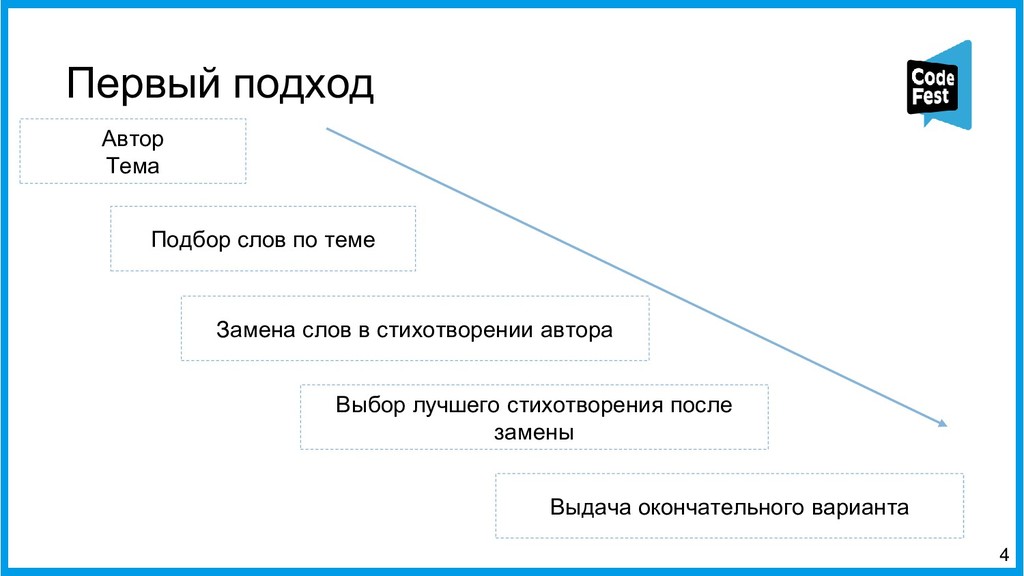
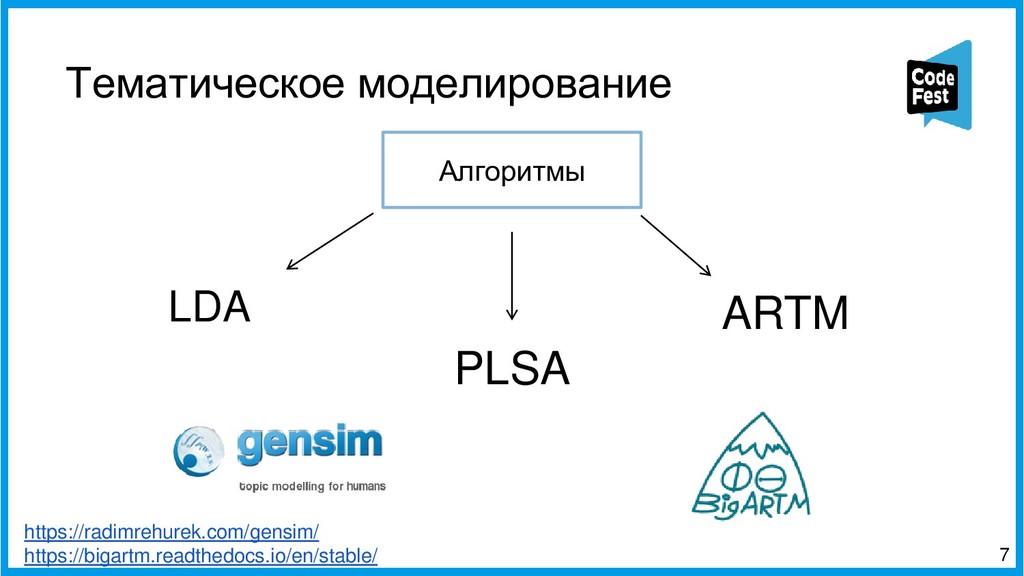
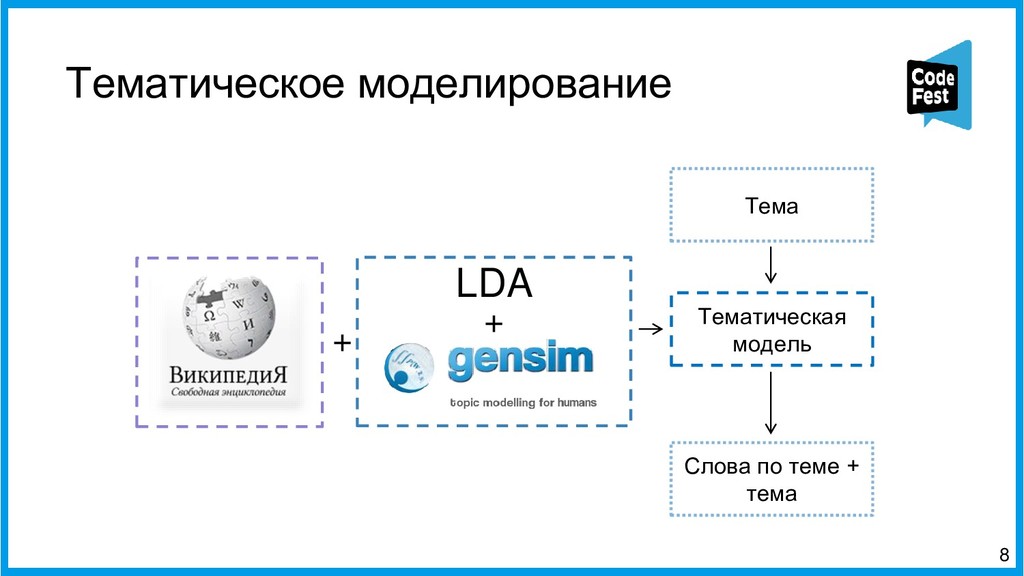
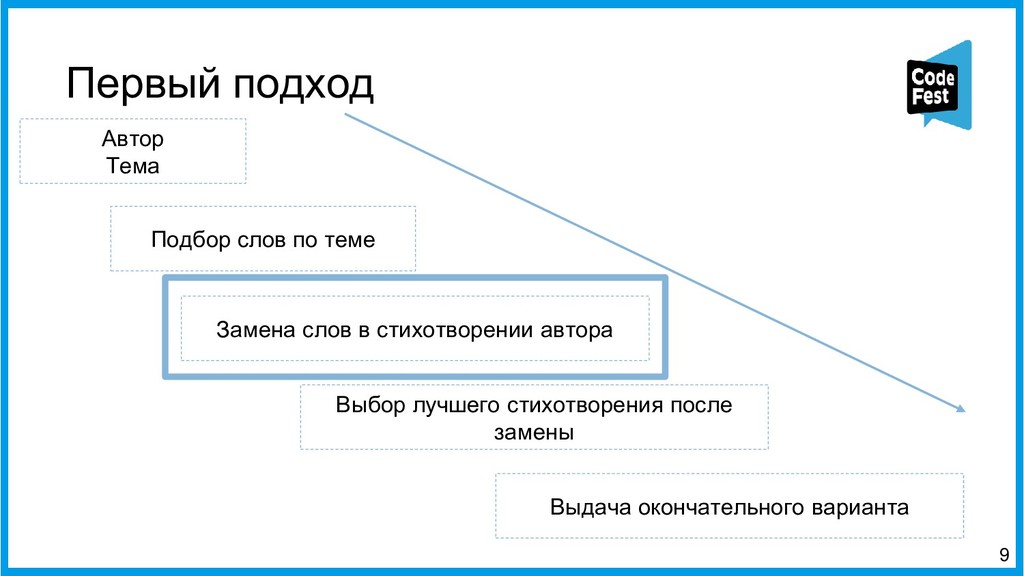
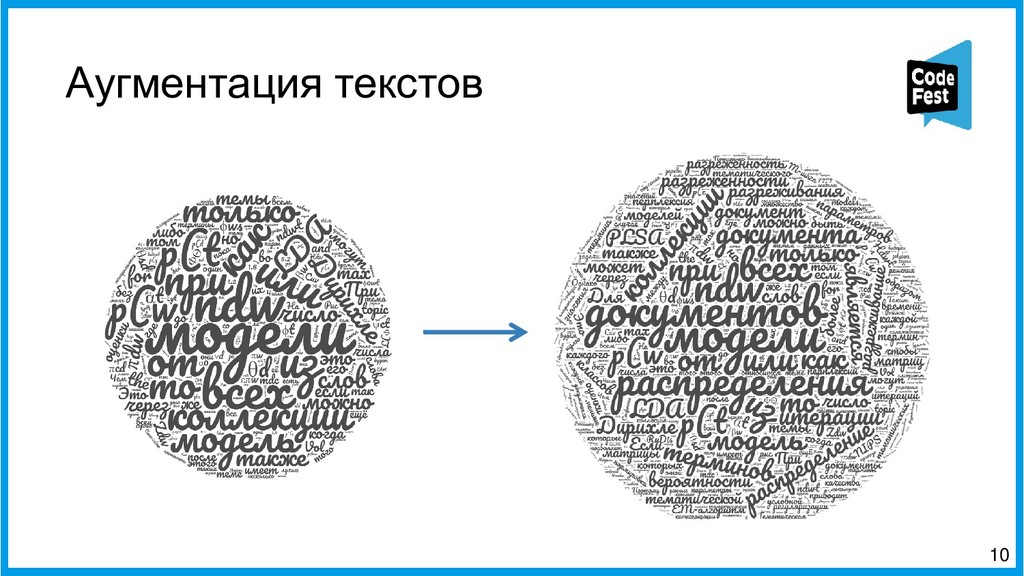
