• Structure of a single object is NOT immediately clear to someone glancing at the shell data • We have to flatten our object out into three tables Tuesday, November 15, 11
• Structure of a single object is NOT immediately clear to someone glancing at the shell data • We have to flatten our object out into three tables • 7 separate inserts just to add “Programming in Scala” Tuesday, November 15, 11
• Structure of a single object is NOT immediately clear to someone glancing at the shell data • We have to flatten our object out into three tables • 7 separate inserts just to add “Programming in Scala” • Once we turn the relational data back into objects ... Tuesday, November 15, 11
• Structure of a single object is NOT immediately clear to someone glancing at the shell data • We have to flatten our object out into three tables • 7 separate inserts just to add “Programming in Scala” • Once we turn the relational data back into objects ... • We still need to convert it to data for our frontend Tuesday, November 15, 11
• Structure of a single object is NOT immediately clear to someone glancing at the shell data • We have to flatten our object out into three tables • 7 separate inserts just to add “Programming in Scala” • Once we turn the relational data back into objects ... • We still need to convert it to data for our frontend • I don’t know about you, but I have better things to do with my time. Tuesday, November 15, 11
memory) •OS controls what data in RAM •When a piece of data isn't found, a page fault occurs (Expensive + Locking!) •OS goes to disk to fetch the data •Indexes are part of the Regular Database files •Deployment Trick: Pre-Warm your Database (PreWarming your cache) to prevent cold start slowdown Operating System map files on the Filesystem to Virtual Memory Tuesday, November 15, 11
bit MongoDB Build •32 Bit has a 2 gig limit; imposed by the operating systems for memory mapped files •Clients can be 32 bit •MongoDB Supports (little endian only) •Linux, FreeBSD, OS X (on Intel, not PowerPC) •Windows •Solaris (Intel only, Joyent offers a cloud service which works for Mongo) A Few Words on OS Choice Tuesday, November 15, 11
used •BUT.... •ext4, XFS or any other filesystem with posix_fallocate() are preferred and best • Turn off “atime” (/etc/fstab : add noatime, nodiratime) Filesystems “sort of” Matter Tuesday, November 15, 11
response id op code (insert) \x68\x00\x00\x00 \xXX\xXX\xXX\xXX \x00\x00\x00\x00 \xd2\x07\x00\x00 reserved collection name document(s) \x00\x00\x00\x00 f o o . t e s t \x00 BSON Data http://www.mongodb.org/display/DOCS/Mongo+Wire+Protocol Tuesday, November 15, 11
