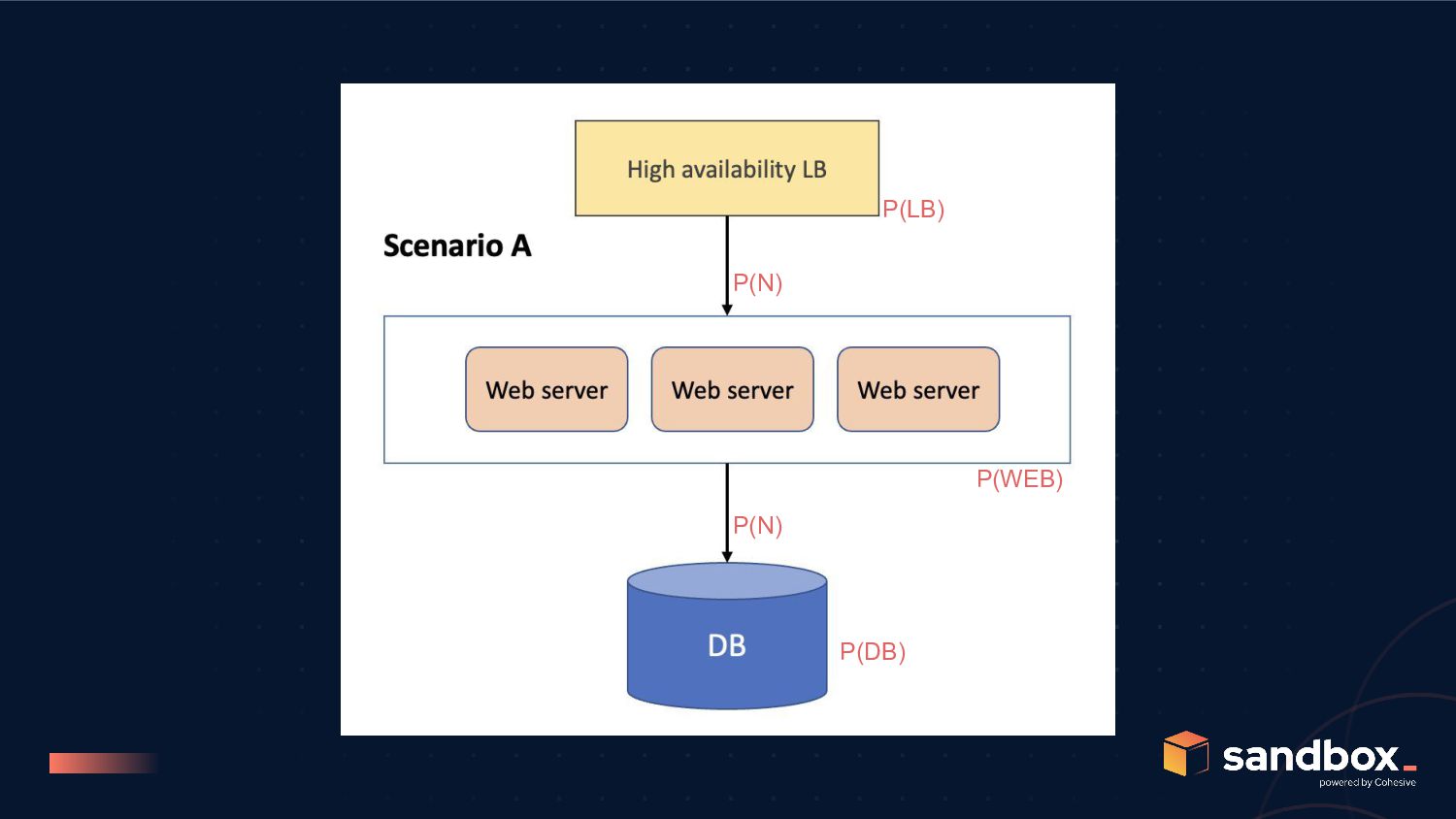
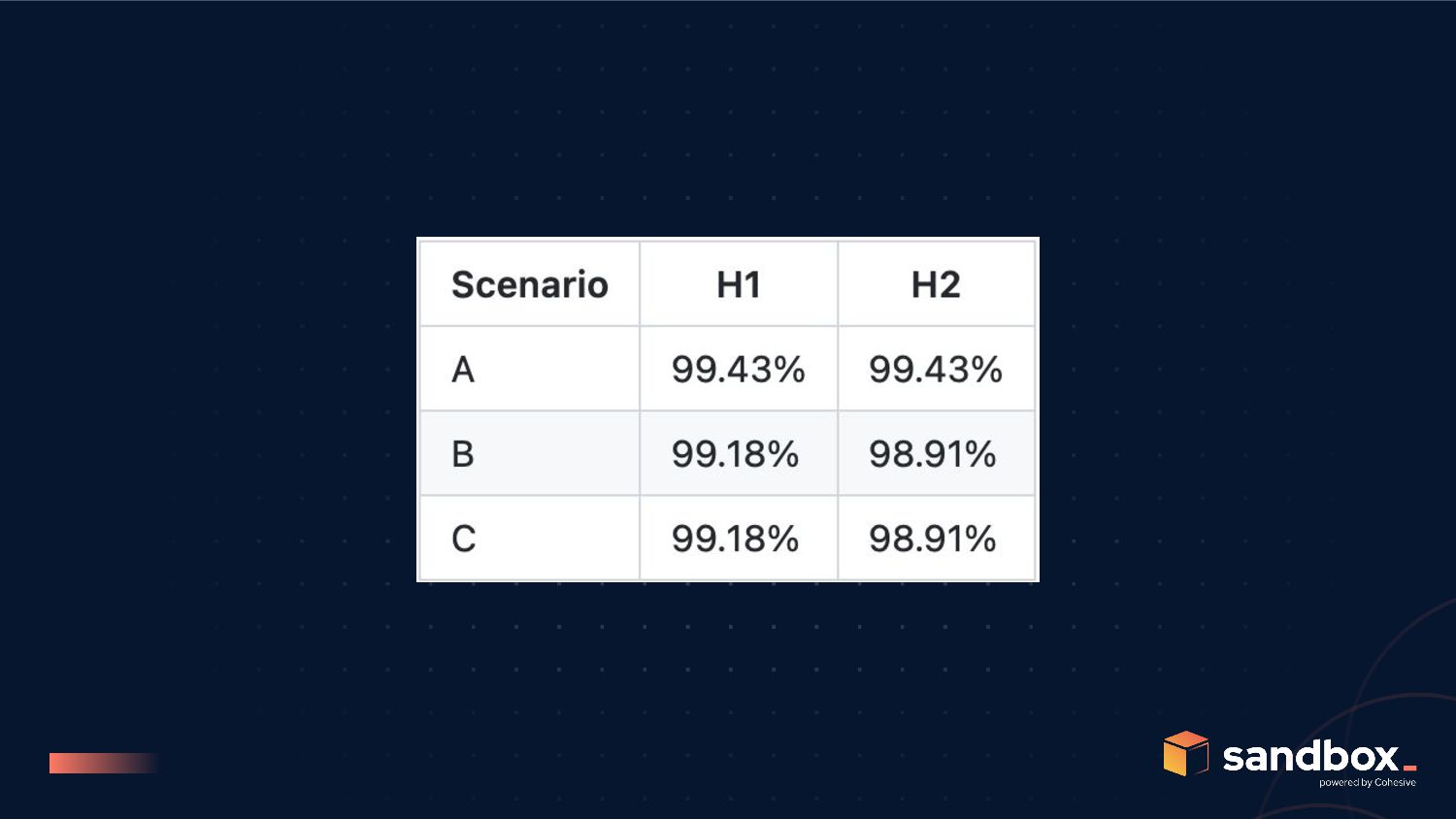
refactoring improved web server and microservice availability P(WEB) = 99.7% P(SVC) = 99.7% Hypothesis B refactoring decreased web server and microservice availability P(WEB) = 99.5% P(SVC) = 99.5%
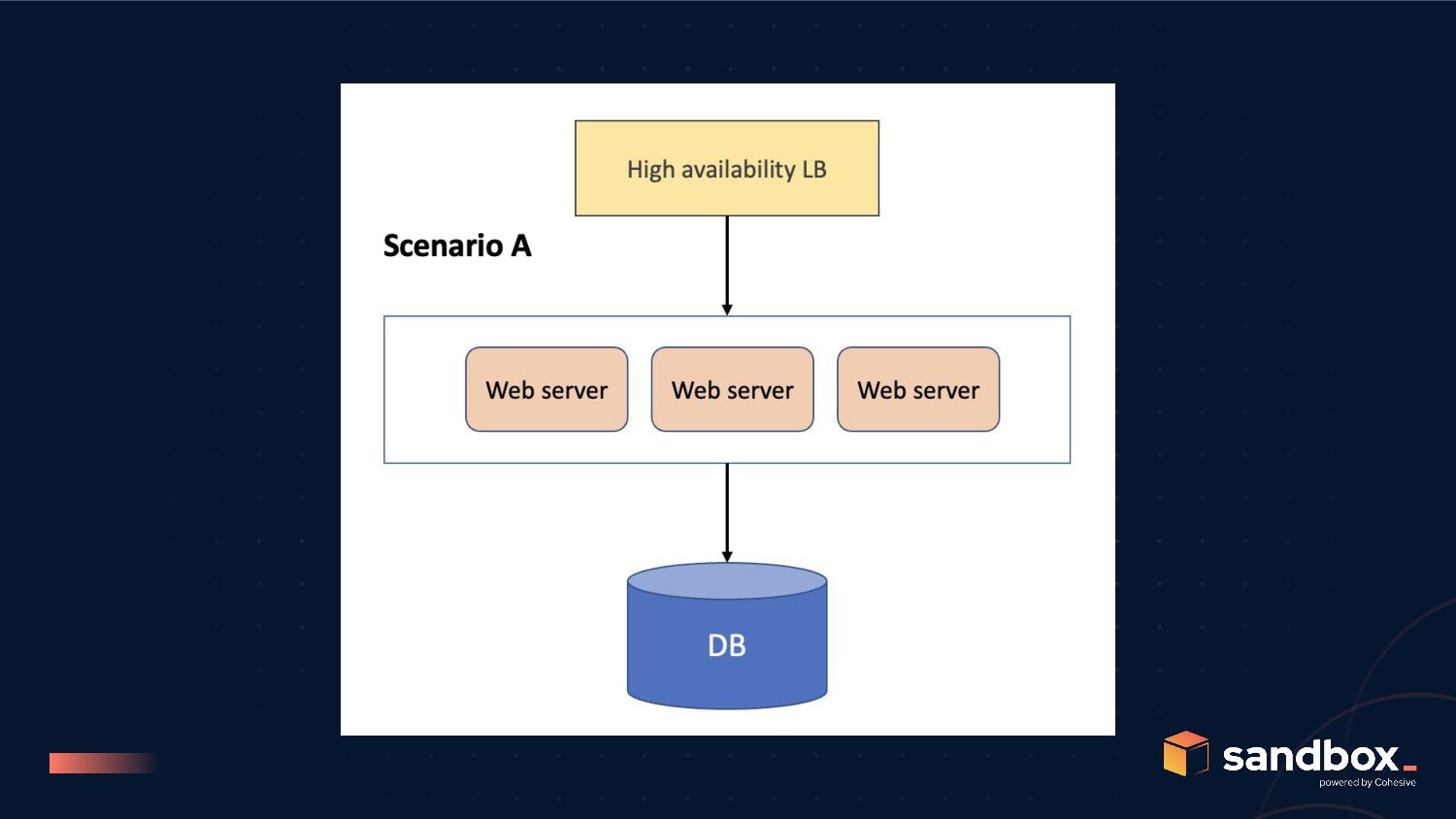
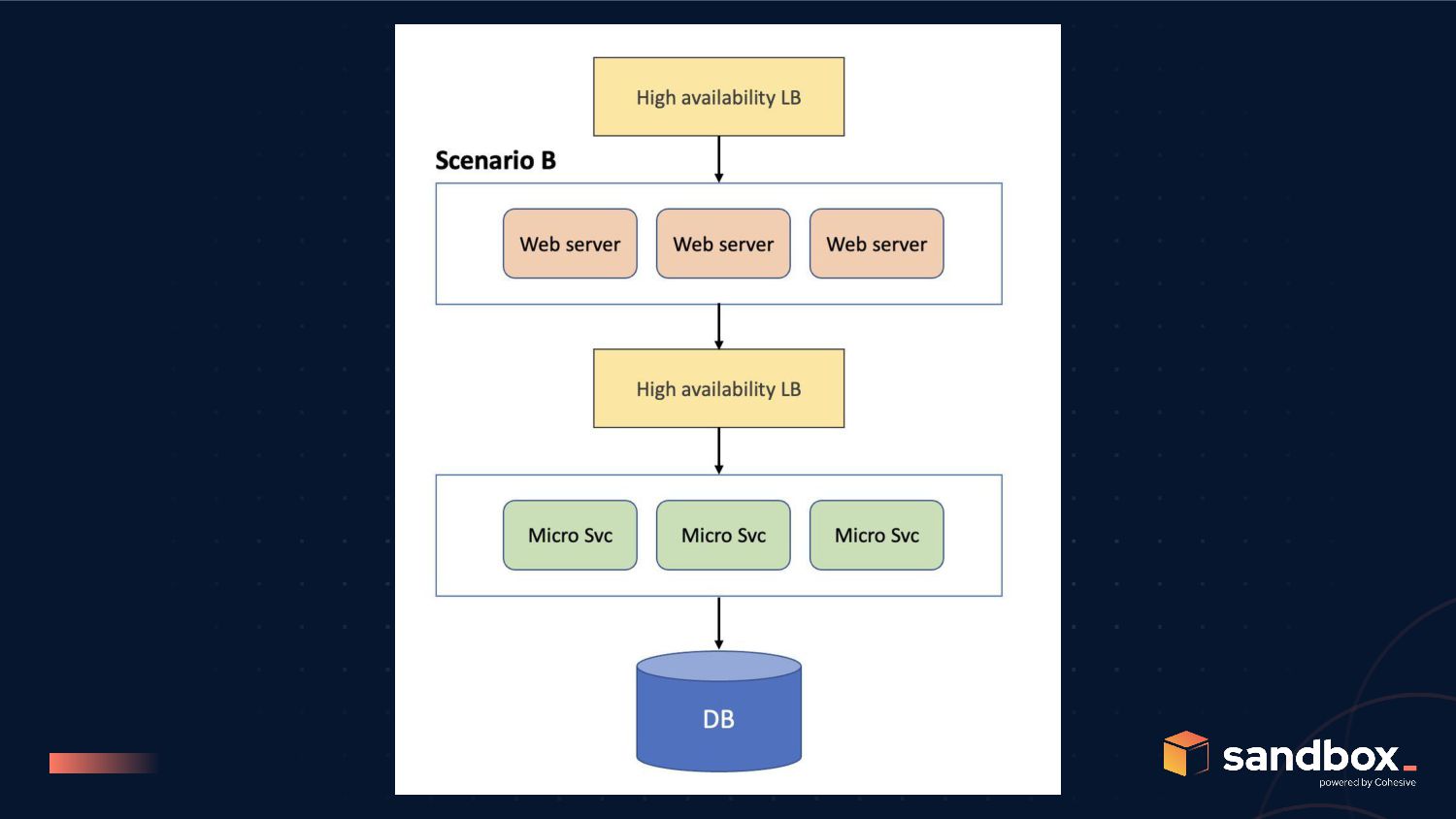