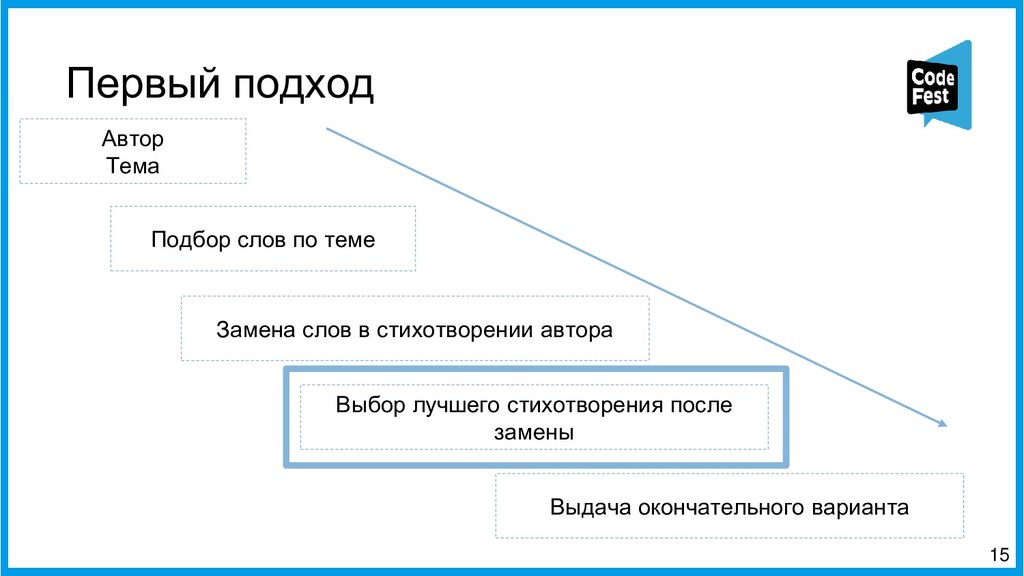
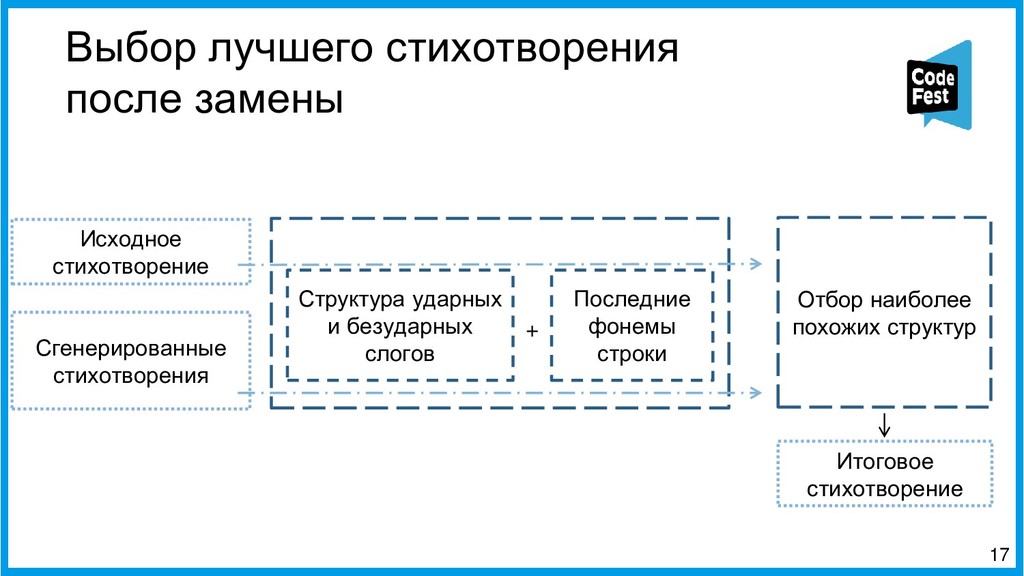
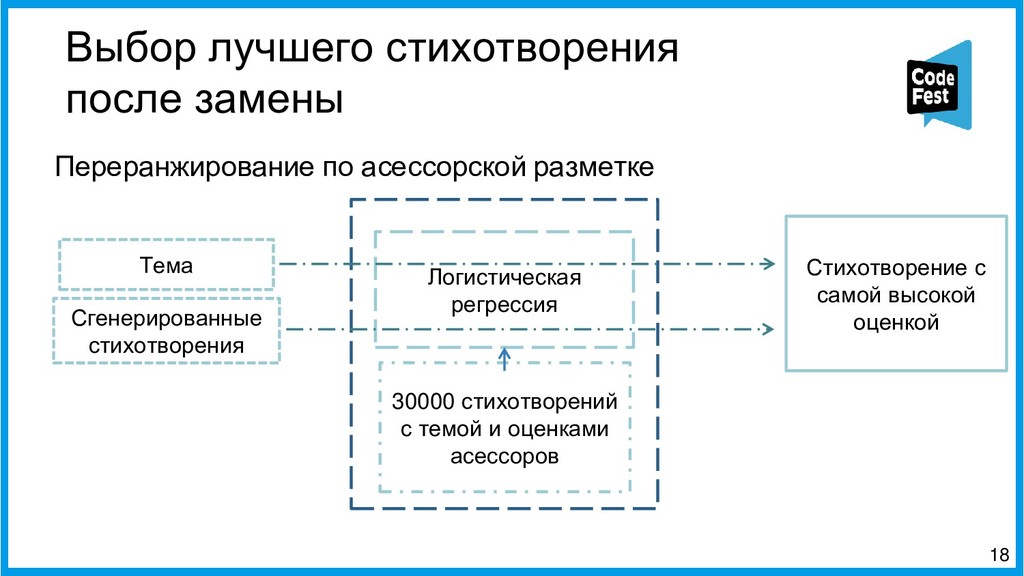
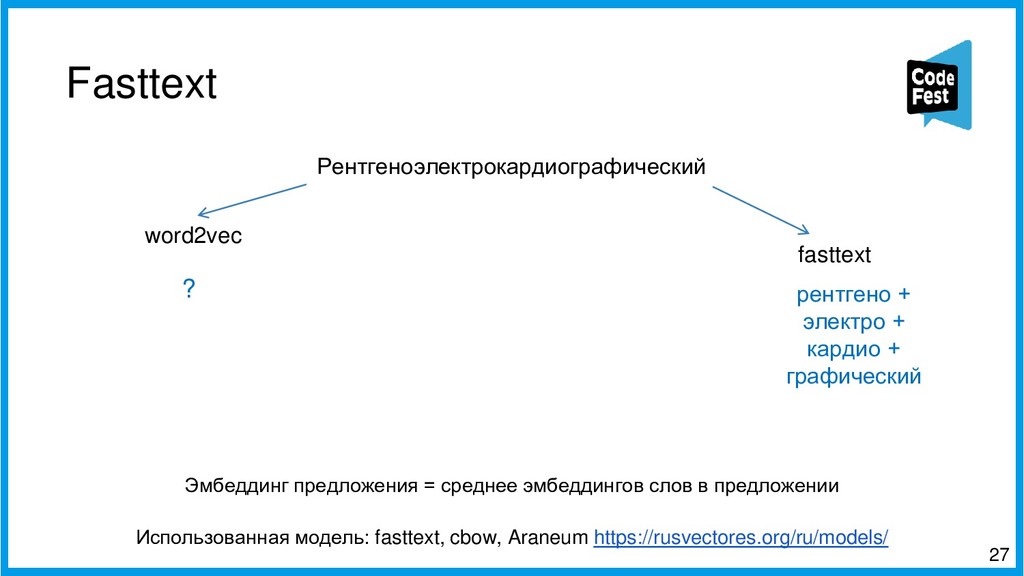