Documents are arranged in “collections” just as “rows” are organized in “tables” • Documents can be embedded in one another, or in Lists, etc. • Favor embedding over referencing • No datastore enforced foreign key relationships Tuesday, November 15, 11
data aggregation • Functions are written in JavaScript • Support for “Incremental” Jobs to build on prior job outputs as data changes w/o rerunning whole dataset • Limitations of JavaScript engines reduce parallelism* Tuesday, November 15, 11
(2D) Geospatial proximity with MongoDB • One GeoIndex per collection • Can index on an array or a subdocument • Searches against the index can treat the dataset as flat (map-like), Spherical (like a globe), and complex (box/ rectangle, circles, concave polygons and convex poylgons) Tuesday, November 15, 11
MongoDB; supported in all official drivers as reference implementation • Works around BSON document size limits by breaking files into chunks • Two collections: ‘fs.files’ for metadata, ‘fs.chunks’ for individual file pieces • Sharding: Individual file chunks don’t shard, but files themselves will • Experimental Modules for Lighttpd and Nginx • On JVM: get back java.io.File handles on GridFS read! Tuesday, November 15, 11
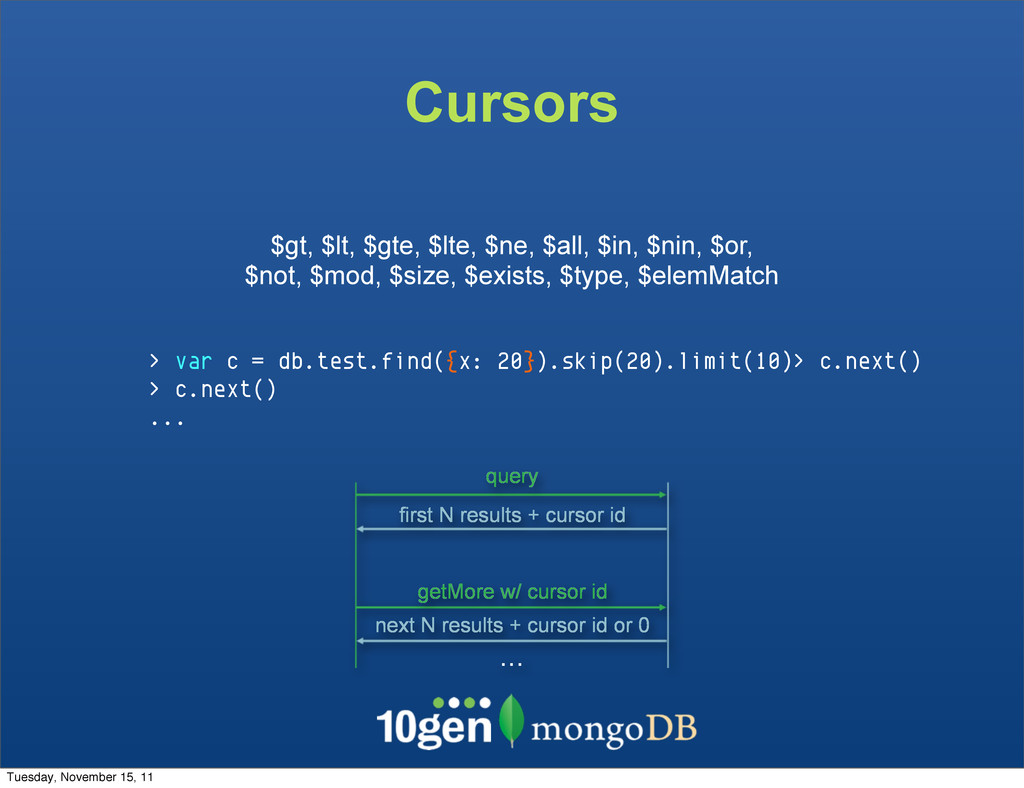
... $gt, $lt, $gte, $lte, $ne, $all, $in, $nin, $or, $not, $mod, $size, $exists, $type, $elemMatch query first N results + cursor id getMore w/ cursor id next N results + cursor id or 0 ... Tuesday, November 15, 11
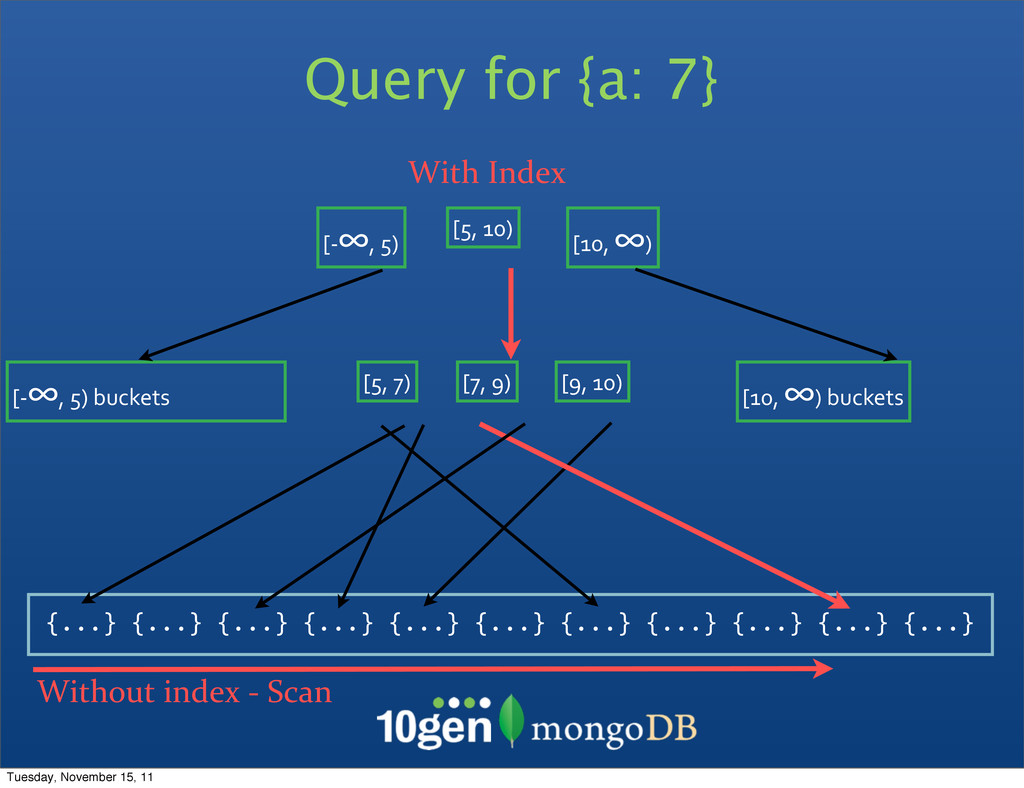
“Foo, Bar” and “Foo, Bar, Baz” • The Query Optimizer figures out the order but can’t do things in reverse • You can pass hints to force a specific index: db.collection.find({username: ‘foo’, city: ‘New York’}).hint({‘username’: 1}) • Missing Values are indexed as “null” • This includes unique indexes • system.indexes Tuesday, November 15, 11
Earth? • Where On Scrabble? • Where On <Coordinate Based Application>? • Covered Indexes • Answering Queries Entirely From Index (1.8+) • Sparse Indexes • Reduce Storage of Null Fields • Can’t answer “not in index” queries • Combine with Unique! Tuesday, November 15, 11
the ORM Pattern can be a disaster, well designed Documents map well to a typical object hierarchy • The world of ODMs for MongoDB has evolved in many languages, with fantastic tools in Scala, Java, Python and Ruby Tuesday, November 15, 11
the ORM Pattern can be a disaster, well designed Documents map well to a typical object hierarchy • The world of ODMs for MongoDB has evolved in many languages, with fantastic tools in Scala, Java, Python and Ruby • Typically “relationship” fields can be defined to be either “embedded” or “referenced” Tuesday, November 15, 11
