LLMs can provide a quick injection of magic into an existing product (or product concept)! Most of us looking to build on LLMs aren't ML engineers or AI experts, after all, and this new wave of LLM offerings makes it easy for any of us to build something delightful.
But once that product or feature is shipped, in production, in front of users, the problems all collapse back into something that feels awfully familiar: performance challenges, questionable accuracy, and unhappy or confused users.
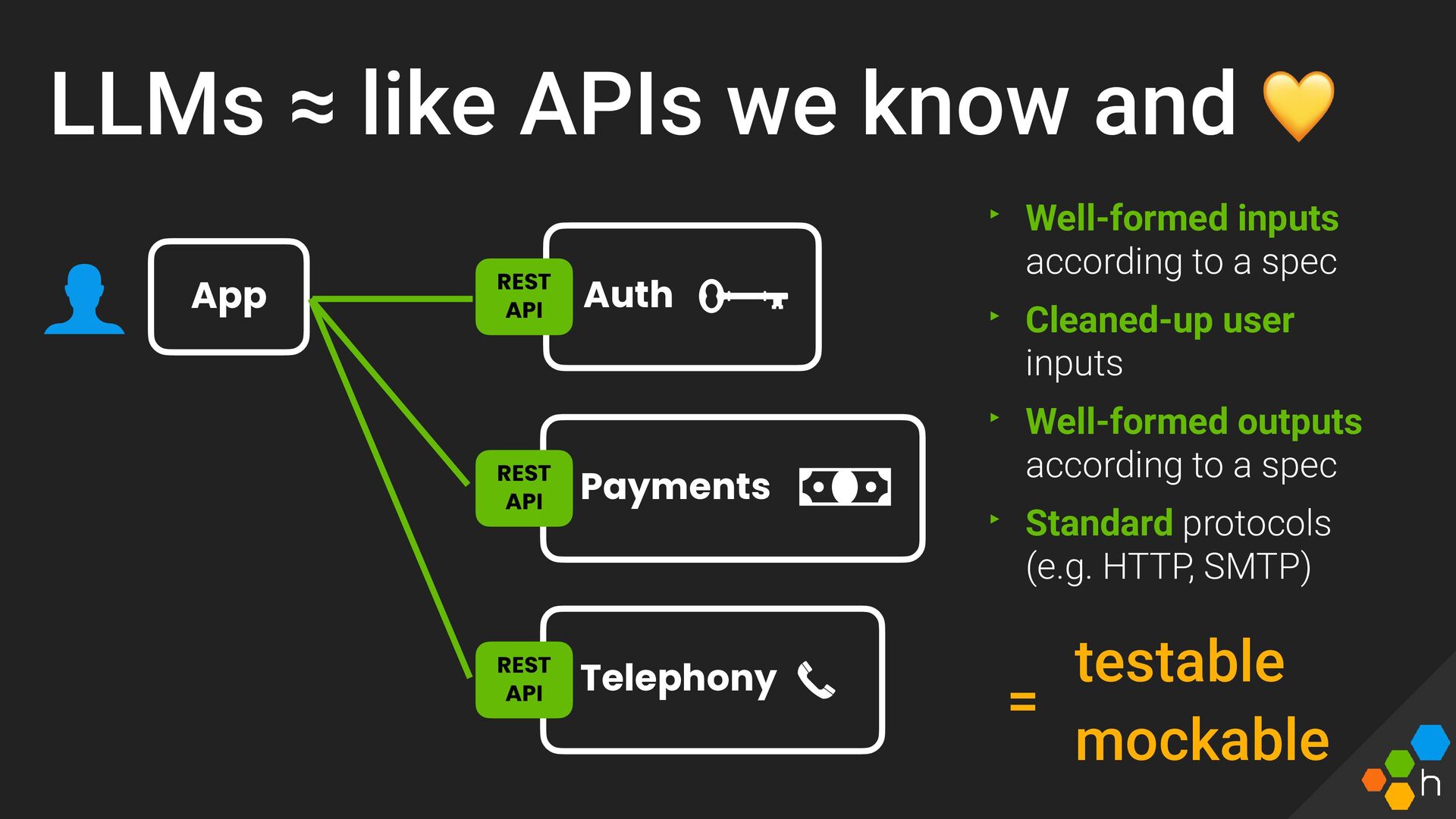
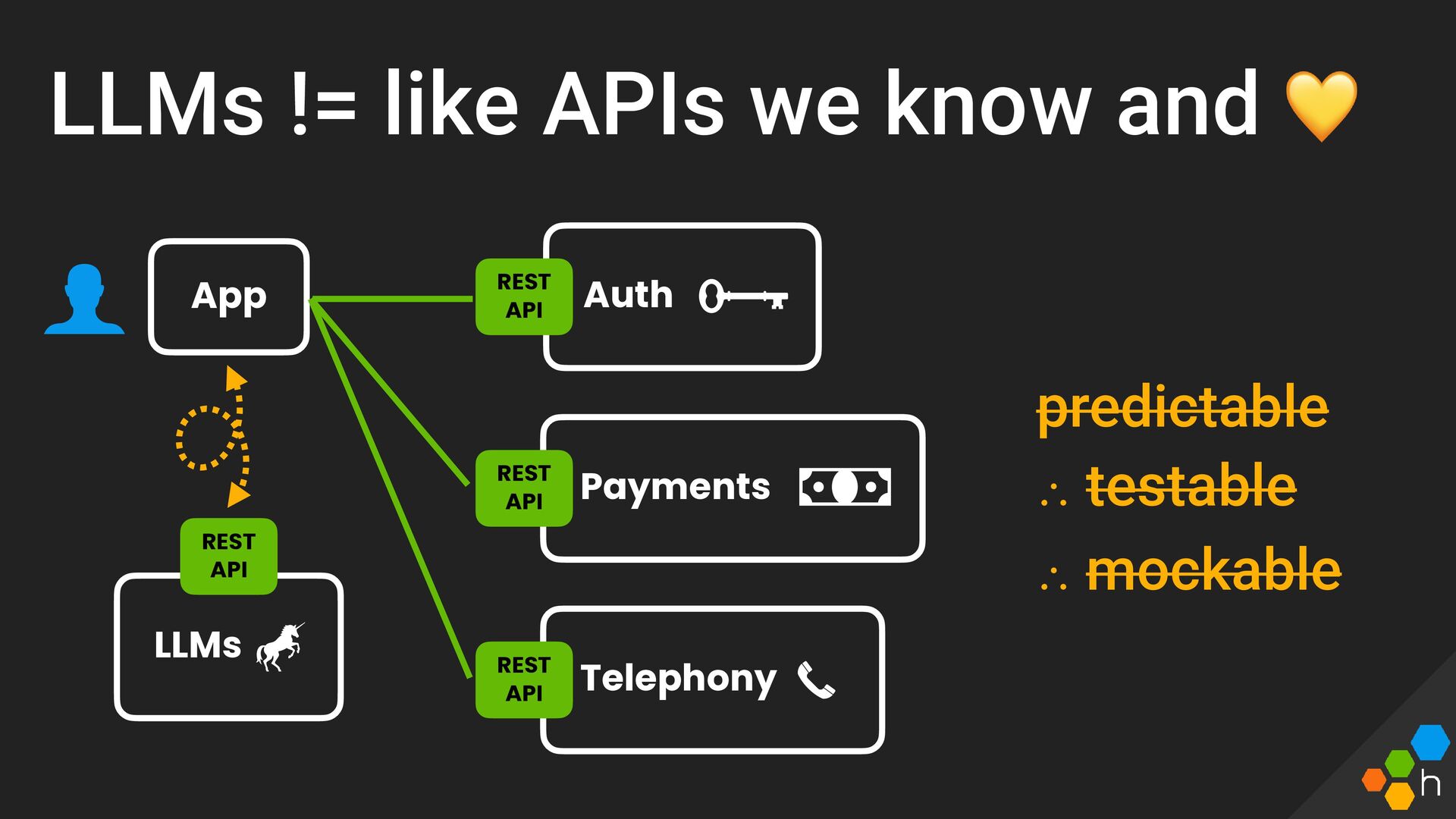
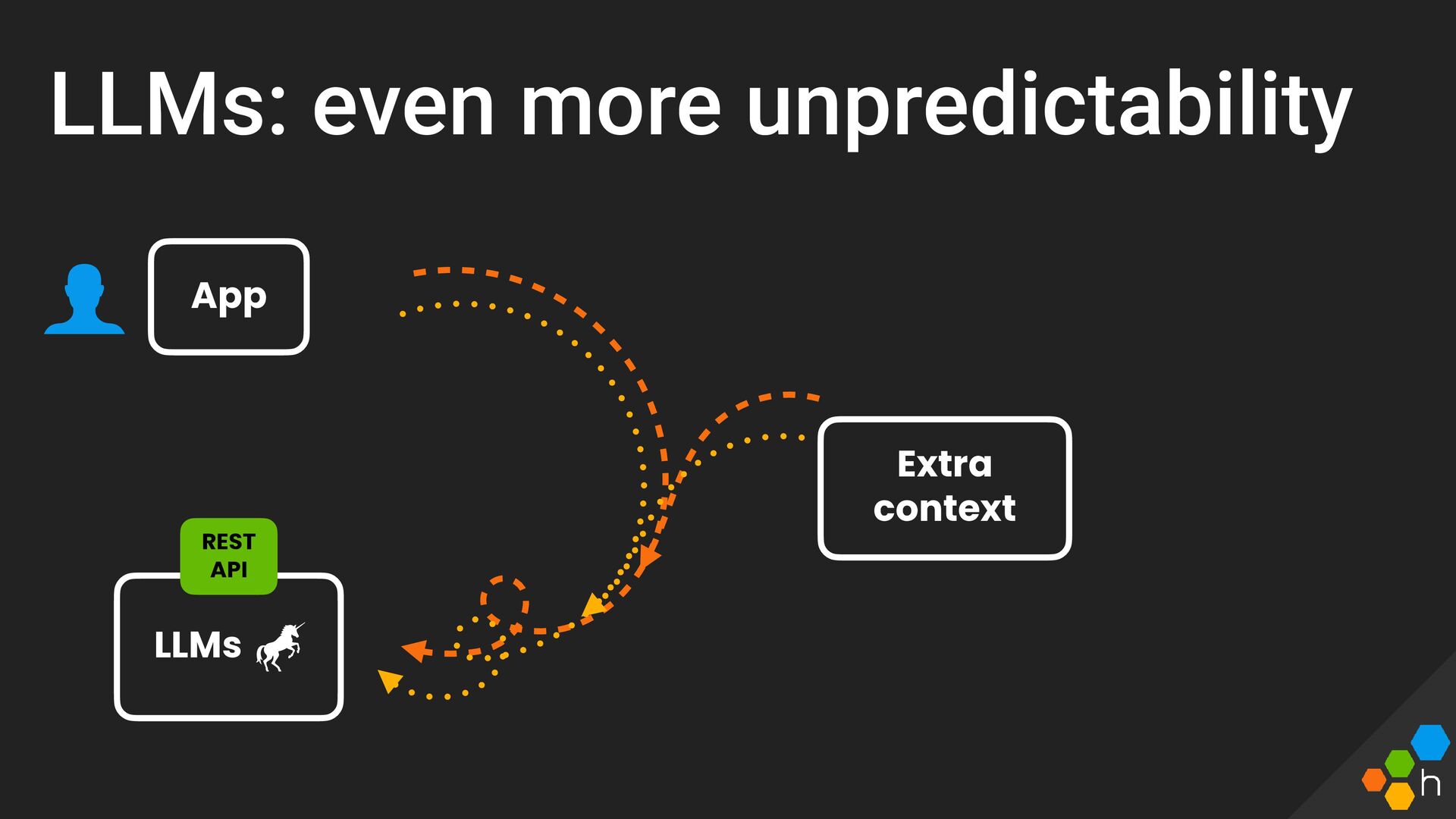
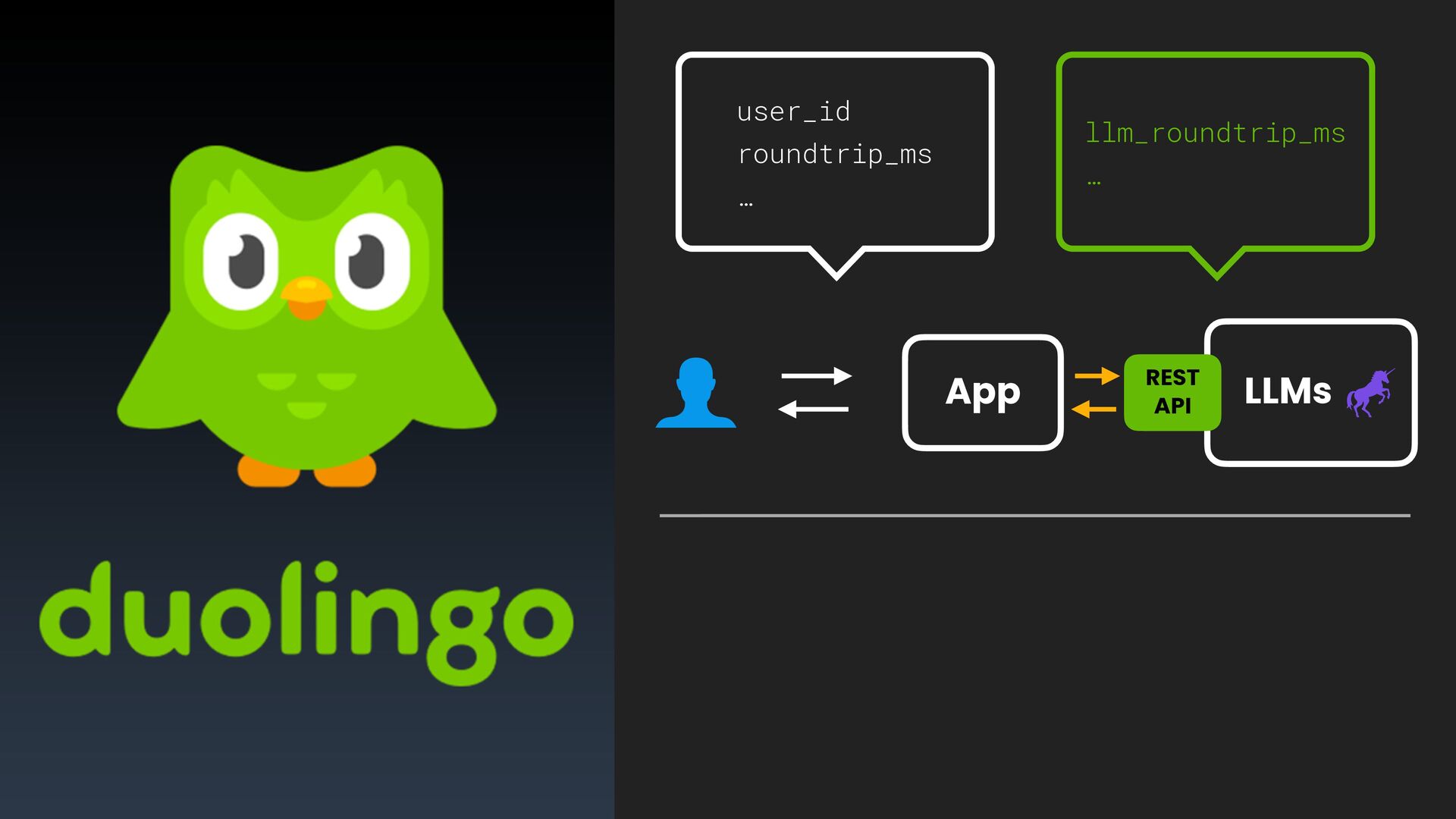
