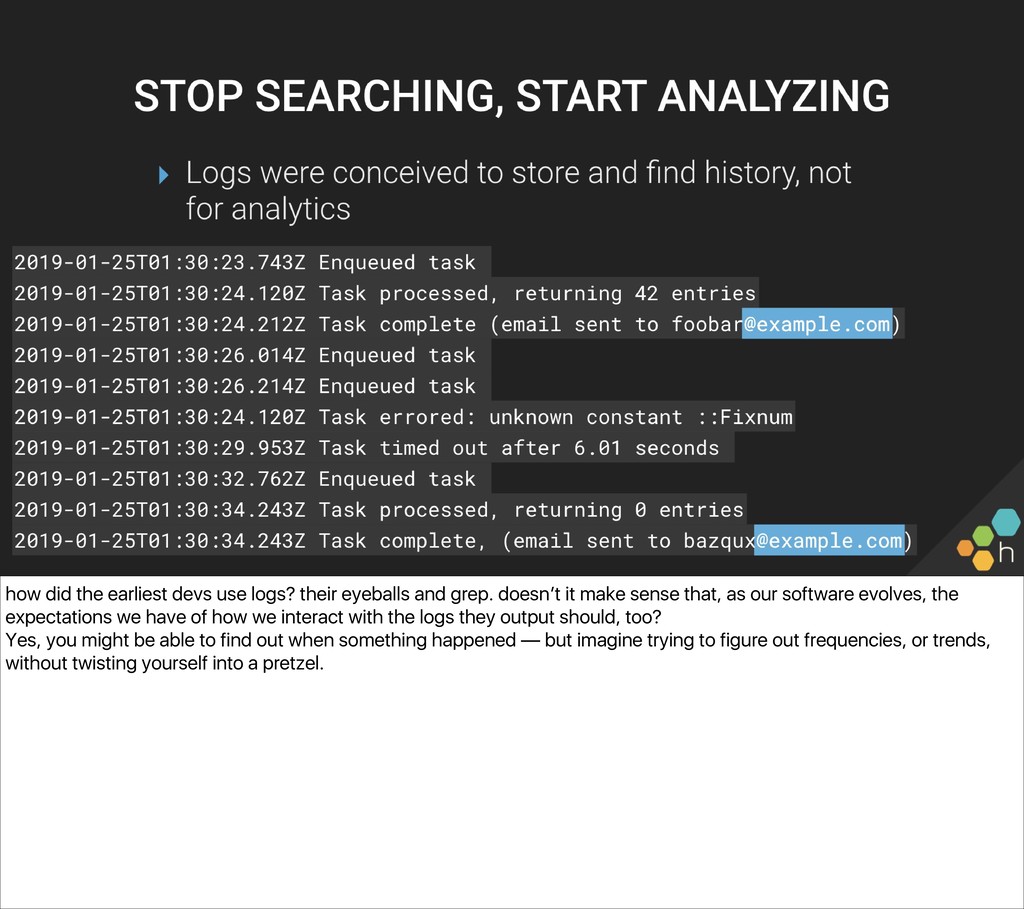
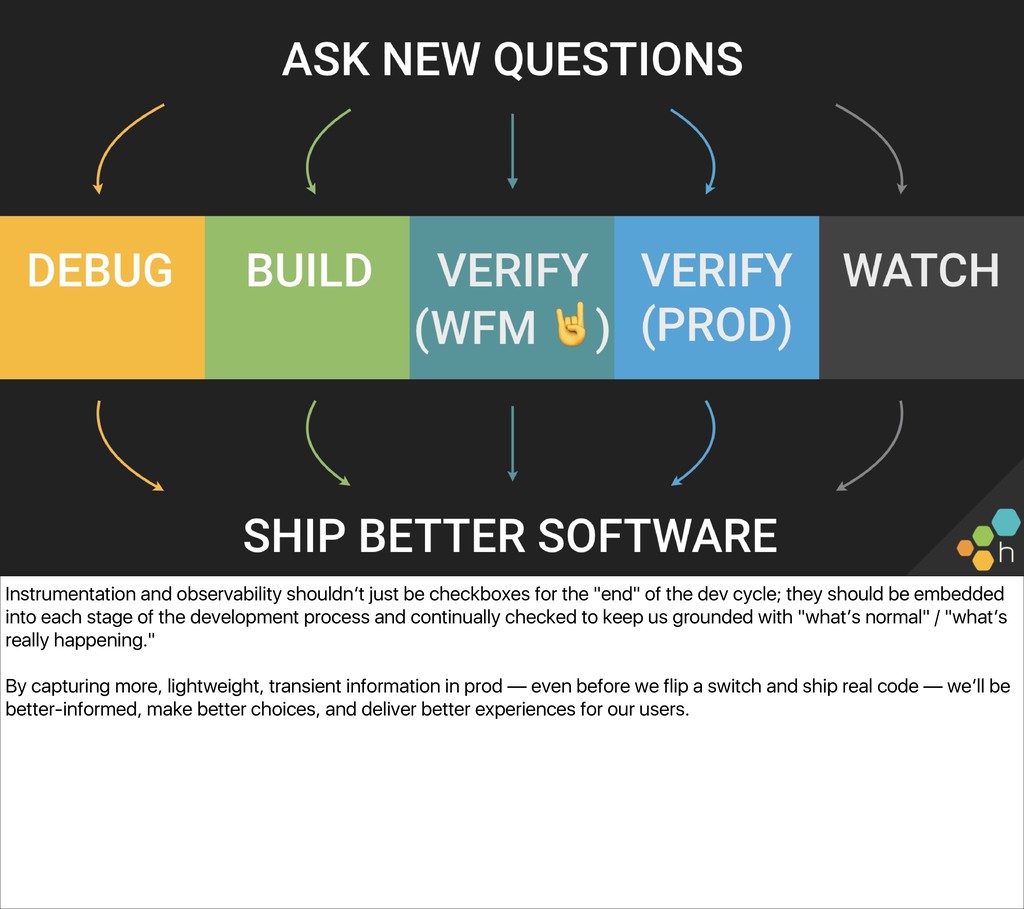
There’s been a lot of talk about software ownership—but what does “owning code in production” really mean for developers, day to day? Many development