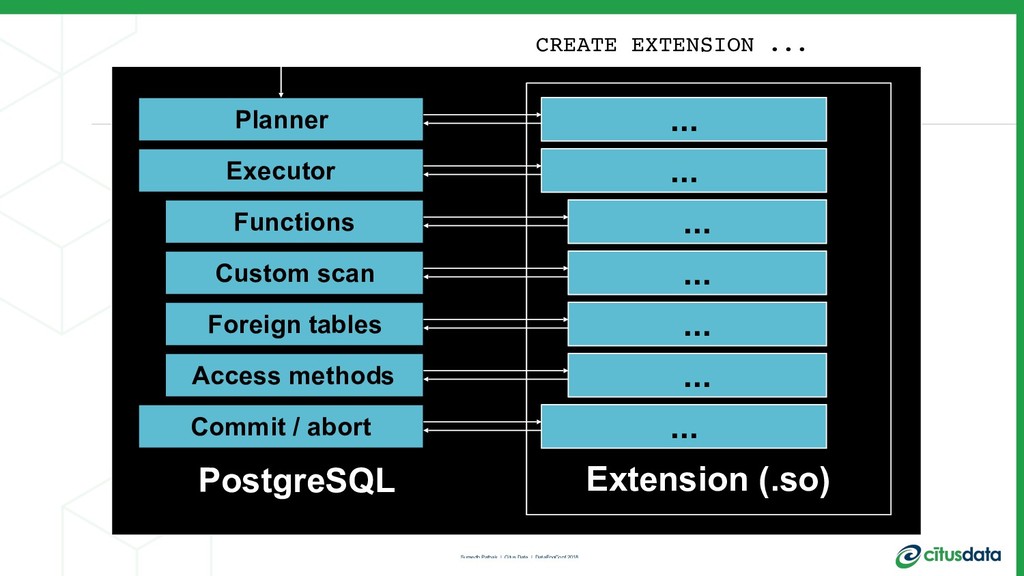
Years ago when working at Amazon on shopping cart infrastructure and the precursor to DynamoDB, my co-founder and I realized that while distributed key value stores were useful for a few use-cases, we missed many of the benefits of relational databases: transactions, joins, and the power of the lingua franca of RDBMS’s: SQL. So we challenged ourselves to modernize the