Major ODMs in the Java World • Morphia • JPA Inspired • Annotation Driven; Able to integrate with existing objects • Written purely for MongoDB, strong coupling Tuesday, November 15, 11
Major ODMs in the Java World • Morphia • JPA Inspired • Annotation Driven; Able to integrate with existing objects • Written purely for MongoDB, strong coupling • Spring-Data-Document Tuesday, November 15, 11
Major ODMs in the Java World • Morphia • JPA Inspired • Annotation Driven; Able to integrate with existing objects • Written purely for MongoDB, strong coupling • Spring-Data-Document • Part of the Spring-Data System Tuesday, November 15, 11
Major ODMs in the Java World • Morphia • JPA Inspired • Annotation Driven; Able to integrate with existing objects • Written purely for MongoDB, strong coupling • Spring-Data-Document • Part of the Spring-Data System • Follows the Spring paradigms; comfortable to the Spring veteran Tuesday, November 15, 11
Major ODMs in the Java World • Morphia • JPA Inspired • Annotation Driven; Able to integrate with existing objects • Written purely for MongoDB, strong coupling • Spring-Data-Document • Part of the Spring-Data System • Follows the Spring paradigms; comfortable to the Spring veteran • Designed for multiple datastores (Couch support forthcoming); less strongly coupled Tuesday, November 15, 11
use "reference", which are stored to 38 * their own collection and loaded automatically 39 * 40 * Morphia uses the field name for where to store the value, 41 * can override with a string arg to the annotation. 42 */ 43 @Embedded private Price price; 44 45 /** 46 * Can rename a field for how stored in MongoDB 47 */ 48 @Property("publicationYear") private int year; 49 50 private List<String> tags = new ArrayList<String>(); 51 private String title; 52 private String publisher; 53 private String edition; 54 55 public String toString(){ 56 return "Book{" + 57 "author=" + author + 58 ", id=" + id + 59 ", isbn='" + isbn + '\'' + 60 ", price=" + price + 61 ", year=" + year + 62 ", tags=" + tags + Tuesday, November 15, 11
Major ODMs in the Scala World • Lift-MongoDB-Record • Based on the Record pattern • Requires entirely custom objects following Record paradigm Tuesday, November 15, 11
Major ODMs in the Scala World • Lift-MongoDB-Record • Based on the Record pattern • Requires entirely custom objects following Record paradigm • Strongly coupled to MongoDB but still bound by Record Tuesday, November 15, 11
Major ODMs in the Scala World • Lift-MongoDB-Record • Based on the Record pattern • Requires entirely custom objects following Record paradigm • Strongly coupled to MongoDB but still bound by Record • Bonus: Absolutely incredible “Rogue” DSL from Foursquare for taking Lift-MongoDB-Record further Tuesday, November 15, 11
