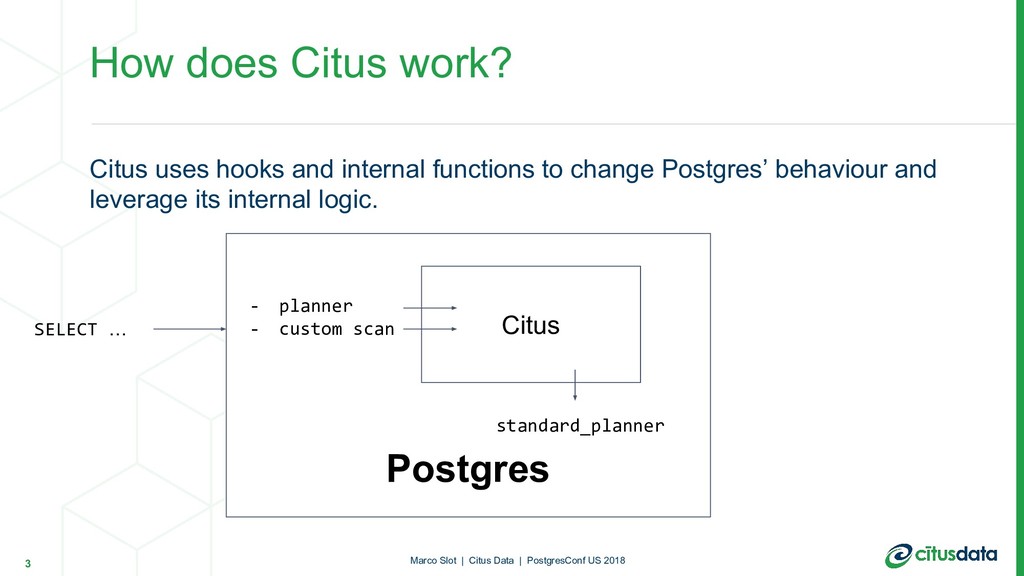
Citus is a sharding extension for Postgres that can efficiently distribute a wide range of SQL queries. It uses Postgres' planner hook to transparently intercept and plan queries on "distributed" tables. Citus then executes the queries in parallel across many servers, in a way that delegates most of the heavy lifting back to Postgres.
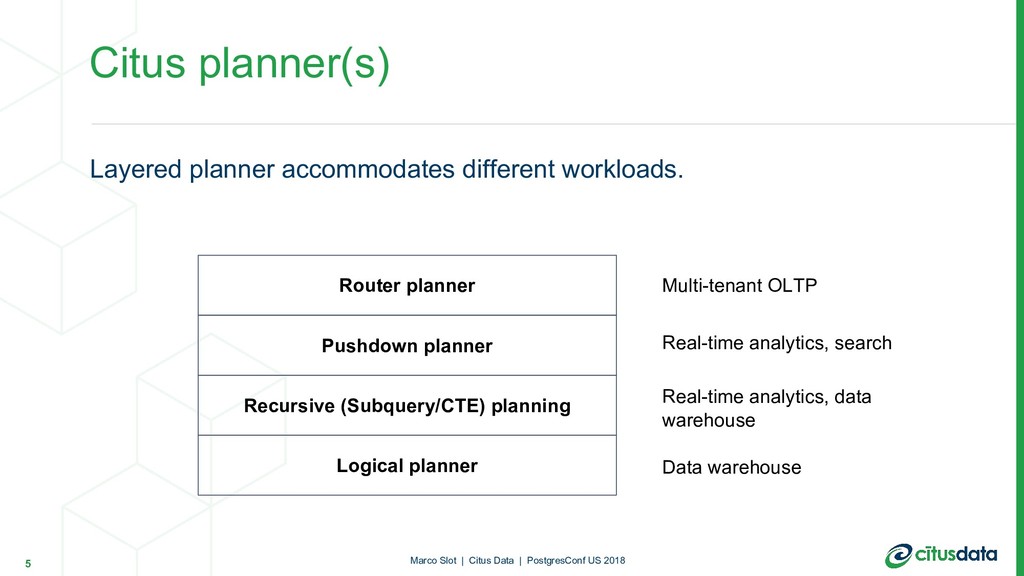
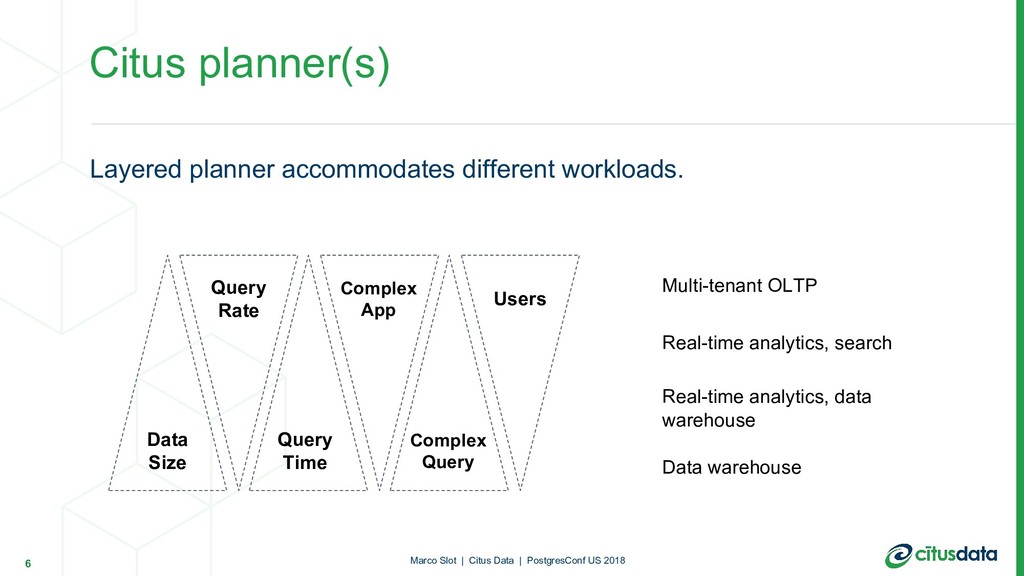
