Christine will tell the spooky story of how her team debugged a mysterious outage involving Amazon RDS with Honeycomb, and how that epic failure became a zombie that followed the team around forever.
that happened to us at honeycomb. officially, we’re "real-time system debugging." but that’s marketing-speak. unofficially, honeycomb is a tool for exploring all of the exhaust (data) from your various pieces of software running - and it lets you do so speedily and powerfully, in realtime (if you want!). - (in reality, we ingest one of these in particular - but unless you're driving around in a tesla, the analogy generally works.)
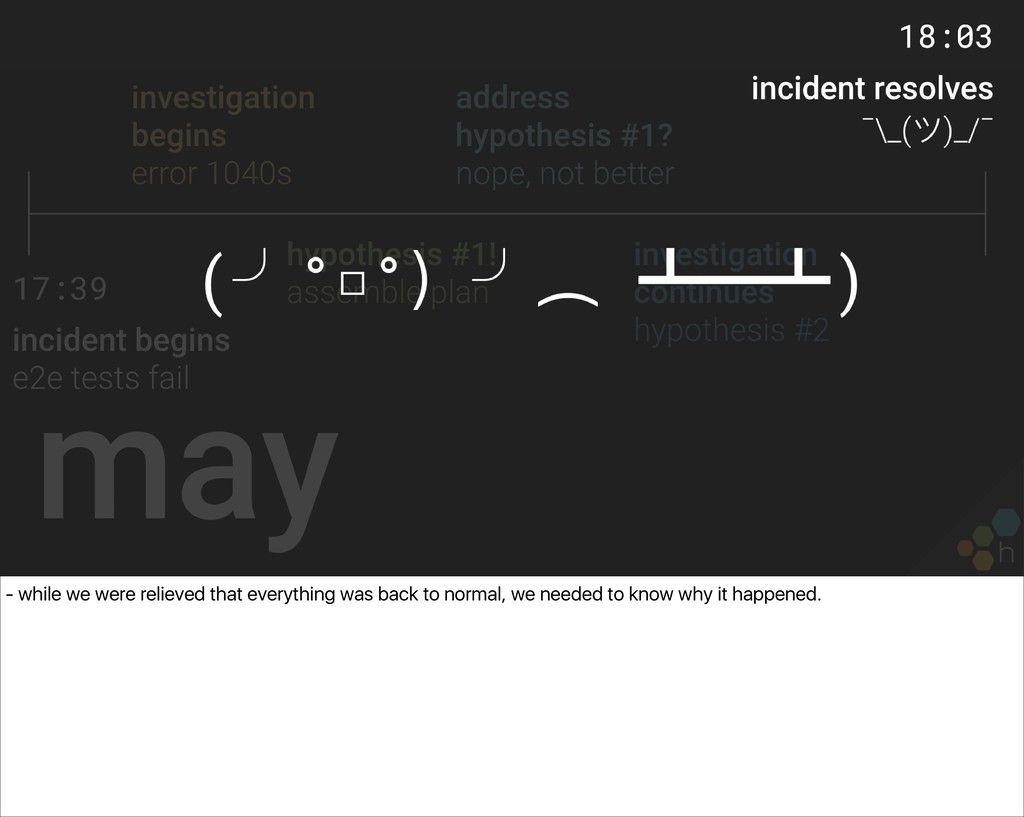
an incident had just started because our end-to-end checks, which run every minute making sure that writes that are made into honeycomb are readable - started failing. - for the ~24 minutes of the incident, we identified that our MySQL RDS instance had suddenly started throwing "too many connections!" error 1040s, which was in turn causing our API and web app to refuse the majority of received requests. - i’ll get into details later, but it was one of those incidents for which we were able to identify the issue, come up with one hypothesis to address the issue, roll it out, realize it didn't help, come up with another hypothesis... before the system seemed to right itself.
over 12 hours: - we reviewed what we knew from the night before: that it was centered around RDS error 1040s - and we figured either there was something in the code that was resulting in an elevated connection count, causing a slowdown in the database
code-side issue in our dogfood cluster, to prove that rule of thumb right or wrong - dug deep into the data exhaust produced by our dogfood experiment, and compared it to the production outage. the honeycomb approach captures a ton of metadata and lets you slice and dice it in new exciting ways, without pre-aggregation -- so we could continue validating new hypotheses even after the incident had resolved itself.
