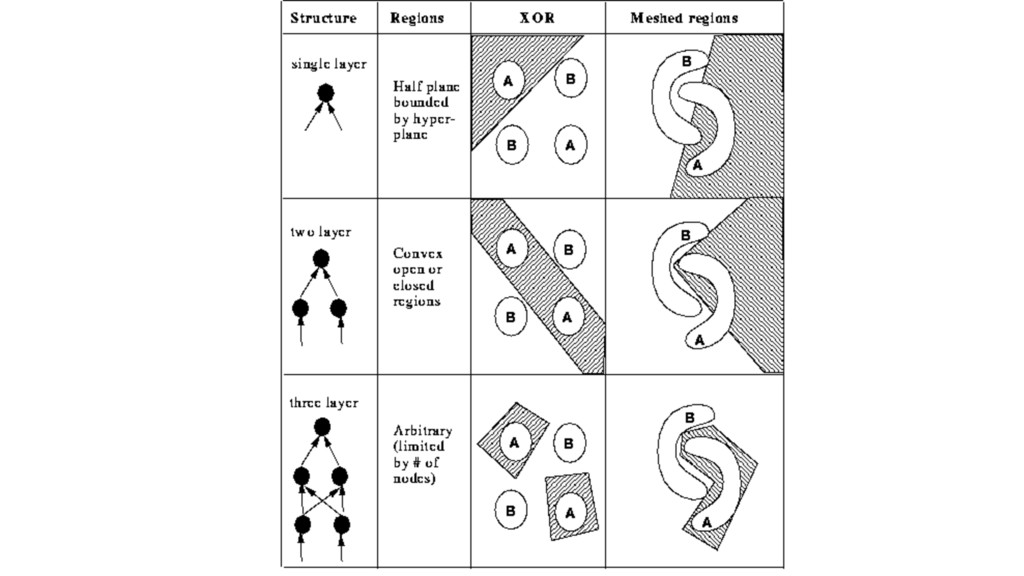{kind=link}
{kind=link}
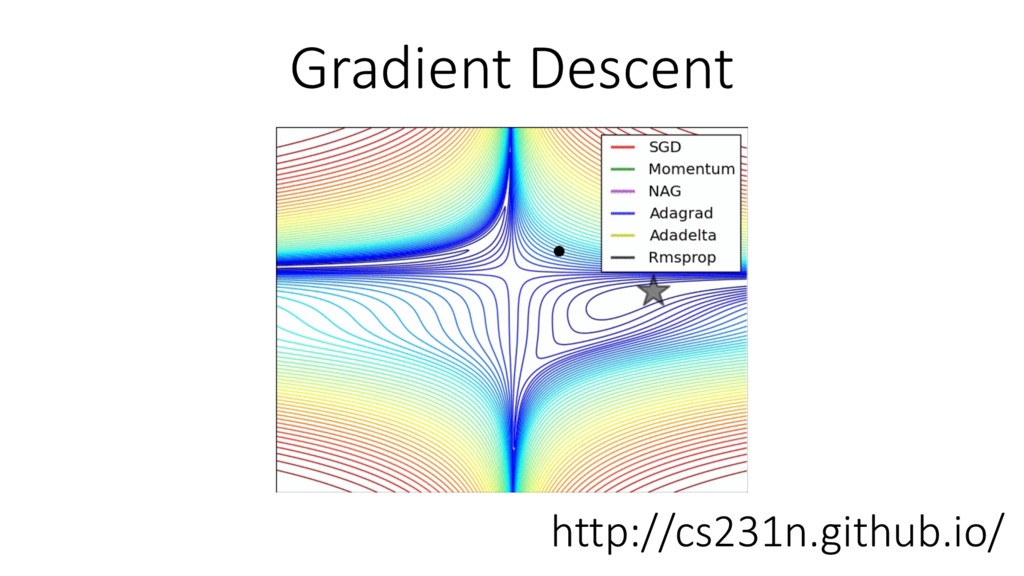{kind=link}
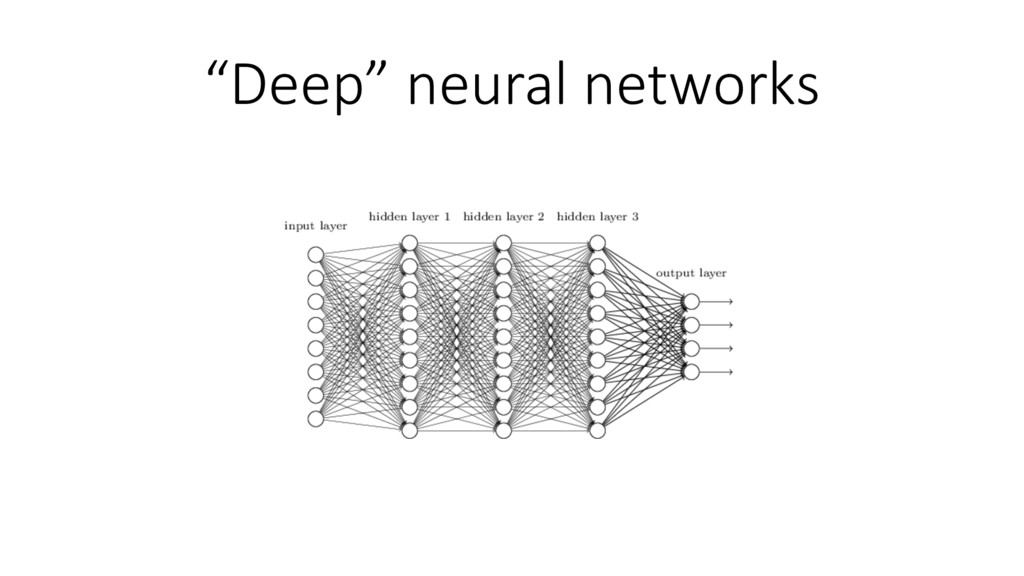