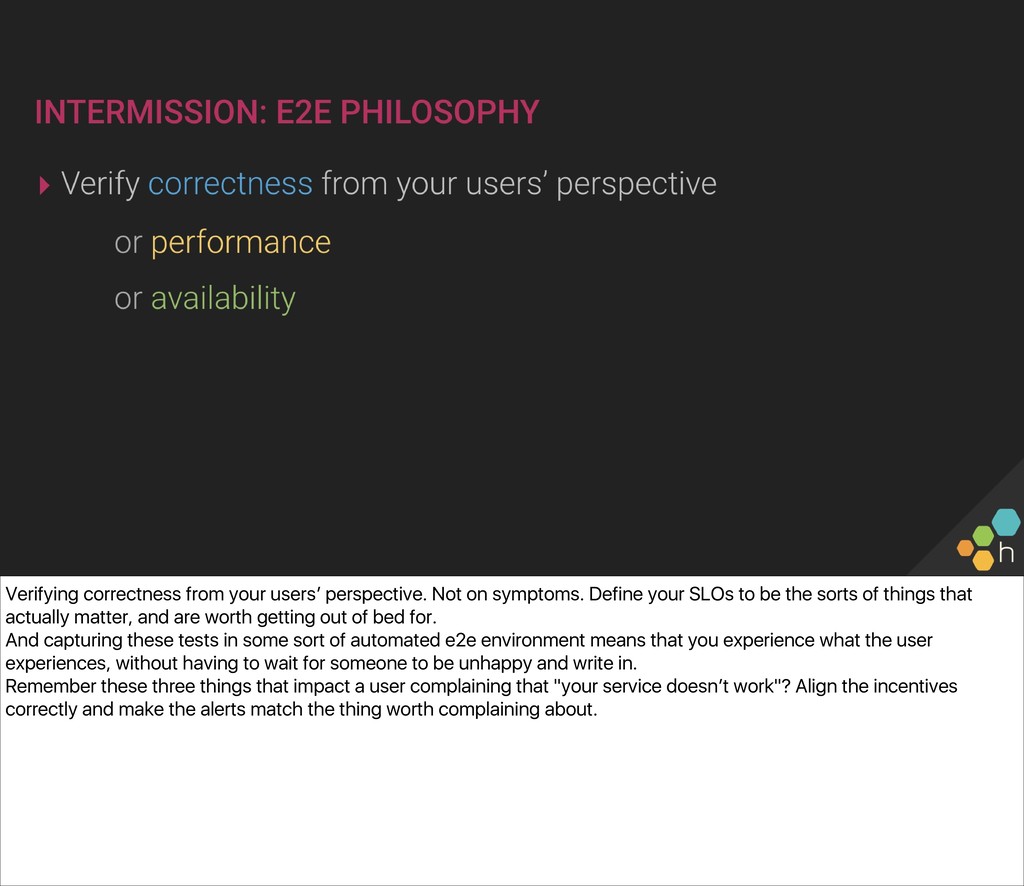
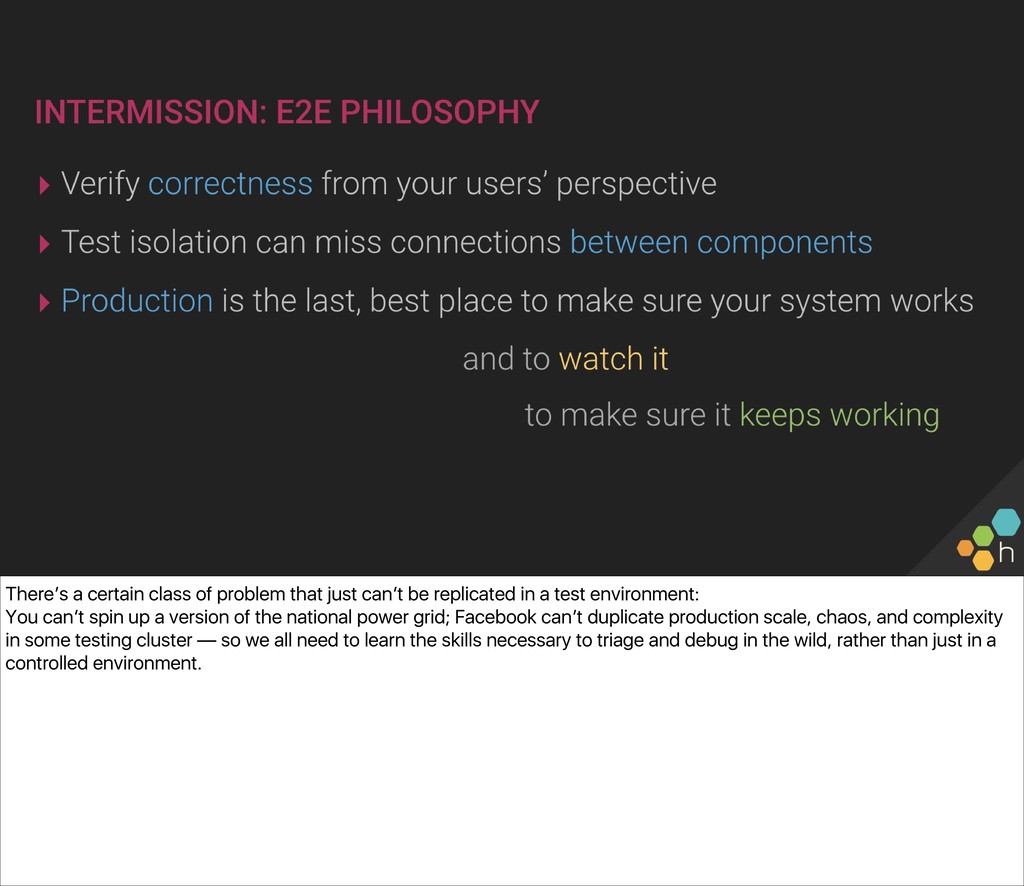
What does “uptime” really mean for your system? An end-to-end (e2e) check is where the rubber hits the road for your user experience and is the operator’s