Within Citus, we distinguish between several types of SQL queries, which each have their own planning logic:
Local-only queries
Single-node “router” queries
Multi-node “real-time” queries
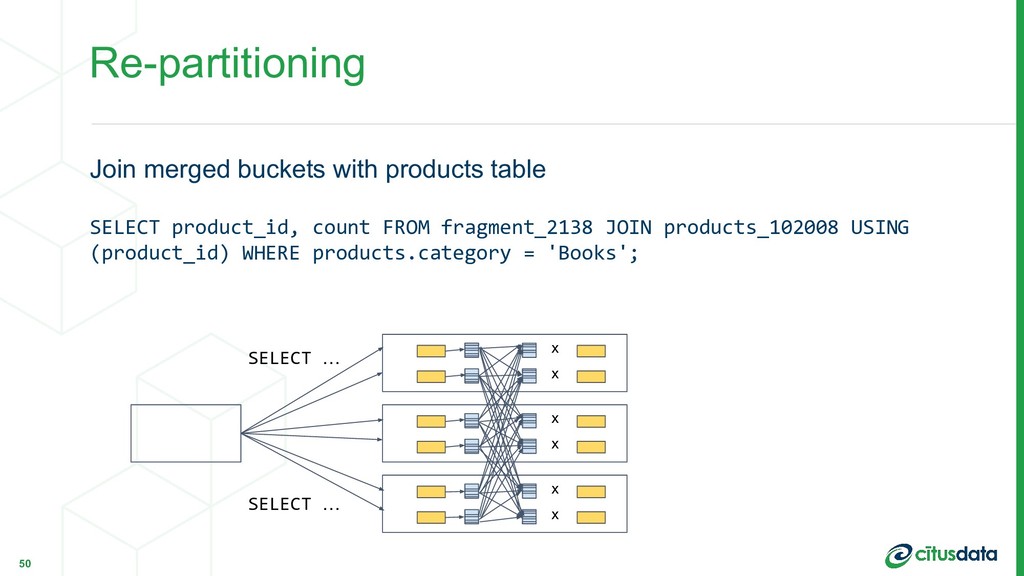
Multi-stage queries
Each type of query corresponds to a different use case, and Citus implements several planners and executors using different techniques to accommodate the performance requirements and trade-offs for each use case.
