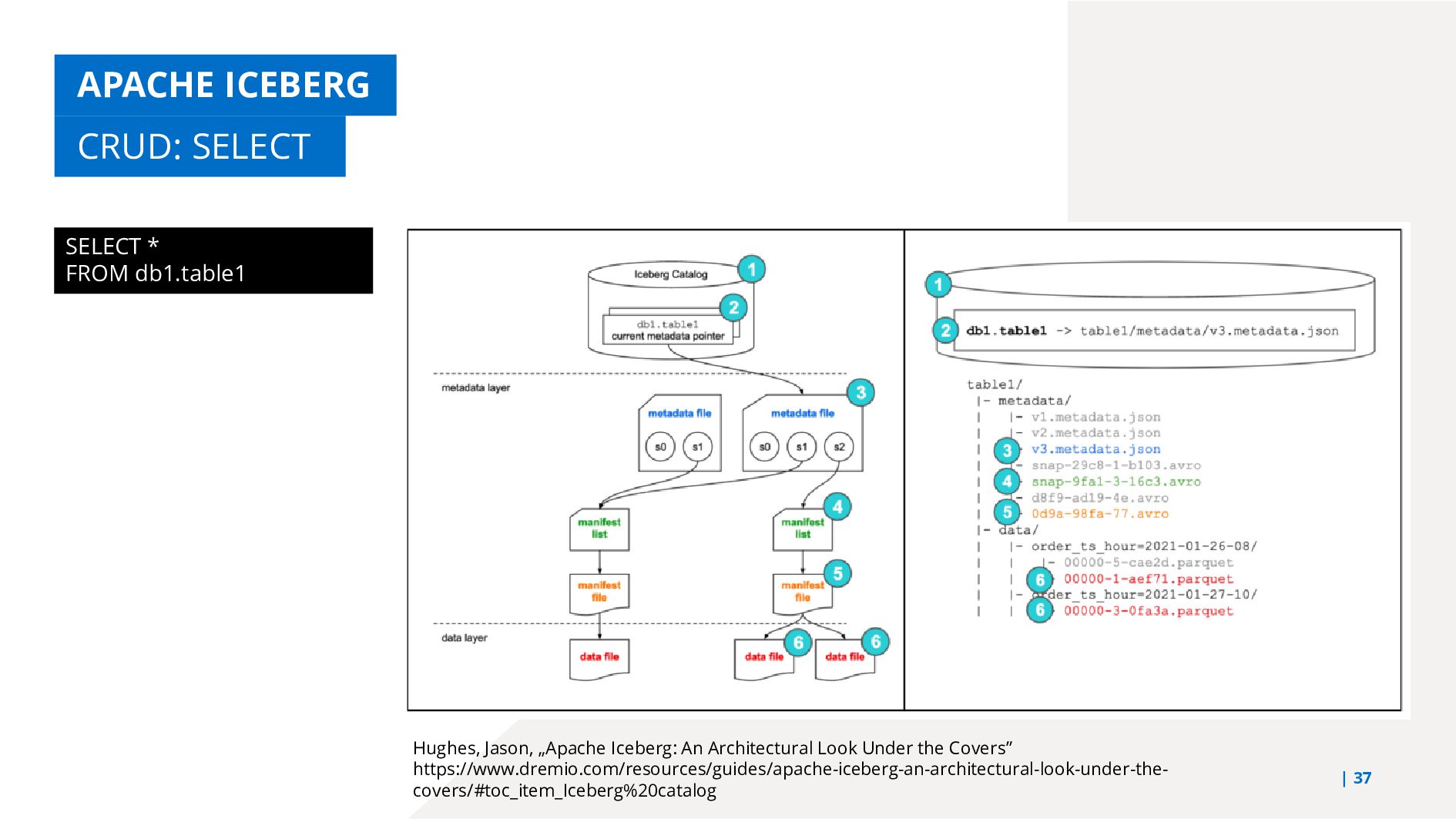
Today's world is dominated by big data and the opportunities it presents. From medicine to agriculture, there is no sector that is not affected by it. But harnessing and managing it