teams still reach for logs in production as the most familiar way to bridge the development environment with production.
This talk will make the case that observability—and the skills to craft the right graphs and read them—benefits developers more than it does operators by examining several instances where well-informed devs can supercharge their development process:
- Data-driven product decisions (or how to know more about what needs to be done than your PM)
- Rewrites and migrations
- Feature flags and “testing in production”
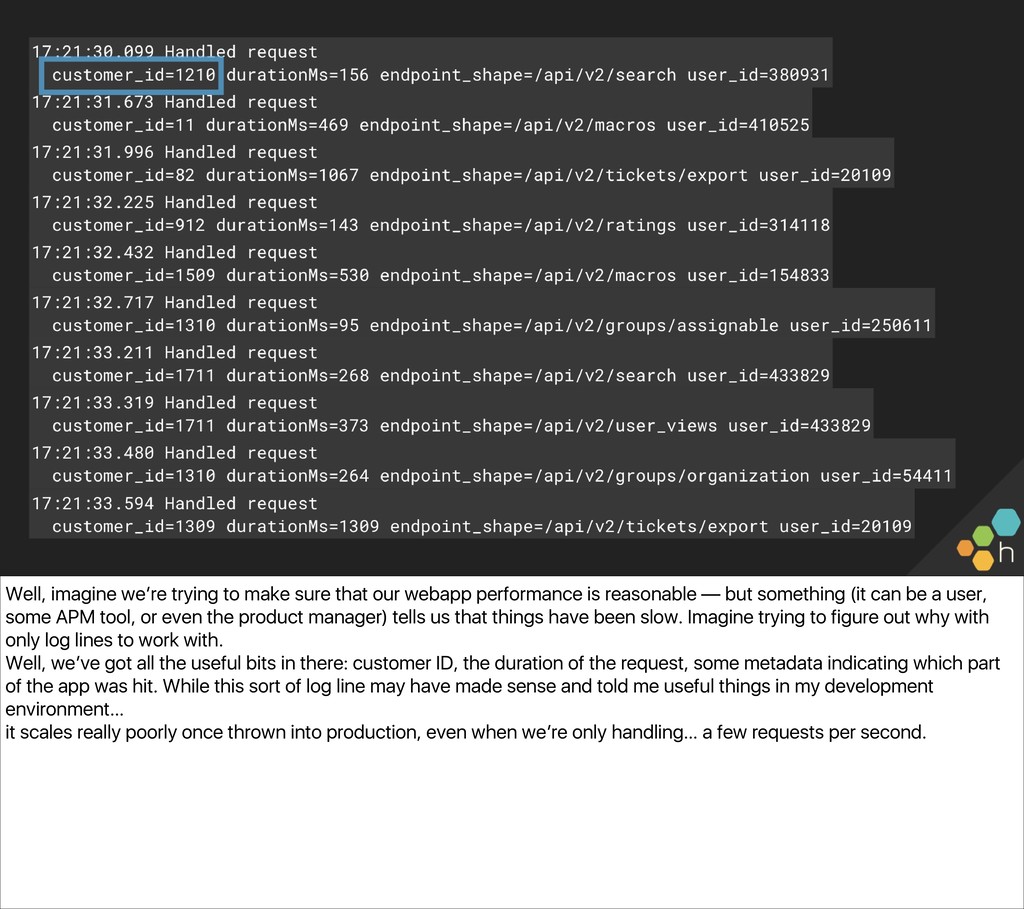
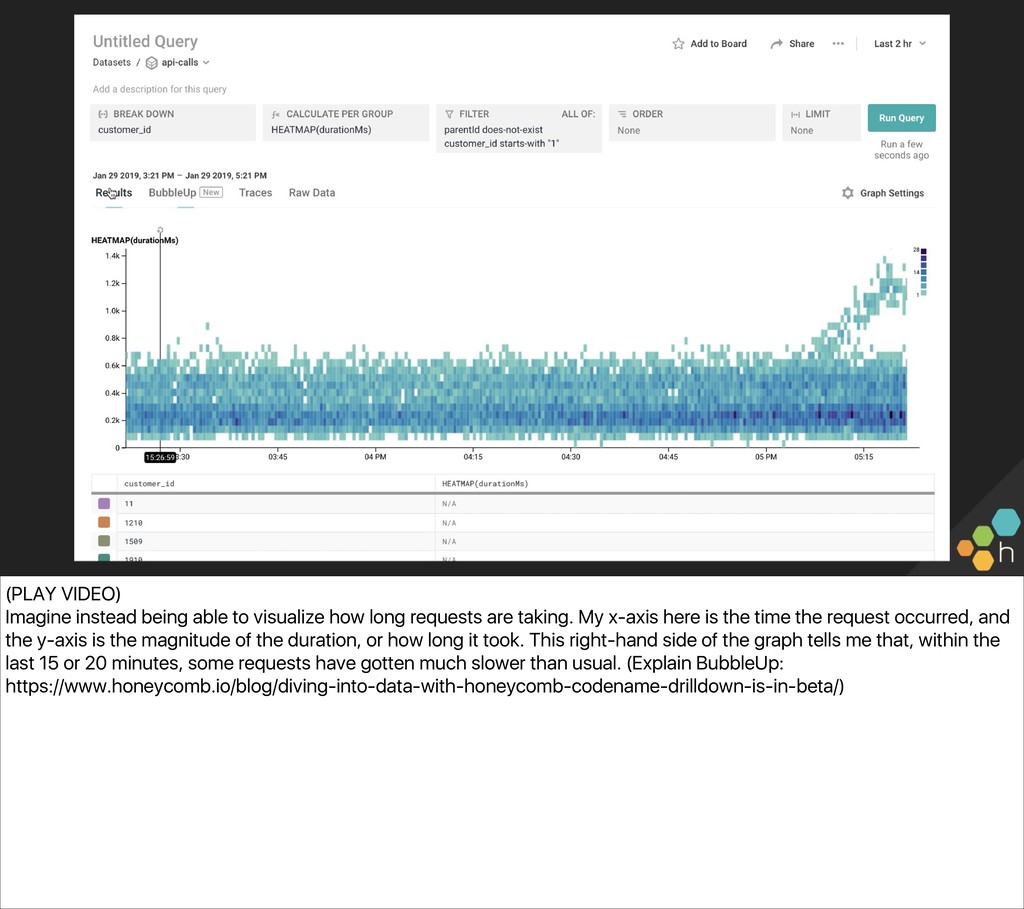
- Fine-grained performance analysis
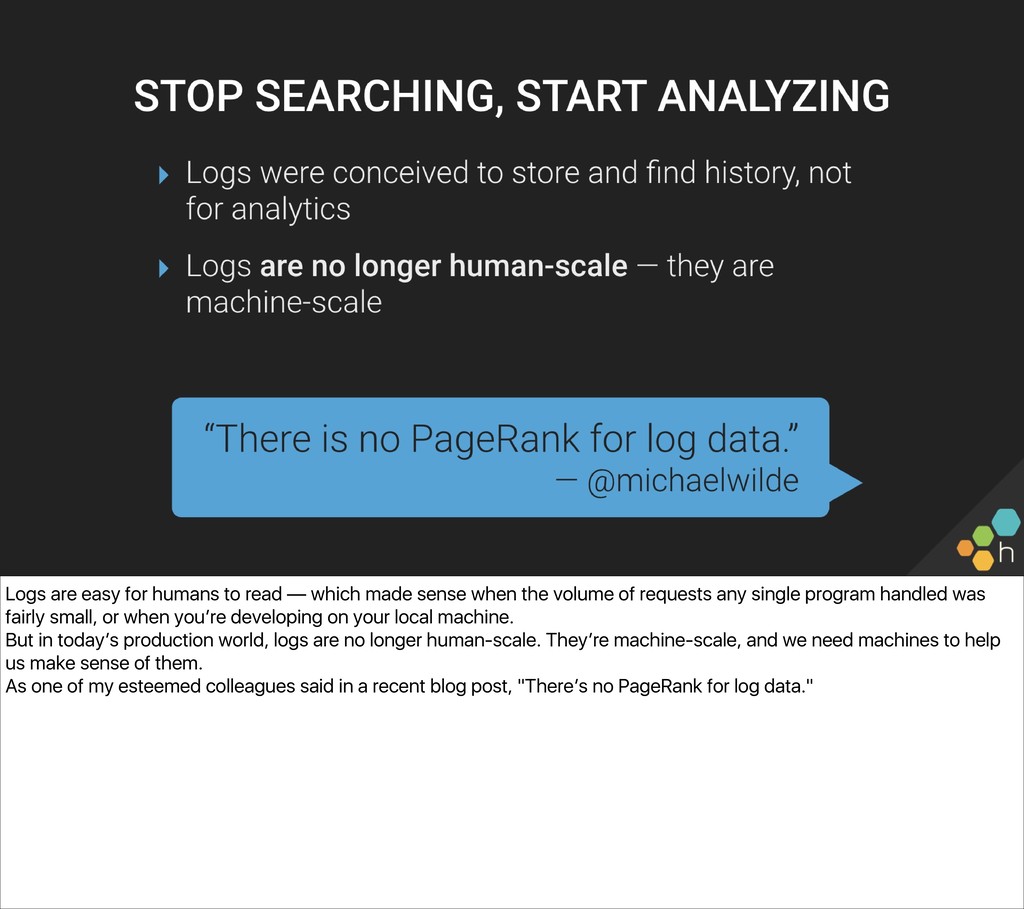