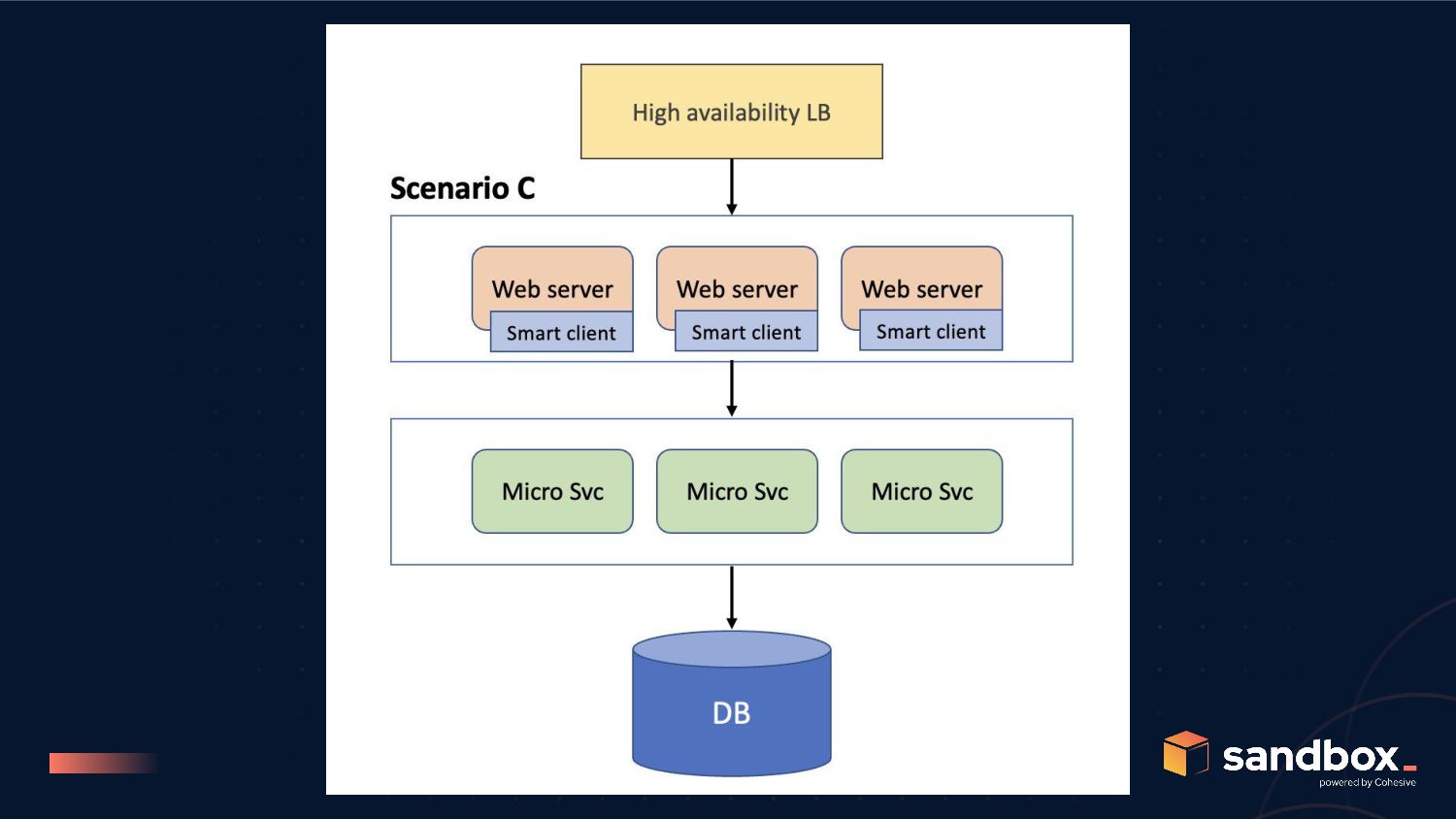
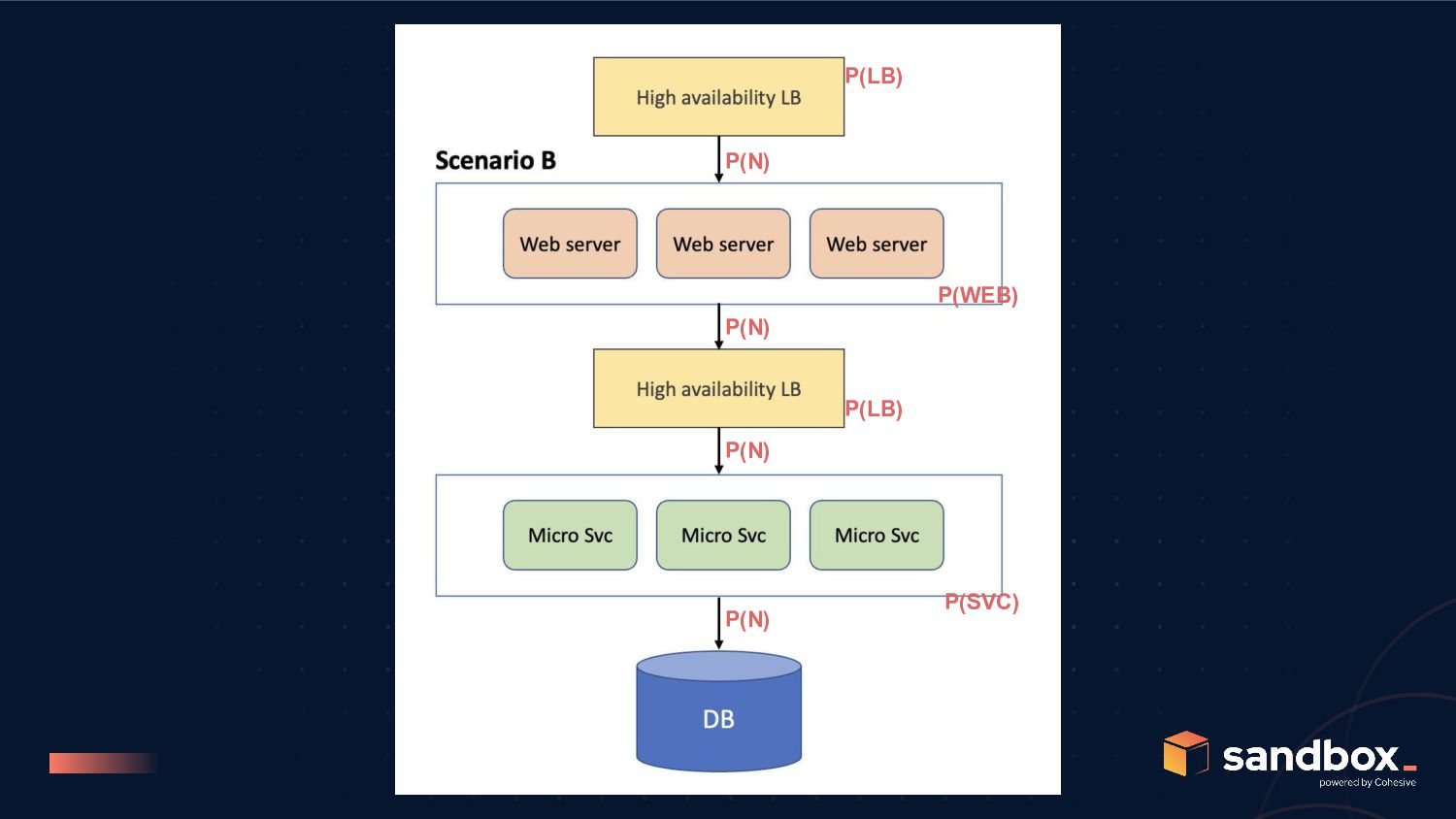
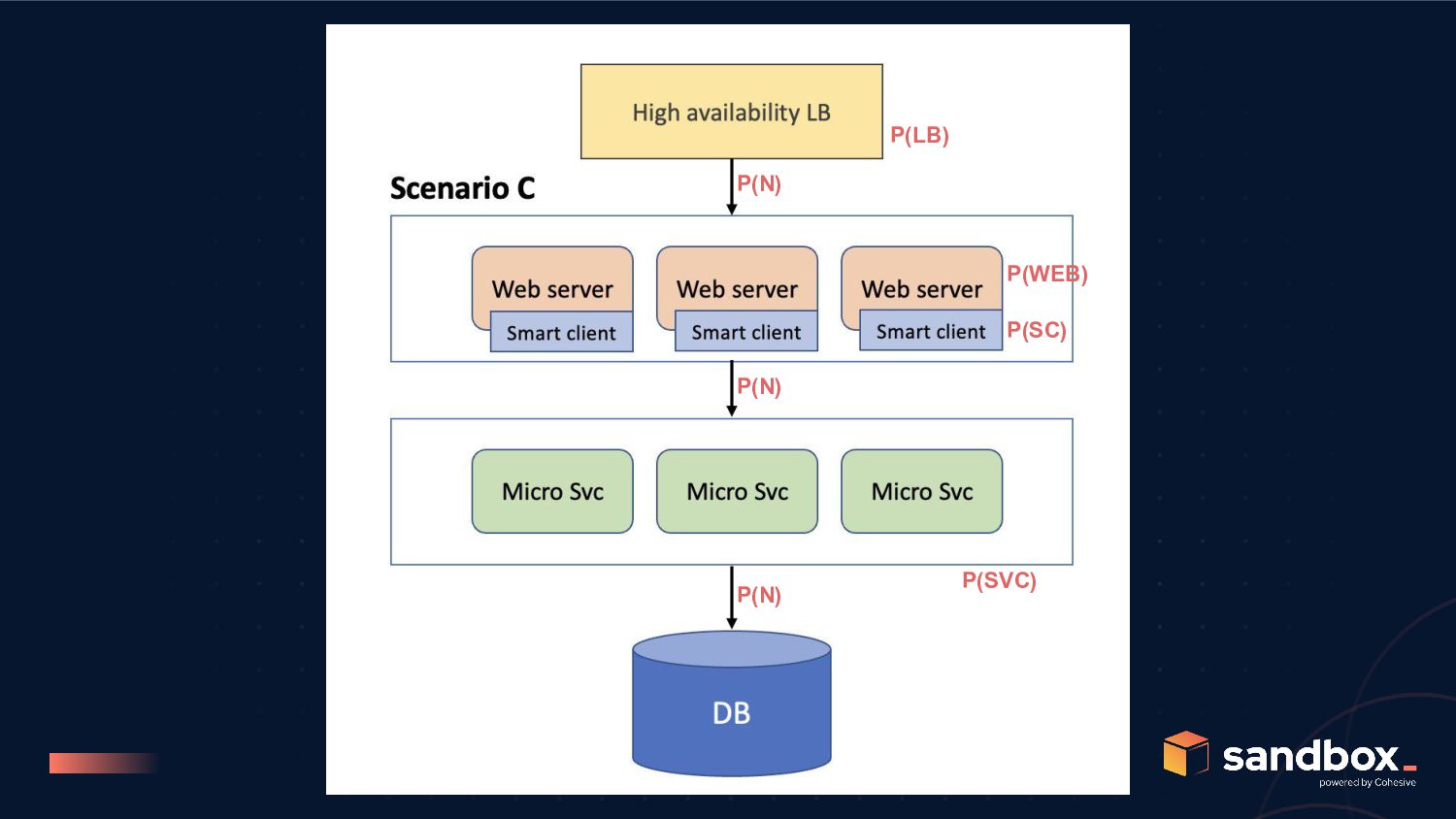
C to be better than scenario A, we need; P(WEB) and P(SVC) greater than 99.85% post refactoring for scenario B to be better than scenario C, we need; P(SC) >>> P(LB), but remember P(SC) is bound by P(N)
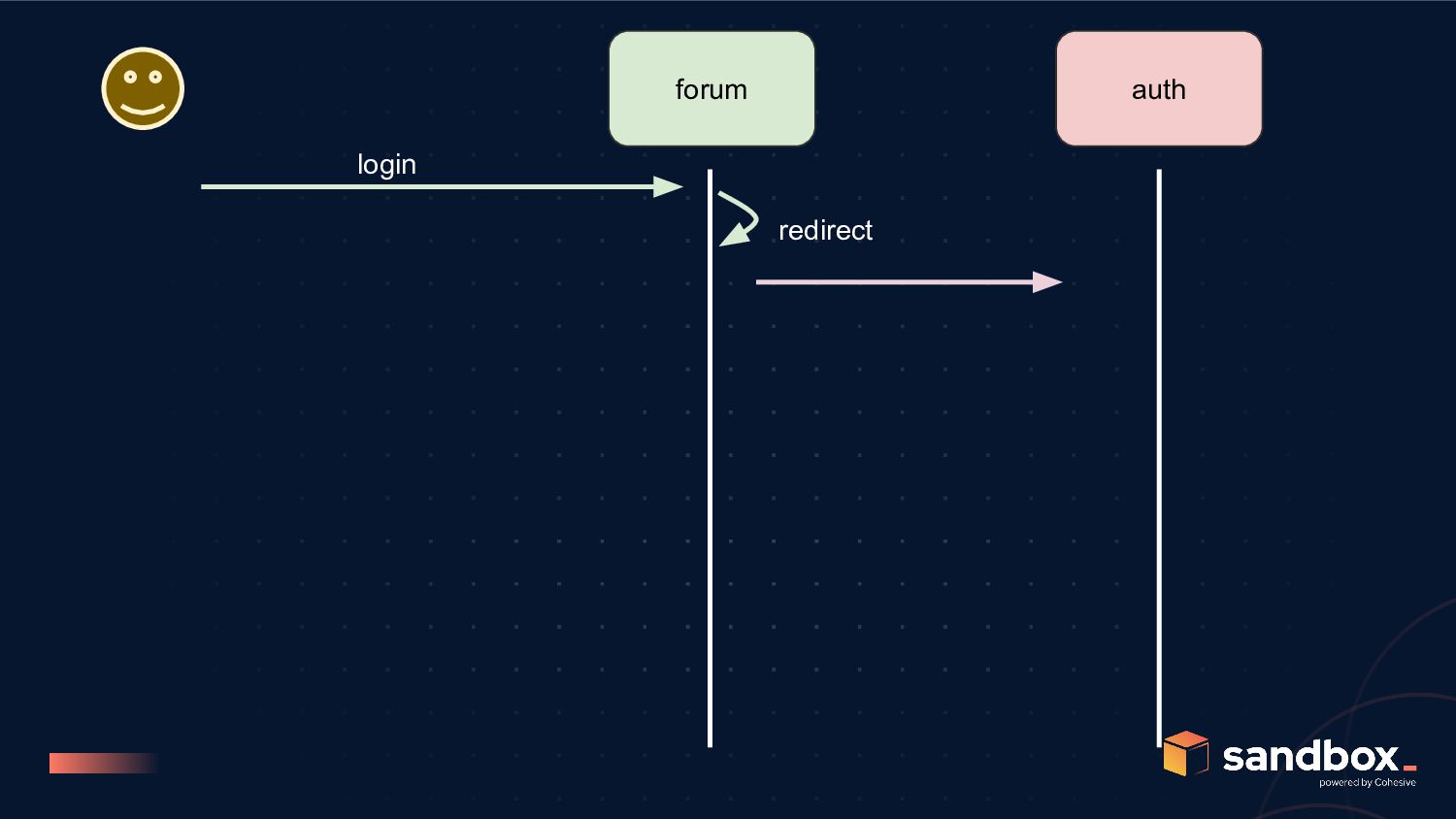
