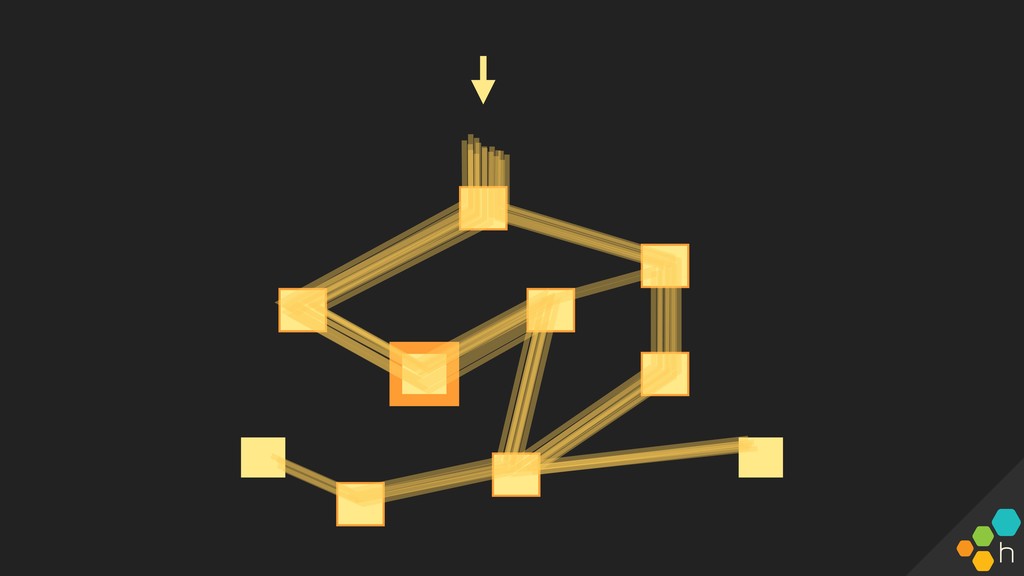
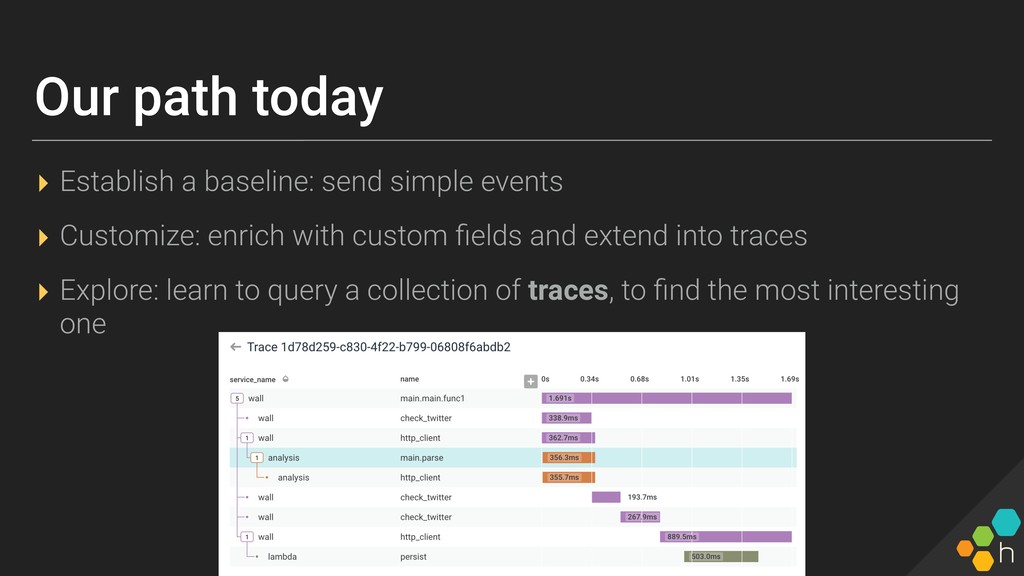
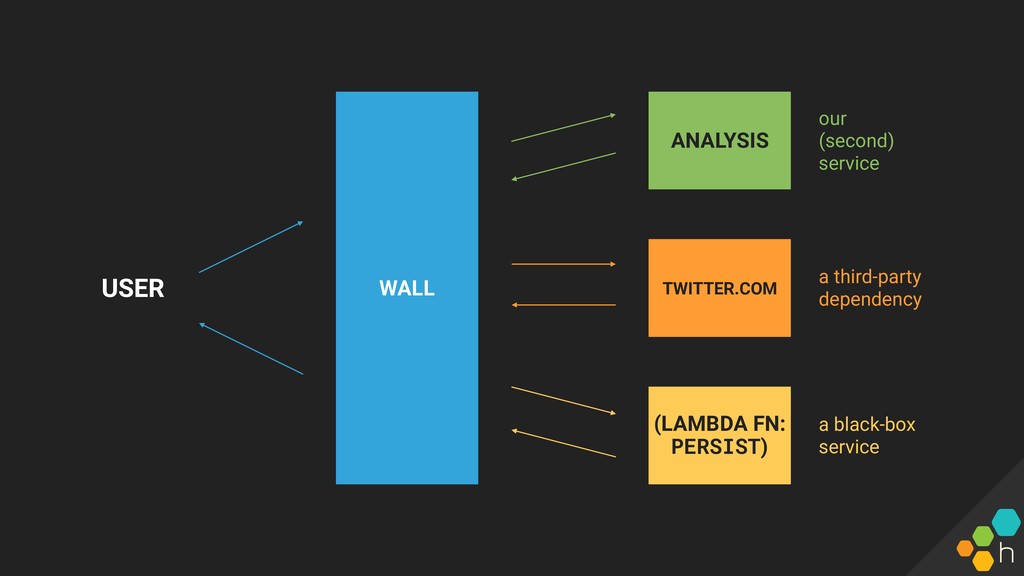
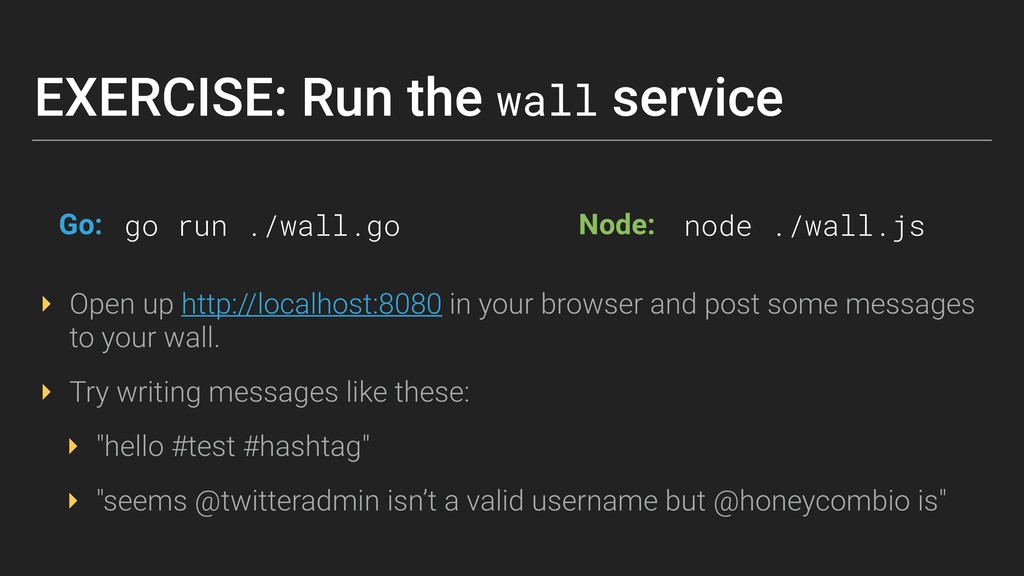
Honeycomb's first half-day Tracing workshop , held on January 24th in SF. Intended to be a great interactive overview for anyone wanting to learn about tracing: creating them and/or using them to answer questions.
We'll cover concepts + important tips for instrumenting an application for tracing, capturing instrumentation around external dependencies, and using traces to debug incidents. Honeycomb engineers will be on hand for the workshop and office hours afterwards, for hands-on consultation around instrumentation and tracing.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}