This talk will assert that building on LLMs is just like buliding on top of any other sort of black box in our architecture (APIs, DBs, etc)—this one just happens to be inherently unpredictable and probablistic.
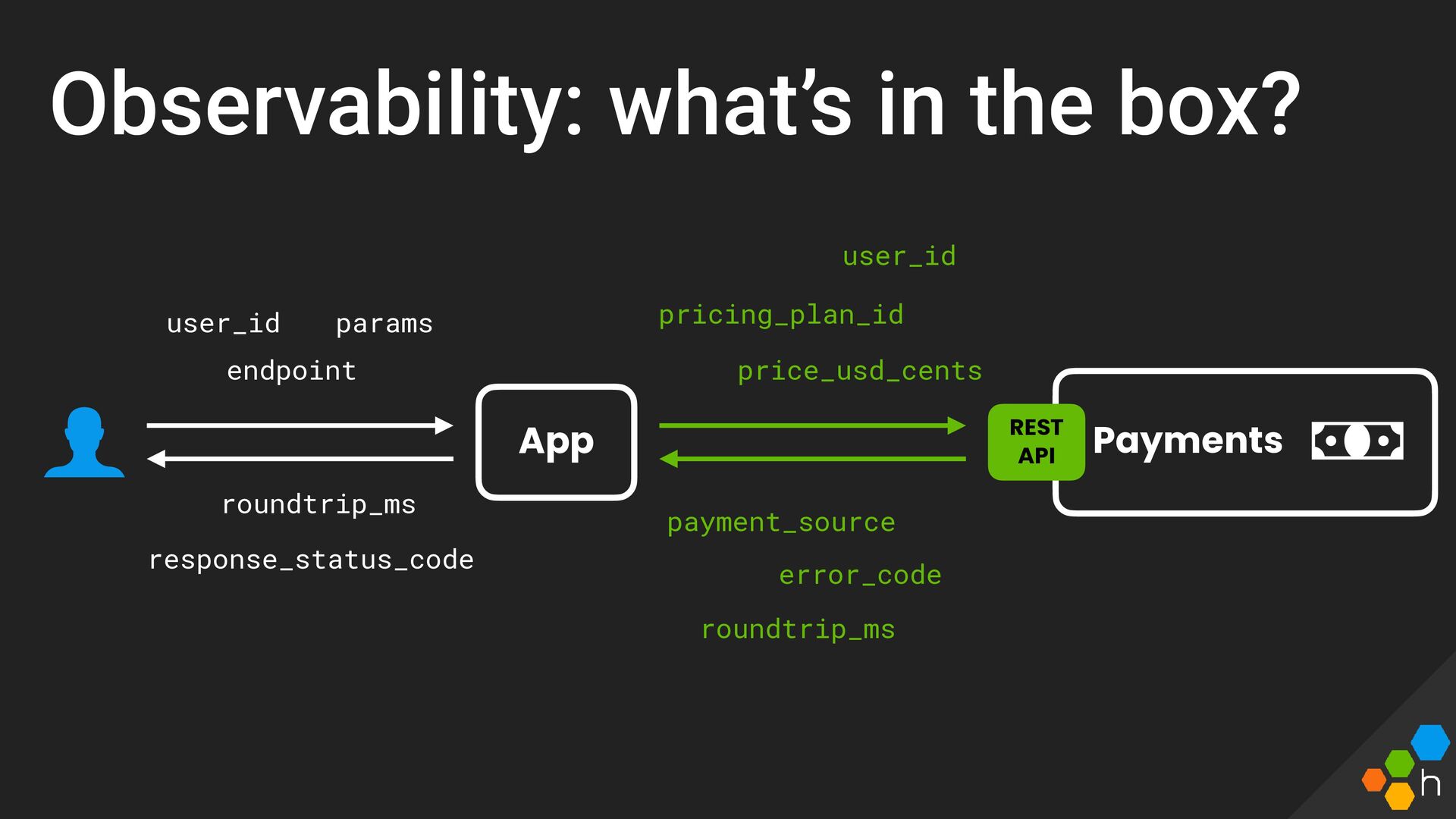
We'll cover techniques for instrumentation, how to leverage observability practices, and even incorporate SLOs to ensure your team continues to deliver a great service to your users.