Then, we’ll lay out a series of steps to get your team from grepping unstructured text logs to outputting and analyzing well-structured traces. Instrumentation and observability aren’t all-or-nothing endeavors, and attendees should leave with an idea of “the next step” they can take to improve their ability to understand their production systems.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
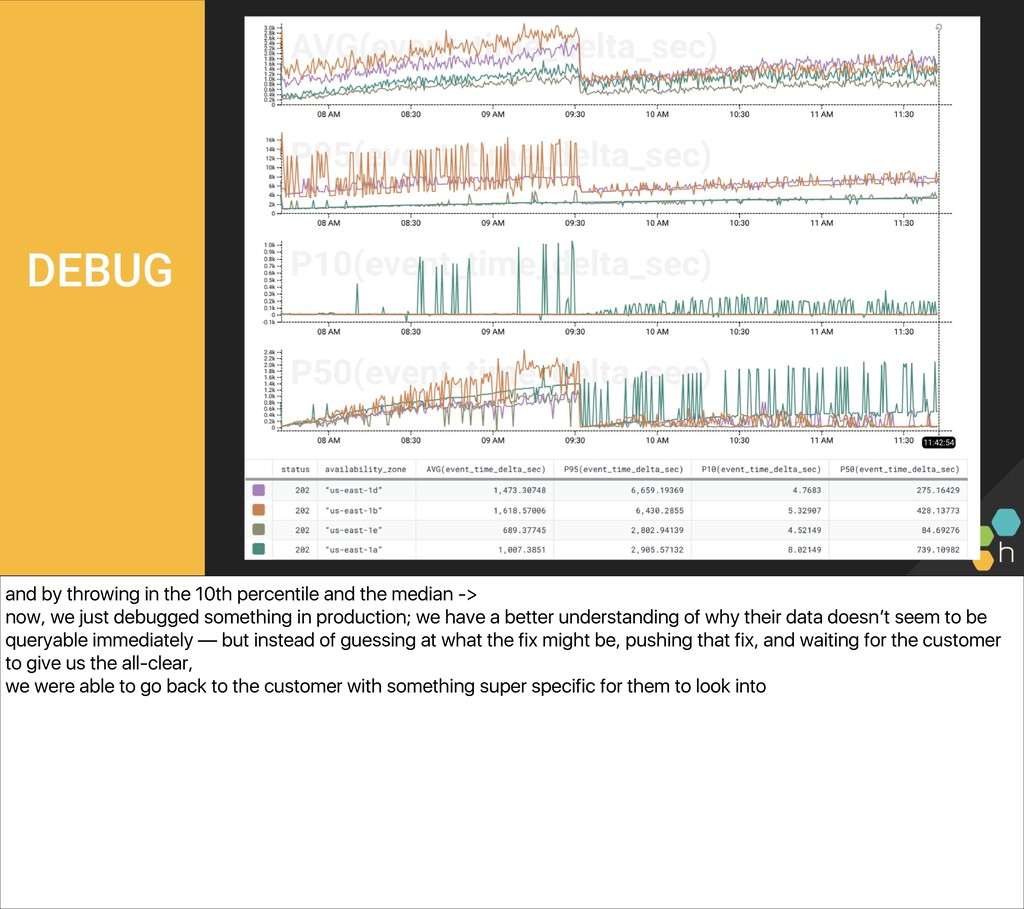{kind=link}