is a challenge. In recent years, data lakes have emerged as the ideal solution for big data analysis. A data lake stores data from different sources and in different formats in its raw state. This offers great advantages, including system scalability, compute-on-demand to optimize costs, and the ability to iteratively adjust analytic processes to extract new, previously hidden information from existing data. However, data lakes also present data governance challenges, including inadequate support for ACID transactions and versioning mechanisms. Experts are proposing a new solution: the data lakehouse, a hybrid of data lake and data warehouse that combines the compliance of data warehouses with the flexibility of data lakes. This is made possible by an emerging technology: the Open Table Format. This talk introduces the architecture of the data lakehouse and the technology of the Open Table Format with special reference to Apache Iceberg.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
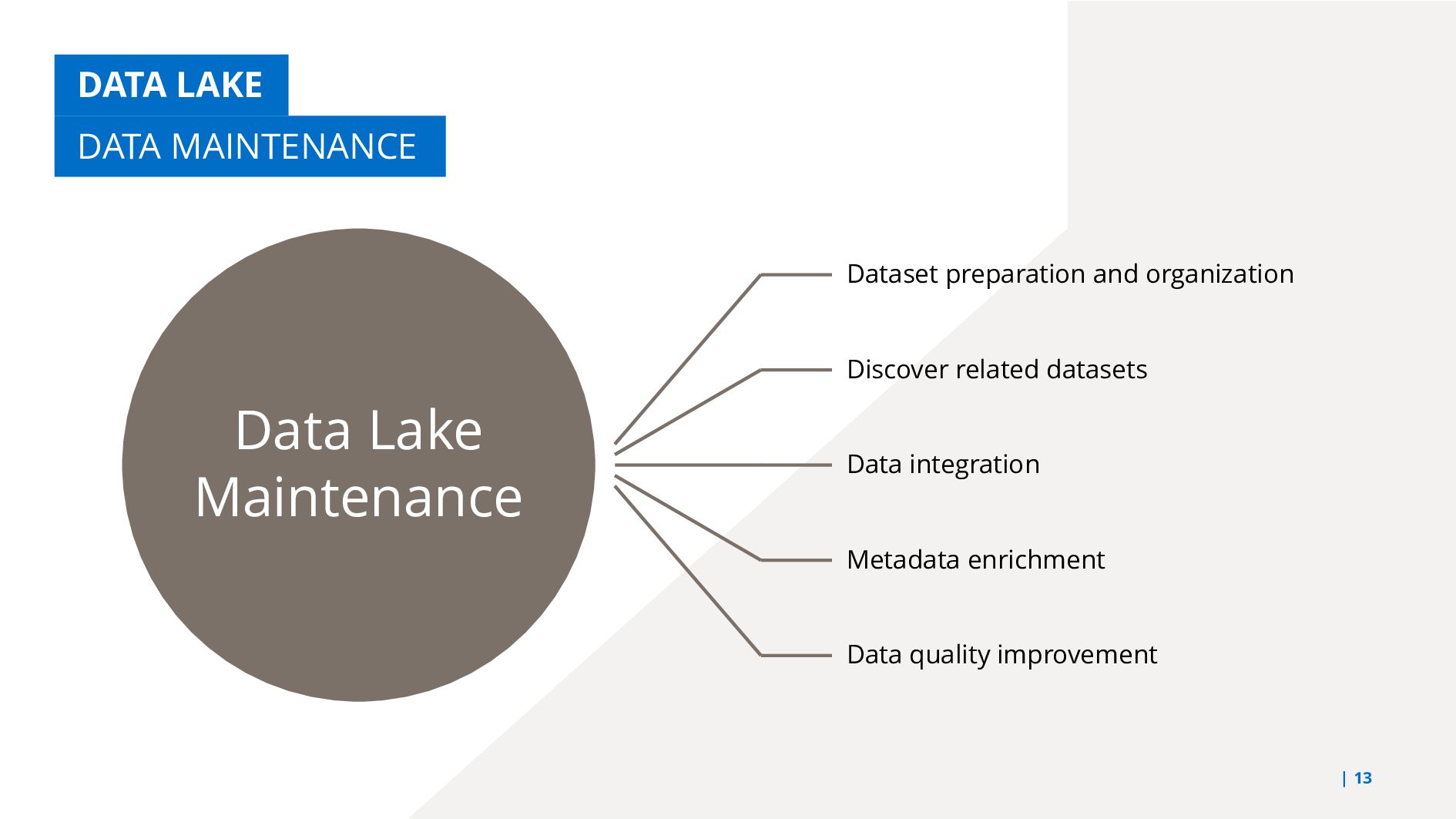{kind=link}
{kind=link}
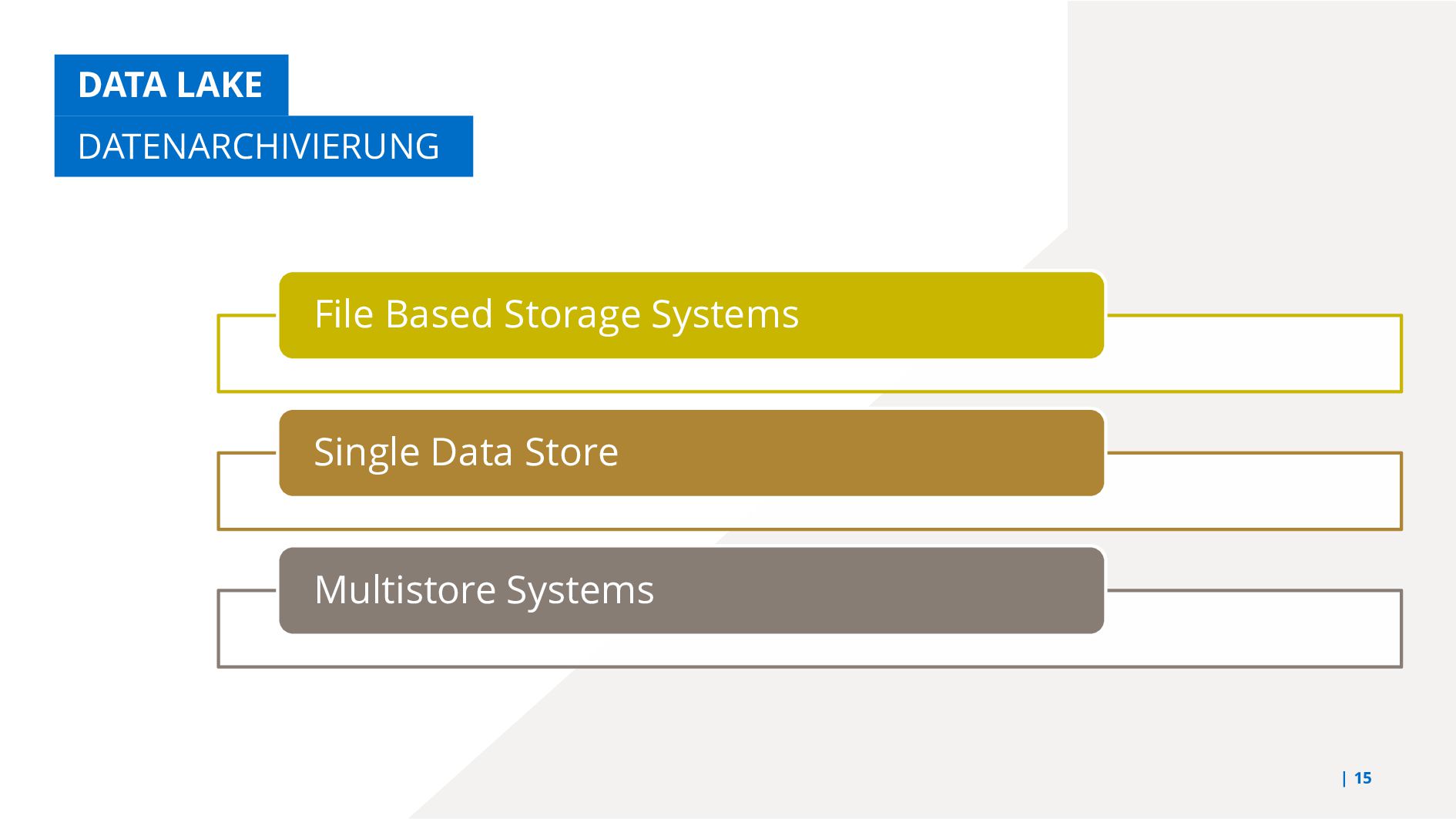{kind=link}