Major ODMs in the Scala World • Lift-MongoDB-Record • Based on the Record pattern • Requires entirely custom objects following Record paradigm • Strongly coupled to MongoDB but still bound by Record • Bonus: Absolutely incredible “Rogue” DSL from Foursquare for taking Lift-MongoDB-Record further • Salat Tuesday, November 15, 11
Major ODMs in the Scala World • Lift-MongoDB-Record • Based on the Record pattern • Requires entirely custom objects following Record paradigm • Strongly coupled to MongoDB but still bound by Record • Bonus: Absolutely incredible “Rogue” DSL from Foursquare for taking Lift-MongoDB-Record further • Salat • Built by same team who helped start Casbah (scala driver) Tuesday, November 15, 11
Major ODMs in the Scala World • Lift-MongoDB-Record • Based on the Record pattern • Requires entirely custom objects following Record paradigm • Strongly coupled to MongoDB but still bound by Record • Bonus: Absolutely incredible “Rogue” DSL from Foursquare for taking Lift-MongoDB-Record further • Salat • Built by same team who helped start Casbah (scala driver) • Annotation driven, built from ground up to apply onto existing business objects cleanly Tuesday, November 15, 11
Major ODMs in the Scala World • Lift-MongoDB-Record • Based on the Record pattern • Requires entirely custom objects following Record paradigm • Strongly coupled to MongoDB but still bound by Record • Bonus: Absolutely incredible “Rogue” DSL from Foursquare for taking Lift-MongoDB-Record further • Salat • Built by same team who helped start Casbah (scala driver) • Annotation driven, built from ground up to apply onto existing business objects cleanly • Strongly coupled to MongoDB Tuesday, November 15, 11
+ Hadoop • Process MongoDB data inside of Hadoop, output back out to MongoDB • Growing support for the “deeper” Hadoop infrastructure such as Pig, Cascading, Hive, etc. Tuesday, November 15, 11
MongoDB, you “roll your own” • But there are great builtin facilities to make it easier for you to do it • Capped Collections • Tailable cursors Tuesday, November 15, 11
MongoDB, you “roll your own” • But there are great builtin facilities to make it easier for you to do it • Capped Collections • Tailable cursors • findAndModify Tuesday, November 15, 11
collection designed for Replication • Created specially with a number of bytes it may hold • No _id index • Documents are maintained in insertion order Tuesday, November 15, 11
