Python is often used to maintain application backends. When the backend should implement user oriented workflows, it may rely on a RDBMS component to take care of the system's integrity.
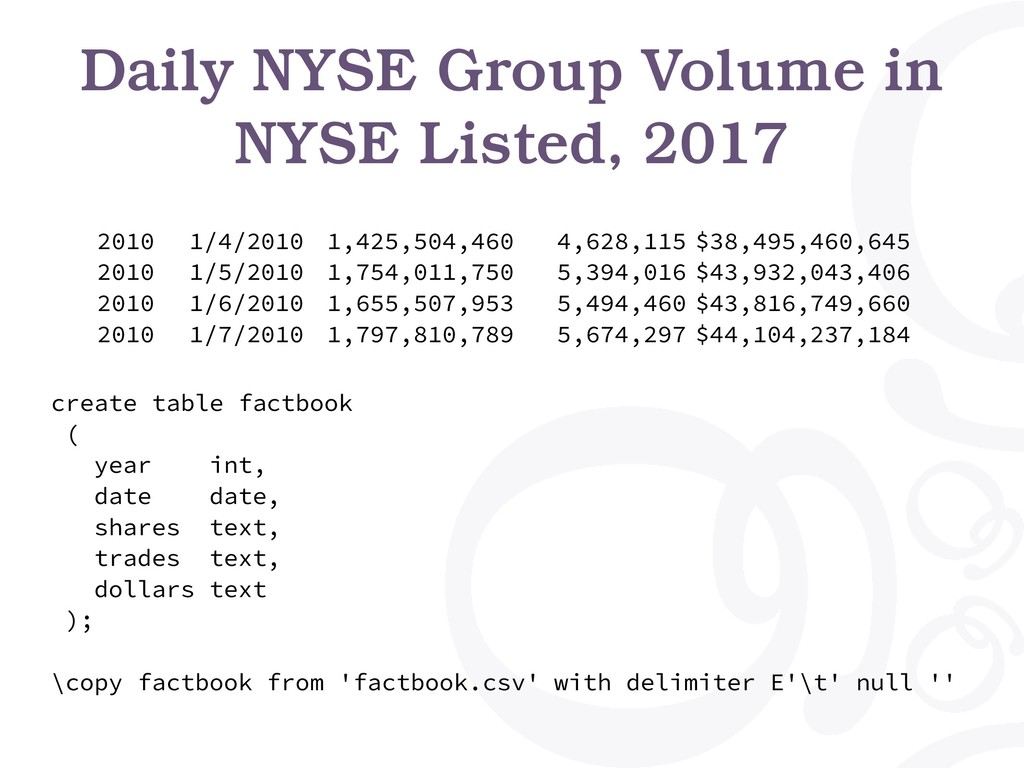
PostgreSQL is the world's most advanced open source relational database, and is very good at taking care of your system's integrity. PostgreSQL also comes with a ton of data processing power, and in many cases a simple enough SQL statement may replace hundreds of lines of code written in Python.
In this talk, we learn advanced SQL techniques and how to reason about which part of the backend code should be done in the database, and which parf of the backend code is so easier to write as a SQL query.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![-[ RECORD 1 ]---------------------------- date | 1995-12-26 host | Toronto](https://files.speakerdeck.com/presentations/bdbb5e4bb79b4a6e9db010964e5f9309/slide_57.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}