com web e software livre desde 1995; • Python desde 2000; • MongoDB desde o início do projeto; • Colaboro e já colaborei com projetos como: – GNU Project (Free Software Foundation); – Debian Project; – Python; – MongoDB – MUG - SP; • Twitter: @dump • Blog: http://christiano.me • Facebook, LinkedIn: Christiano Anderson
ser: – Orientados a documentos; – Orientados a chave/valor; – Orientado a colunas; – Orientado a grafos; – Multi modelagem; • Sua principal vantagem é ser livre de modelagem; • Altamente escalável; • Rápido deploy; • Rápida integração com linguagens de programação
– E você não tem como estimar; • Não necessita de modelagem prévia; • Sua aplicação muda com muita frequência (beta perpétua); • Utiliza desenvolvimento ágil;
por exemplo: JSON; • Não existe necessidade de modelagem prévia; • É possível em uma mesma coleção existirem documentos com estruturas bem diferentes; • Exemplo de banco: MongoDB; • Exemplo de aplicação: Catálogo de produtos de um e-commerce;
tem um valor (que pode ser um array); • Geralmente são armazenados em memória RAM; • Ótimo para manipular dataset; • Exemplo de banco: Redis; • Exemplo de aplicação: sessão de usuário e carrinho de compras;
• São bem escaláveis; • Dividido em linhas; • Ótimo para séries temporais (cada linha é uma hora, cada coluna pode ser um segundo); • Exemplo de banco: Hbase; • Exemplo de aplicação: Análises temporais;
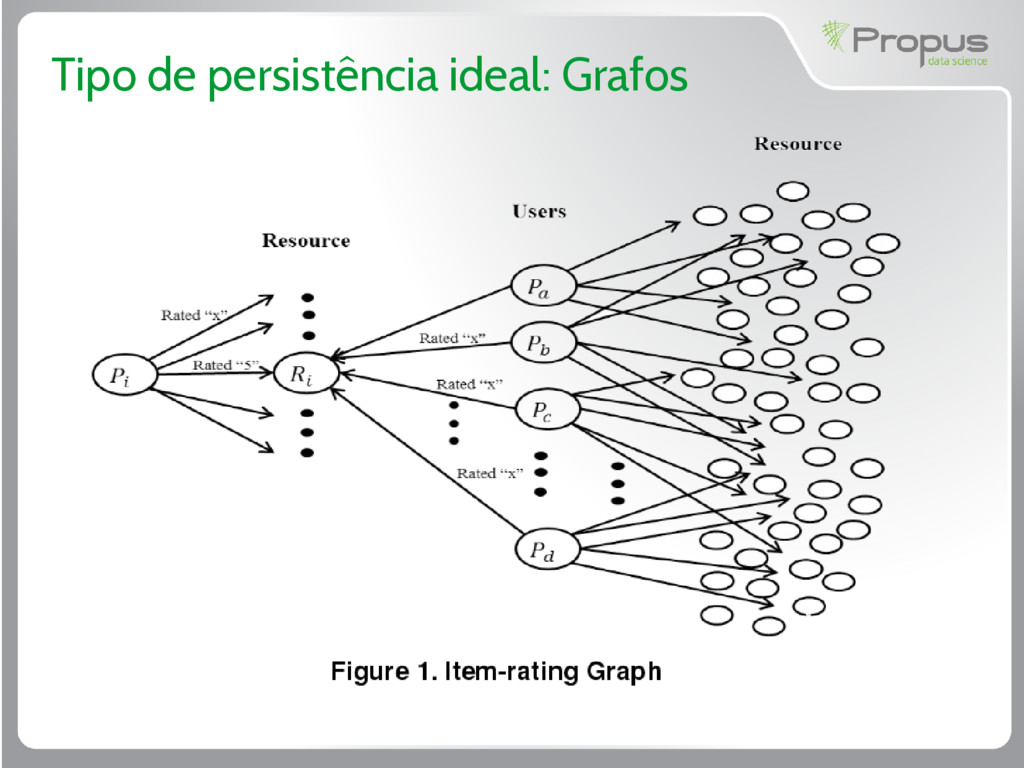
armazenar dados, nós, edges, etc; • Possível navegar entre os nós com alta velocidade; • São altamente escaláveis; • Possuem uma linguagem de consulta eficiente; • Exemplo de banco: Neo4J; • Exemplo de aplicação: recomendação de produtos;
• Exemplos: – ArangoDB → Suporta documentos (como MongoDB) e também suporta Grafos (como Neo4J) – OrientDB → Também suporta tanto documentos quanto grafos
banco pode ser melhor que outro; • Você pode ter uma aplicação onde mais de um banco pode ser o ideal; • Inclusive uso de SQL; • O SQL deve ser considerado nos cenários mais apropriados; • Sua aplicação pode exigir mais de um banco;
um e-commerce; • É a que recebe mais acessos (usuários ficam mais tempo pesquisando produtos); • Produtos possuem atributos diferentes: – Ex: SmartTV Panasonic 32” bivolt – Ex.: Geladeira Frostfree Brastemp Inox, 400 Litros; – Ex.: Notebook Asus 14”, 8Gb de RAM, 1Tb de Disco; • Como criar tantos atributos em um banco relacional? • Tabela de atributos?
