Palestra apresentada na Campus Party Brasil 12.
Nesta palestra, a ideia é desmistificar alguns conceitos sobre Inteligência participal e principalmente Machine Learning e refletir sobre como ele tem revolucionado as nossas vidas. Não à toa, empresas como Google, IBM, Microsoft, Amazon têm direcionado times inteiros para desenvolver tecnologias de análise de dados. Quais são as tecnologias e ferramentas por trás desse conceito? E qual o nosso papel em tudo isso? O objetivo é apresentar algumas aplicações reais de como essa tecnologia tem mudado o mercado e explicar alguns conceitos básicos dos algoritmos responsáveis por essas automações isso.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
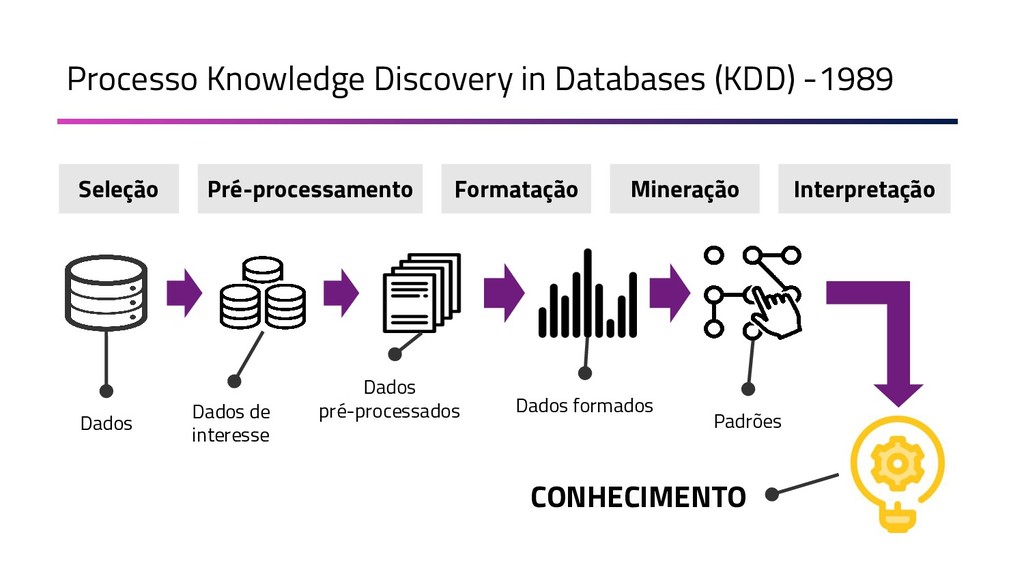{kind=link}
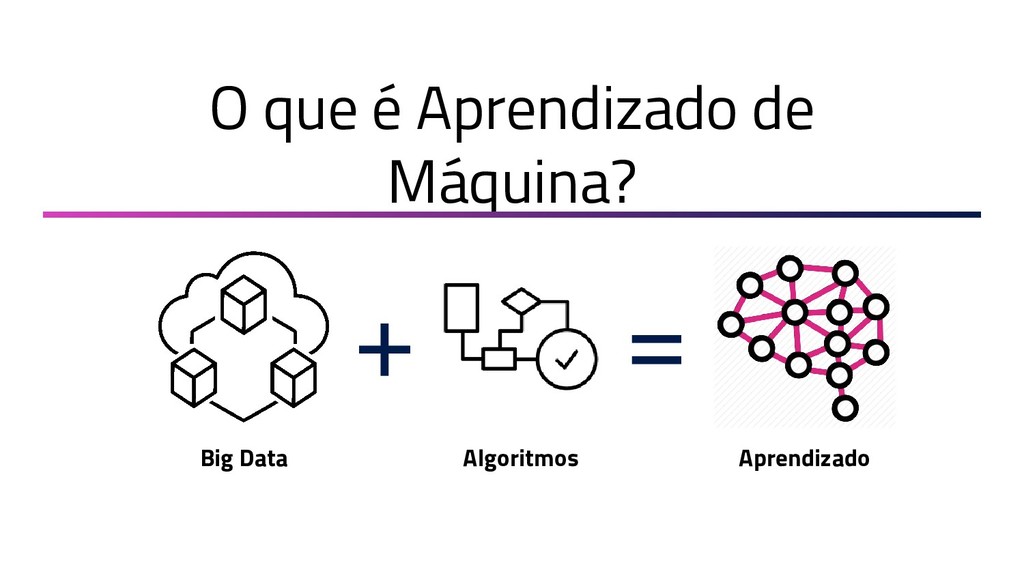{kind=link}
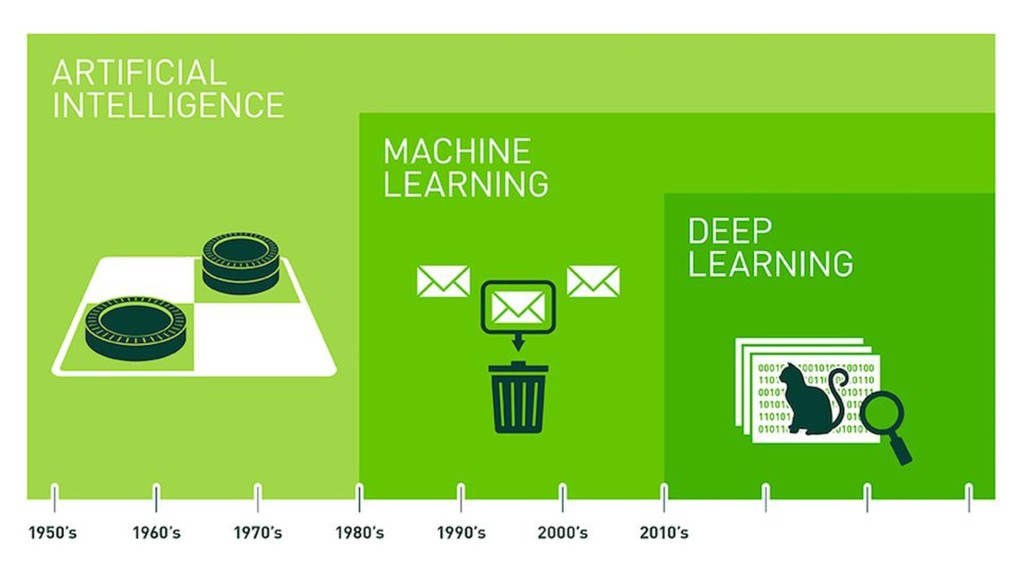{kind=link}
{kind=link}
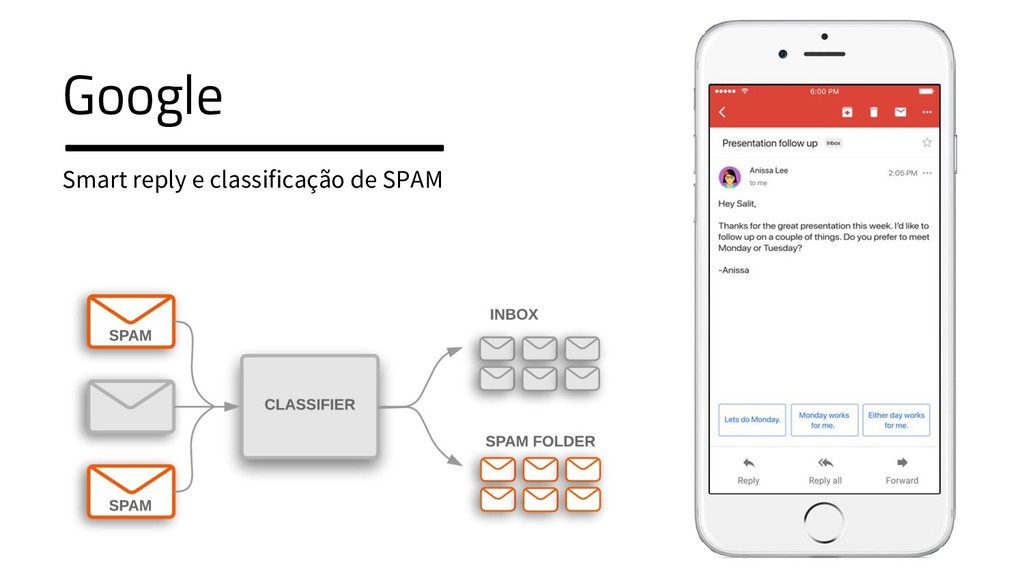{kind=link}
{kind=link}
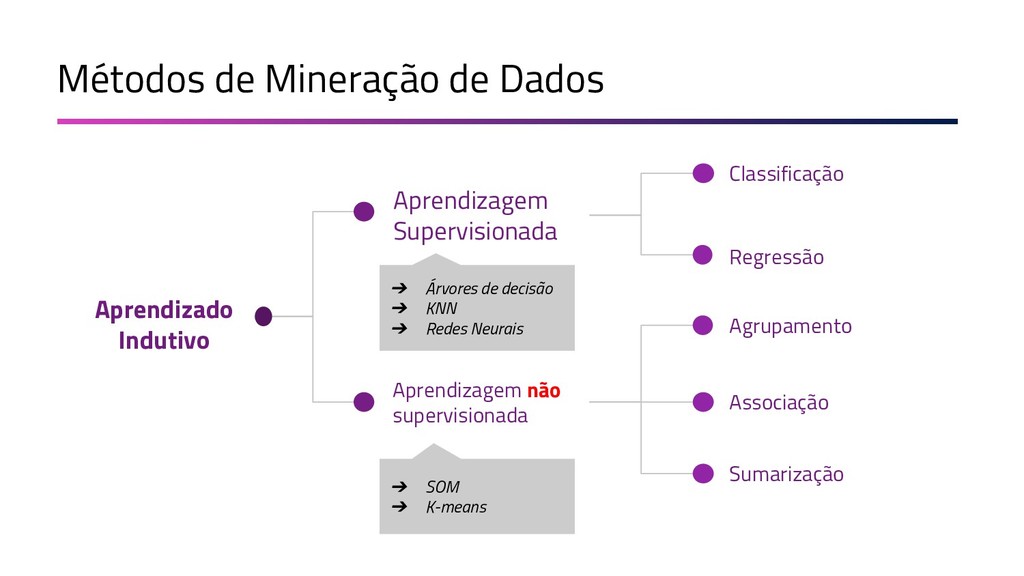{kind=link}