{kind=link}
{kind=link}
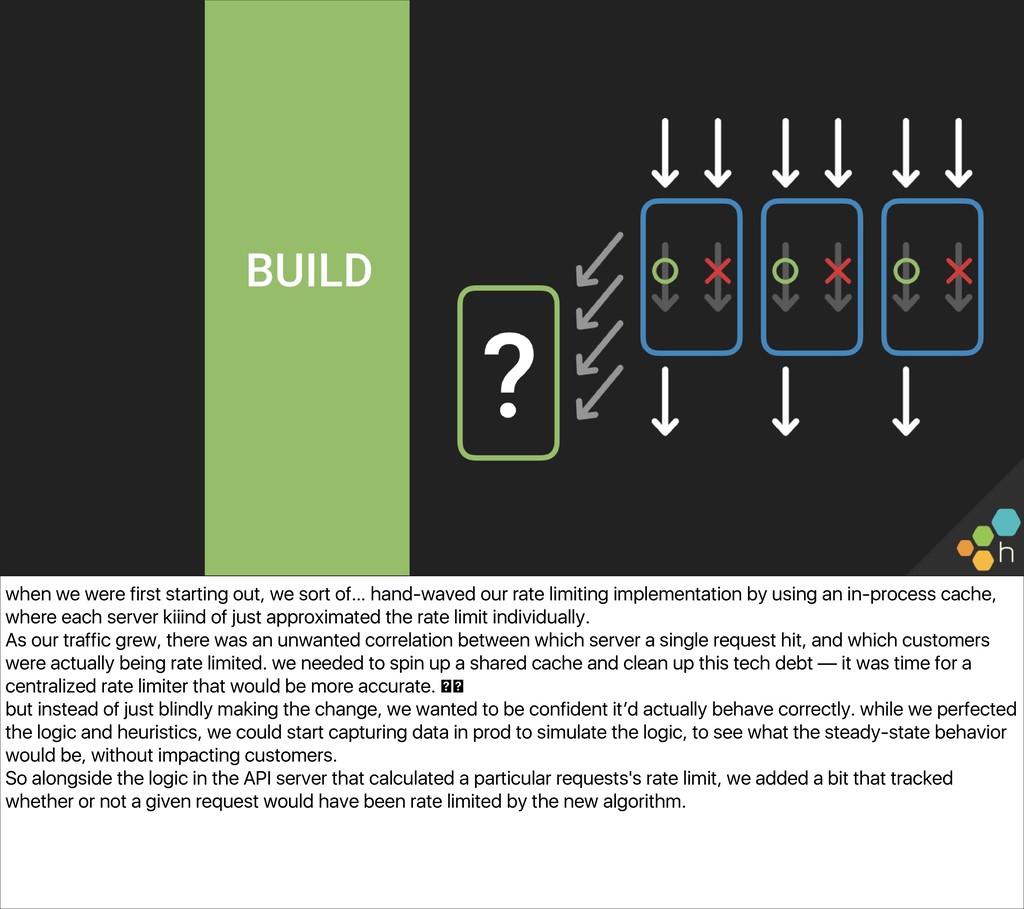{kind=link}
{kind=link}
{kind=link}
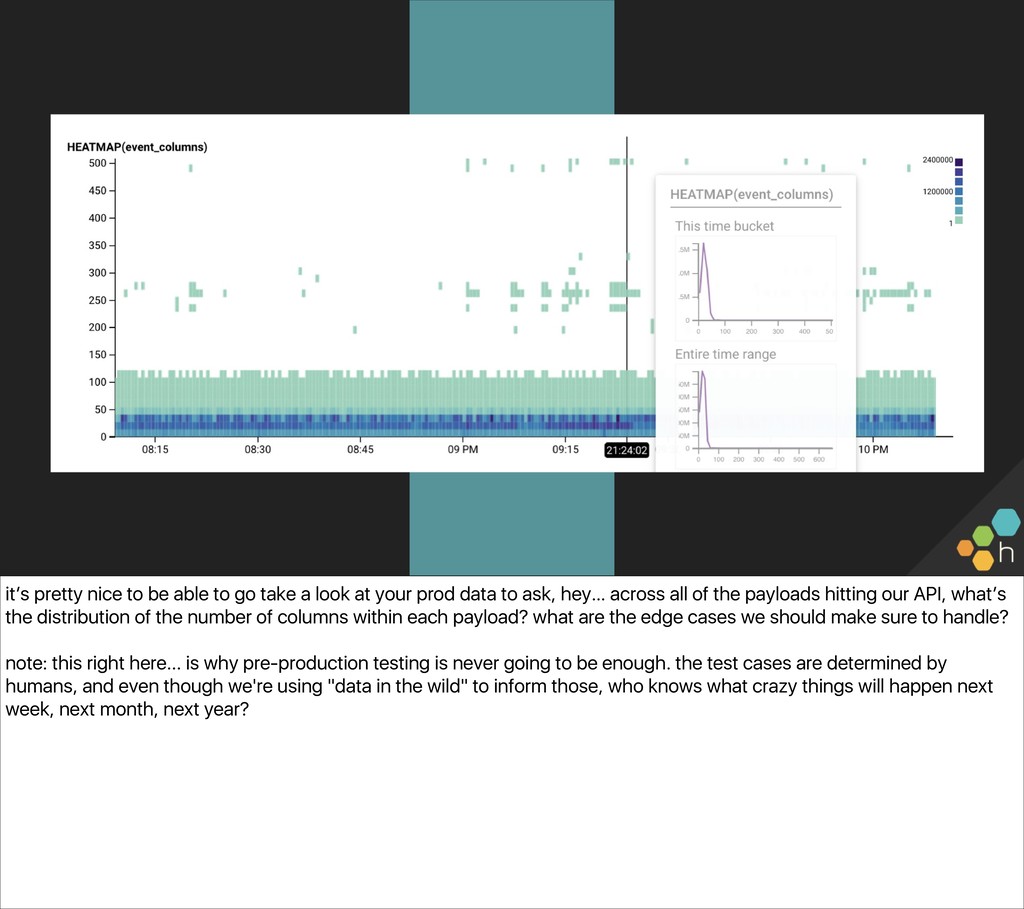{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
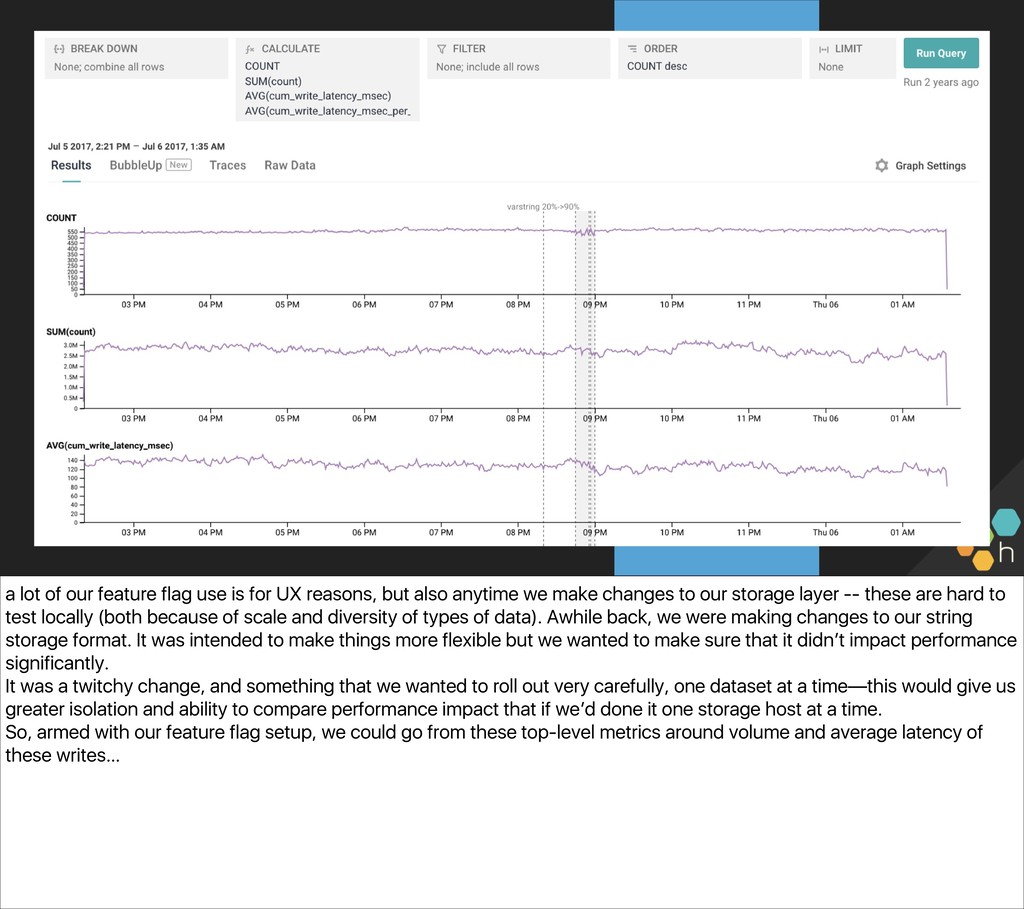