{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
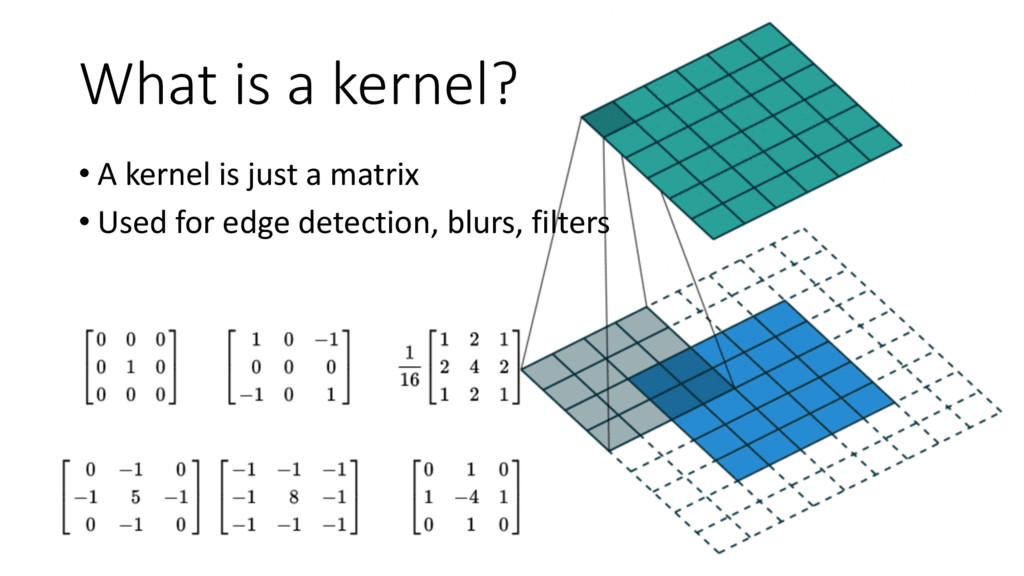{