traditional relational database, to take a robust open source relational database and transform it into a distributed database.
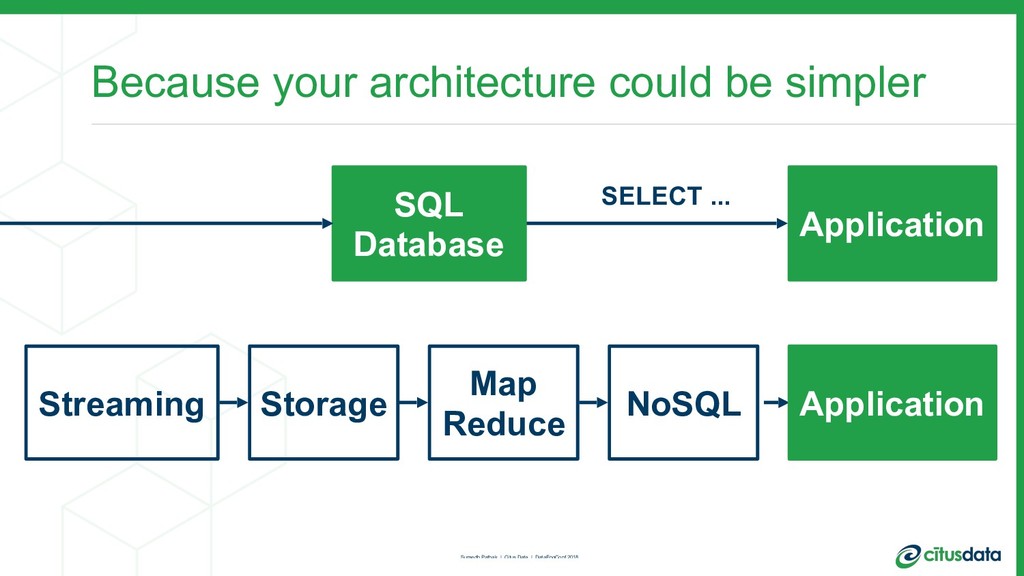
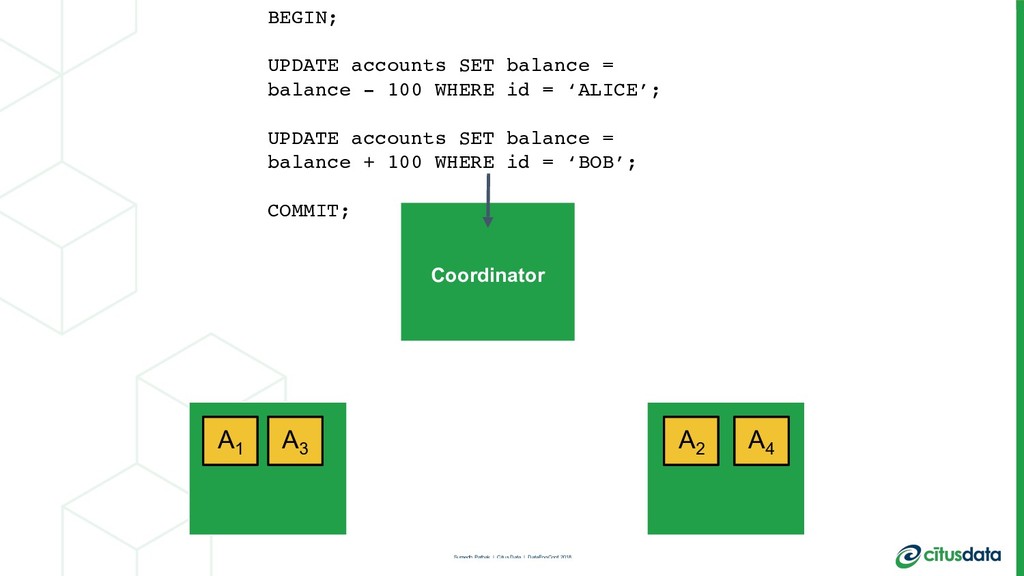
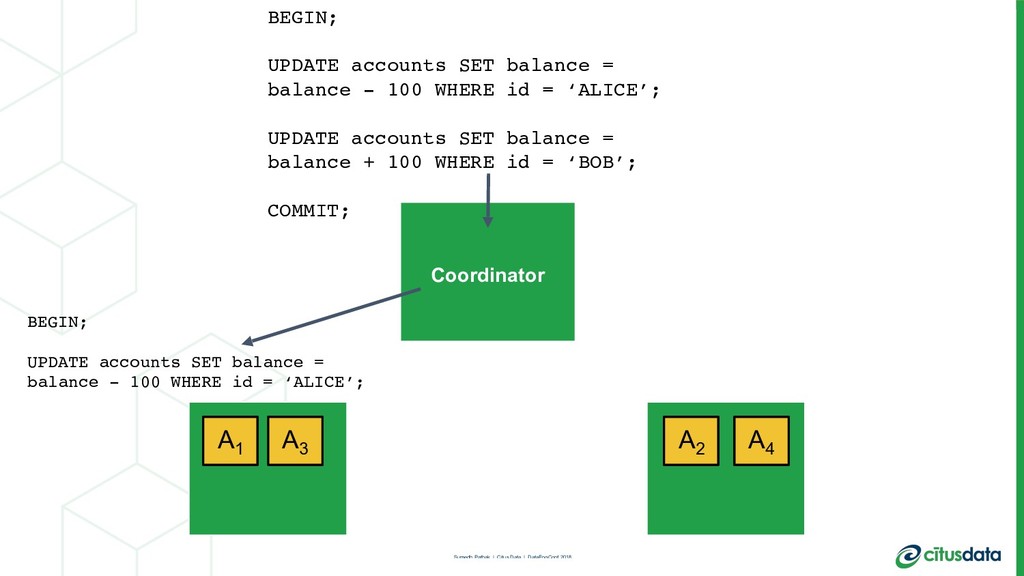
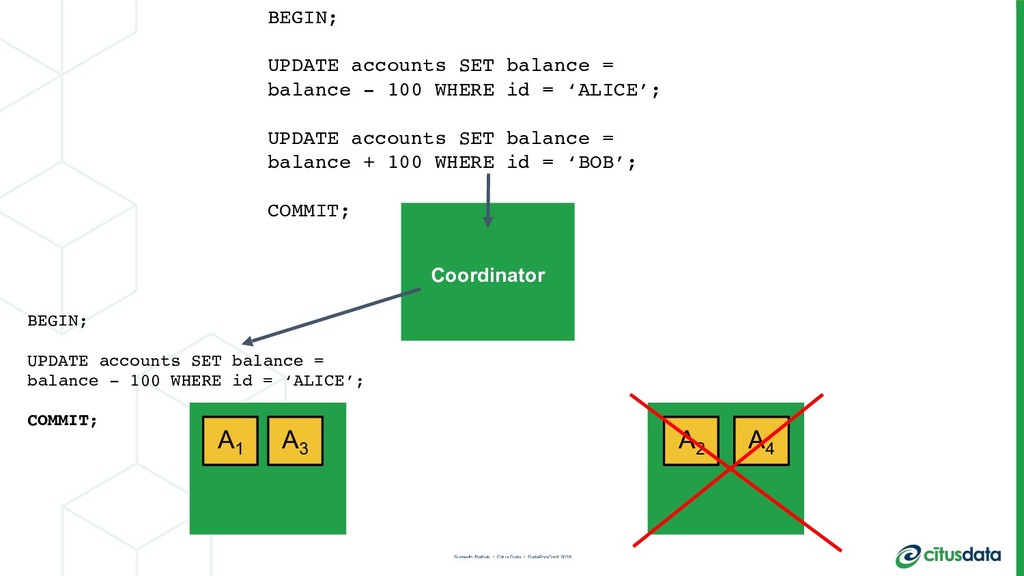
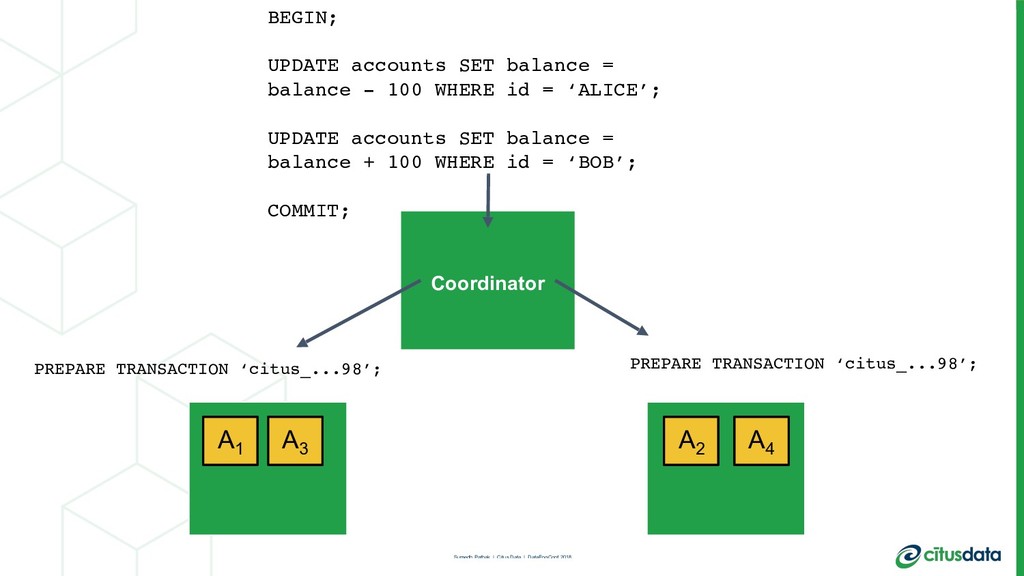
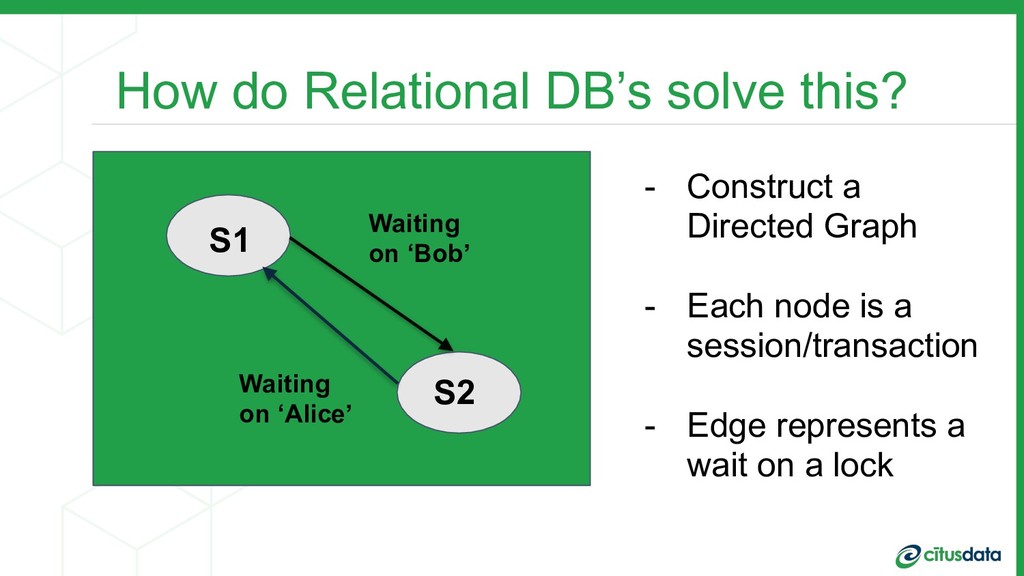
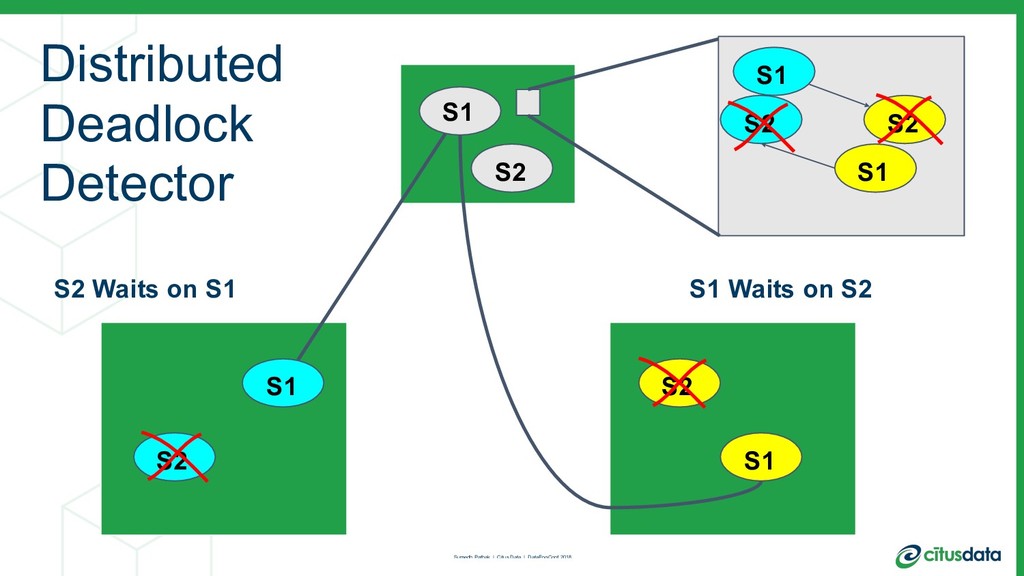