{kind=link}
{kind=link}
{kind=link}
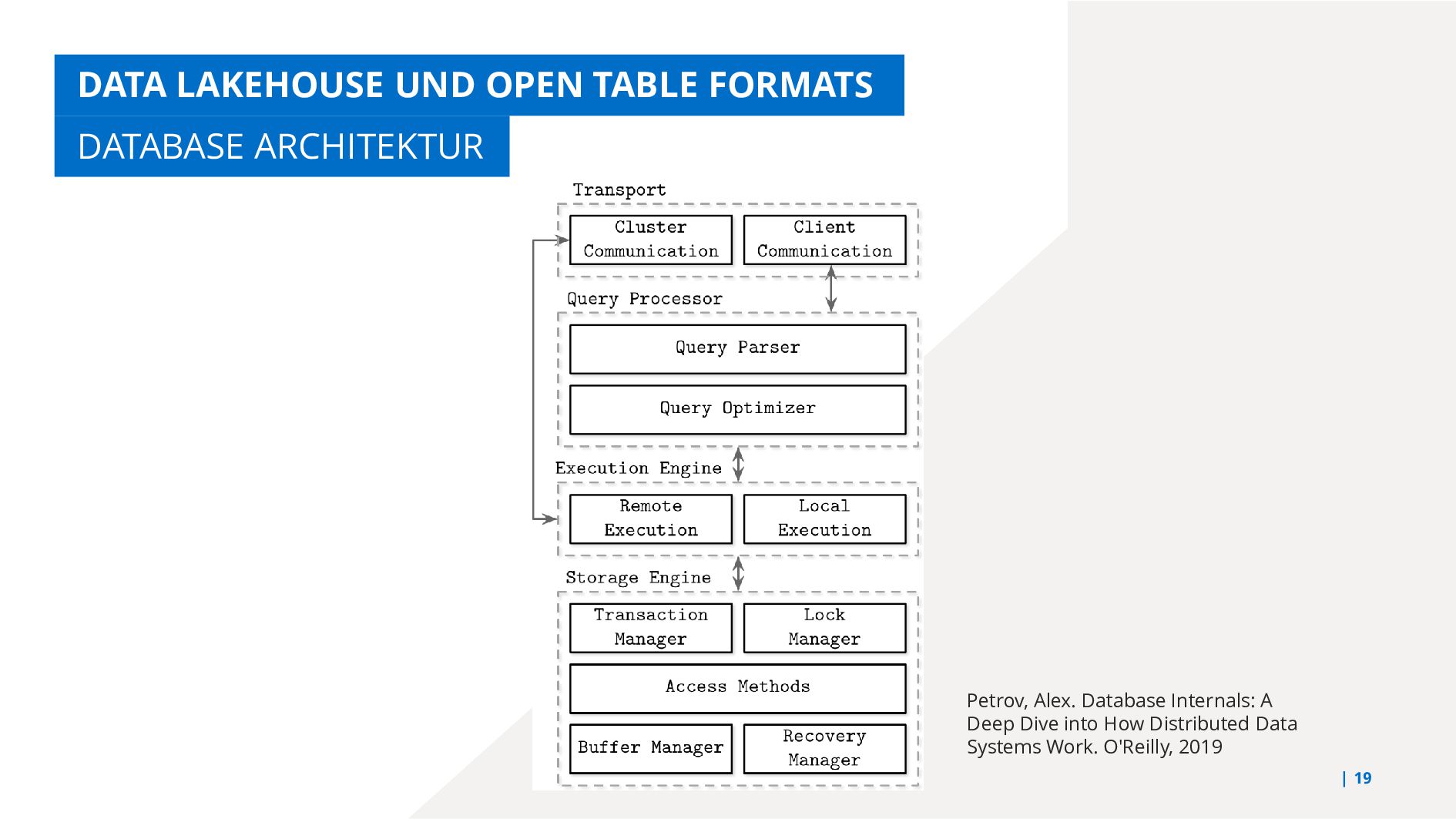{kind=link}
{kind=link}
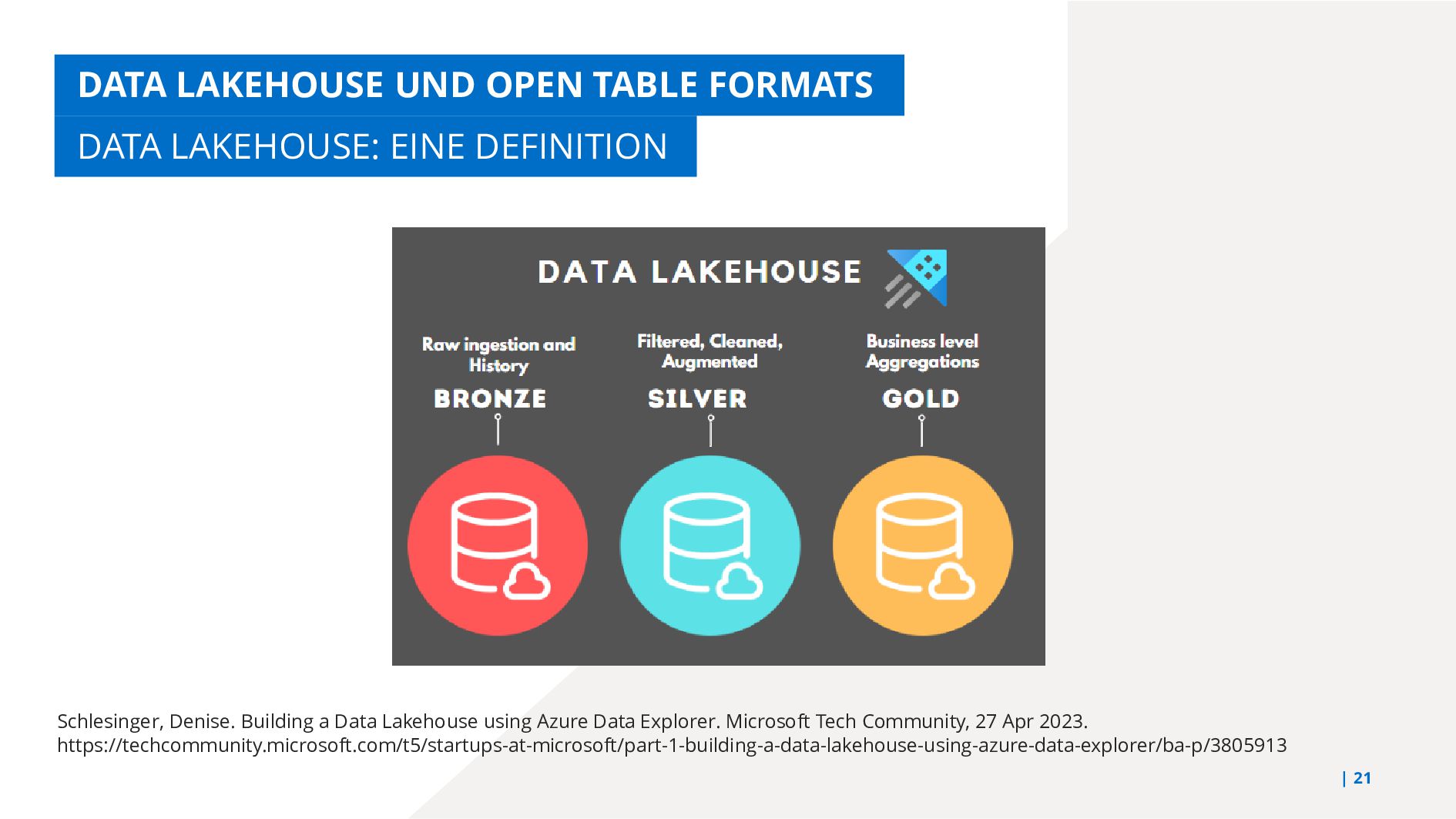{kind=link}
{kind=link}
{kind=link}