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
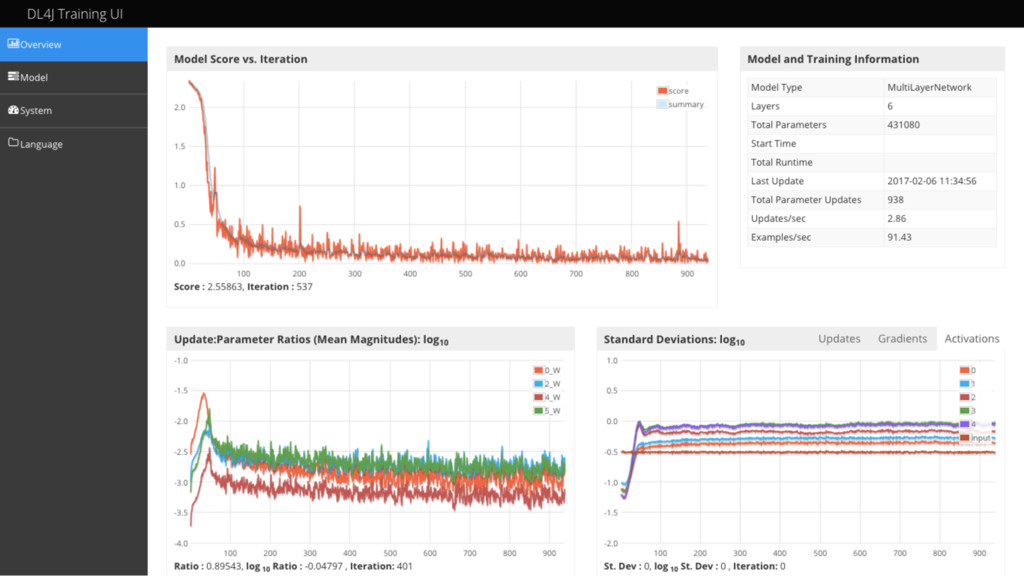{kind=link}
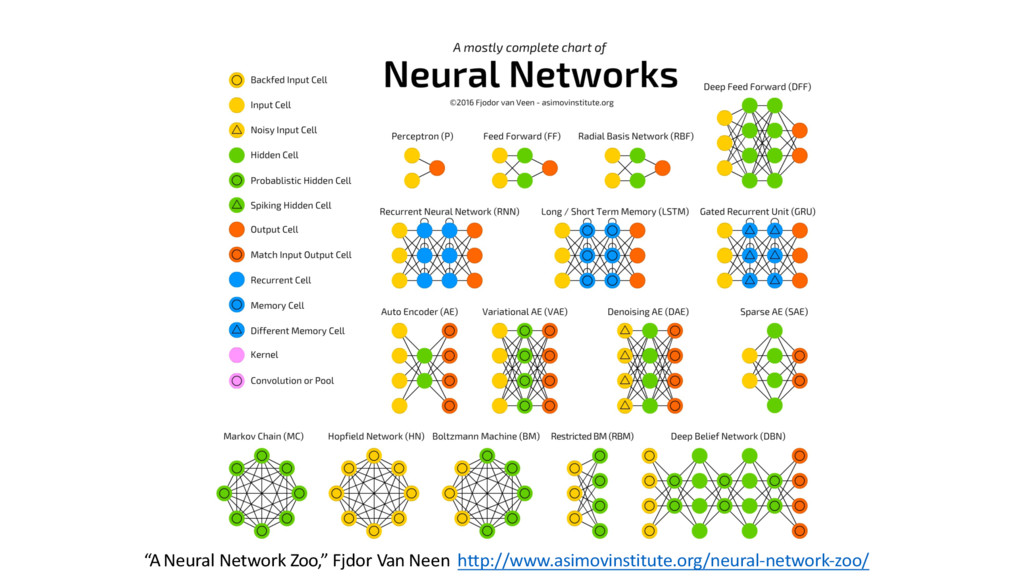{kind=link}