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
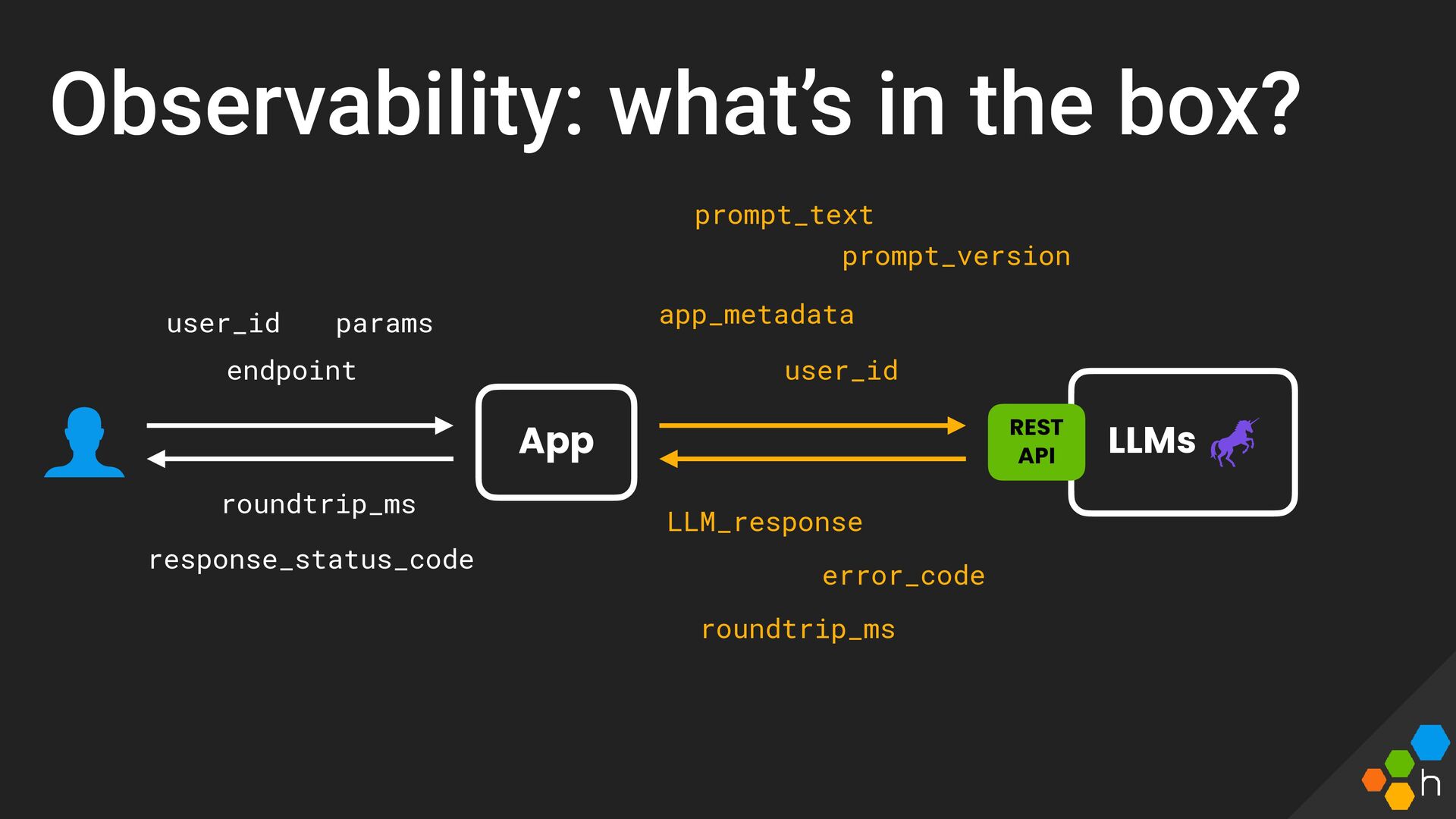{kind=link}
{kind=link}
{kind=link}
{kind=link}
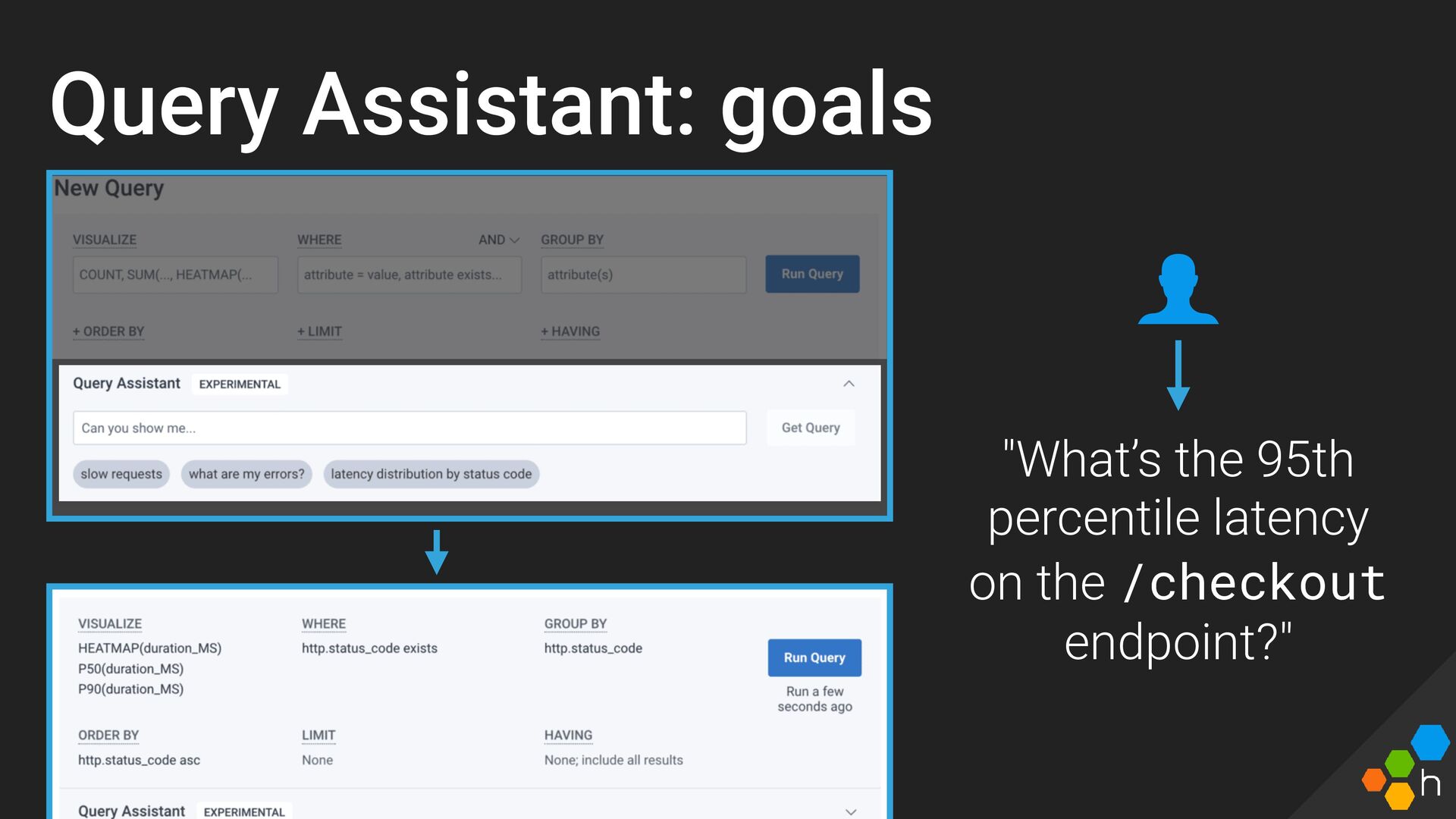{kind=link}
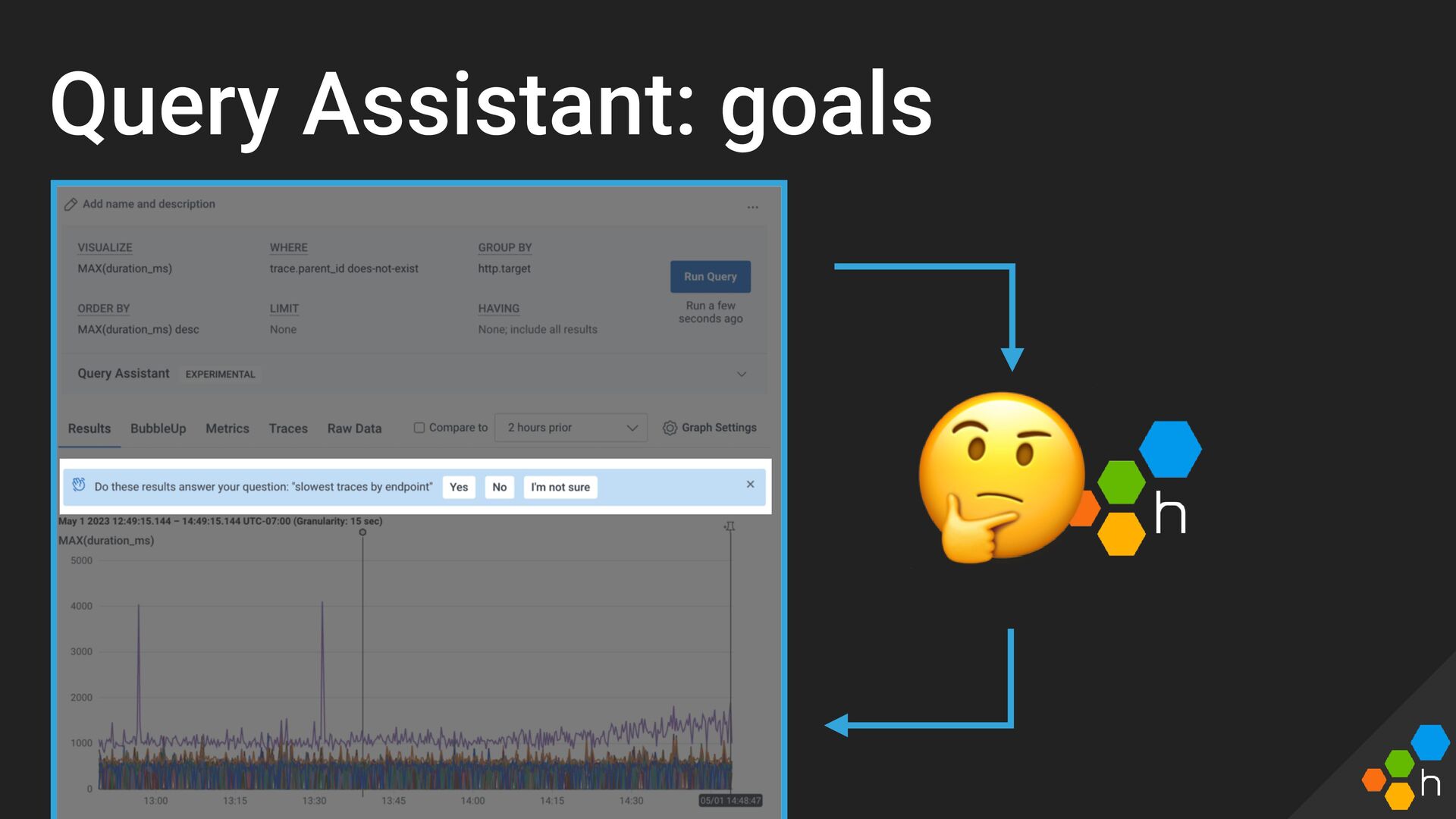{kind=link}