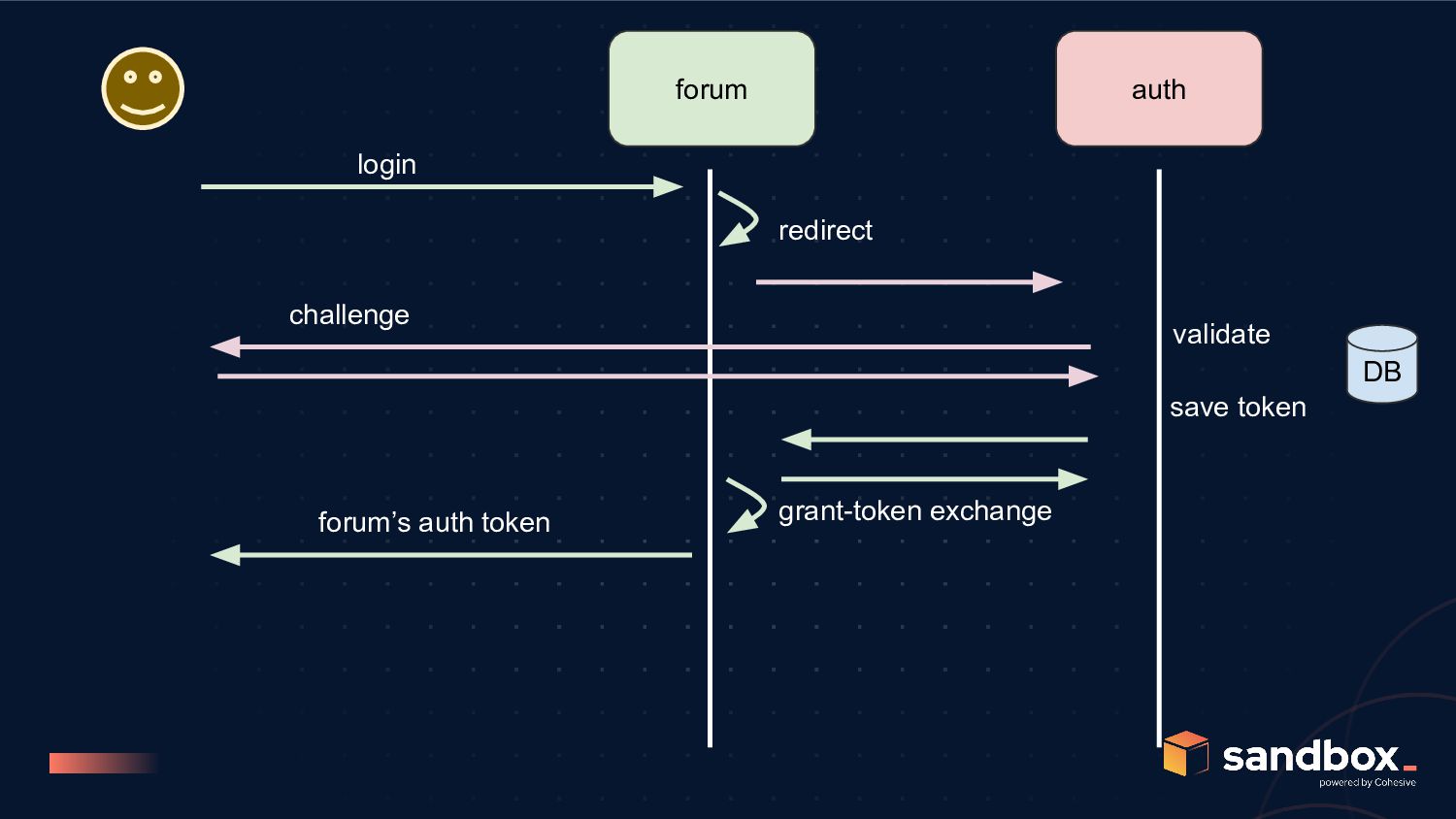
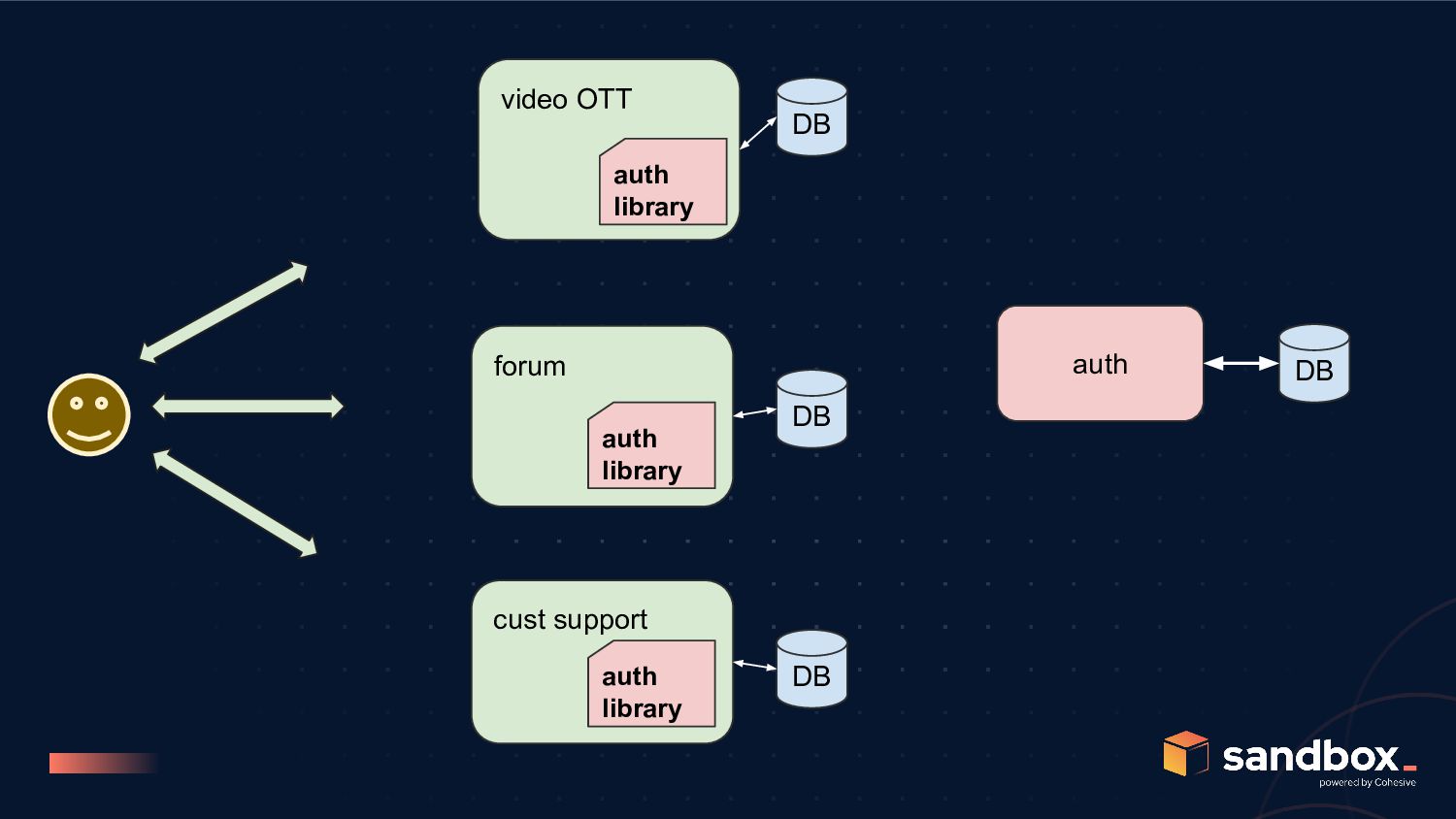
Auth Service • connected to user DB • has private key side of JWT signing • does not need to be exposed outside DMZ/VPC • can be called for extra-security calls, 2FA, where required • basic request authorization flow doesn’t touch this • can have downtime, without affecting majority of API calls Auth