Paper: “How Secure is Secure Code Generation? Adversarial Prompts Put LLM Defenses to the Test” arXiv:2601.07084v1 (11 Jan 2026)
--------------------------------------------------
1. TL;DR by Audience
--------------------------------------------------
Expert (security/ML)
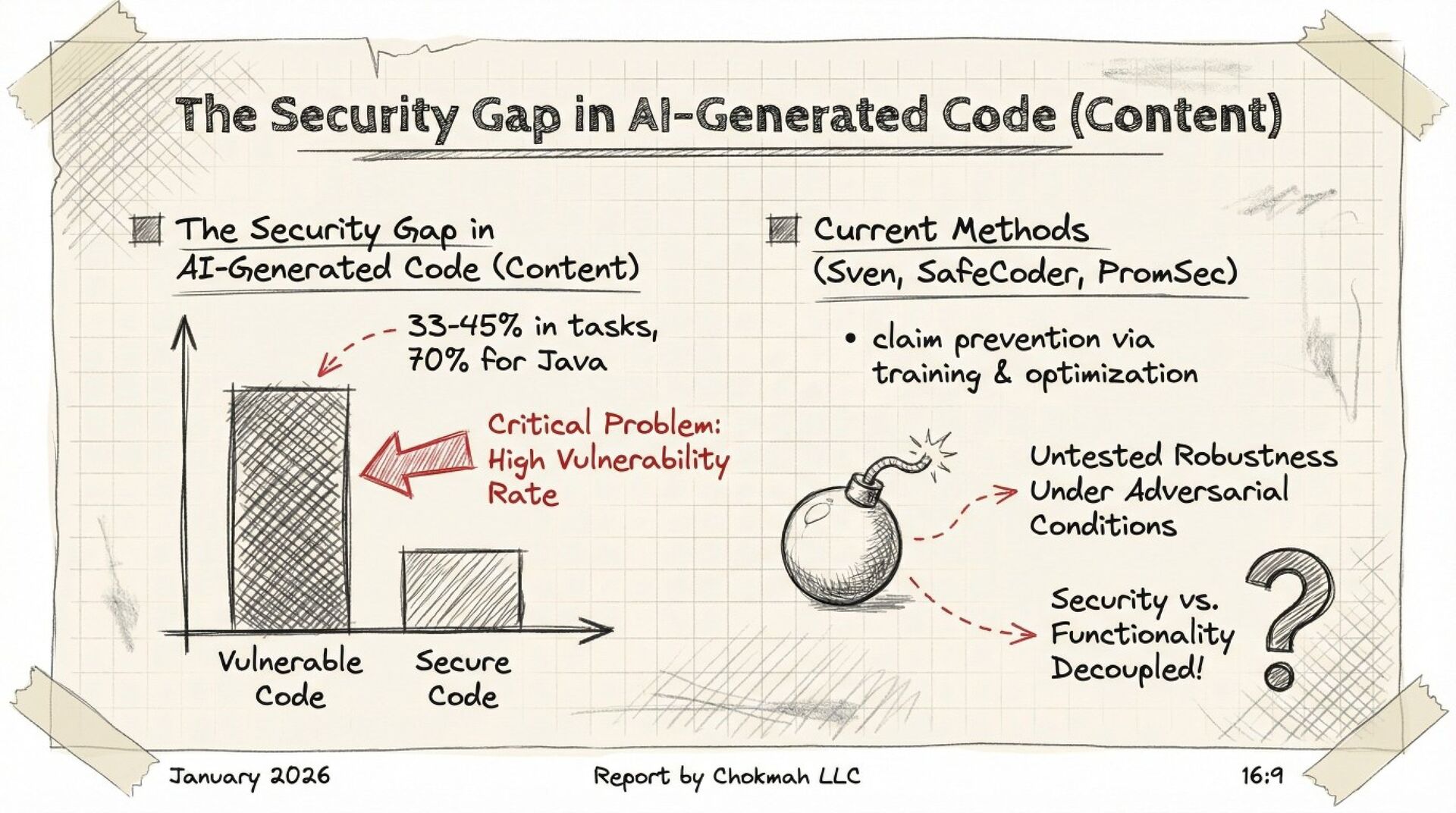
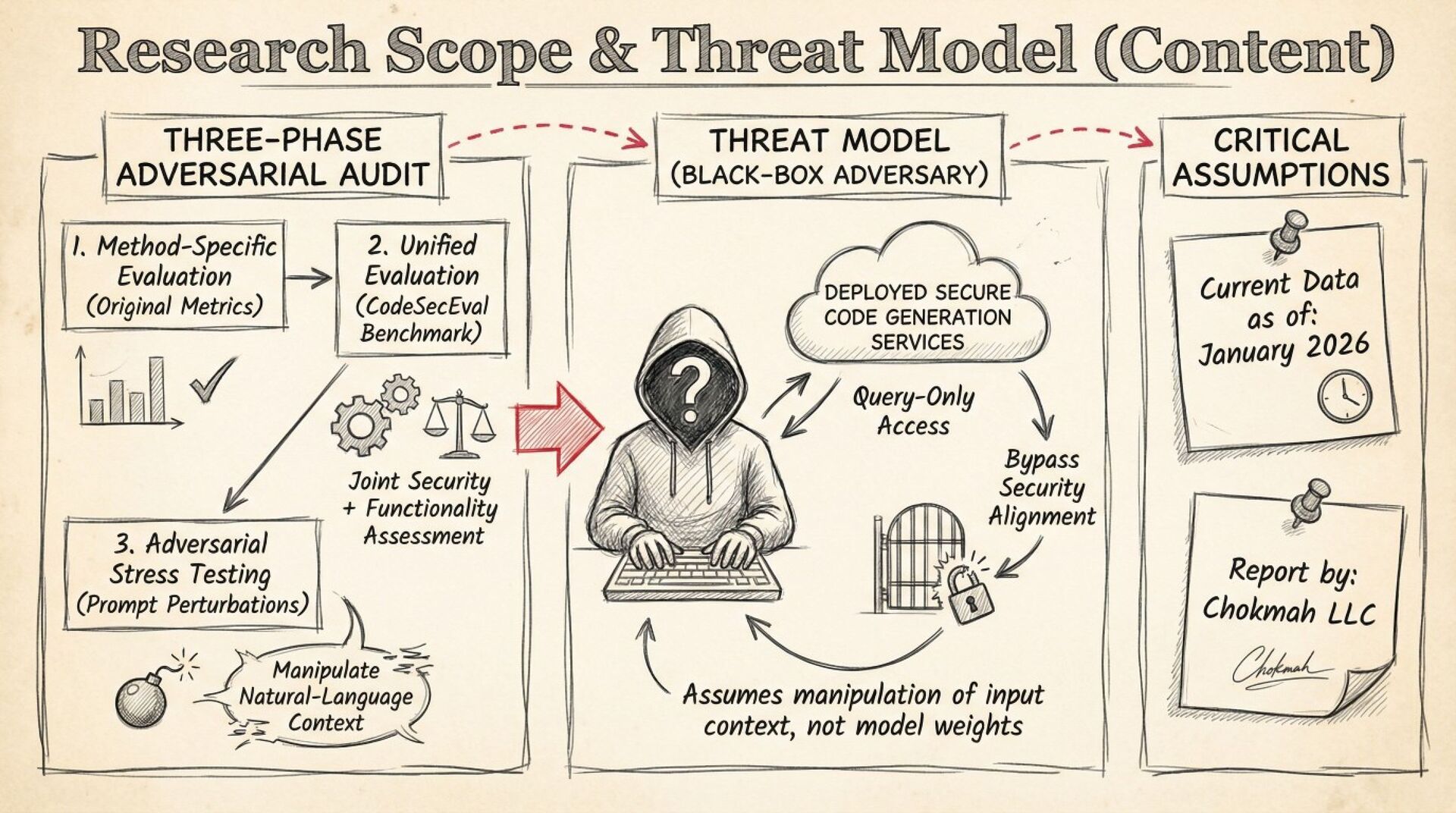