This talk will discuss the internals of the different types of planners and executors for distributing SQL on top of Postgres, and how they can be applied to different use cases.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
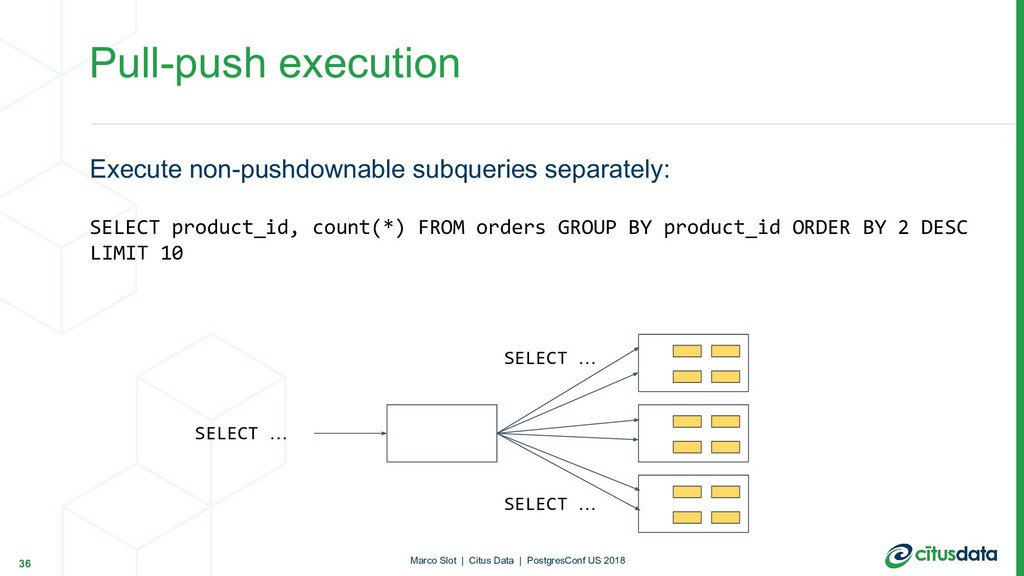{kind=link}
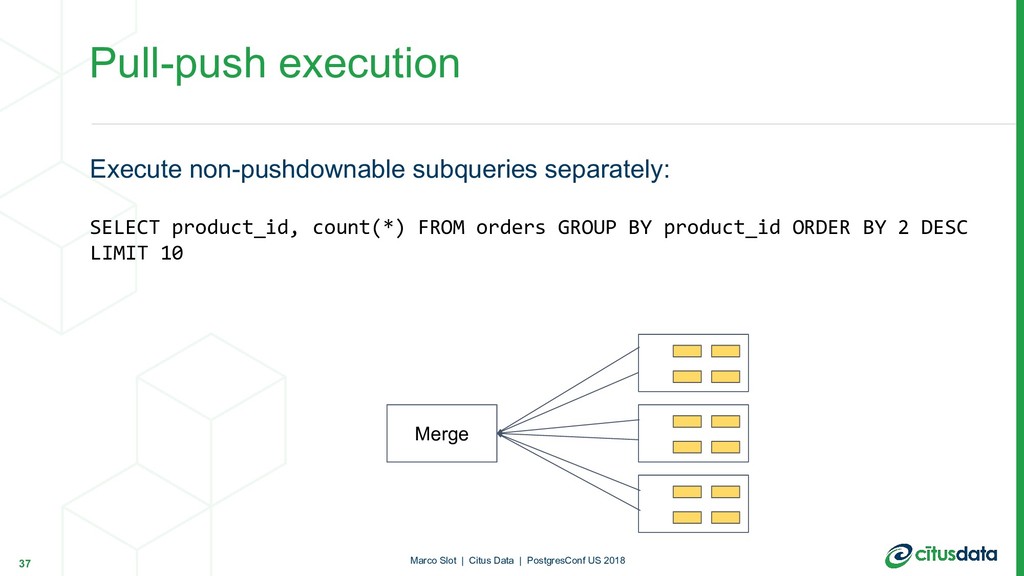{kind=link}
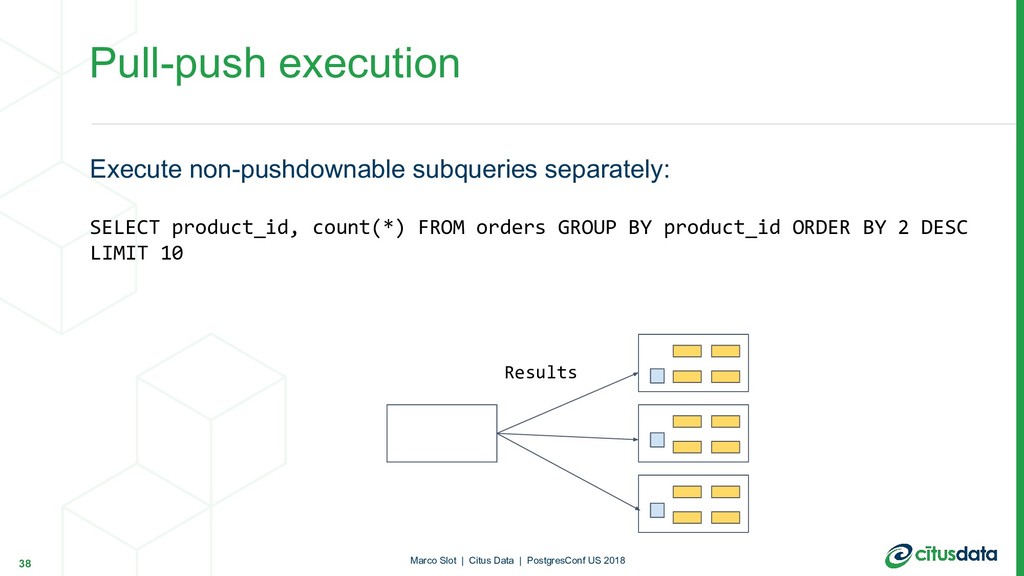{kind=link}
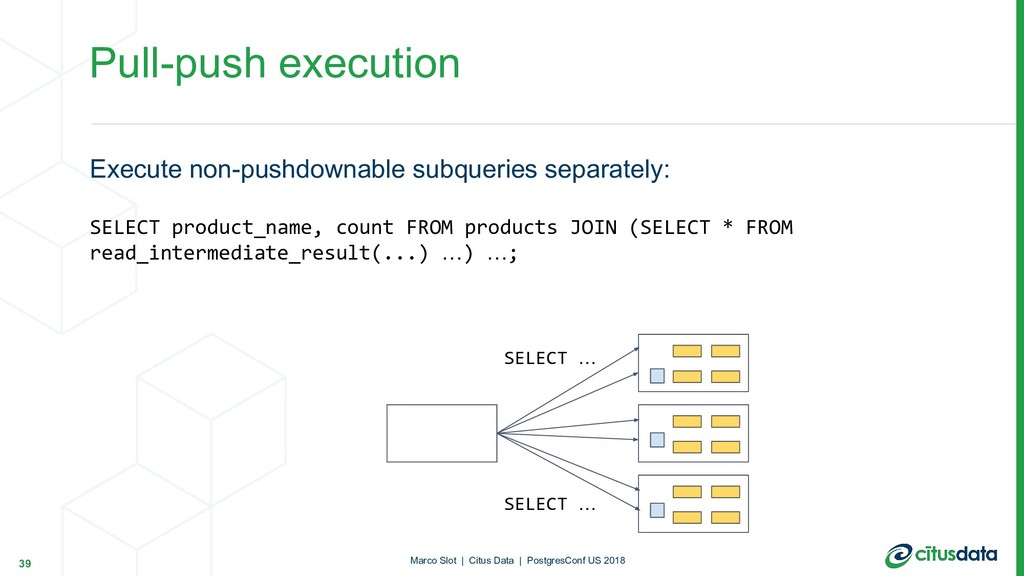{kind=link}