Library (Embeddable) • embeddable, stateless library that can be included in other services • contains the public key side of the JWT signing • can call auth service for additional checks • simple JWT verification is handled, without needing auth service • Cons: challenges around server-side invalidation
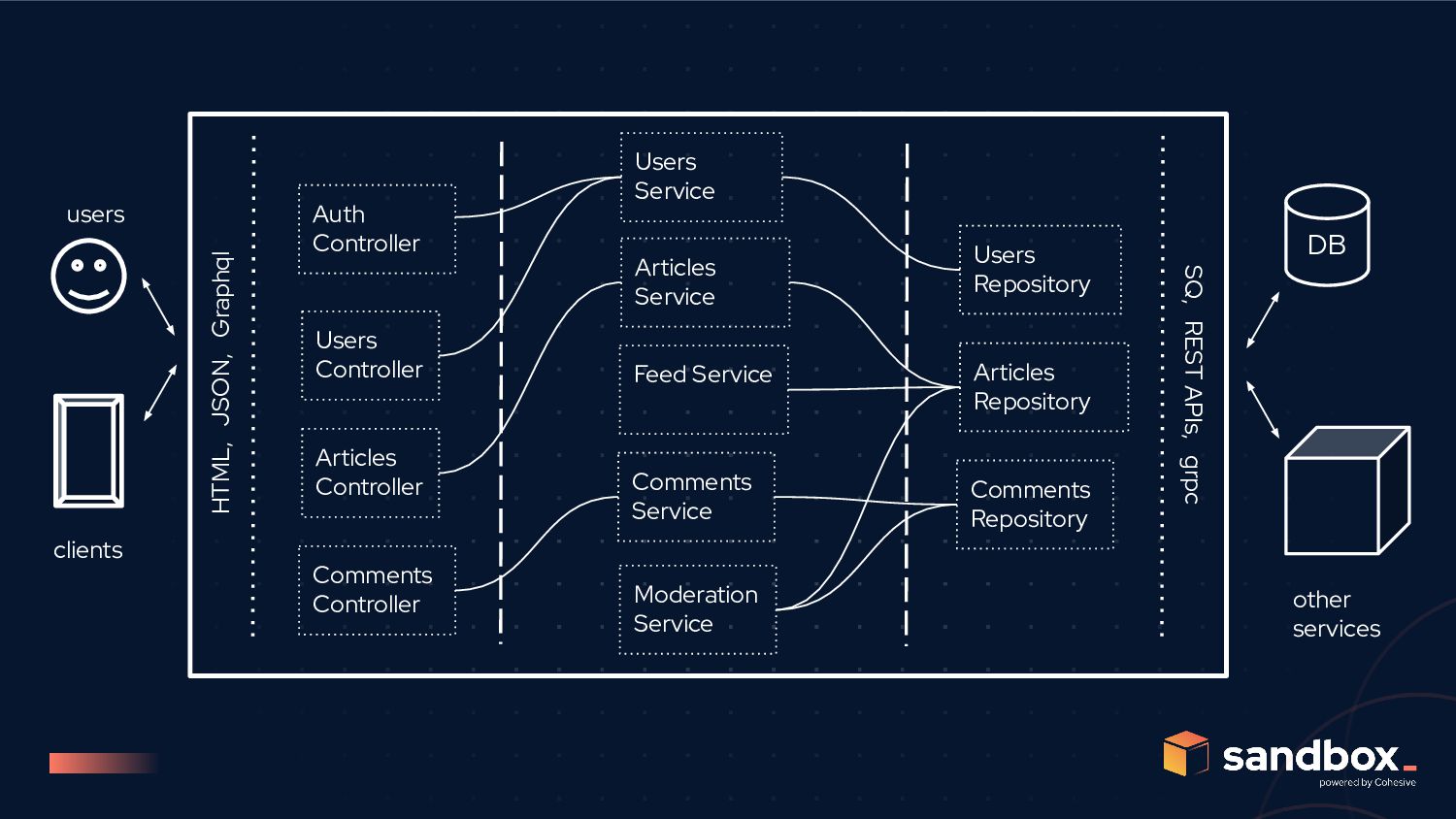