{kind=link}
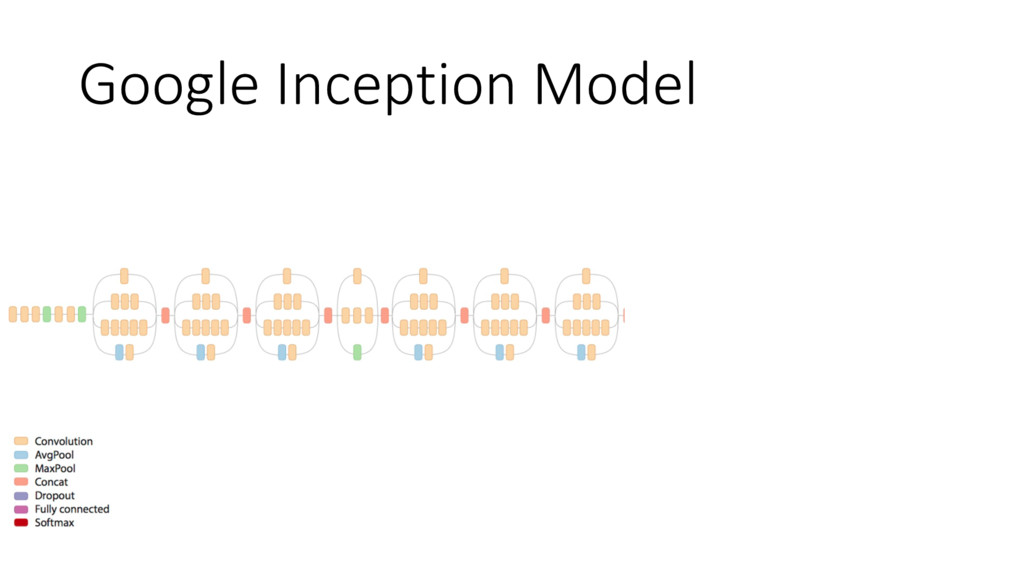{kind=link}
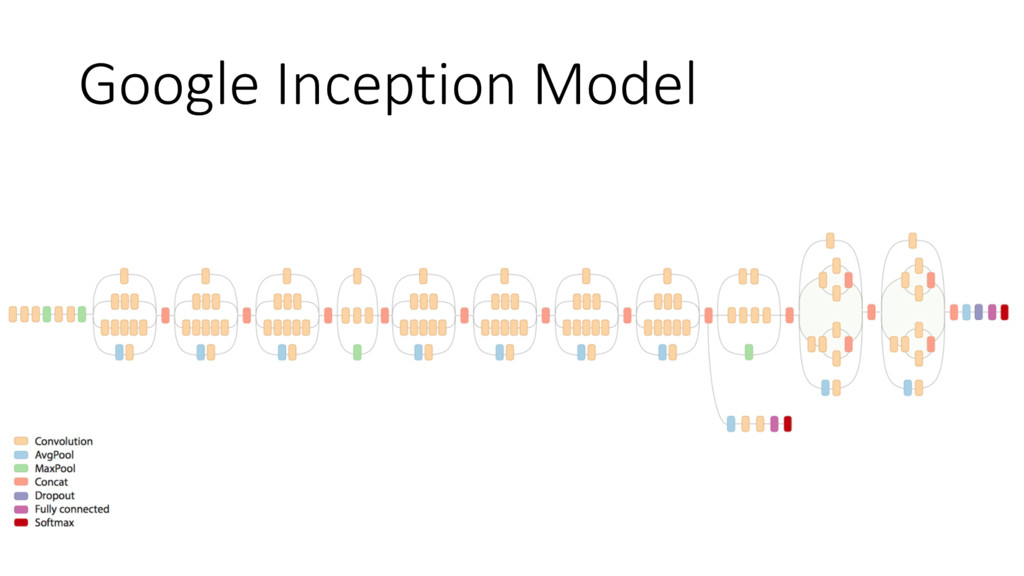{kind=link}
{kind=link}