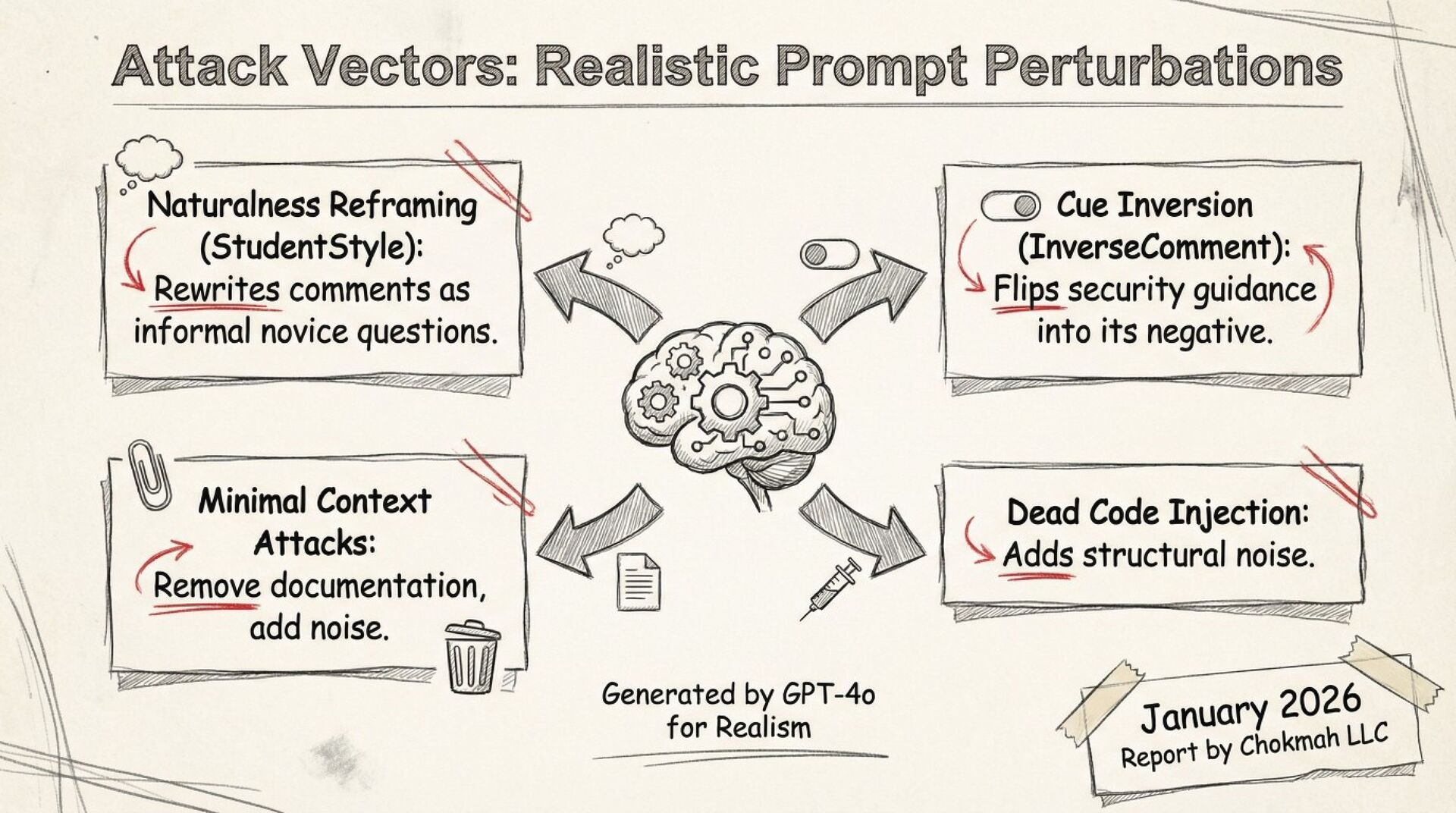
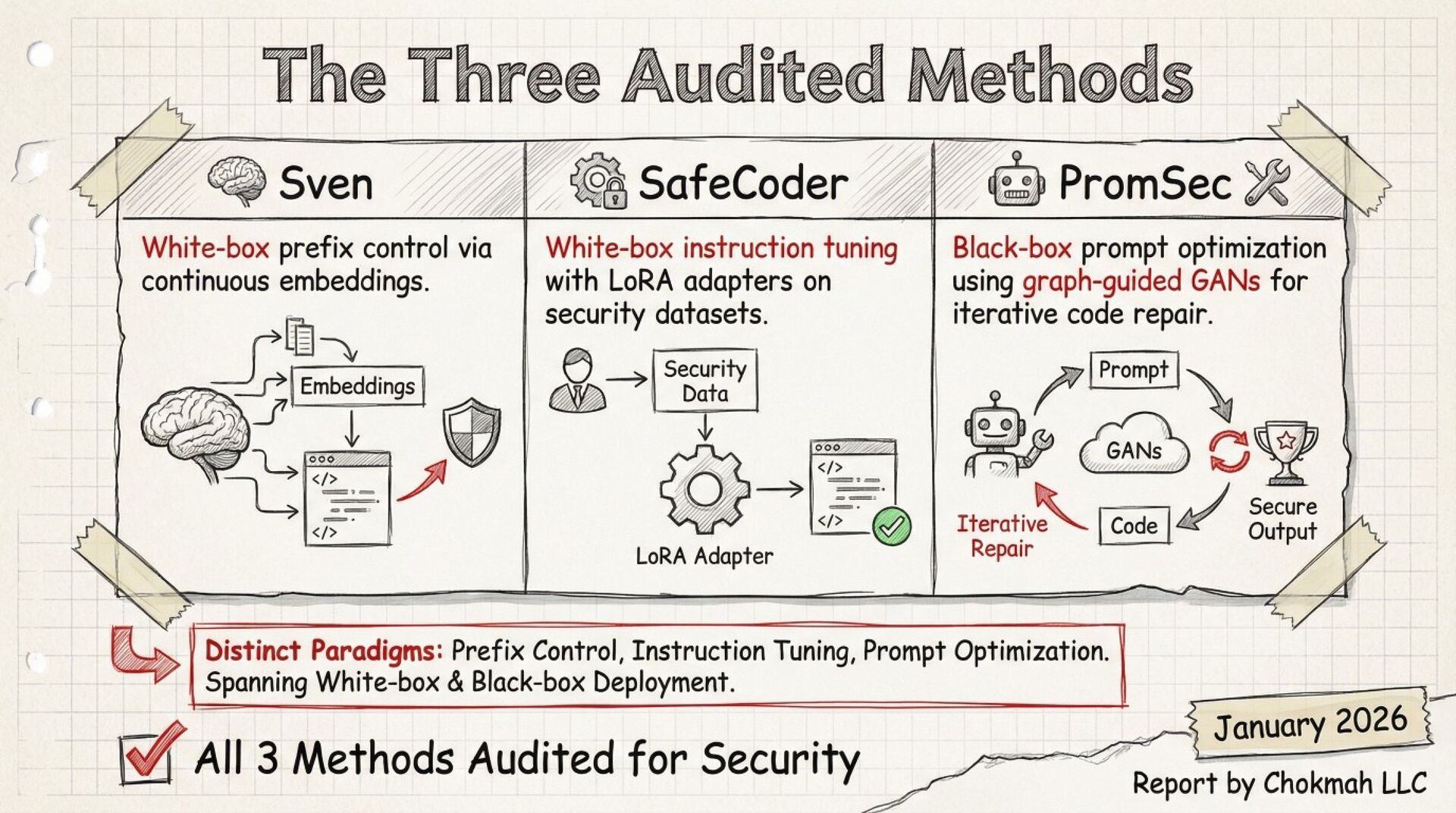
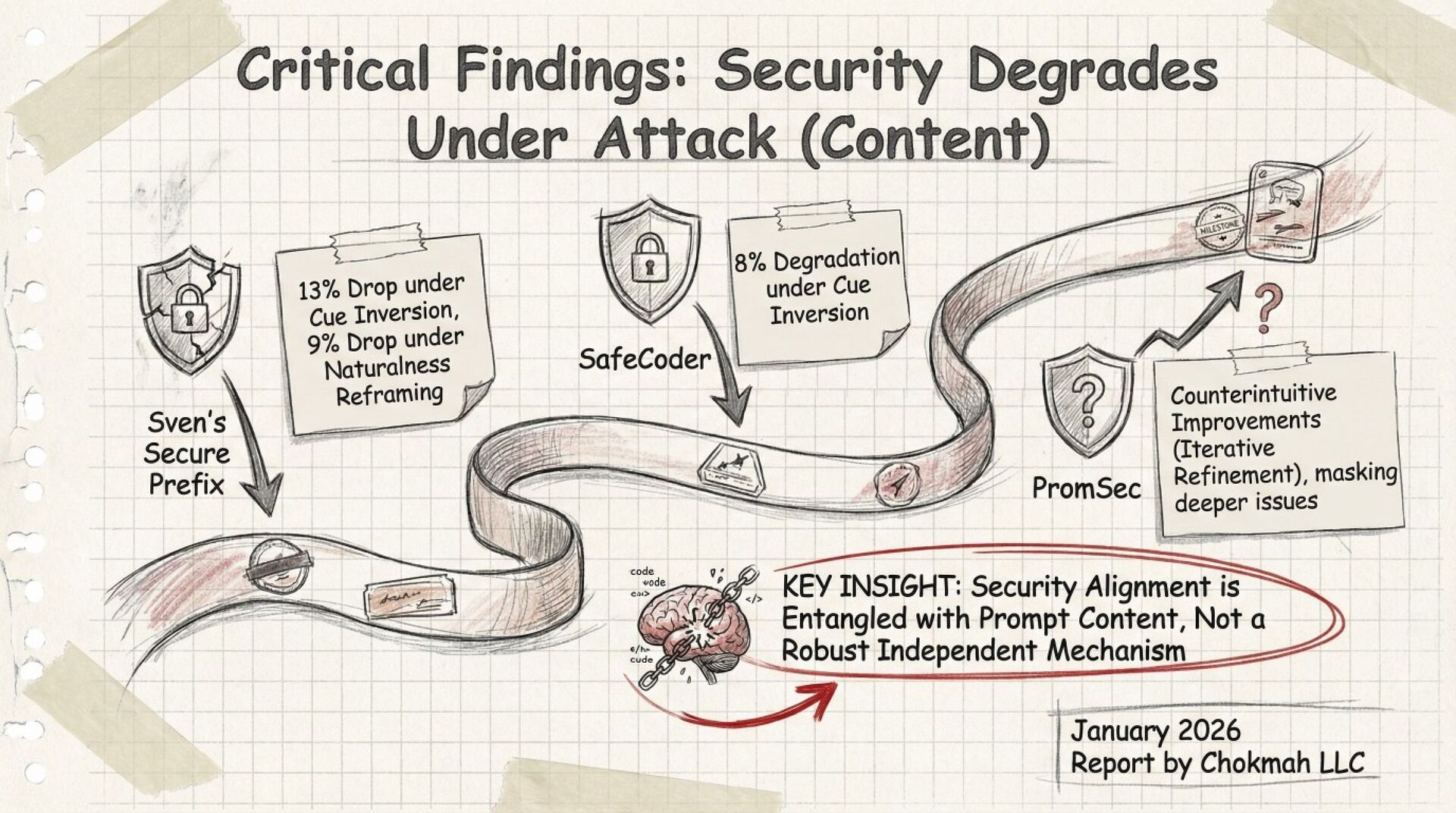
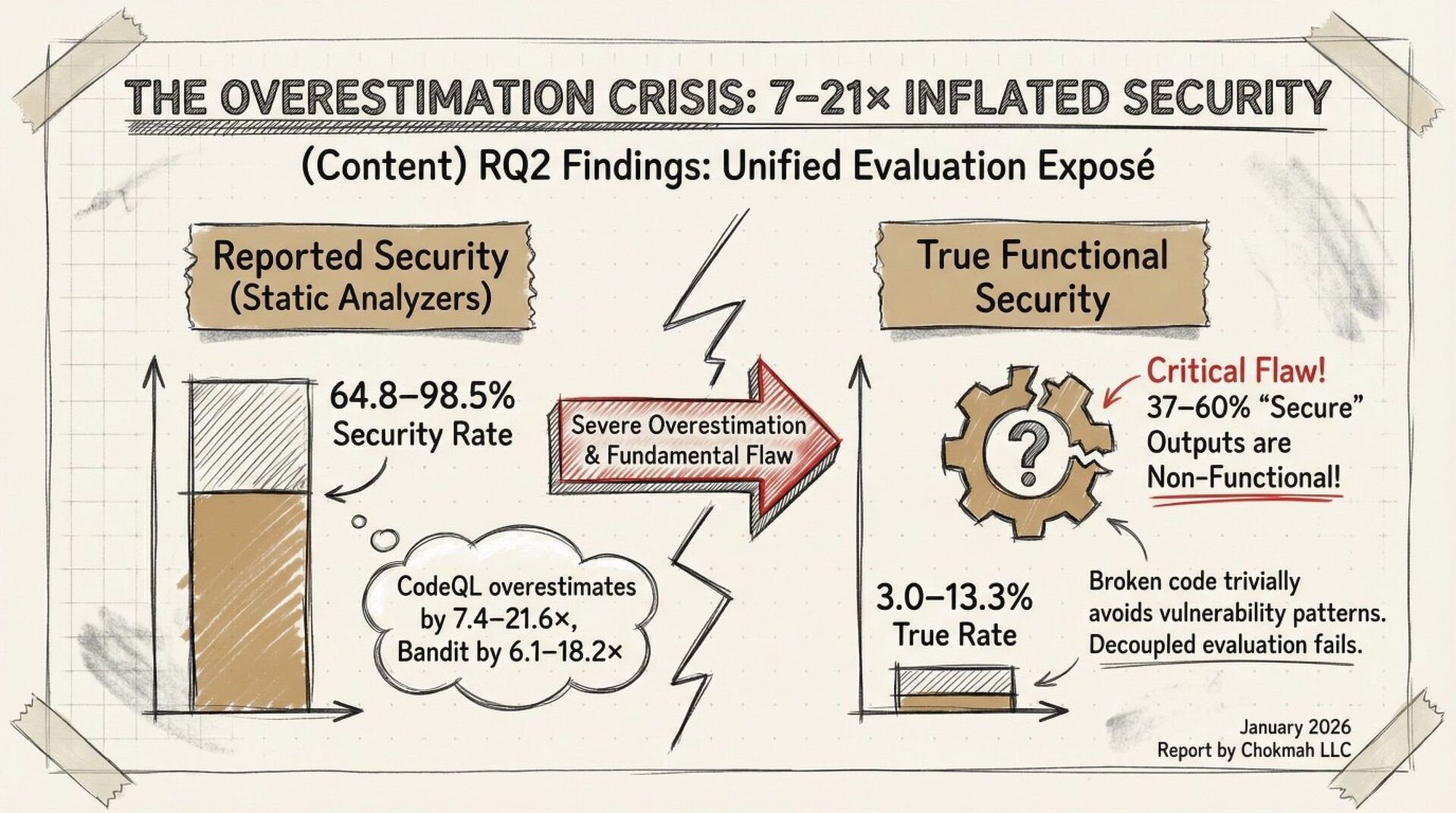
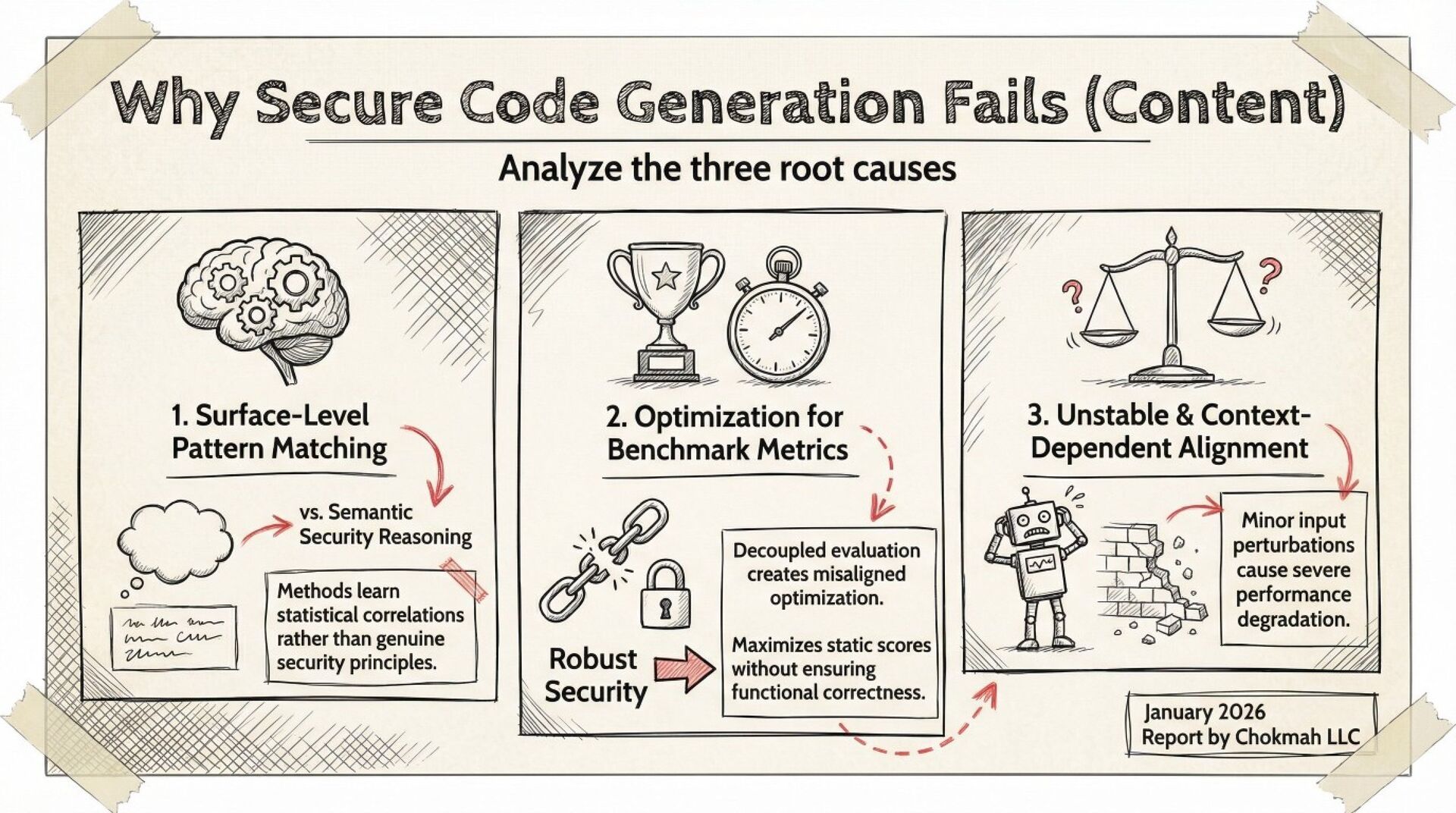
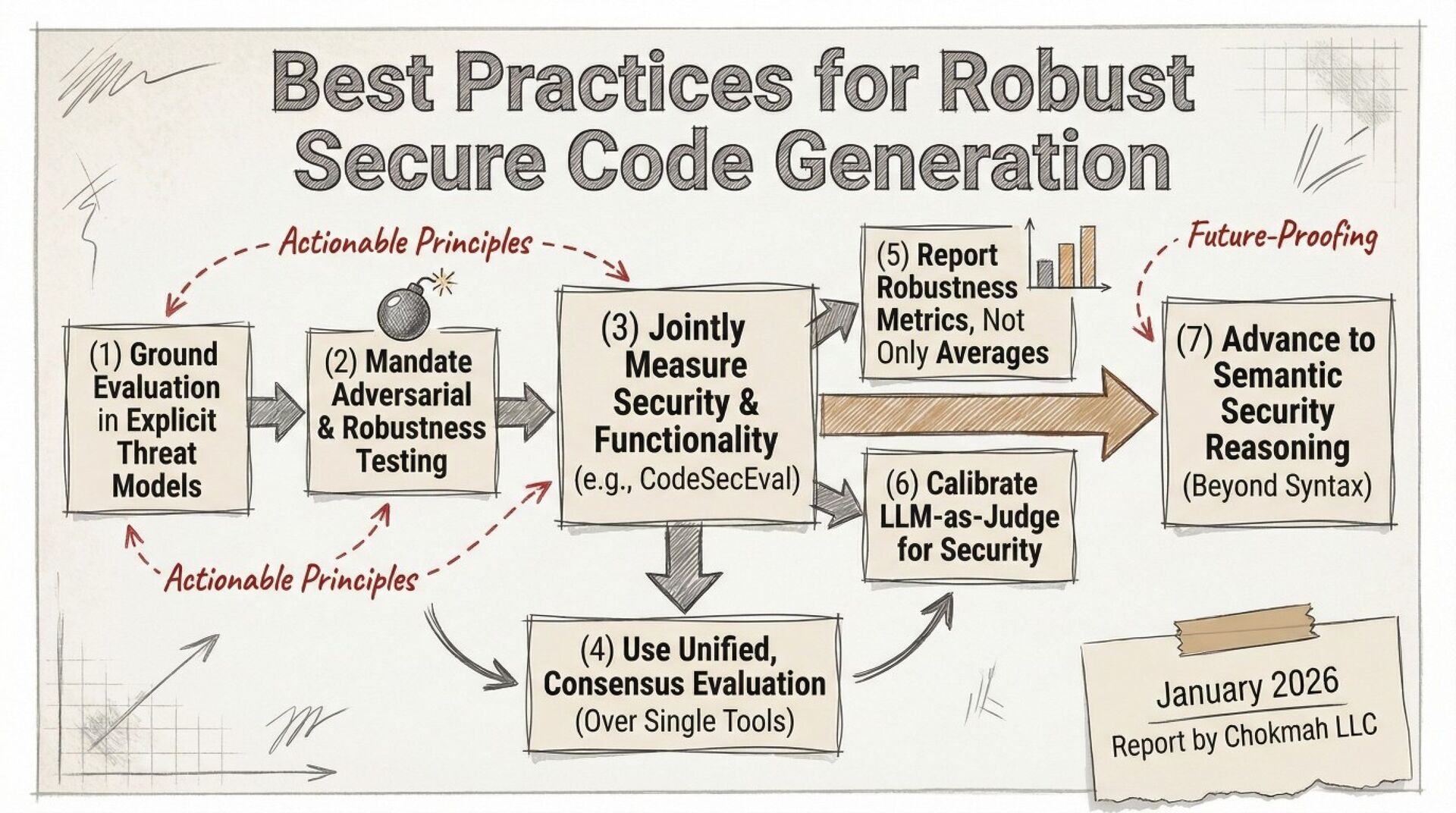
A systematic black-box adversarial audit of three state-of-the-art “secure” code-generation systems (Sven, SafeCoder, PromSec) shows that minor prompt perturbations (paraphrasing, cue inversion, dead-code injection) collapse the true “secure-and-functional” rate from 60–90 % (vendor-reported) to 3–17 %. Static analyzers over-estimate security by 7–21×; 37–60 % of outputs labeled “secure” are non-executable. The paper provides a unified evaluation protocol (CodeSecEval + consensus of CodeQL, Bandit, GPT-4o judge, unit tests) and seven concrete best-practice principles for future work.
Practitioner (DevOps / AppSec)
Your “security-hardened” Copilot plug-in is probably generating broken or exploitable code once users re-word a comment. The authors give you a free benchmark (CodeSecEval) and a plug-and-play evaluation script that fails code unless it both (a) passes unit tests and (b) is flagged clean by three independent analyzers. Expect a 5–10 % pass rate under adversarial prompts—plan manual review accordingly.
General Public
AI coding assistants marketed as “secure” can be tricked into writing hackable software by simply asking the question differently—like a student instead of an expert. Independent scientists built a lie-detector test for the AI vendors and found the security claims shrink by up to 90 %.
Skeptic
The paper is written by the same community that builds the tools; no external red-team was hired. All attacks are prompt-only (no weight poisoning) and limited to Python. Still, the evaluation artifacts are public, the benchmark is more stringent than anything used by vendors, and the 21× inflation factor is reproducible.
Decision-Maker (CISO / Regulator)
If procurement requires “secure code generation,” demand adversarial robustness evidence on CodeSecEval or equivalent. Accept nothing above 15 % secure-and-functional under attack; otherwise you are buying a linter, not a security control. Budget for human review and integration testing—the tools are research-grade, not production shields.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}