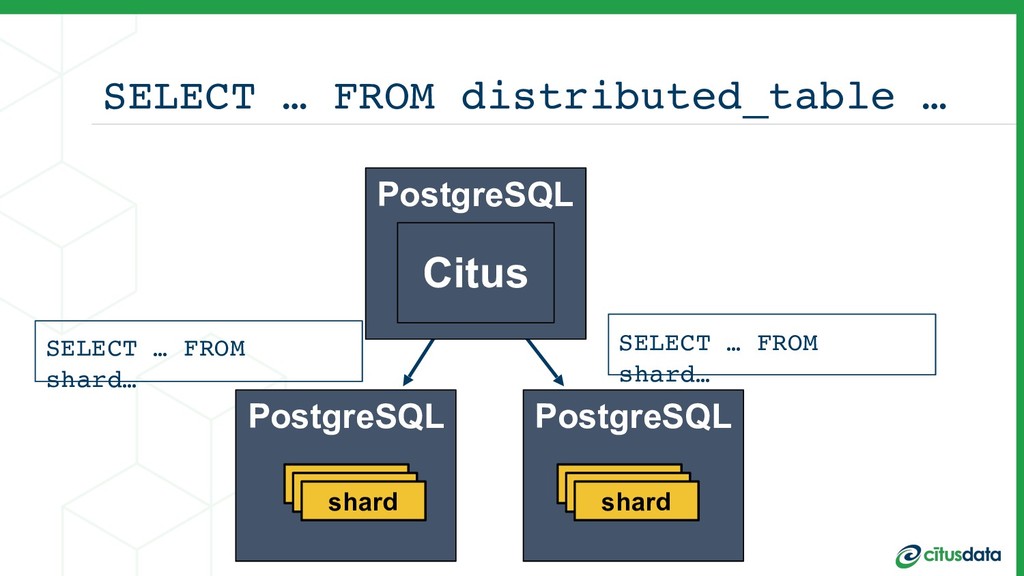
This talk is about my team’s journey to create a more modern relational database. I’ll talk about the distributed systems problems we had to solve in order to scale out the Postgres open source database, in order to achieve parallelism and a concomitant increase in performance. I'll describe the architecture of the distributed query planner; how we extend traditional relational algebra operators to plan distributed queries and scale reads. I’ll also describe distributed deadlock detection, and how that enabled us to scale out transactions spanning multiple machines.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! Sumedh Pathak [email protected] @moss_toss | @citusdata | citusdata.com](https://files.speakerdeck.com/presentations/911fe57233ab4b648340a62e4792d393/slide_67.jpg){kind=link}