produtos é a parte mais “pesada” da aplicação; • Com MongoDB é possível eliminar inúmeros joins e inner joins de um relacional; • Cria-se uma modelagem limpa, orientada a documento; • Utiliza-se todos os recursos do MongoDB como replica set para alta disponibilidade e sharding para escalabilidade; • É possível criar uma estrutura bastante elástica;
basicamente o código do produto; • Esse dado deixa de existir quando usuário efetua o pagamento ou desiste da compra; • Não há necessidade de persistir essa informação em disco; • São dados simples, chave/valor, podem ficar na memória; • Bancos recomendados: Redis, Memcached
a chave/valor como o Redis, não há necessidade de gerar I/O em disco; • Pode parecer pouco, mas imagine um site de venda de ingressos para um show ou final de campeonato de futebol (em poucos minutos, milhares de pessoas compram ao mesmo tempo); • Mantendo esses dados em memória, a aplicação fica bem mais dinâmica; • Precisa somente do ID da sessão do usuário seguido de um dicionário com os produtos e quantidades que foram adicionadas;
visualizando um produto ou depois de concluir a compra, algumas recomendações de outros produtos são apresentadas; • Essa recomendação vem de algoritmo, com base nas compras de outros usuários ou de outros parâmetros baseados na navegação e comportamento do usuário perante o site; • É o famoso “Quem comprou esse produto também comprou esses...”
ideal para essa etapa da aplicação; • A medida que os usuários votam, comentam, indicam ou realizam alguma ação, esse comportamento é registrado e serve para indicar produtos relacionados; • Bancos recomendados: Neo4J ou ArangoDB;
de rotinas de: – Anti-fraude; – Sistema de crediário; – Comunicação com operadoras de cartão de crédito; – Comunicação com bancos (TED); – Liberação do produto, retirada de estoque;
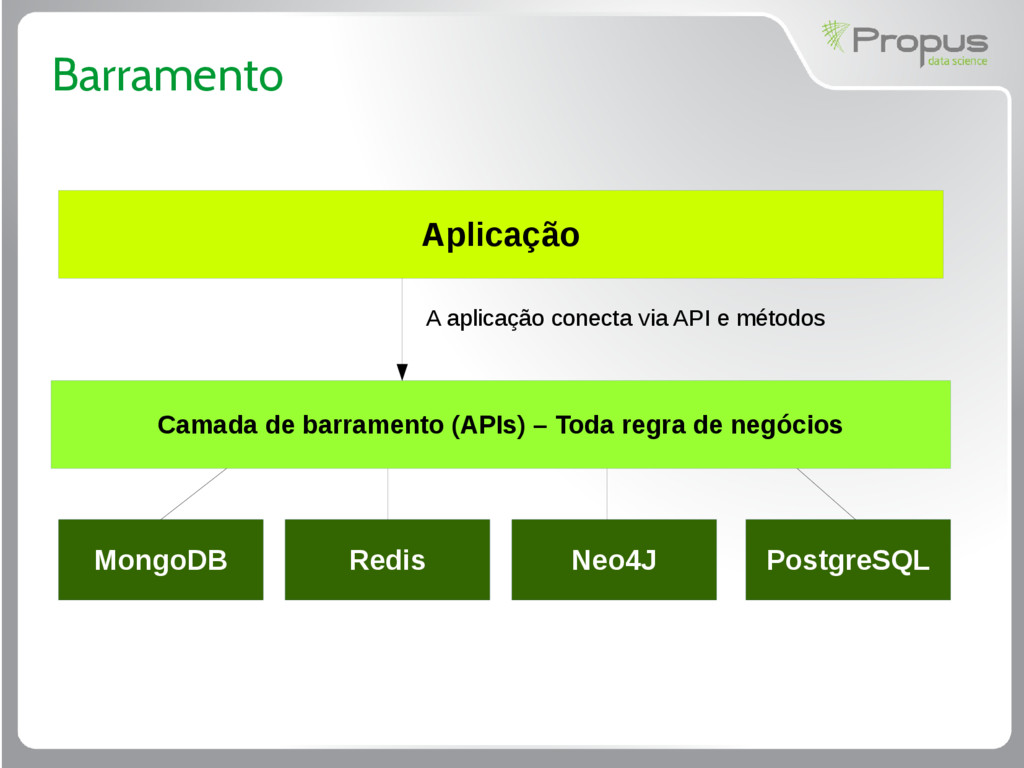
aplicação, pense em várias aplicações trabalhando em conjunto; • Cada aplicação tem suas próprias regras e suas características, pode ter seu tipo de persistência; • A inteligência do negócio fica no “barramento”