collection designed for Replication • Created specially with a number of bytes it may hold • No _id index • Documents are maintained in insertion order • No deletes allowed Tuesday, November 15, 11
collection designed for Replication • Created specially with a number of bytes it may hold • No _id index • Documents are maintained in insertion order • No deletes allowed • Updates only allowed if document won’t “grow” Tuesday, November 15, 11
collection designed for Replication • Created specially with a number of bytes it may hold • No _id index • Documents are maintained in insertion order • No deletes allowed • Updates only allowed if document won’t “grow” • As collection fills up, oldest entries “fall out” Tuesday, November 15, 11
collection designed for Replication • Created specially with a number of bytes it may hold • No _id index • Documents are maintained in insertion order • No deletes allowed • Updates only allowed if document won’t “grow” • As collection fills up, oldest entries “fall out” • Allow for a special cursor type: Tailable Cursors Tuesday, November 15, 11
special cursor mode in MongoDB • Similar to Unix’ ‘tail -f’, maintain a pointer to the last document seen; continue moving forward as new documents added Tuesday, November 15, 11
special cursor mode in MongoDB • Similar to Unix’ ‘tail -f’, maintain a pointer to the last document seen; continue moving forward as new documents added • With “Await” cursor mode, can poll until new documents arrive Tuesday, November 15, 11
special cursor mode in MongoDB • Similar to Unix’ ‘tail -f’, maintain a pointer to the last document seen; continue moving forward as new documents added • With “Await” cursor mode, can poll until new documents arrive • Incredibly efficient for non-indexed queries Tuesday, November 15, 11
easy broadcast messaging • ... In fact, it is exactly how MongoDB does replication • Because you can’t delete messages this wouldn’t be ideal for pub/sub Tuesday, November 15, 11
easy broadcast messaging • ... In fact, it is exactly how MongoDB does replication • Because you can’t delete messages this wouldn’t be ideal for pub/sub • But could be paired carefully with findAndModify Tuesday, November 15, 11
can be tricky • AKA “Distributed Locking is Hard - Let’s Go Shopping!” • MongoDB’s update doesn’t allow you to fetch the exact document(s) changed • The findAndModify command enables a proper mechanism • Find and modify first matching document and return new doc or old one • Find and remove first matching document and return the pre-removed document • Isolated; two competing threads won’t get the same document Tuesday, November 15, 11