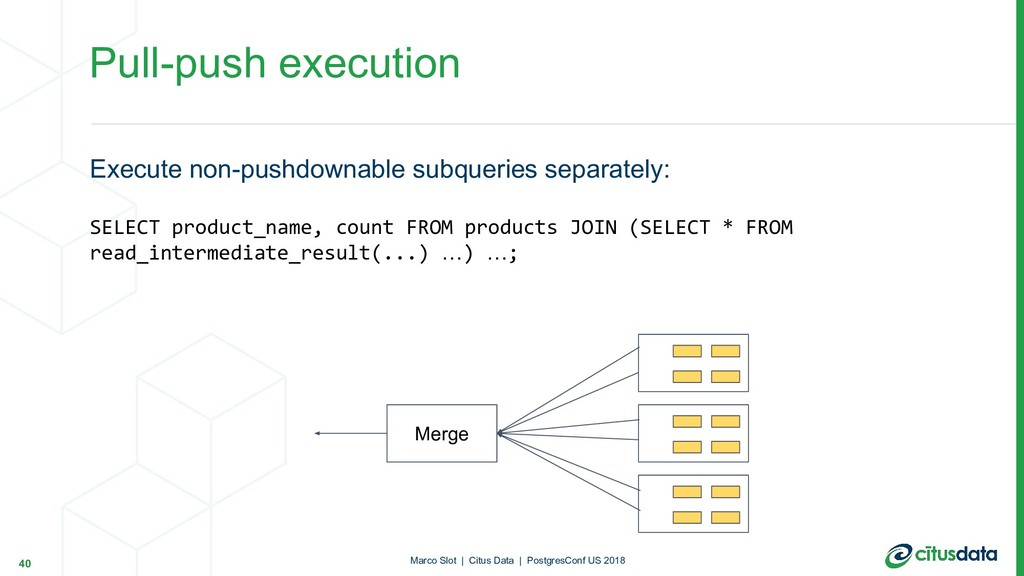{kind=link}
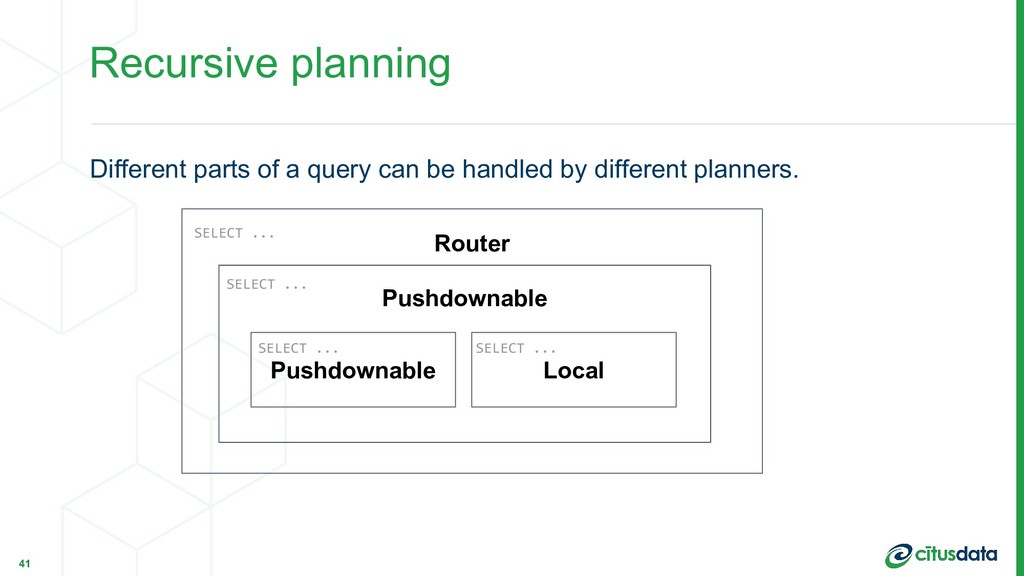{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
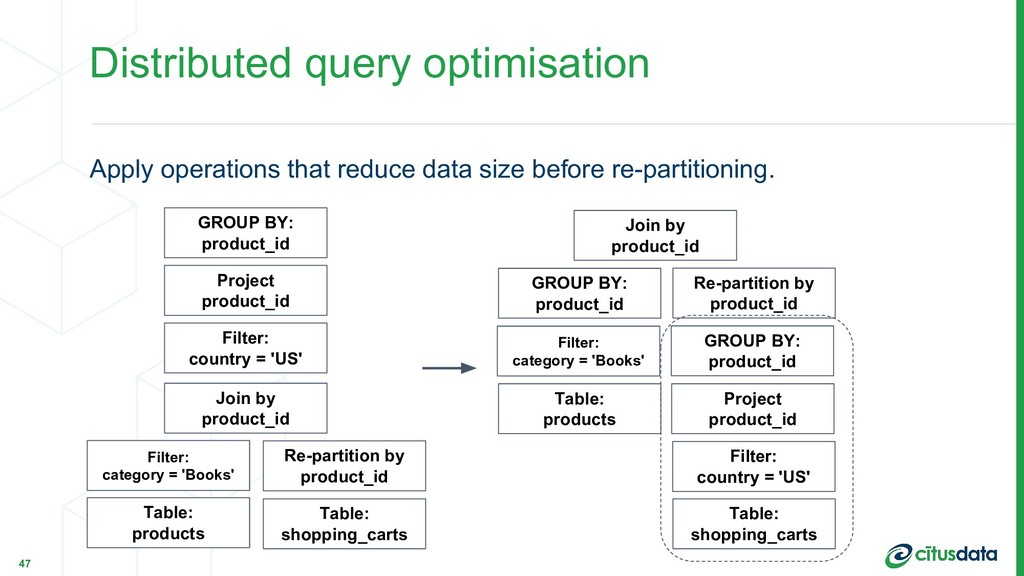{kind=link}
{kind=link}