{kind=link}
{kind=link}
{kind=link}
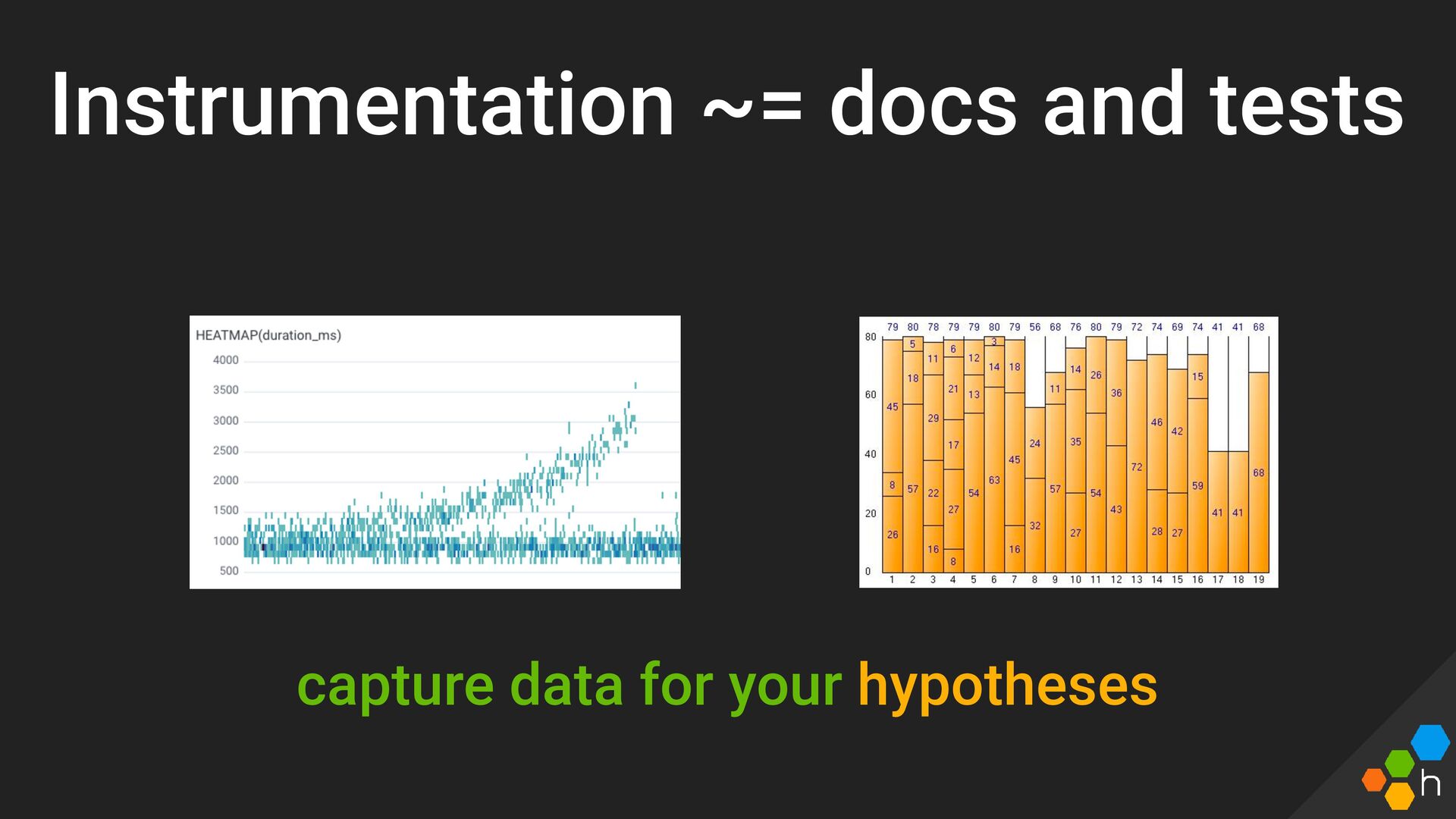{kind=link}
{kind=link}
{kind=link}
{kind=link}
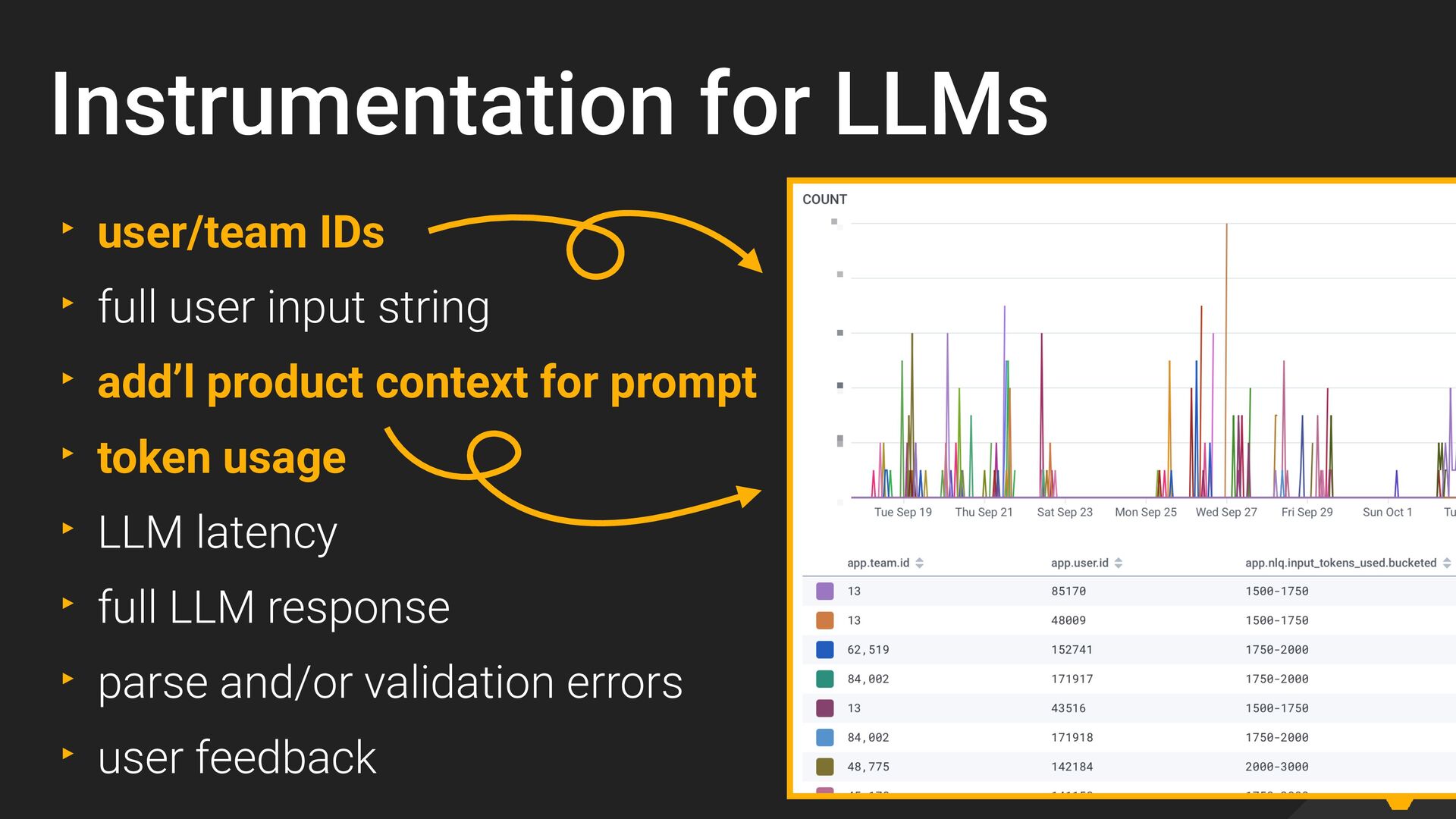{kind=link}