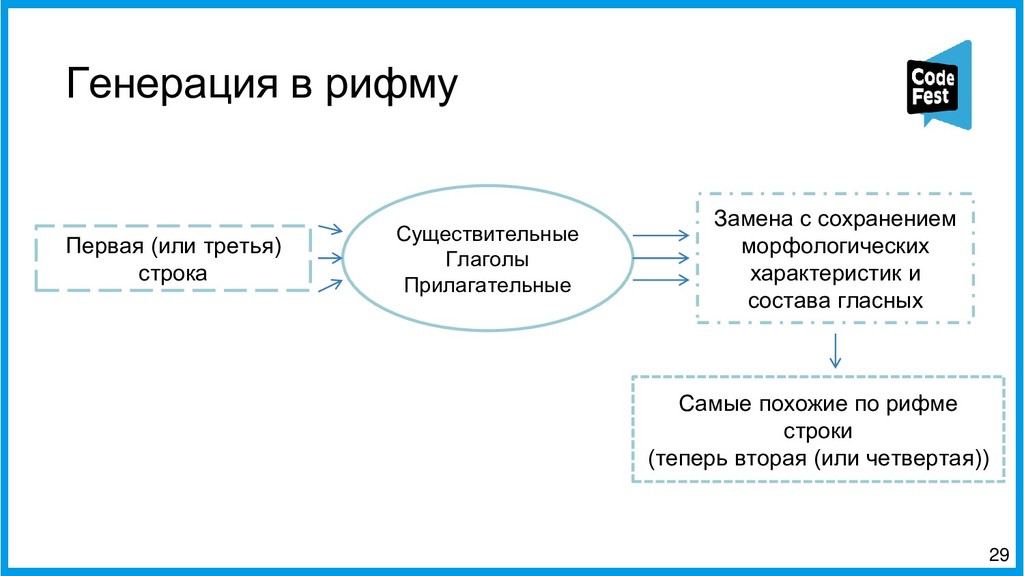
Доклад посвящён описанию двух алгоритмов работы автопоэта для русского языка, изначально создававшегося для соревнования, а потом ставшего чем-то большим. Первая часть рассказа будет о первом алгоритме автопоэта, который осуществлял поиск ключевых слов с помощью тематической модели LDA, обученной на корпусе википедии, подставлял их всеми возможными способами в рамках морфологических характеристик слов в исходные стихотворения автора и затем ранжировал по приближенности ритмы и рифмы к оригинальному стихотворению автора.