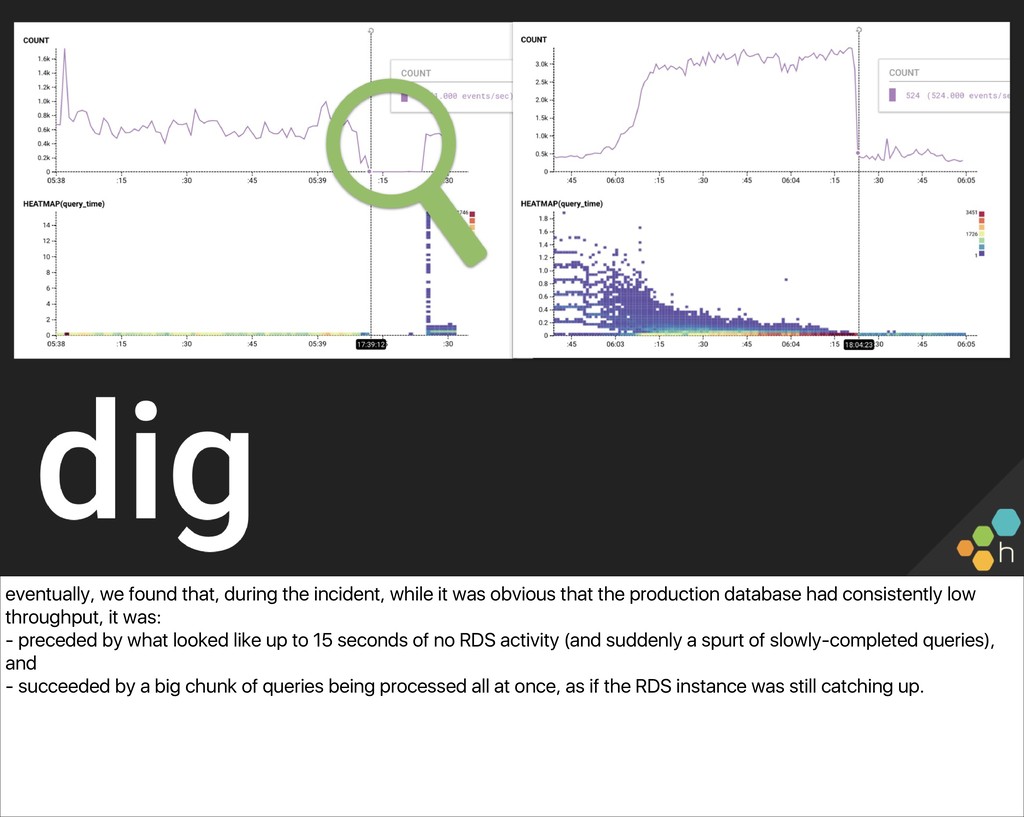
obvious that the production database had consistently low throughput, it was: - preceded by what looked like up to 15 seconds of no RDS activity (and suddenly a spurt of slowly-completed queries), and - succeeded by a big chunk of queries being processed all at once, as if the RDS instance was still catching up.
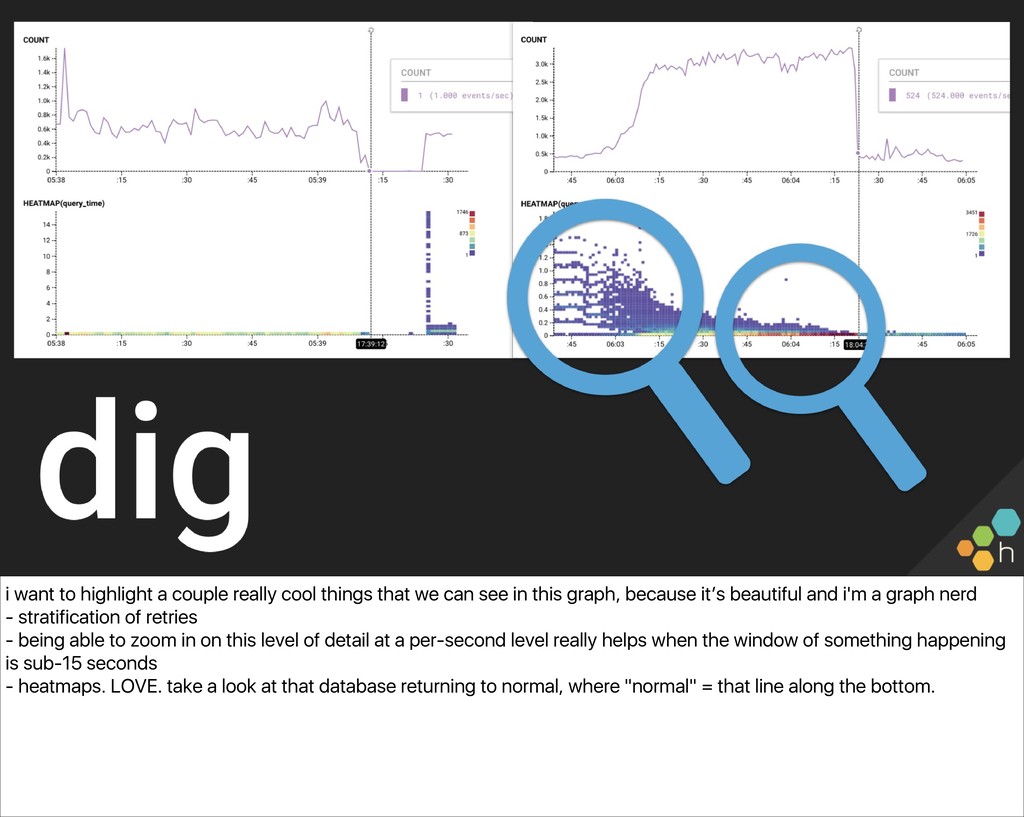
we can see in this graph, because it’s beautiful and i'm a graph nerd - stratification of retries - being able to zoom in on this level of detail at a per-second level really helps when the window of something happening is sub-15 seconds - heatmaps. LOVE. take a look at that database returning to normal, where "normal" = that line along the bottom.