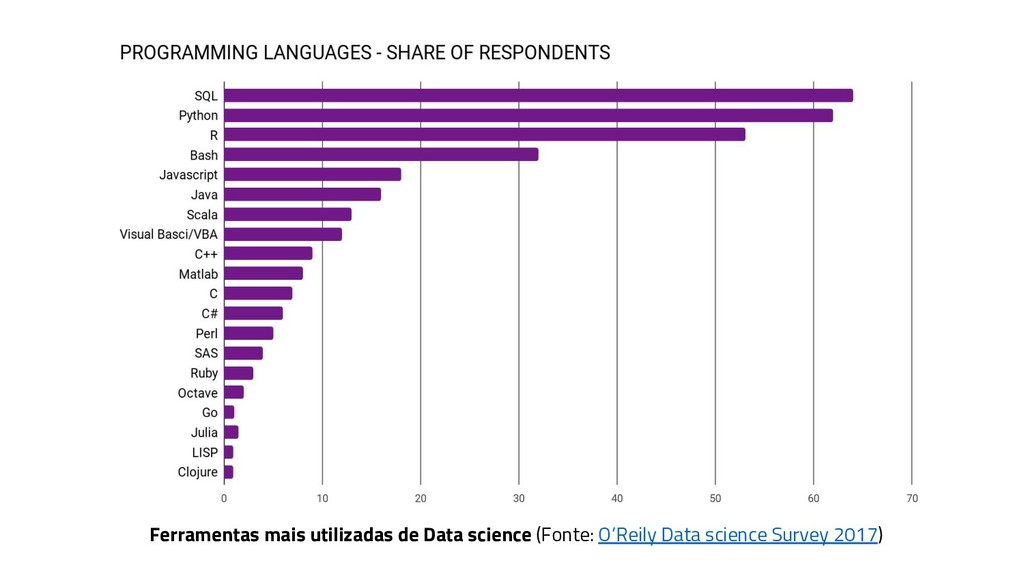{kind=link}
{kind=link}
{kind=link}
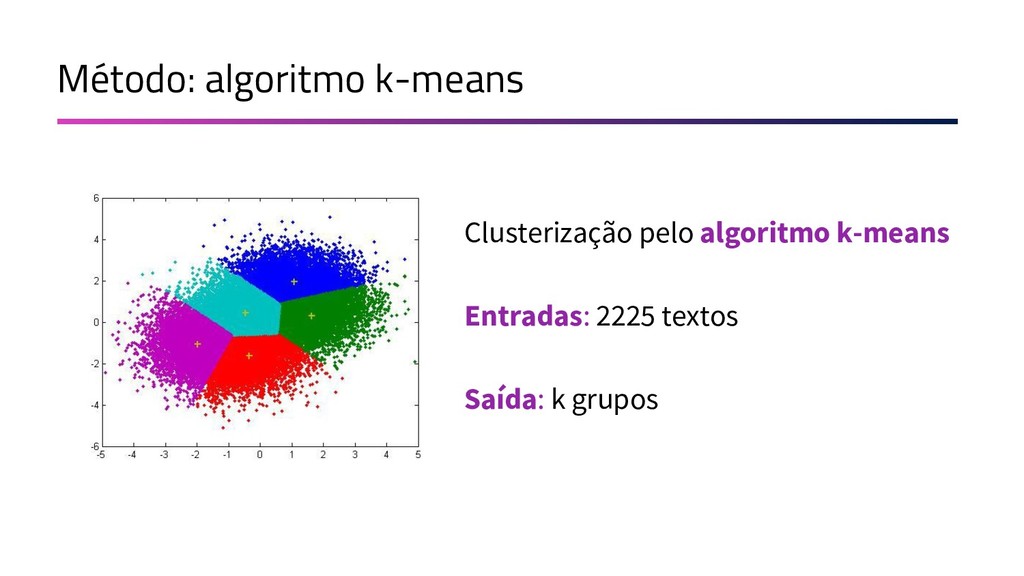{kind=link}
{kind=link}
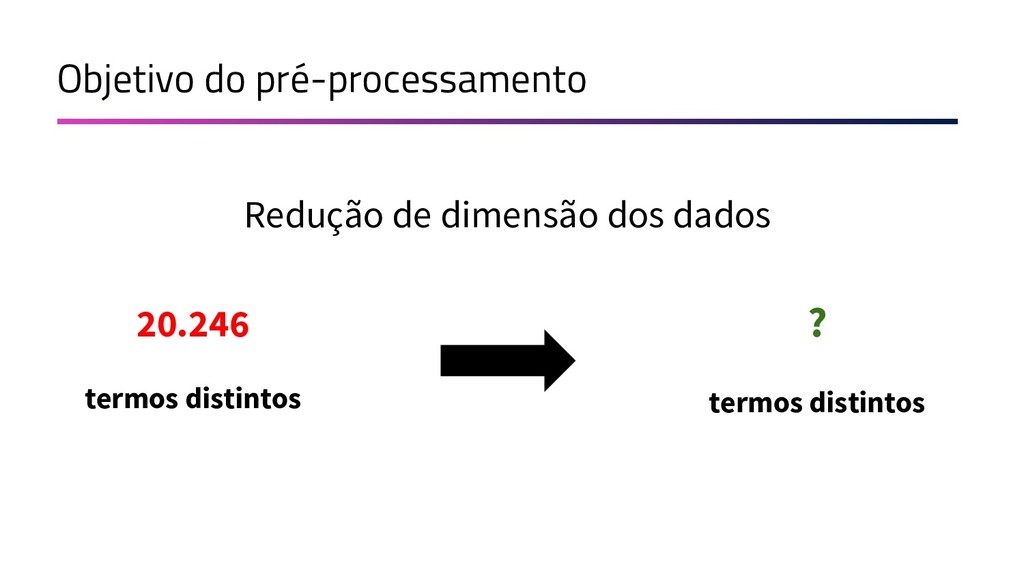{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