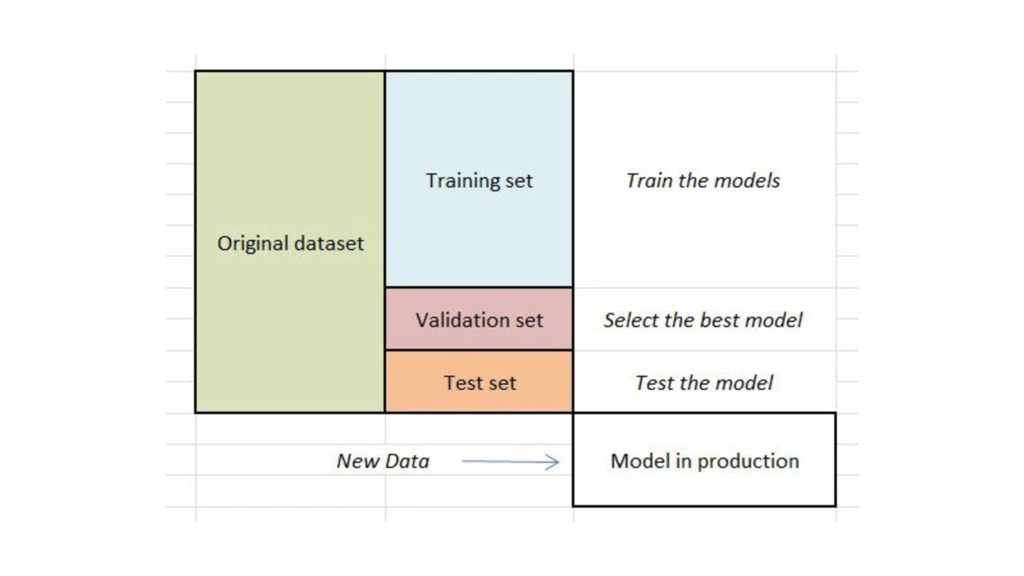{kind=link}
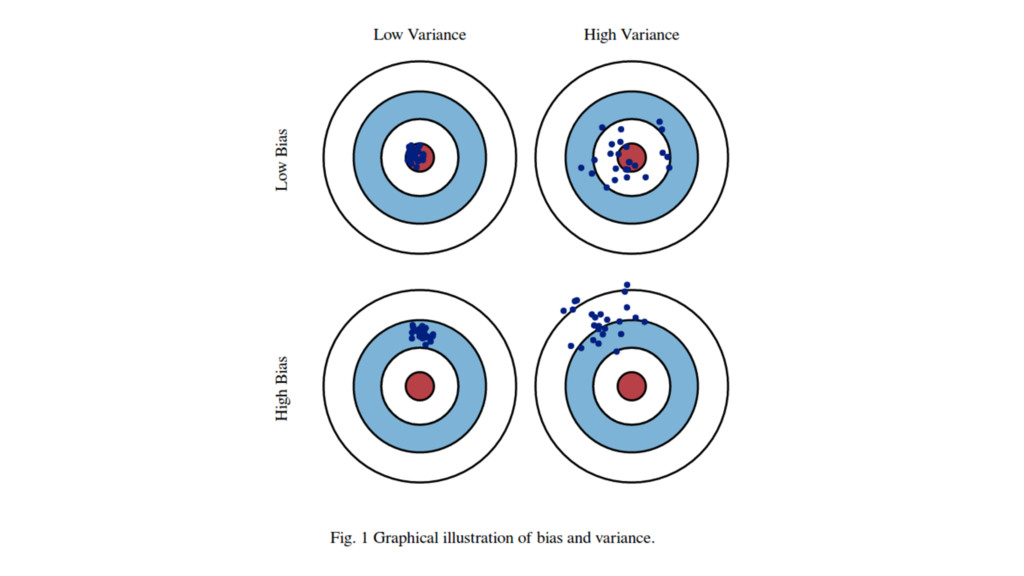{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