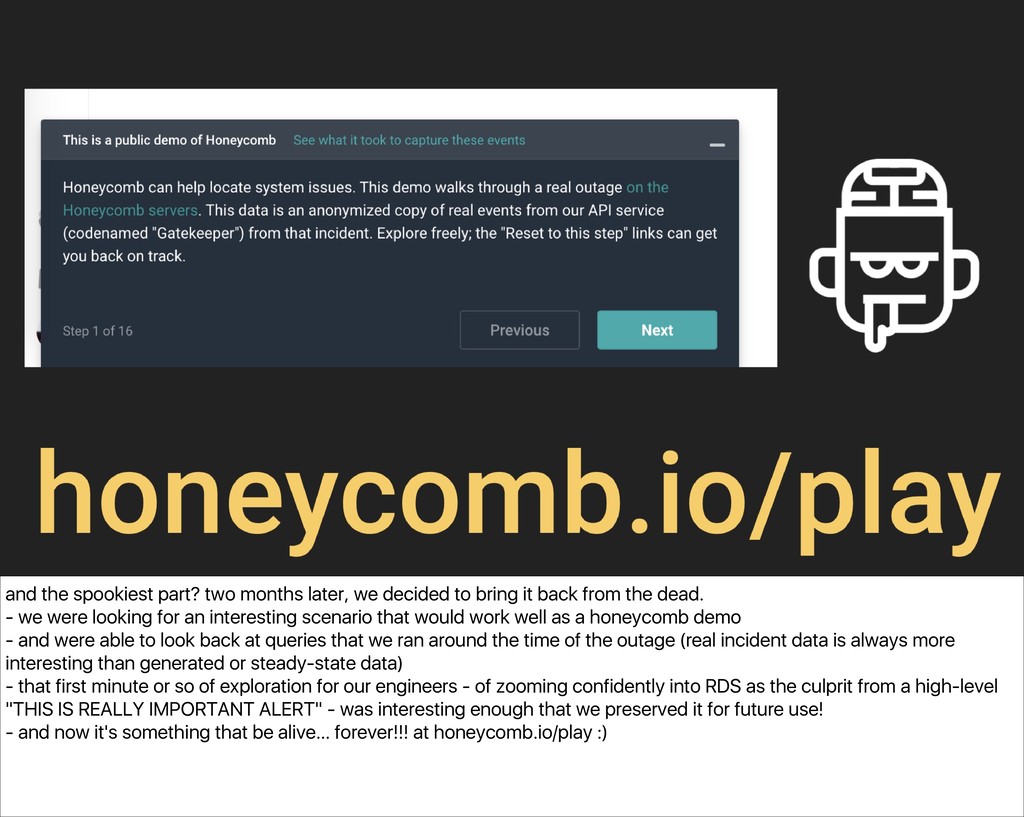
bring it back from the dead. - we were looking for an interesting scenario that would work well as a honeycomb demo - and were able to look back at queries that we ran around the time of the outage (real incident data is always more interesting than generated or steady-state data) - that first minute or so of exploration for our engineers - of zooming confidently into RDS as the culprit from a high-level "THIS IS REALLY IMPORTANT ALERT" - was interesting enough that we preserved it for future use! - and now it's something that be alive… forever!!! at honeycomb.io/play :)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}