JSON, Graphql Users Controller Articles Controller Comments Controller Auth Controller Users Repository Articles Repository Comments Repository Users Service Articles Service Comments Service Moderation Service Feed Service API Gateway Data Service Auth Service
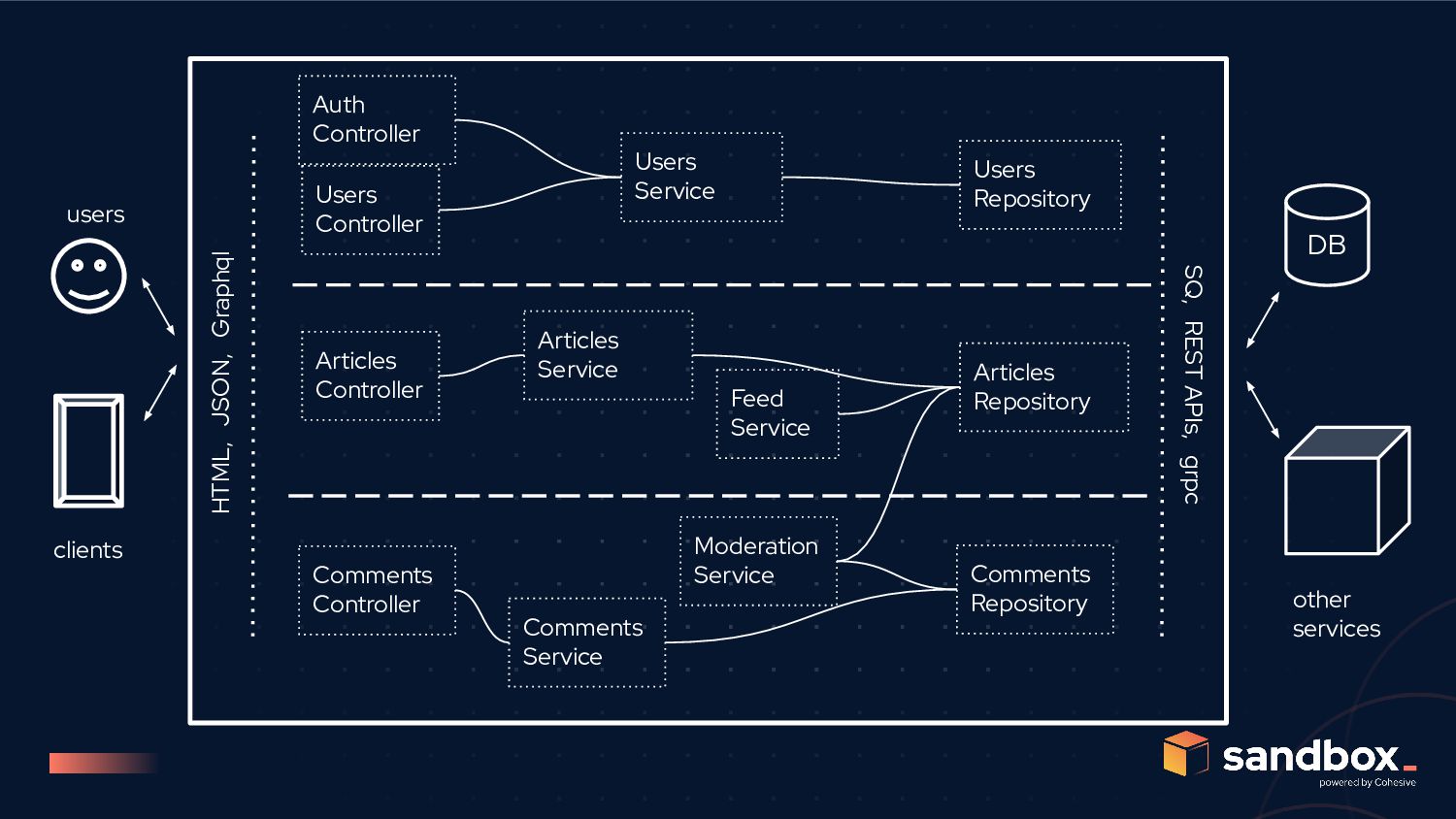
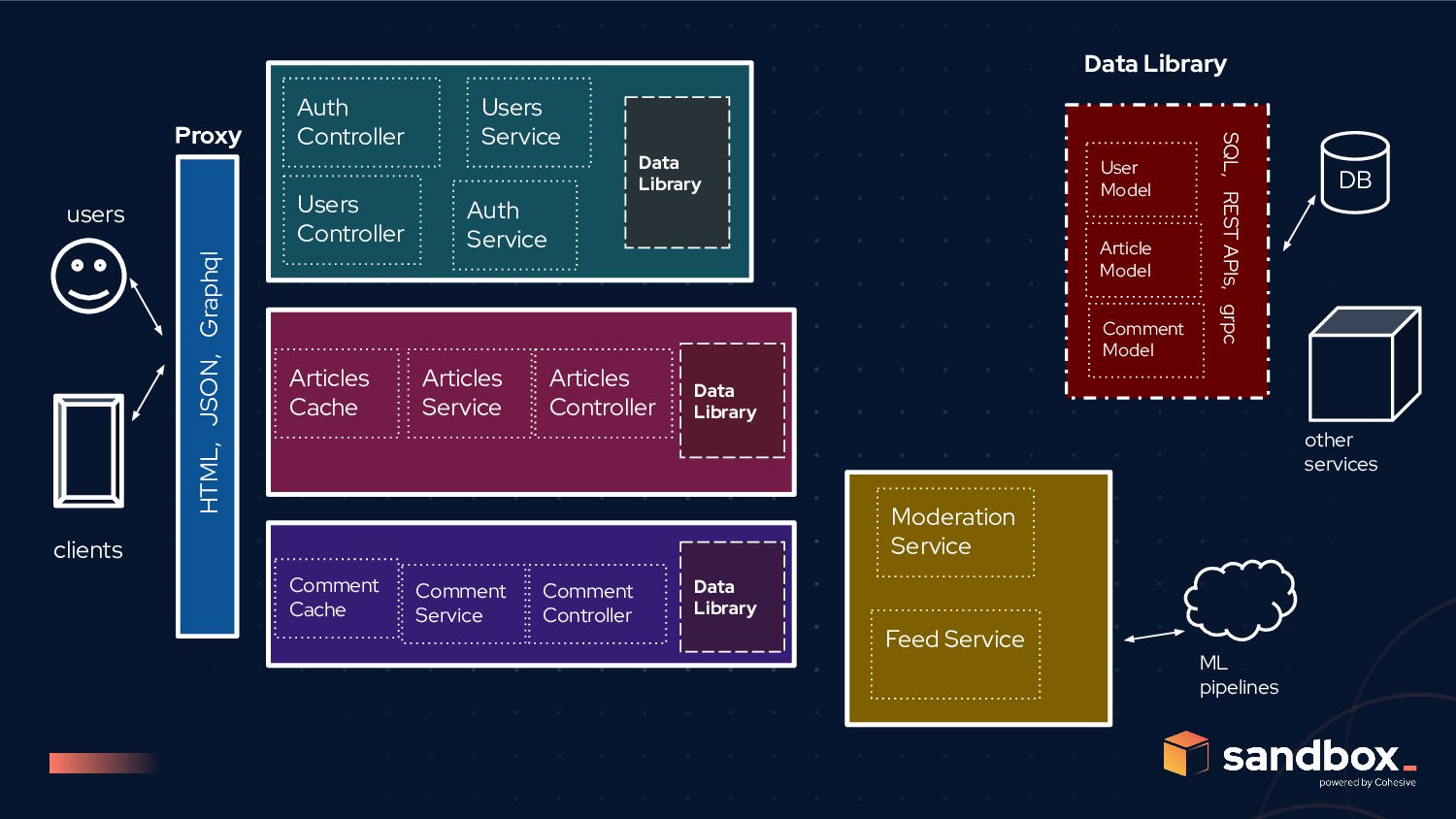
JSON, Graphql Users Controller Articles Controller Auth Controller User Model Article Model Comment Model Users Service Articles Service Moderation Service Feed Service Proxy Data Library Auth Service Data Library Data Library Articles Cache Comment Controller Comment Service Comment Cache Data Library ML pipelines
a new availability factor in the equation • serialization/deserialization overheads pile up faster than expected • documentation • observability • on-call (stems from Conway’s Law driven microservices too) • introducing new single-point of failures
image upload, video transcode • “side effects” - logging, auditing, cold-storage • “post-processing” - MLops on ingested data, moderation workflows • “spiky” workflows - code evaluation during online test • “sacrifice-able” features - during IPL, Hotstar can drop recommendations
N : 1, not 1 : N (ideally N>2) • exotic services - API gateway, service registry, multi-tenant queues, non-trivial caches • senior* engineers : exotic services also to be N : 1, (ideally N > 2) • creating services shouldn’t be “cheap”. RFCs, arch docs, and valid reasoning
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}