{kind=link}
{kind=link}
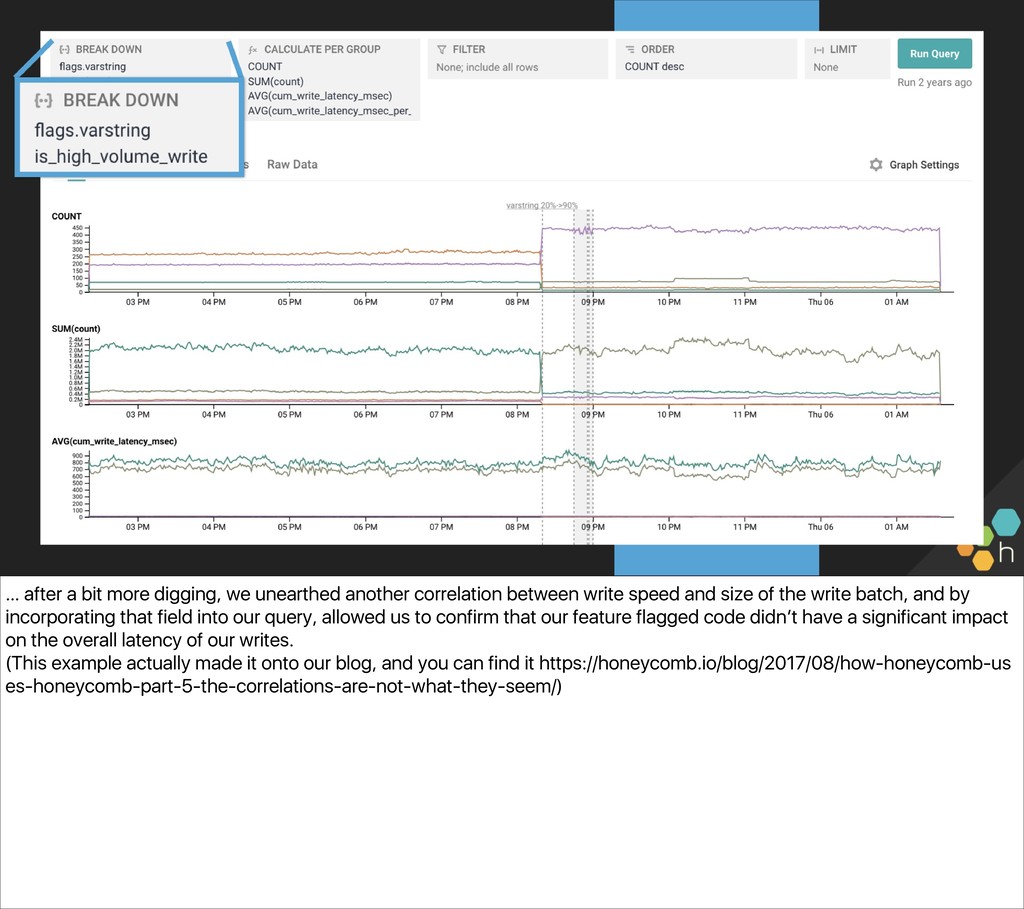
{kind=link}
{kind=link}
{kind=link}
{kind=link}
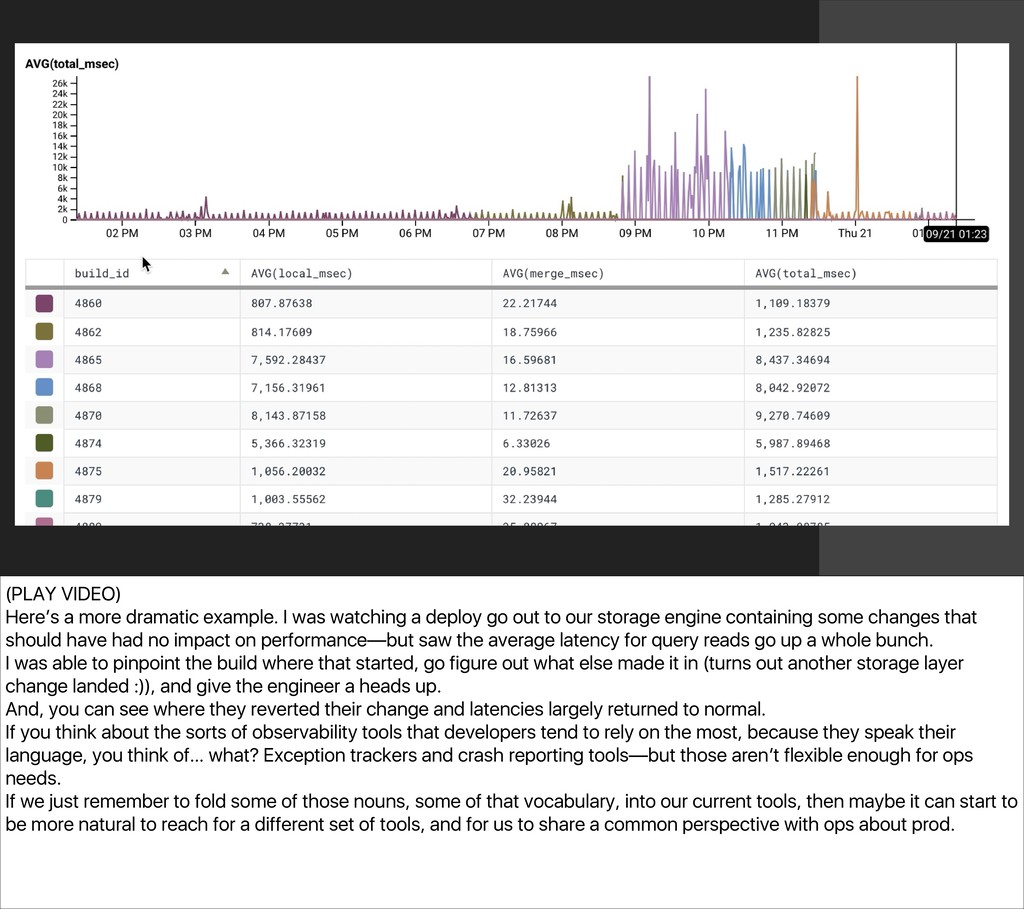
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}