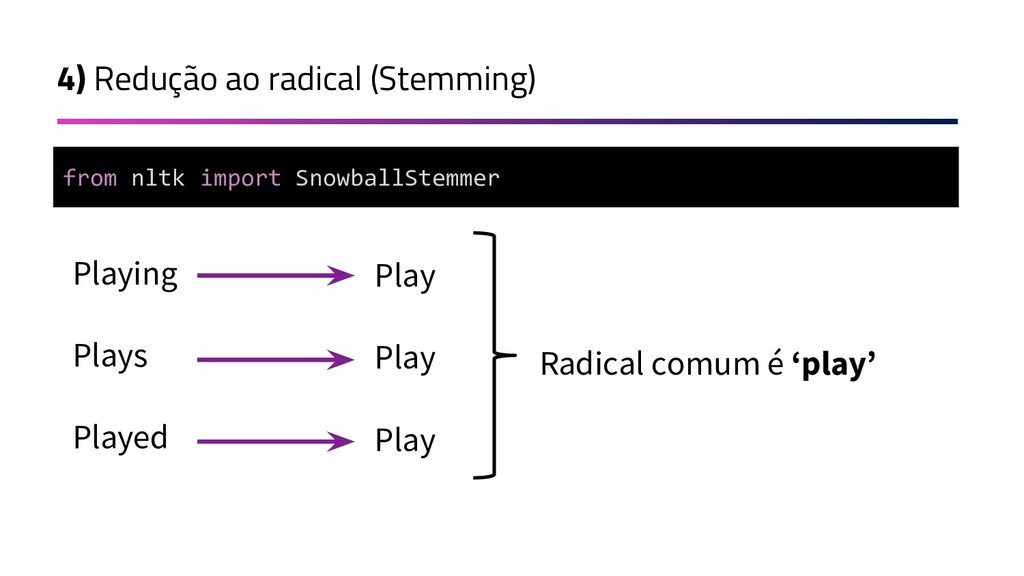{kind=link}
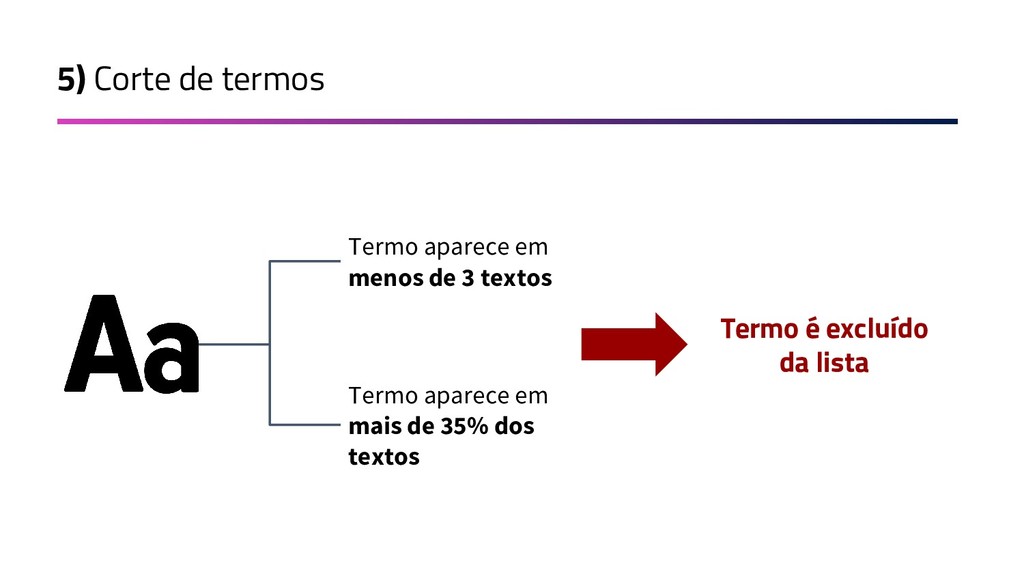{kind=link}
{kind=link}
{kind=link}
{kind=link}
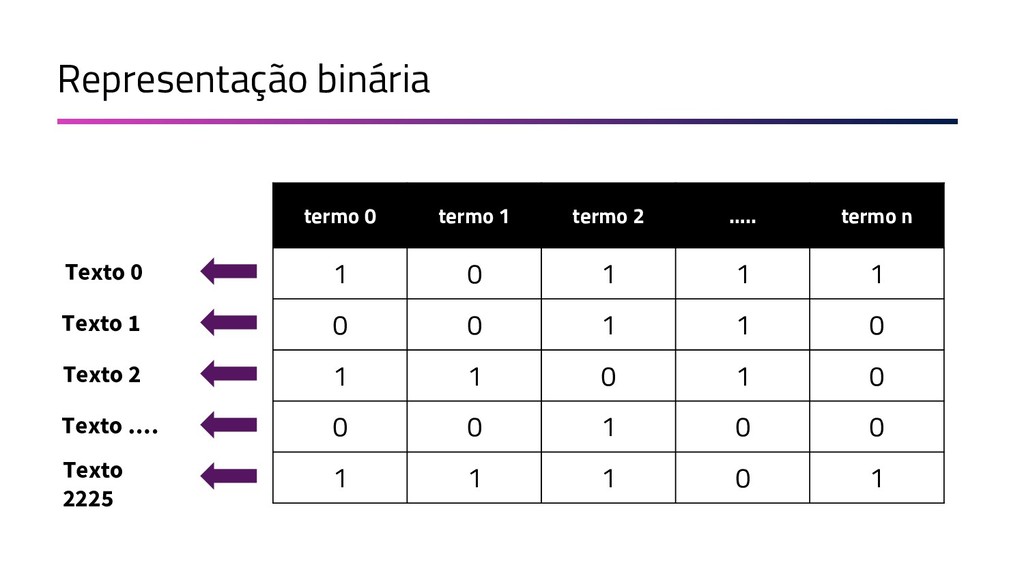{kind=link}
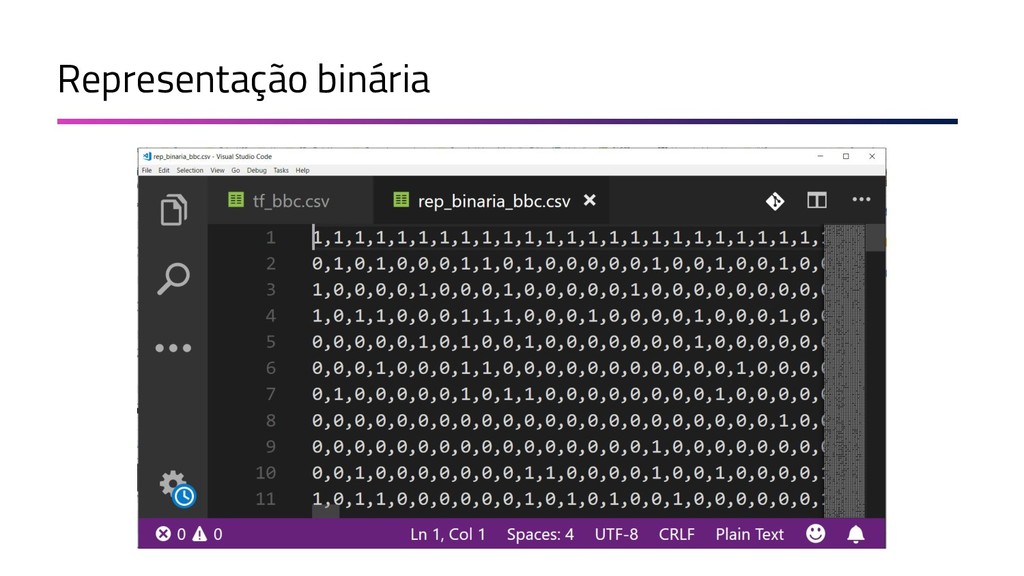{kind=link}