best tool for measuring uptime as experienced by your users. Creating and evolving e2e checks also establishes a basis for defining the SLOs and SLIs that we are willing to support.
Ben Hartshorne and Christine Yen explore what it means for a system to be “up” by explaining what makes a good end-to-end (e2e) check and what techniques are valuable when thinking about them. Along the way, you’ll learn how to write and evolve an e2e check against a common API.
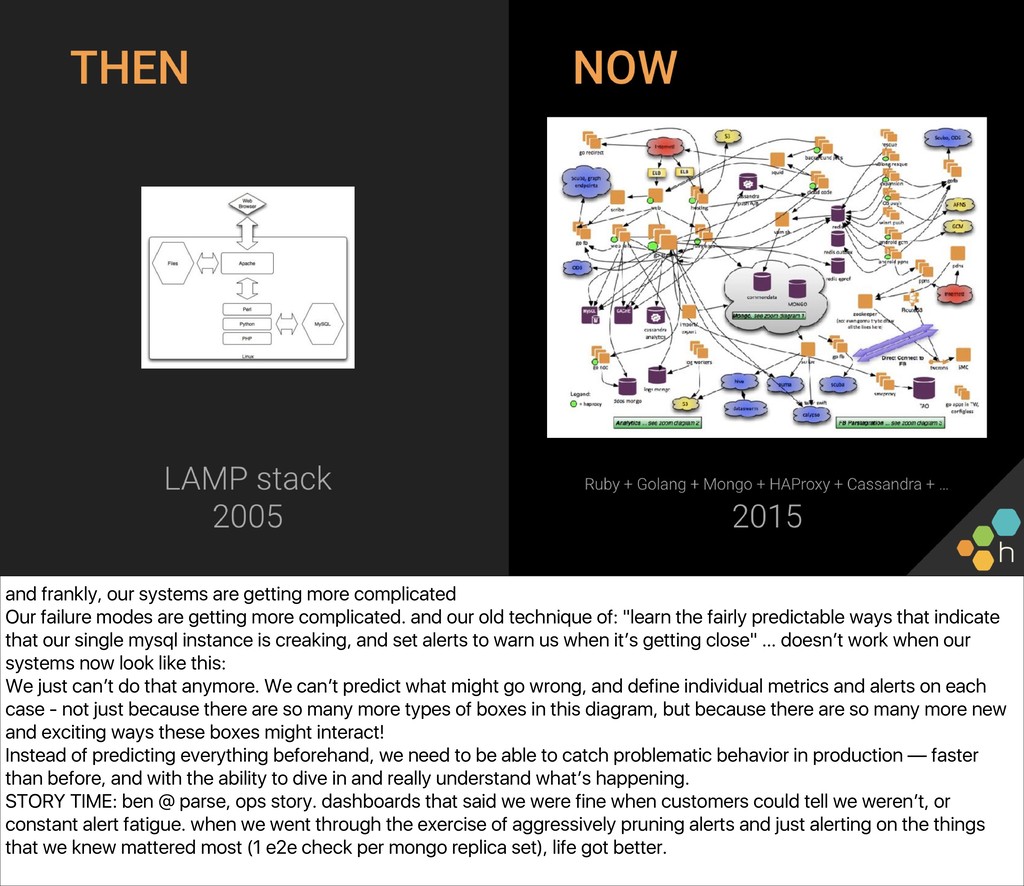
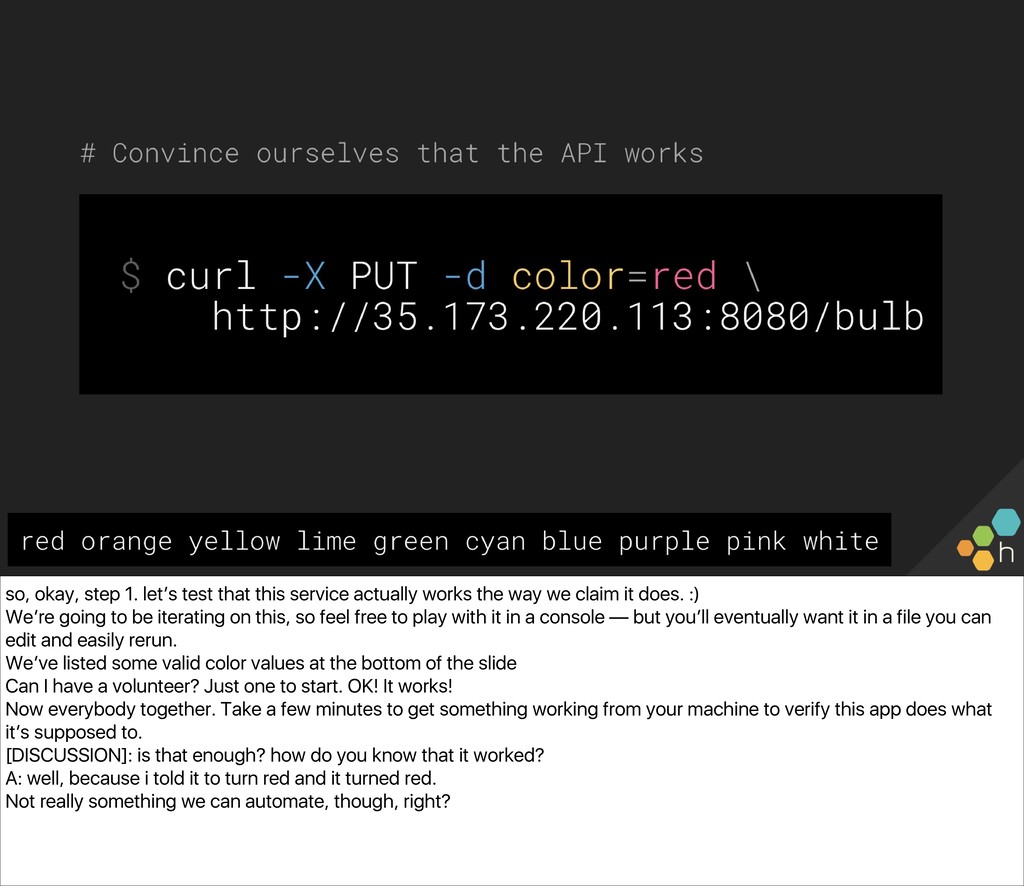
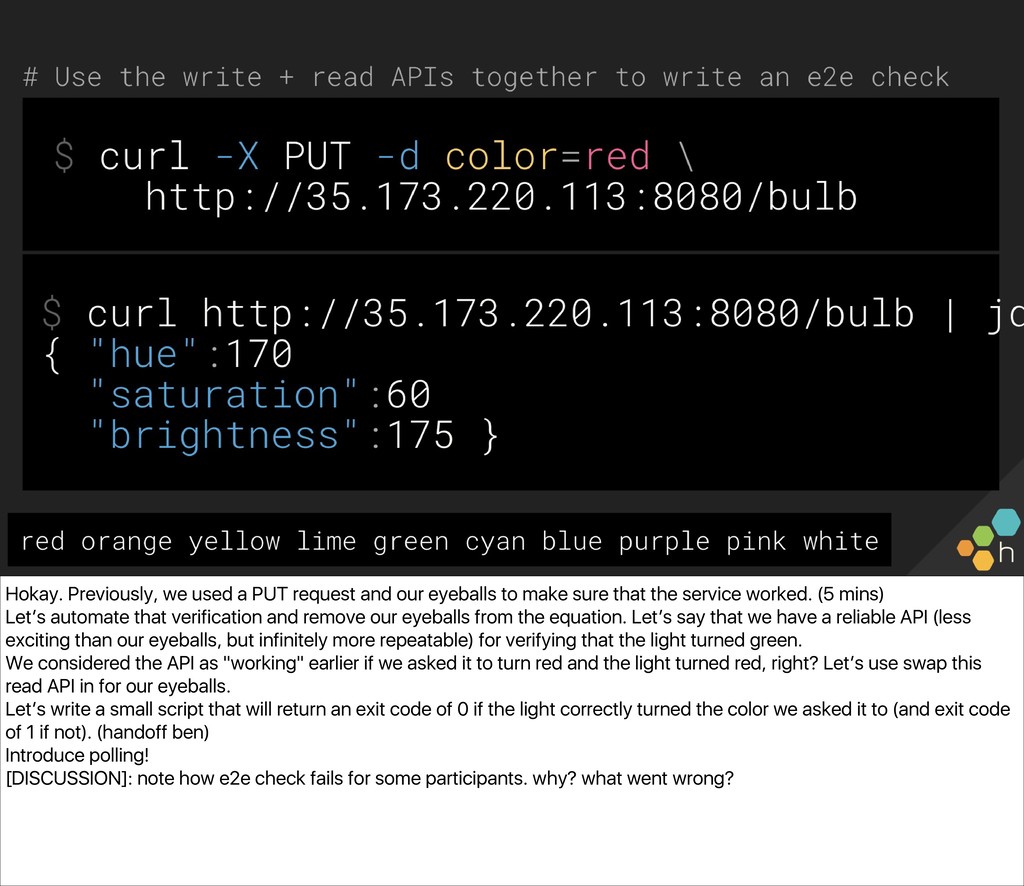
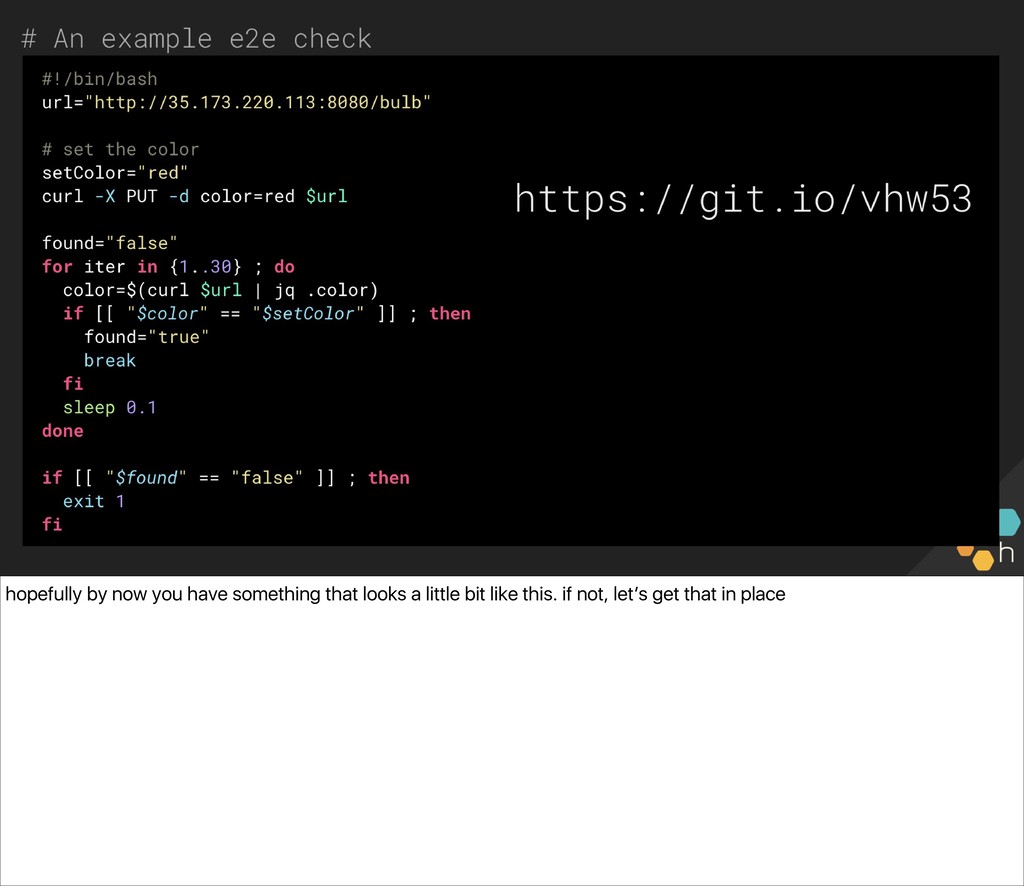
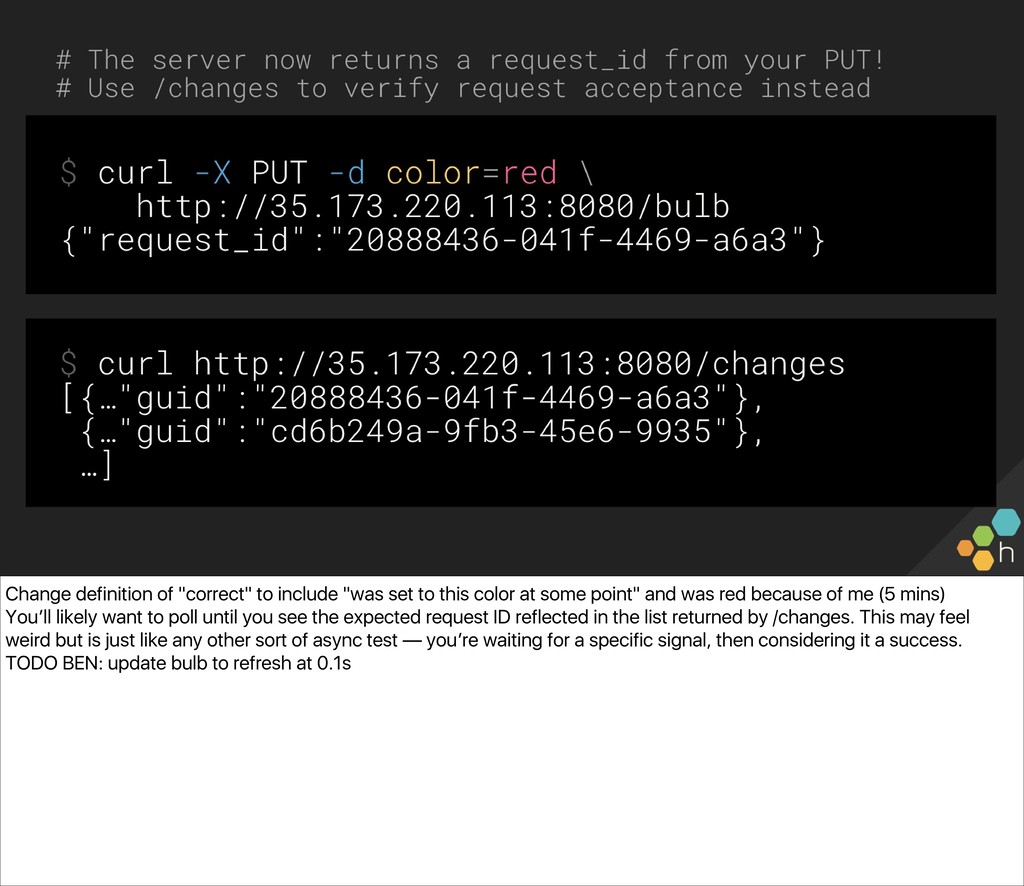
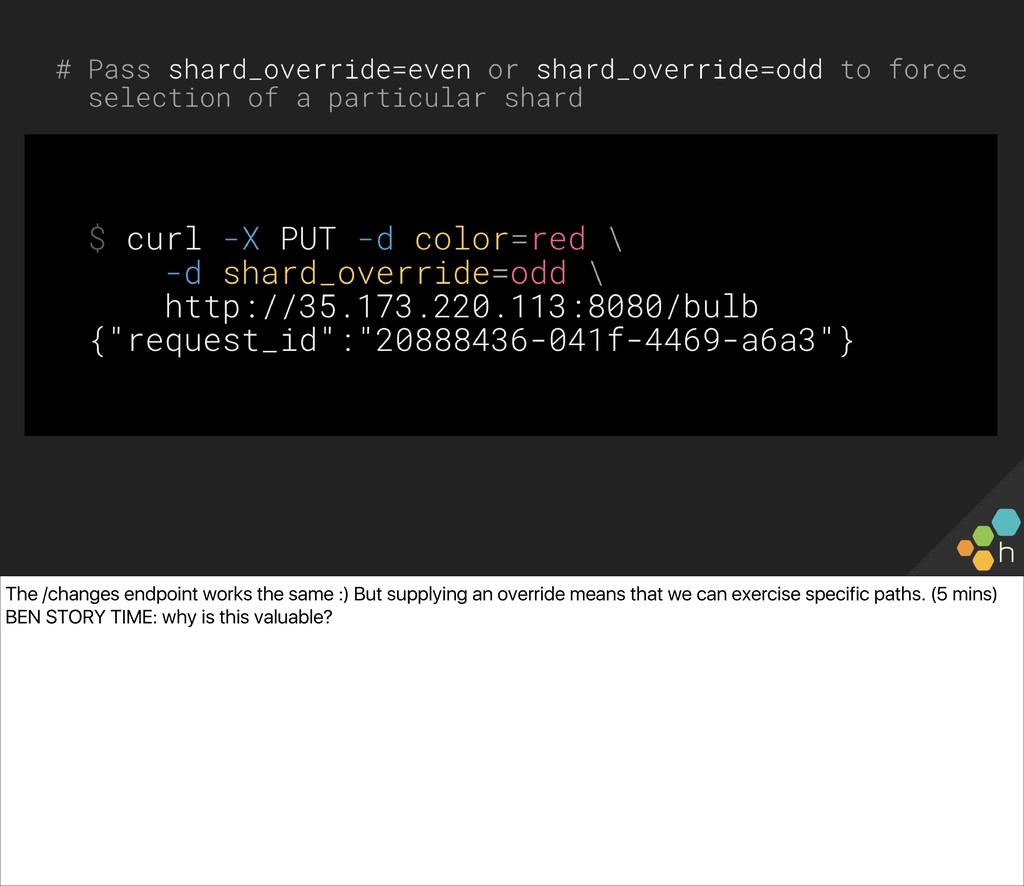