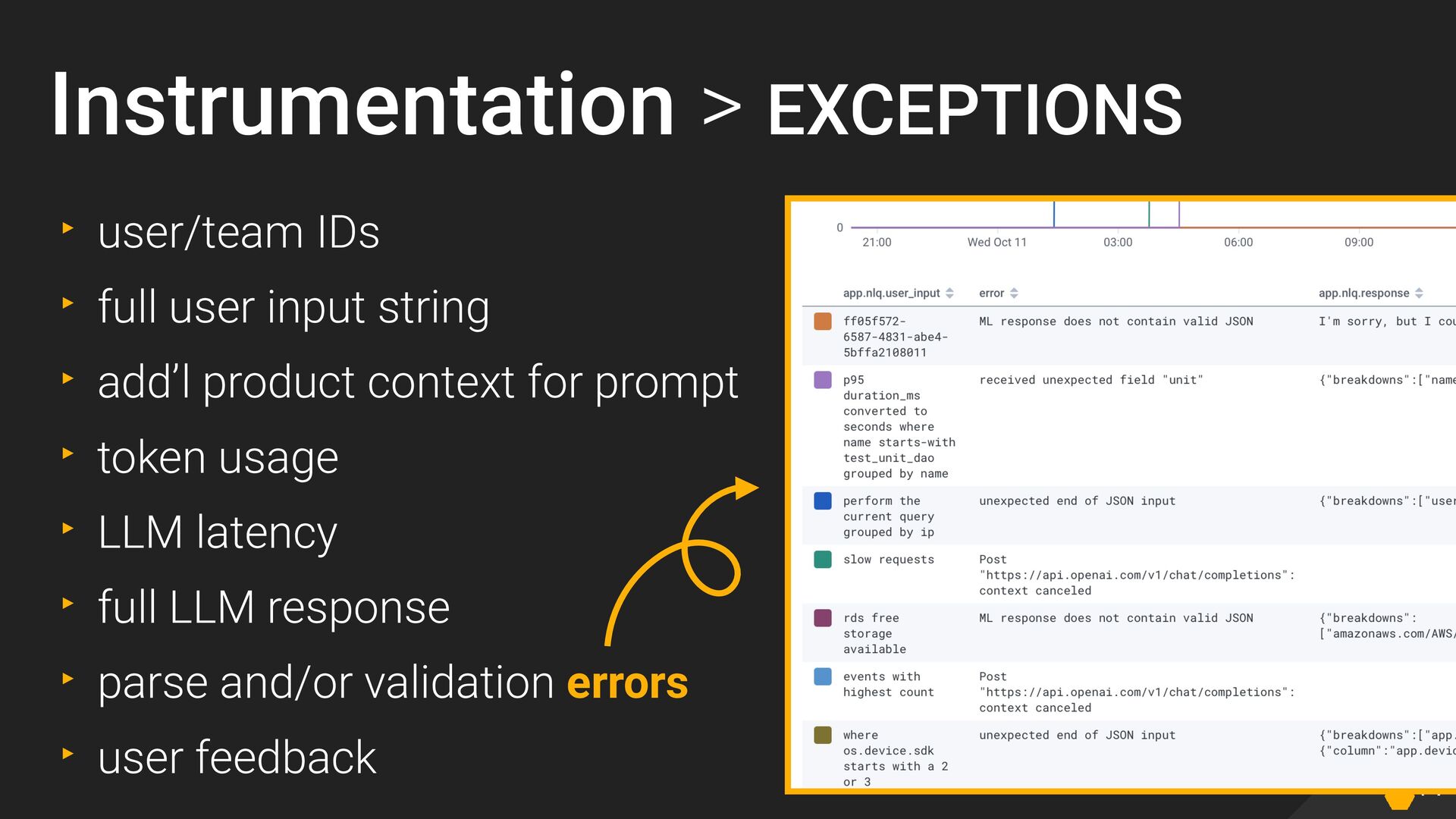{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
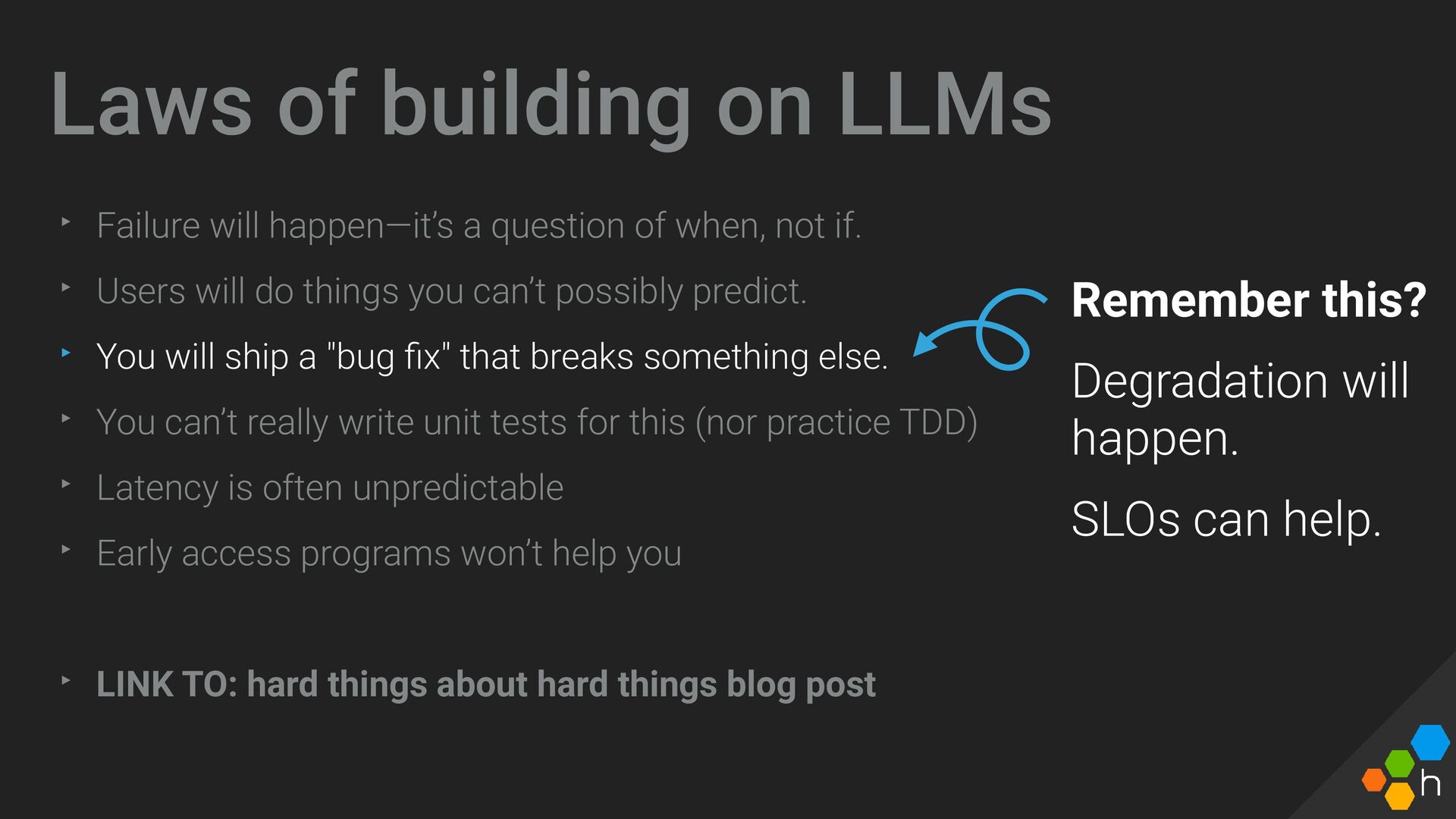{kind=link}
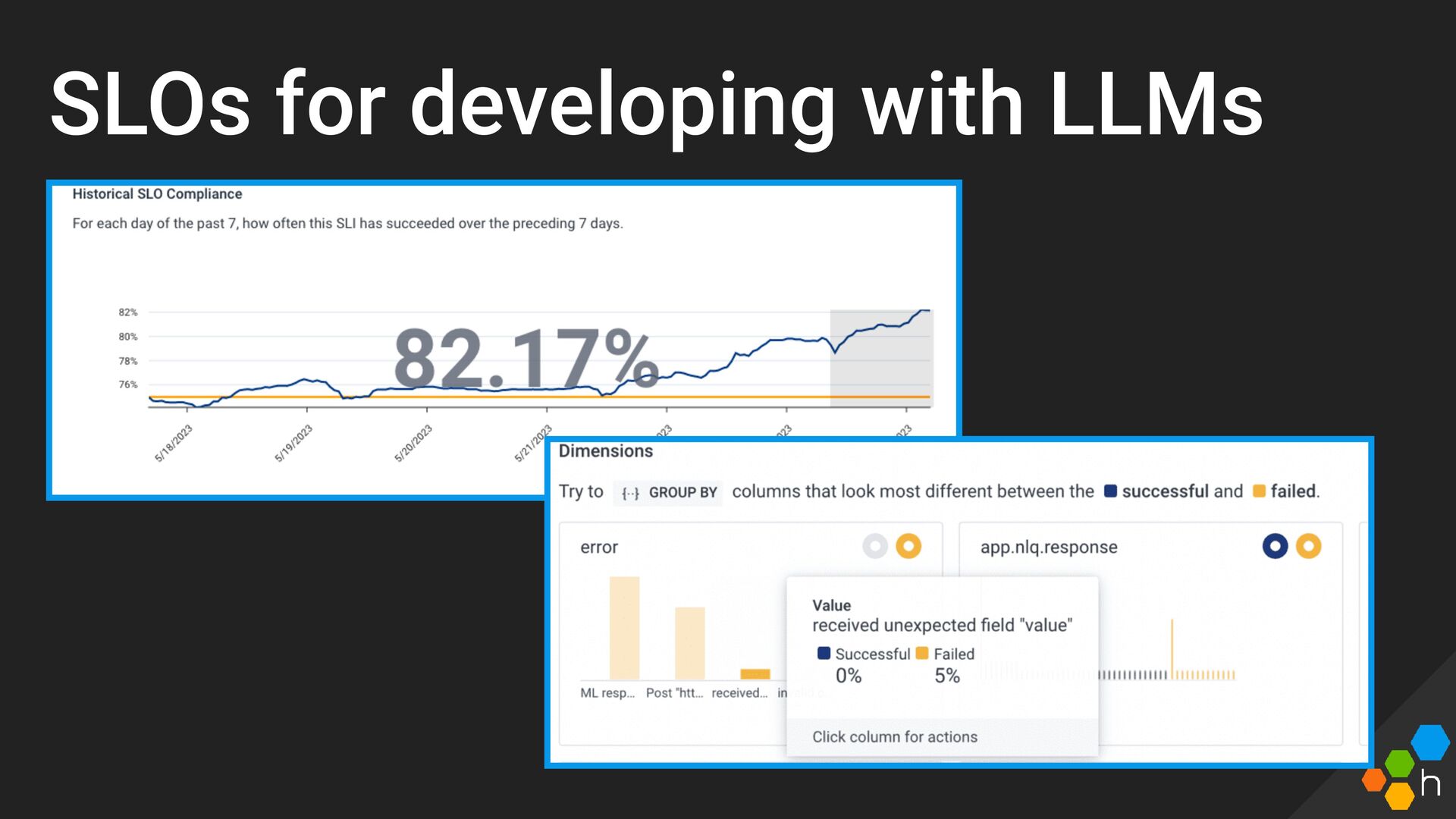{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}