computing & Actor framework) now includes a MongoDB based durable mailbox, using these concepts for unbounded (soon: bounded) messaging • 10gen’s MMS monitoring service uses findAndModify to facilitate worker queues Tuesday, November 15, 11
MustMatchers with BeforeAndAfterEach with BeforeAndAfterAll { 43 import DurableMongoMailboxSpecActorFactory._ 44 45 implicit val dispatcher = DurableDispatcher("mongodb", MongoNaiveDurableMailboxStorage, 1) 46 47 "A MongoDB based naive mailbox backed actor" should { 48 "should handle reply to ! for 1 message" in { 49 val latch = new CountDownLatch(1) 50 val queueActor = createMongoMailboxTestActor("mongoDB Backend should handle Reply to !") 51 val sender = localActorOf(new Actor { def receive = { case "sum" => latch.countDown } }).start 52 53 queueActor.!("sum")(Some(sender)) 54 latch.await(10, TimeUnit.SECONDS) must be (true) 55 } 56 57 "should handle reply to ! for multiple messages" in { 58 val latch = new CountDownLatch(5) 59 val queueActor = createMongoMailboxTestActor("mongoDB Backend should handle reply to !") 60 val sender = localActorOf( new Actor { def receive = { case "sum" => latch.countDown } } ).start 61 Tuesday, November 15, 11
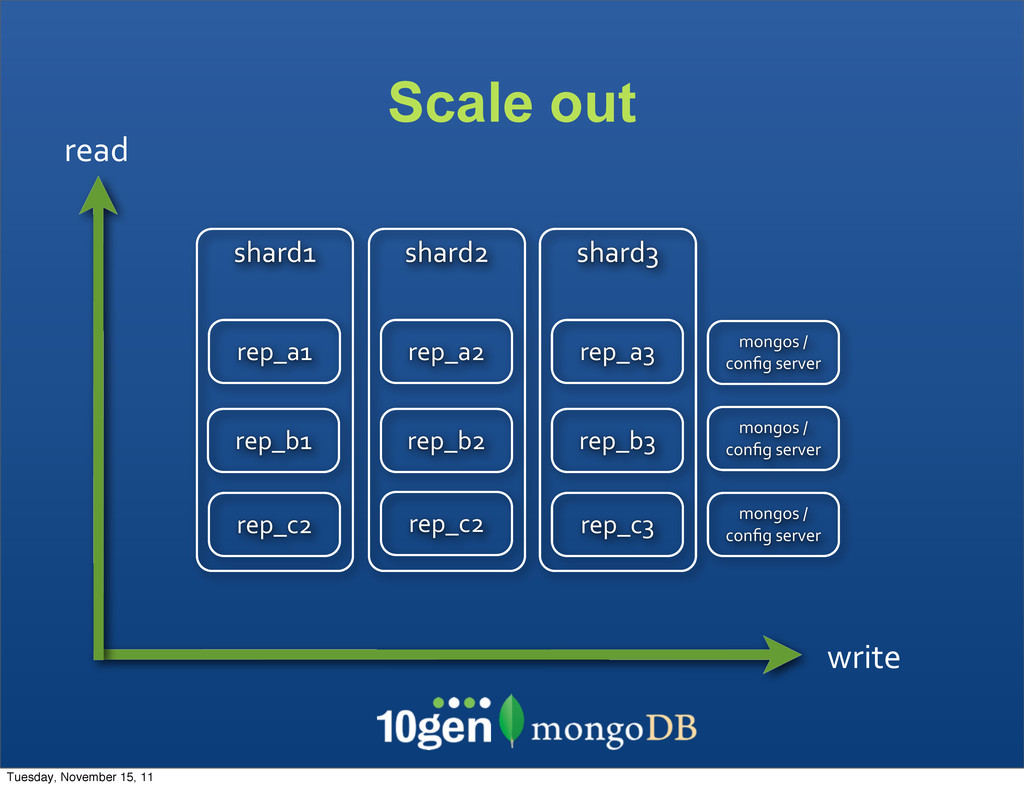
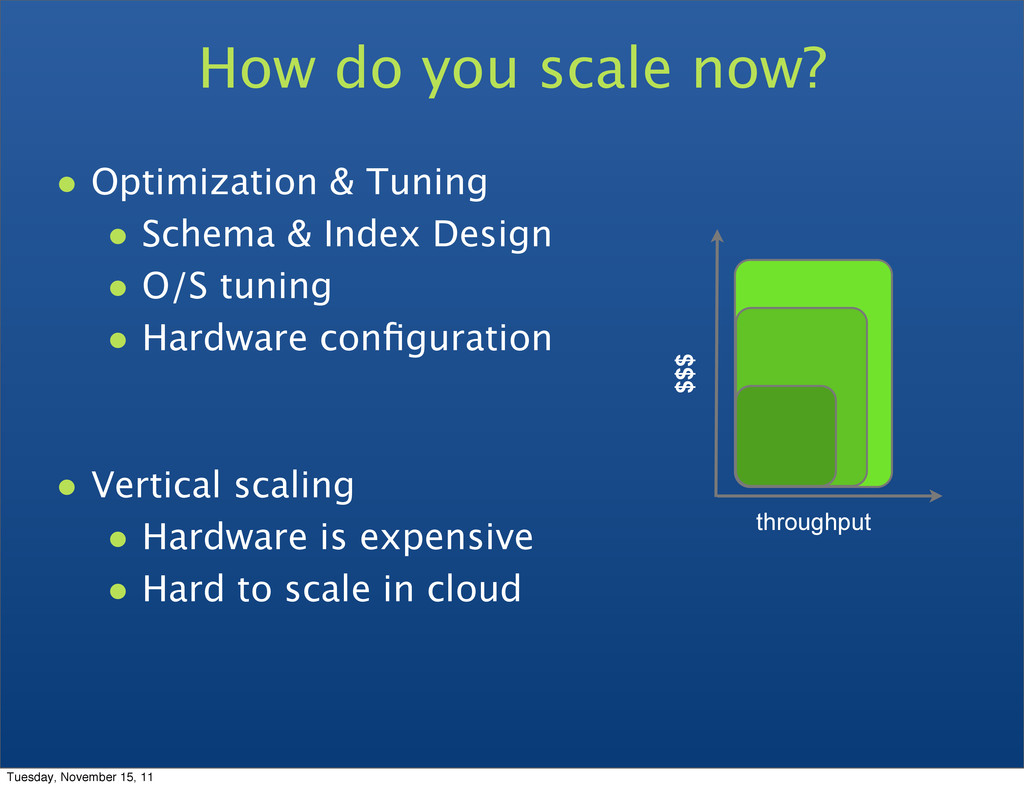
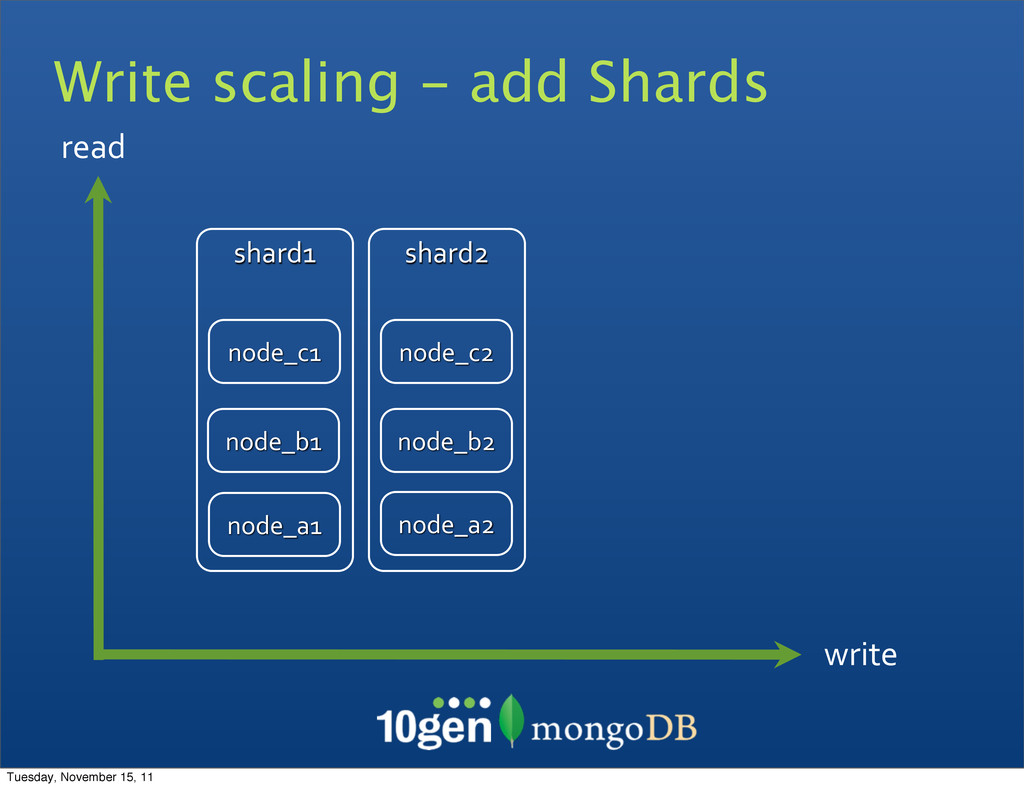
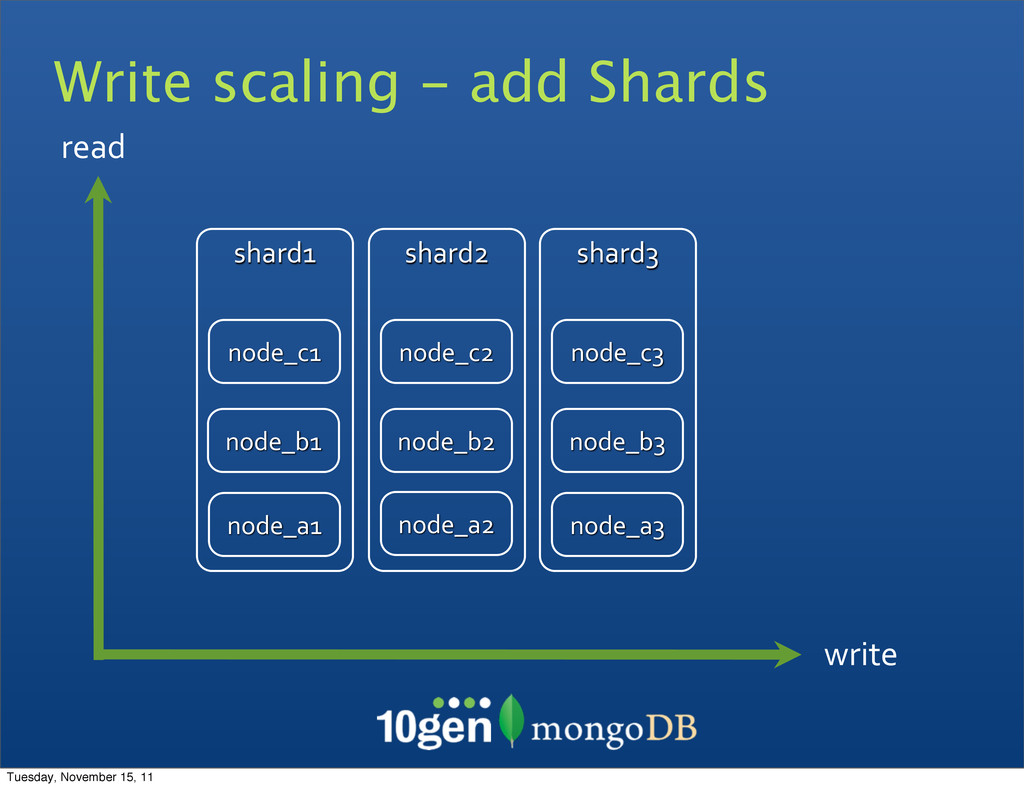
O/S tuning • Hardware configuration • Vertical scaling • Hardware is expensive • Hard to scale in cloud How do you scale now? $$$ throughput Tuesday, November 15, 11
• Roundtrips to database • Disk seek time • Size of data to read & write • Partial versus full document writes • Partial versus full document reads • Schema and Schema usage critical for scaling and performance Tuesday, November 15, 11
balancing as data is written • Commands routed (switched) to correct node • Inserts - must have the Shard Key • Updates - must have the Shard Key • Queries • With Shard Key - routed to nodes • Without Shard Key - scatter gather • Indexed Queries • With Shard Key - routed in order • Without Shard Key - distributed sort merge Tuesday, November 15, 11
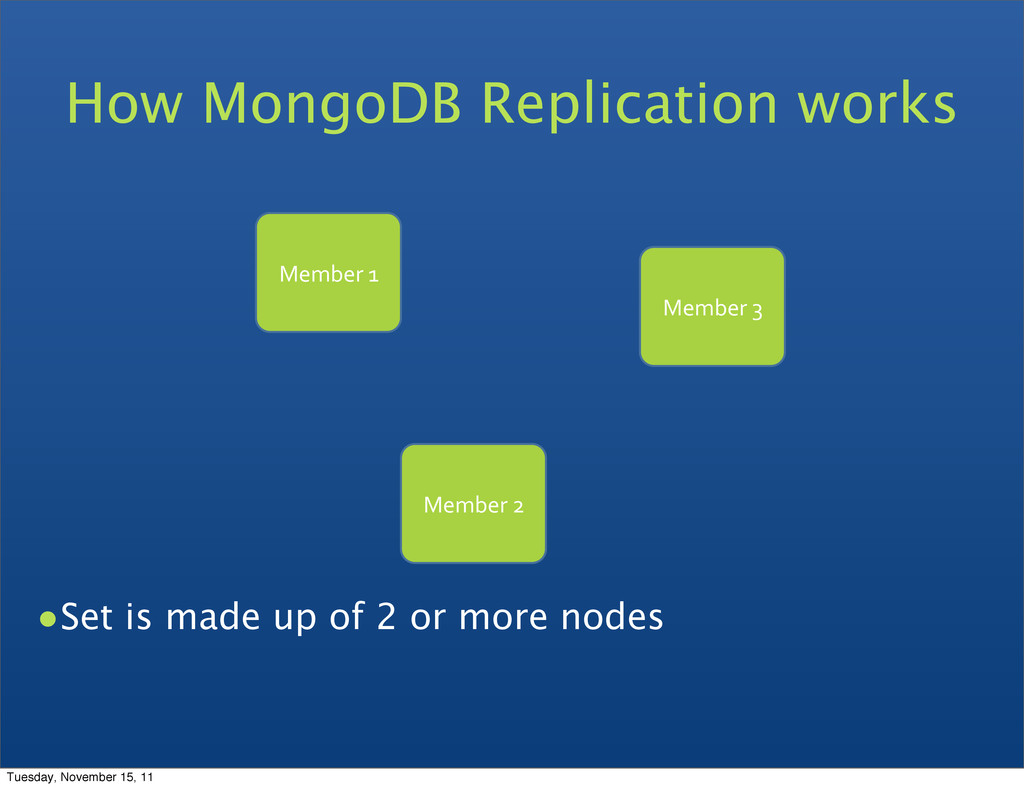
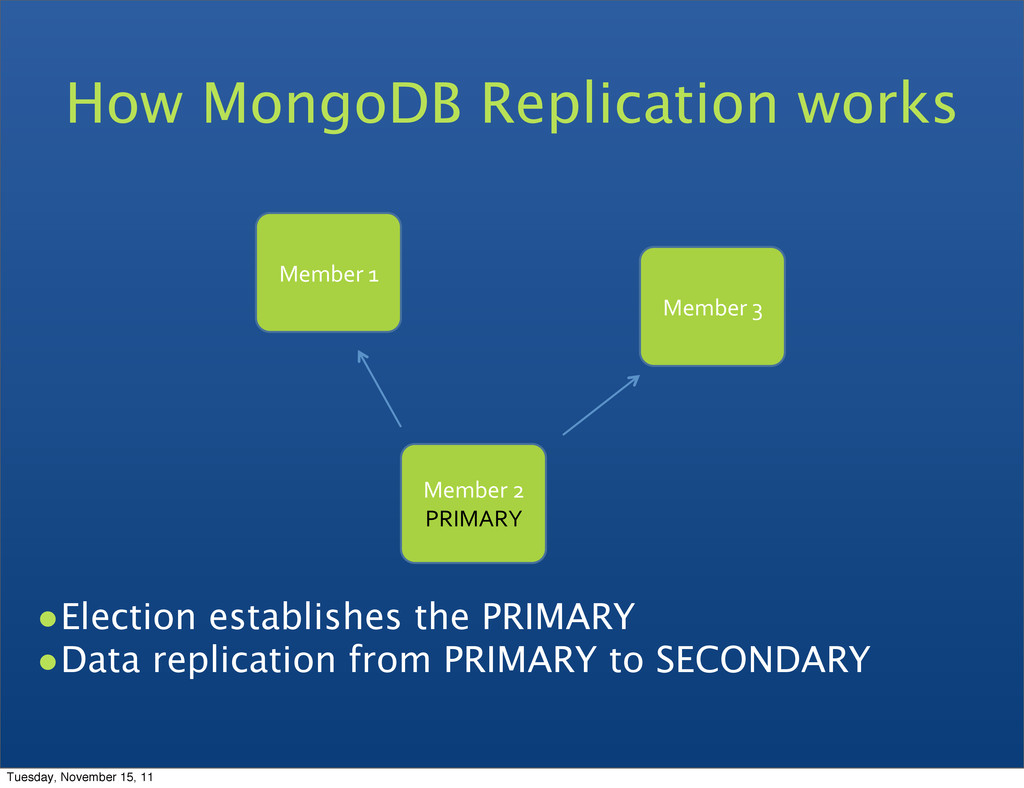
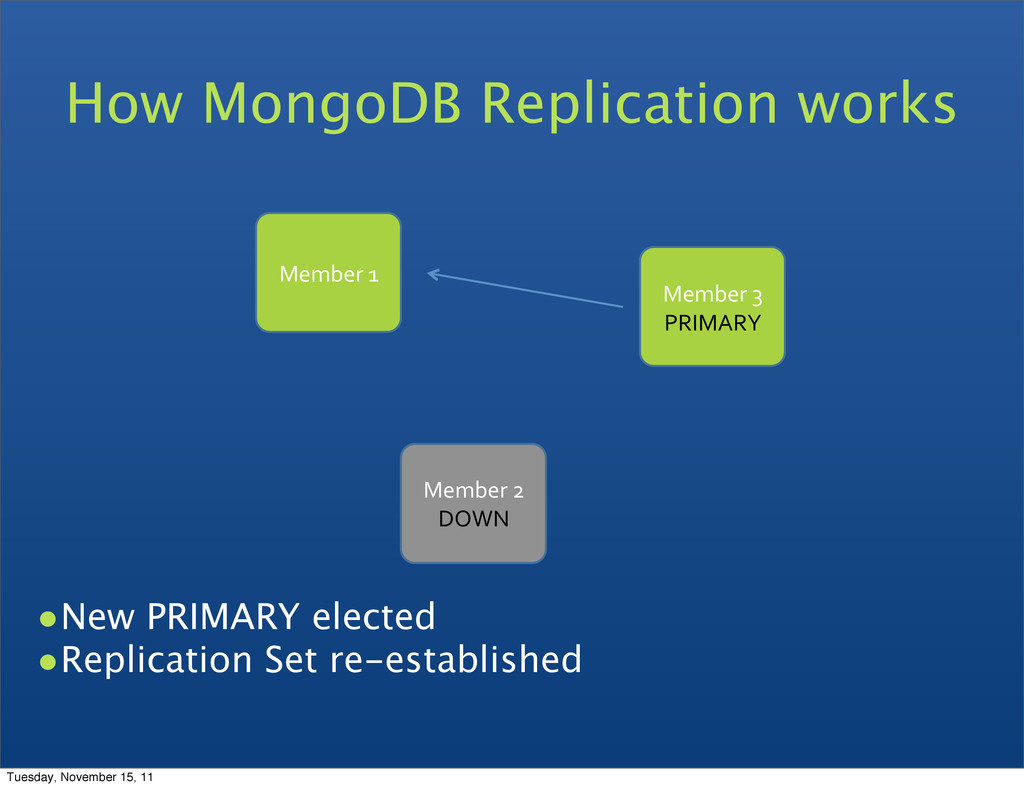
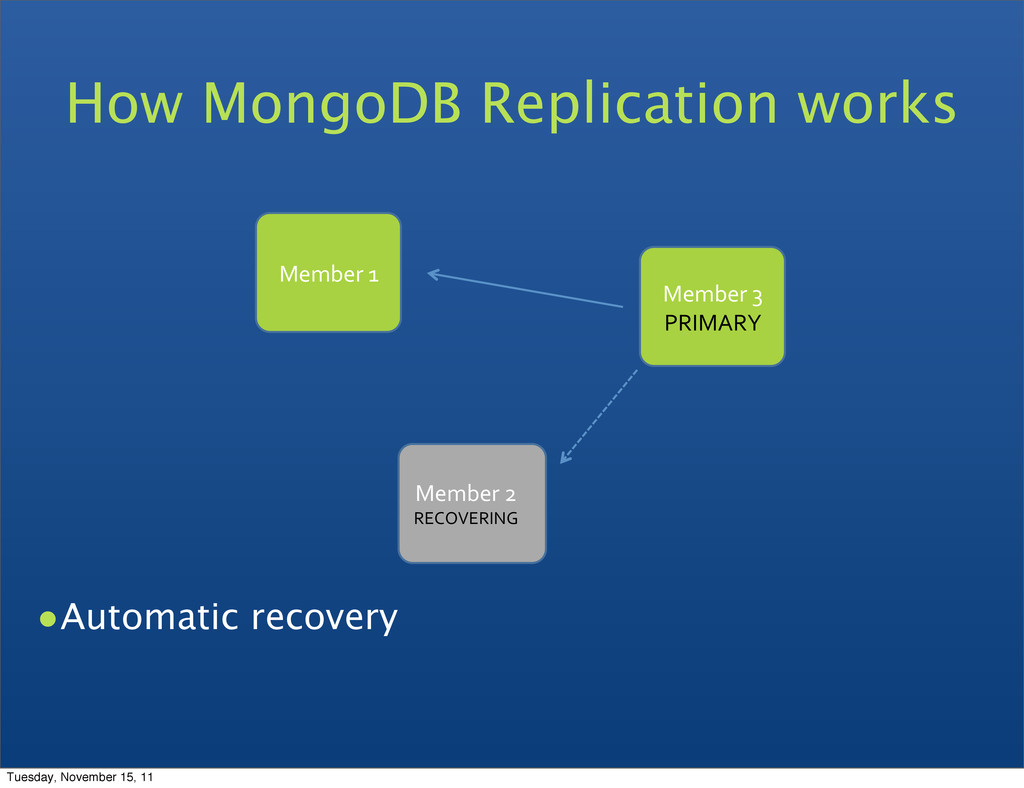
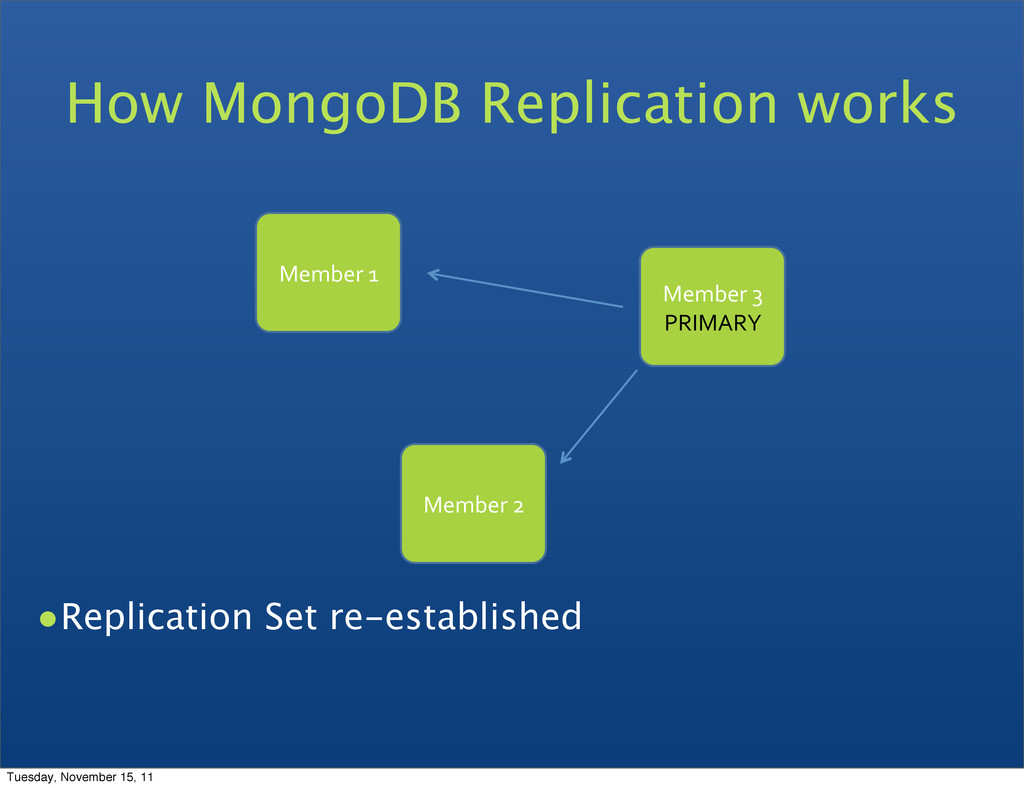
can be primary • Consensus election of primary • Automatic failover • Automatic recovery • All writes to primary • Reads can be to primary (default) or a secondary Replica Set features Tuesday, November 15, 11
• Cannot be elected as PRIMARY • Arbiters • Can vote in an election • Do not hold any data • Hidden {hidden:True} • Tagging - New in 2.0 • tags : {"dc": "ny"}, "rack": "r23s5"} Tuesday, November 15, 11