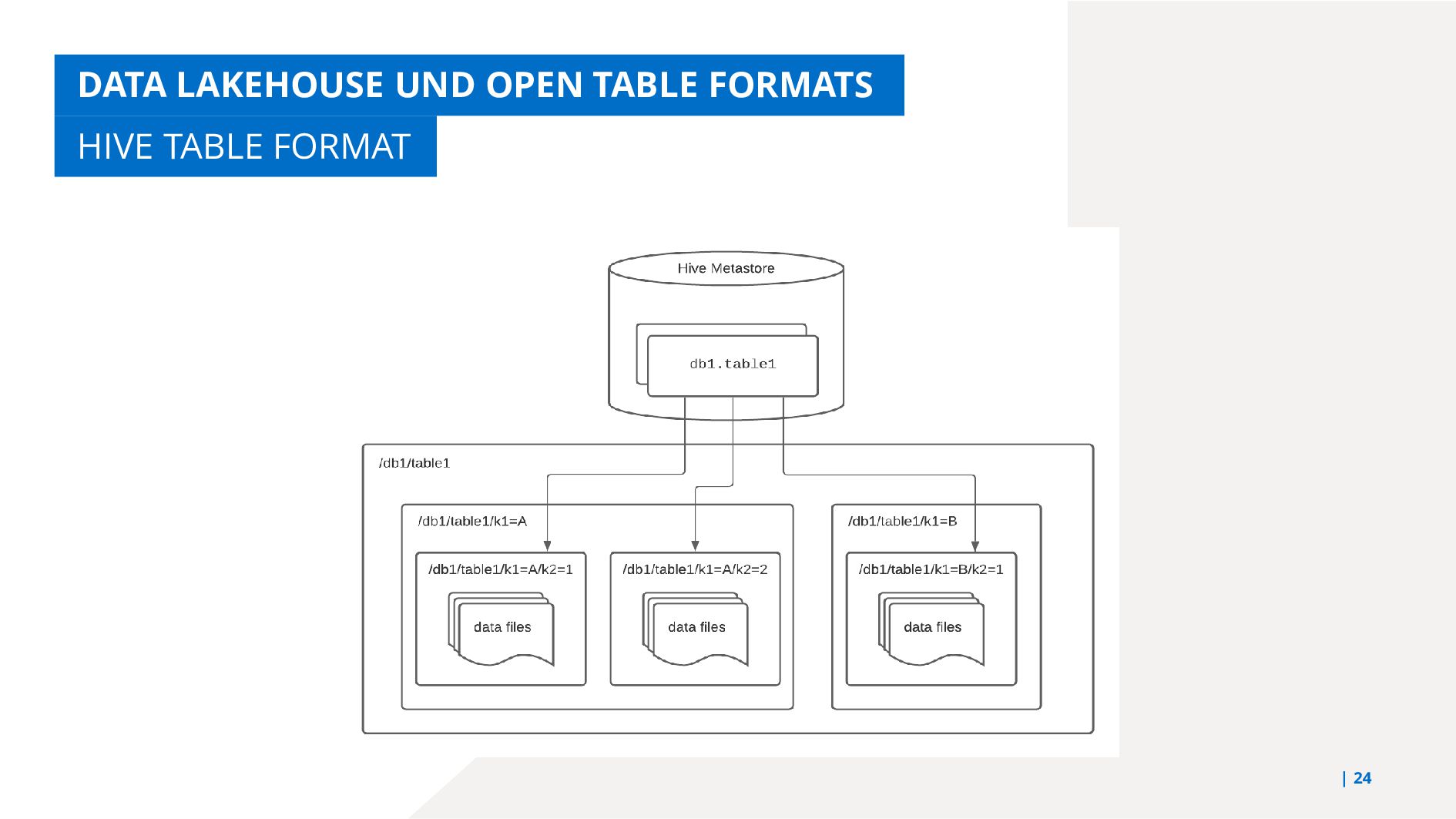{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
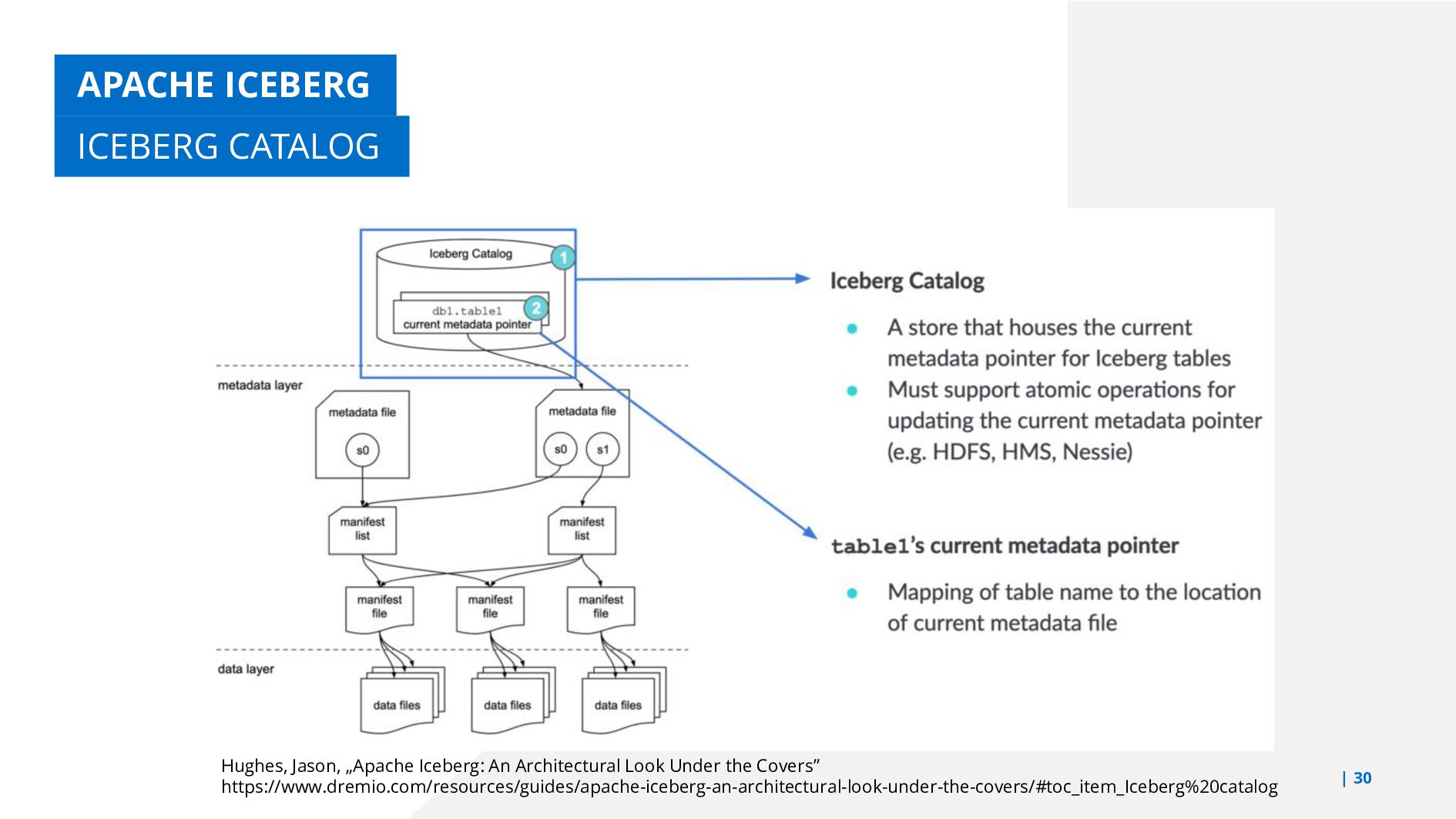{kind=link}
{kind=link}
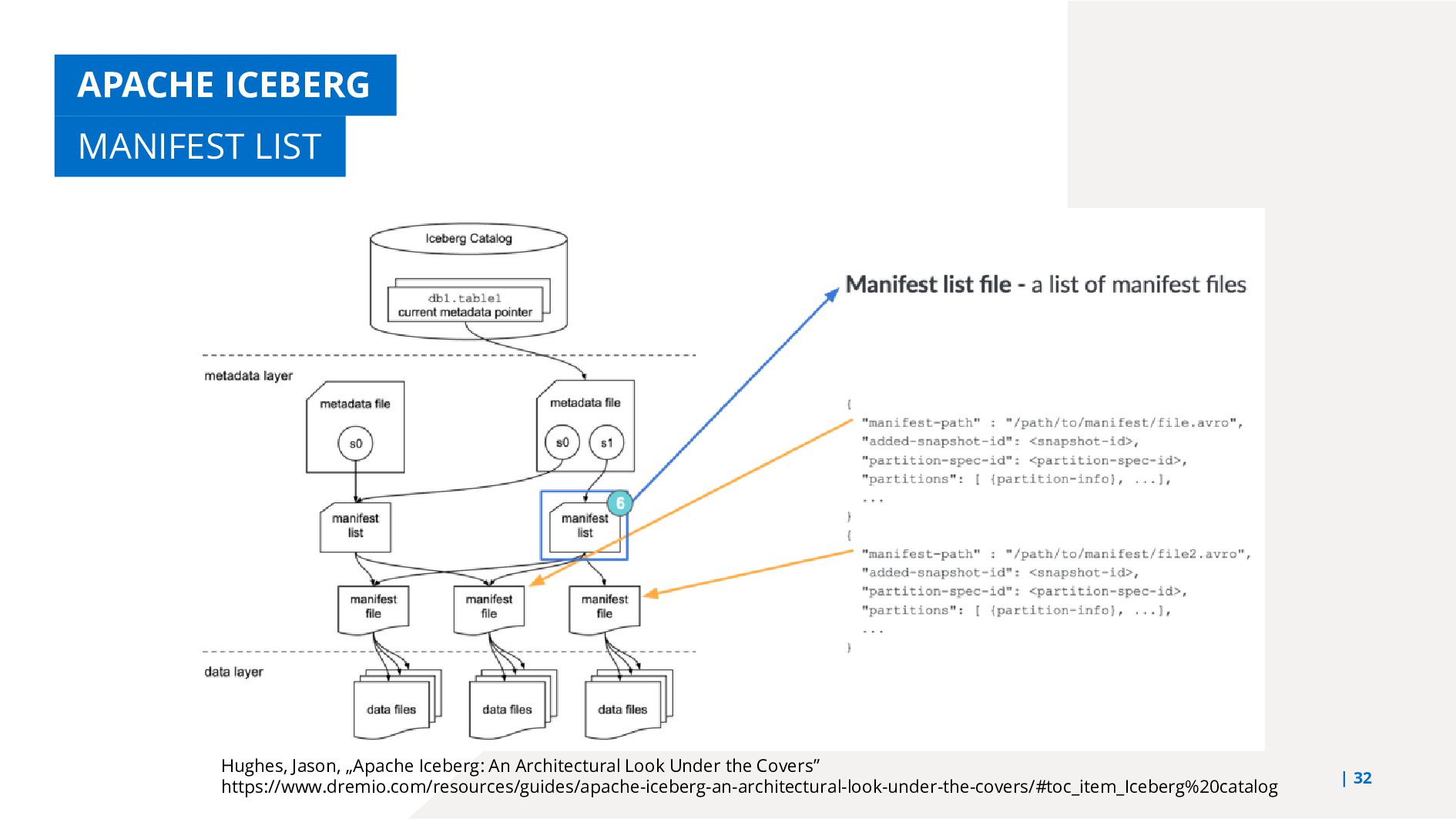{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}