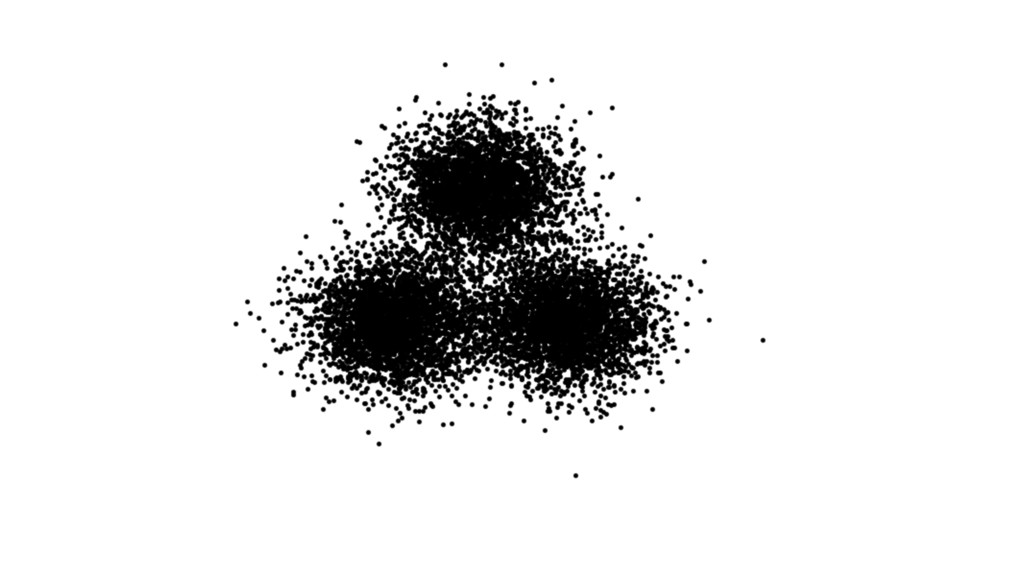{kind=link}
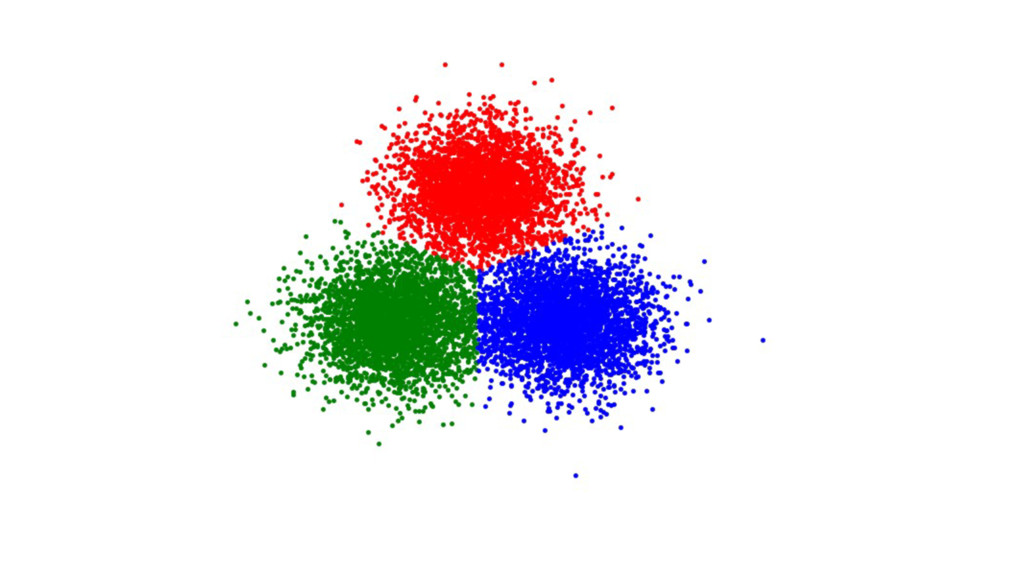{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}