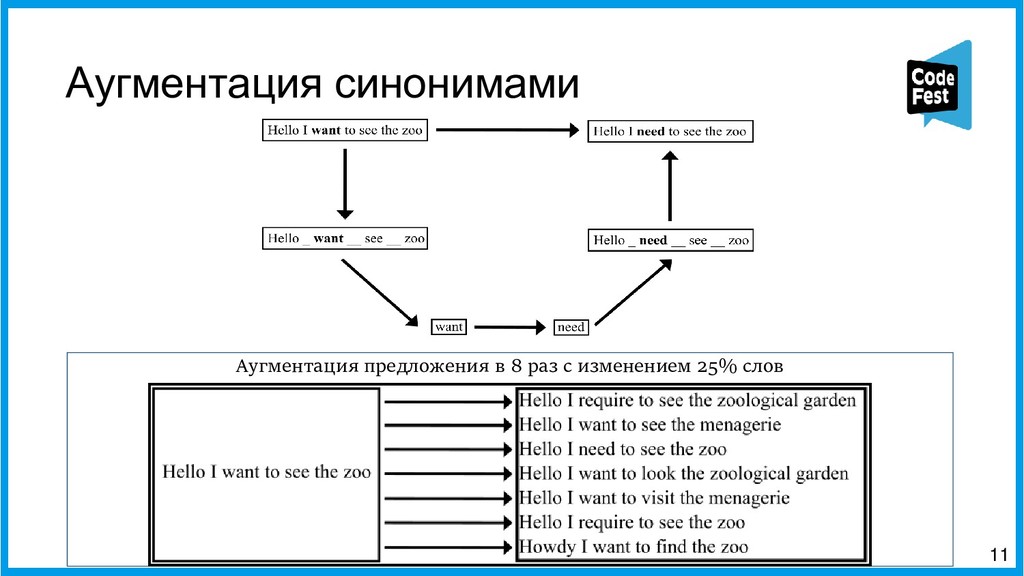
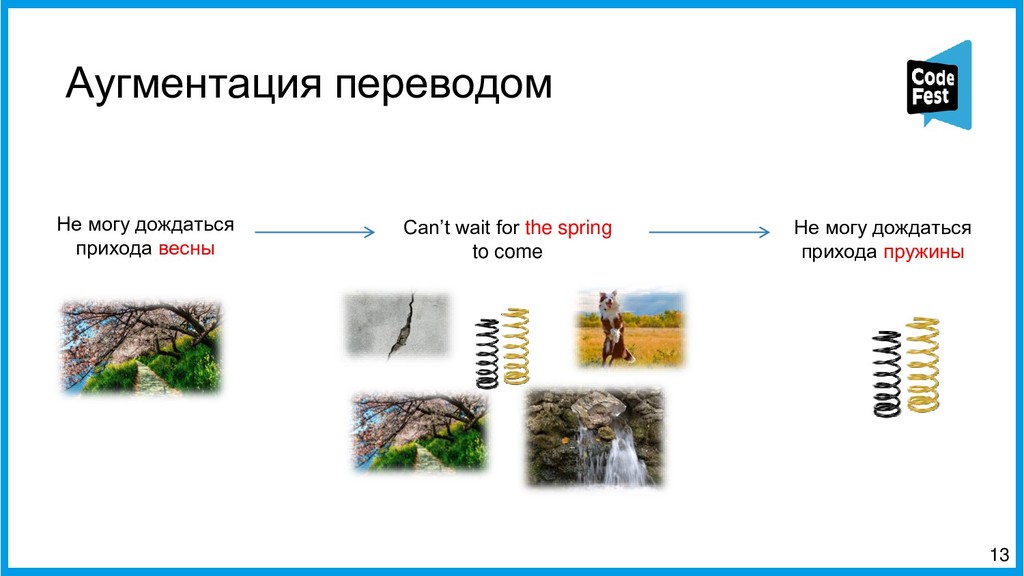