regra do negócio; • É onde toda programação pesada e inteligência do negócio está concentrada; • A aplicação pode ser apenas um frontend, mobile, API de terceiros que consome os métodos disponíveis no barramento (adicionar_carrinho, obter_produto, obter_recomendacao, etc)
schema design e boas práticas; • Não adianta separar toda aplicação em aplicações menores se as boas práticas de cada tipo de persistência não é seguido;
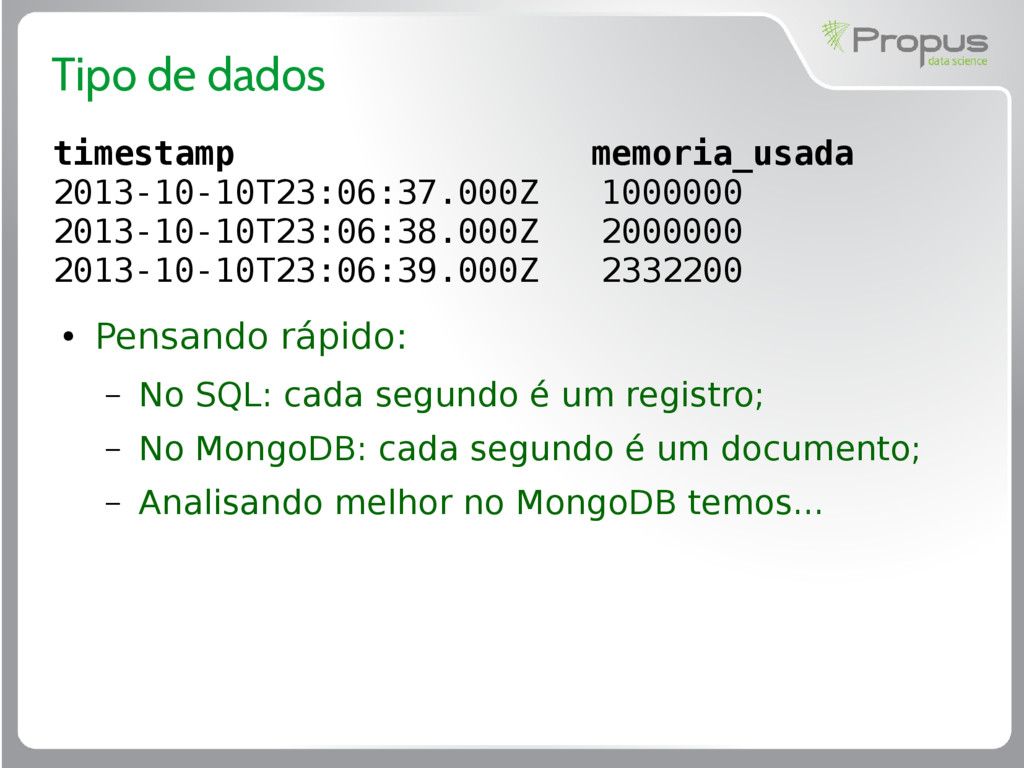
o schema design bem elaborado aumenta a performance, reduz o uso de recursos (CPU, Memória, Disco) e facilita o desenvolvimento • Caso de uso: Série temporal (logs);
86.400 segundos; • Então, são 86.400 documentos por coleção; • Uma query de um dia, necessário varrer 86.400 documentos; • Query de um ano são aproximadamente 31.550.00 documentos; • Para o MongoDB é pouco, mas podemos organizar melhor isso.
“memory_used”, values: { 0: 999999, … 37: 1000000, 38: 1500000, … 59: 2000000 } } Todos os 60 segudos das 23:06 estão guardadas em um único documento, onde cada segundo representa um sub-documento
86.400 segundos); • Então teremos 1.440 documentos em um dia; • O scan de uma consulta diária é reduzida de 86.400 documentos para 1.440 documentos; • Uma consulta anual retorna 525.600 documentos, contra mais de 31 milhões no schema anterior; • E ainda podemos melhorar mais...
24 documentos por dia; • Para pegar todo o histórico de um ano, será necessário varrer apenas 8.760 documentos; • Neste ponto, chegamos em um nível interessante de granularidade de dados!
ajuda muito na organização de dados em bancos não relacionais; • É necessário entender as particularidades de cada banco; • No MongoDB, pensar em como agregar esses dados, como escalar; • No Neo4J, pensar como os nós são organizados para obter uma melhor navegação; • No Redis, pensar como buscar chaves e valores rapidamente; • Usar SQL para aquilo que ele faz bem, tirando tarefas excessivas dele.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}