write is synchronous - command returns after primary has written to memory • w=n or w='majority' - n is the number of nodes data must be replicated to - driver will always send writes to Primary • w='myTag' [MongoDB 2.0] - Each member is "tagged" e.g. "US_EAST", "EMEA", "US_WEST" - Ensure that the write is executed in each tagged "region" Tuesday, November 15, 11
Reads from Secondaries are eventually consistent • Automatic failover if a Primary fails • Automatic recovery when a node joins the set Tuesday, November 15, 11
to identify a "user" • Facebook ID • Twitter Name • Email address • SSN# / National Identifier • What is the best schema, index and sharding strategy? Tuesday, November 15, 11
Easy to add new identifiers, e.g. foursquare name • Query is routed to a shard db.profiles.find({twitter_name: "rit"}) Bad: • Each identifier needs a separate index • More indexes means less data in memory • Memory contention and disk paging • Query is scatter/gathered across cluster db.profiles.find({linkedin_name:"bwmcadams"}) Tuesday, November 15, 11
foursquare name • All query are routed to a shard > db.identifiers.find( {_id : {type: "twitter_name": value: "rit"}}) > db.identifiers.find( {_id : {type: "foursquare_id": value: "bwmcadams"}}) Bad: • Schema is more complex • Two lookups are required for each access (but both routed) • Need to maintain links (data relationships) Tuesday, November 15, 11
for one server is in a single chunk • Chunk cannot be split any smaller • Better : {server:1,time:1} • Chunk can be split by millisecond { server : "ny153.example.com" , application : "apache" , time : "2011-‐01-‐02T21:21:56.249Z" , level : "ERROR" , msg : "something is broken" } Tuesday, November 15, 11
Time is an increasing number • All data will be first written to a single shard • Data balanced to other shards later • Better : {server:1,application:1,time:1} • More key values to enable writes to all shards { server : "ny153.example.com" , application : "apache" , time : "2011-‐01-‐02T21:21:56.249Z" , level : "ERROR" , msg : "something is broken" } Tuesday, November 15, 11
information about the sharding setup is stored in the config servers; it’s important you don’t lose them • You may have 1 or 3 config servers; this is the only valid configuration (Two Phase Commit) • Production deployments should always have 3 • If any config server fails ... • Chunk splitting will stop • Migration / balancing will stop • ... Until all 3 servers are back up • This can lead to unbalanced shard situations • Through mongos the config info is in the “config” db Tuesday, November 15, 11