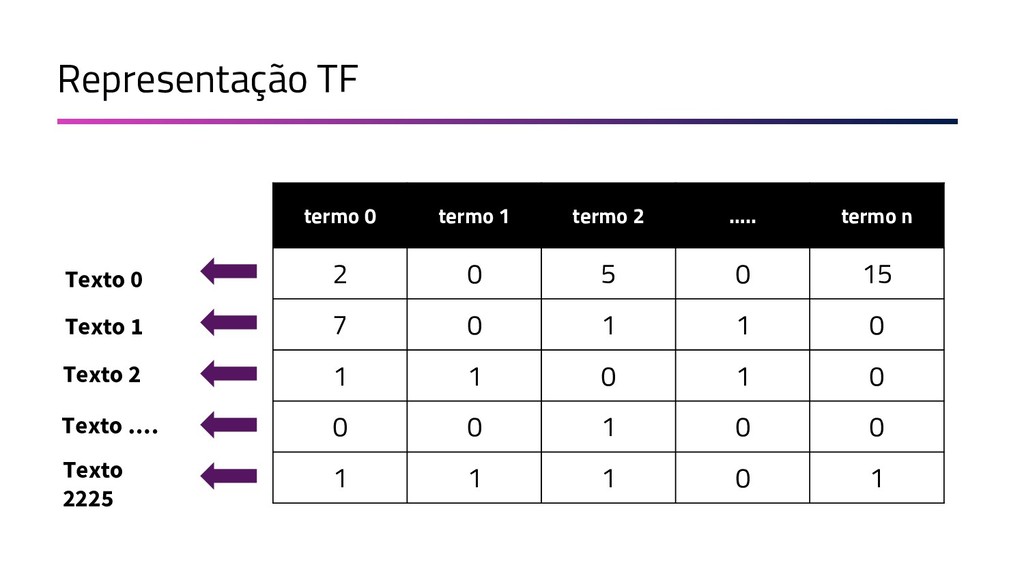{kind=link}
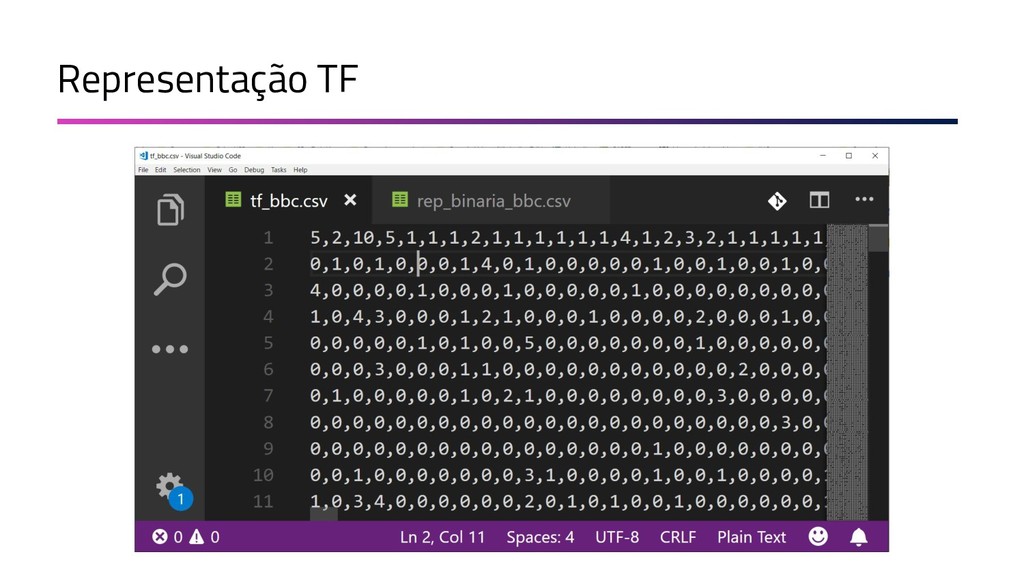{kind=link}
{kind=link}
{kind=link}
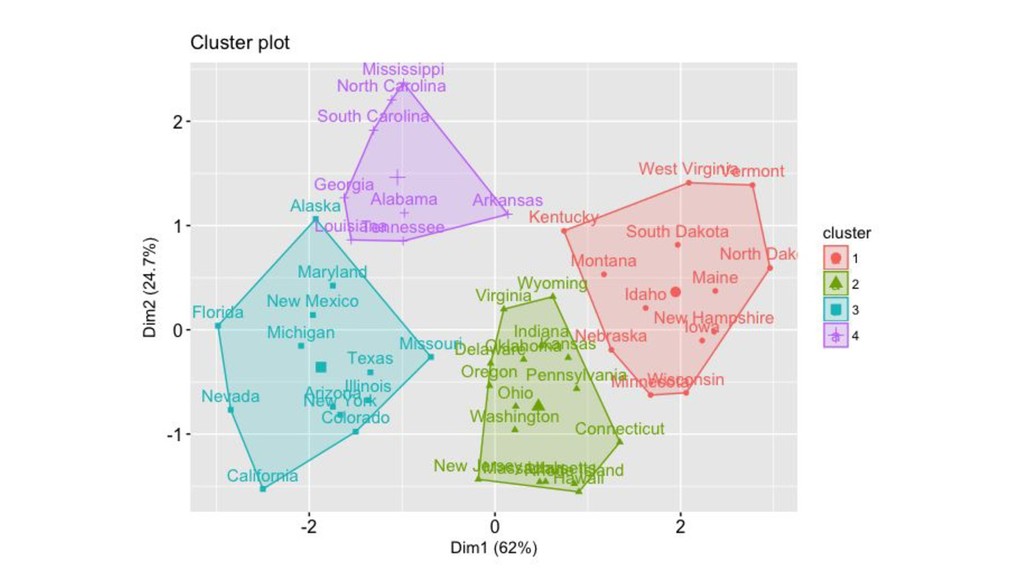{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}