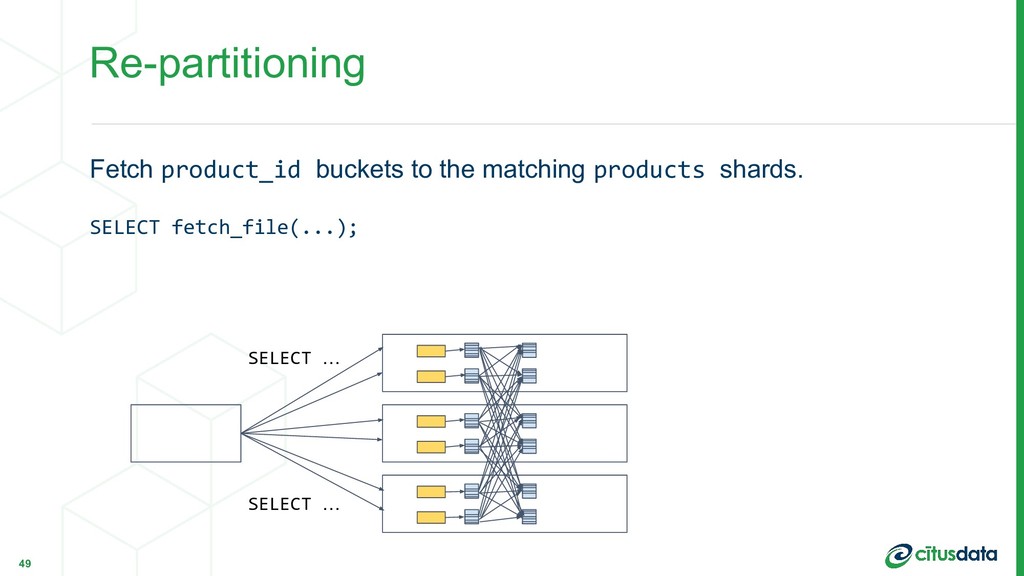{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[email protected] Thanks! 53](https://files.speakerdeck.com/presentations/0855373143cb46b4ae0c9db985b2665e/slide_52.jpg){kind=link}