sharding • Basic unit of transfer: “chunk” • Default size of 64 MB proves to be a “sweet spot” • More: Migration takes too long, queries la • Less: Overhead of moving doesn’t pay off • The idea is to keep a balance of data & load on each server. Even is good! • Once a threshold of “imbalance” is reached, the balancer kicks in • Usually about ~8 chunks: Don’t want to balance on one doc diff. Tuesday, November 15, 11
time • Known as balancer “rounds” • Balancing rounds continue until difference between any two shards is only 2 chunks • Common Question – “Why isn’t collection $x being balanced?!” • Commonly, it just doesn’t need to. Not enough chunk diff, and the cost of balancing would outweigh the benefit. • Alternately, the balancer may be running but not progressing Tuesday, November 15, 11
will be “2” for MongoDB v2.0 • Indicates the lock is taken • "when" : "Mon Dec 20 2010 11:41:10 GMT-0500 (EST)" • This is when the balancer began running for this round • "who" : "guaruja:1292810611:1804289383:Balancer:846930886" • The name of the server the balancer round is running on Tuesday, November 15, 11
default • At times, this may not be desirable • High traffic during peak hours where the balancer slows things down • Sites which don’t write a lot of data during the day, but having the balancer run may be disruptive Tuesday, November 15, 11
default • At times, this may not be desirable • High traffic during peak hours where the balancer slows things down • Sites which don’t write a lot of data during the day, but having the balancer run may be disruptive • MongoDB allows you to set a time frame in which the Balancer runs Tuesday, November 15, 11
to 9pm • Currently only time of day is supported to scheduling // connect to mongos > use config > db.settings.update({ _id : "balancer" }, { $set : { activeWindow : { start : "9:00", stop : "21:00" } } }, true ) Tuesday, November 15, 11
![Devoxx Workshop Brendan McAdams @rit 10gen, Inc. [email protected] Tuesday, November](https://files.speakerdeck.com/presentations/4ec37fd3b57aab0051008813/slide_0.jpg){kind=link}
![Introductions • Brendan McAdams - [email protected] • 10gen Engineer •](https://files.speakerdeck.com/presentations/4ec37fd3b57aab0051008813/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
), 55 doc.as[Number]("publicationYear").intValue, 56 doc.as[BasicDBList]](https://files.speakerdeck.com/presentations/4ec37fd3b57aab0051008813/slide_83.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Object Mapping with Lift 5 class Book private() extends BsonRecord[Book]](https://files.speakerdeck.com/presentations/4ec37fd3b57aab0051008813/slide_114.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}