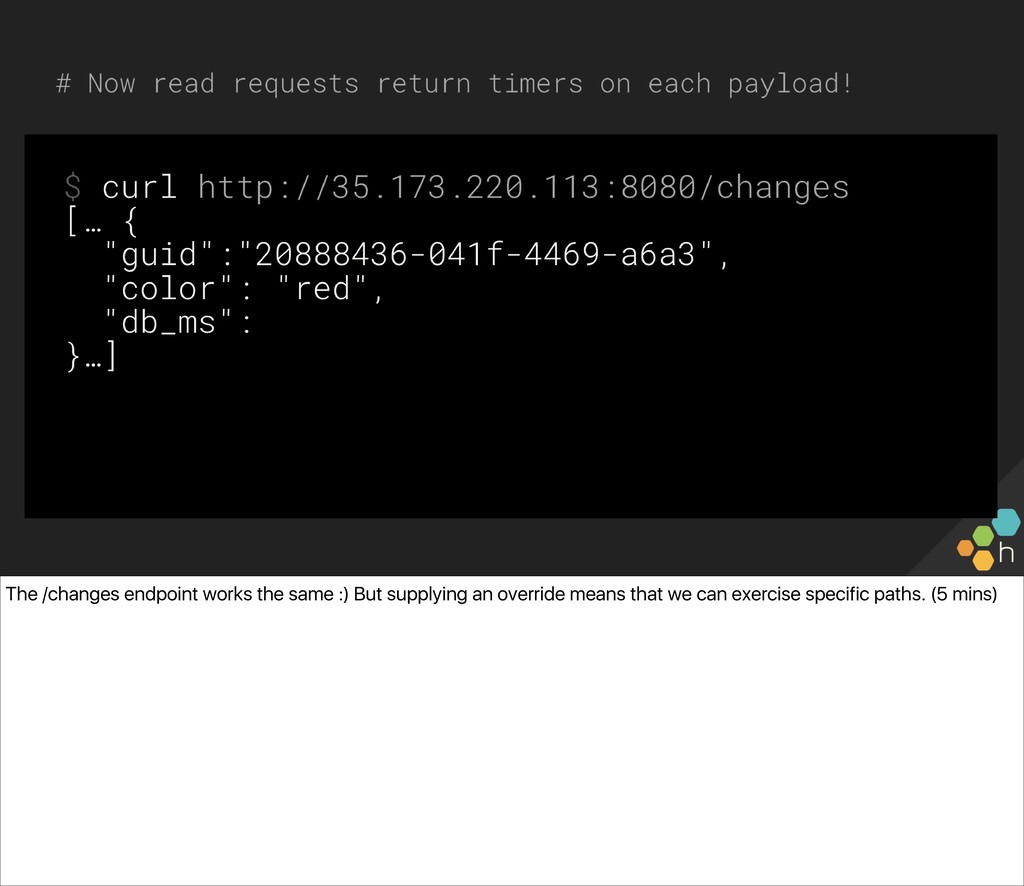
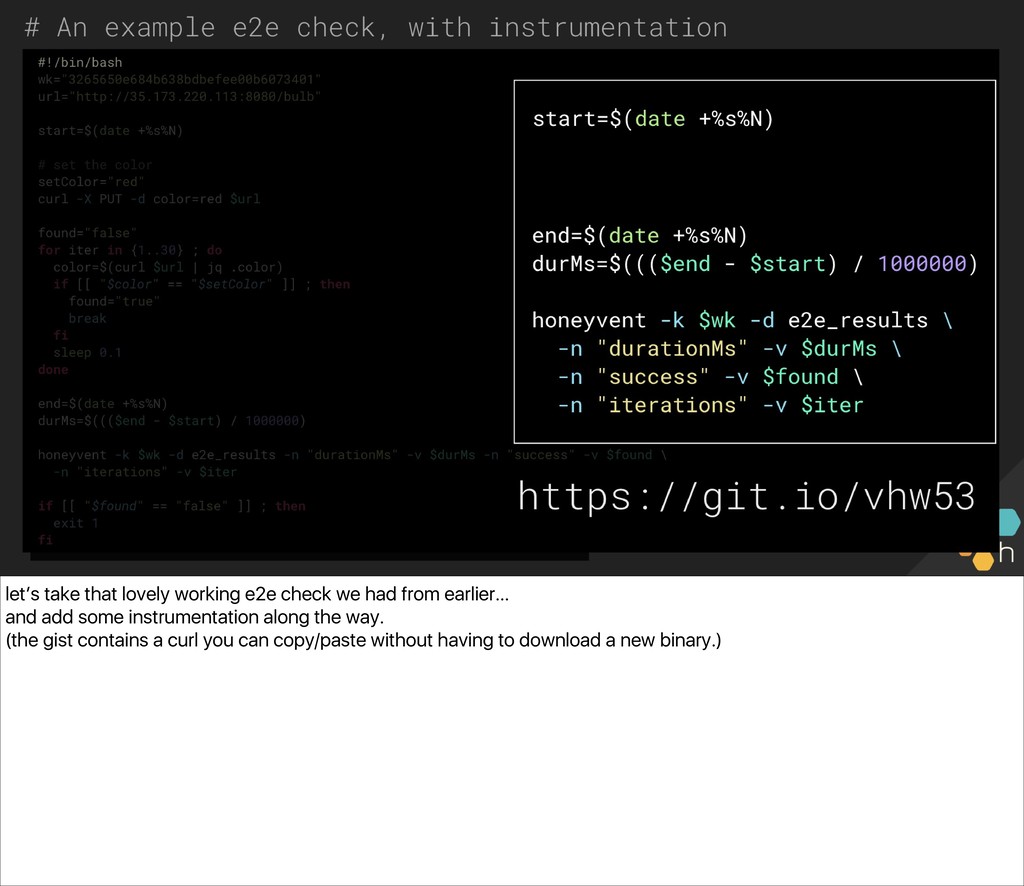
The class will write one together against a common API we can all access (a small server driving a Philips Hue bulb in the front of the room), and use the simple lightbulb server as a touchpoint from which to gauge the “correctness” of the system. You’ll also write an e2e check for the server, in whichever language and environment you prefer. Ben and Christine then explore capturing, visualizing, and alerting on results (e.g., What’s useful to capture? What metadata should we have along the way? What existing paging alerts are obsoleted by an effective e2e check?) and unveil a new, extended version of the lightbulb server, with multiple light bulbs representing a sharded backend. You’ll update your e2e checks for the more complicated architecture before exploring some real-world trade-offs of e2e checks.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}