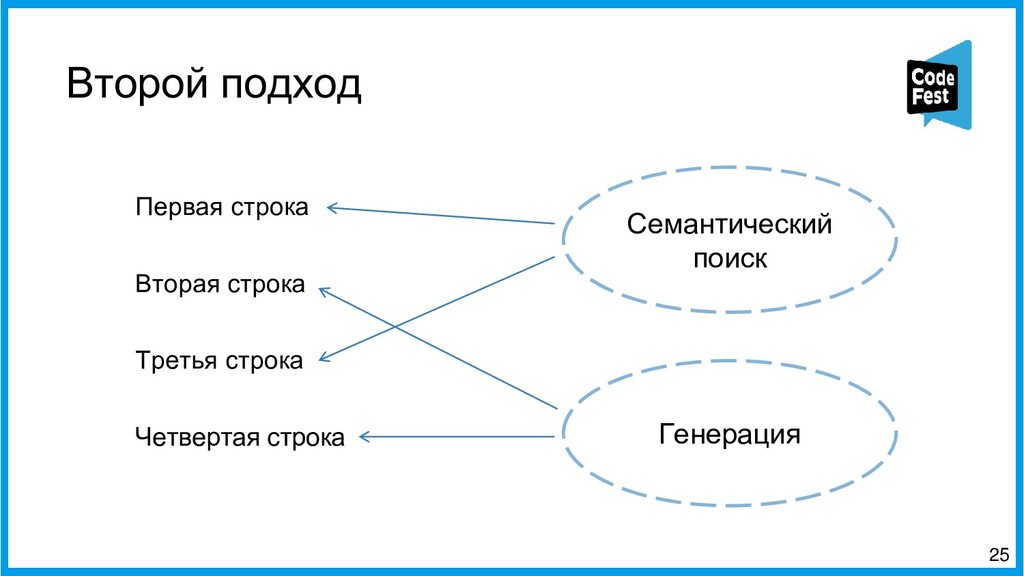
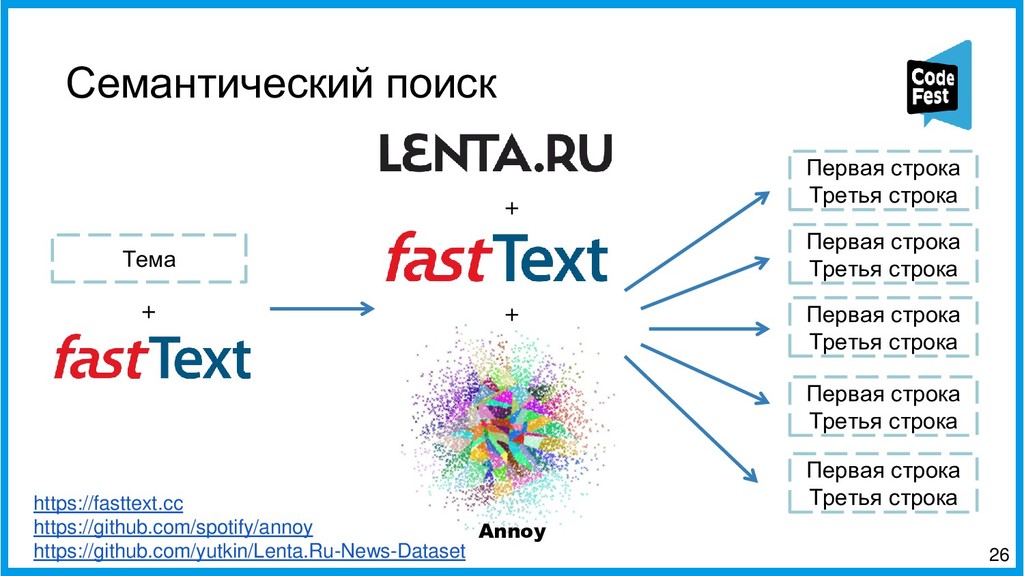
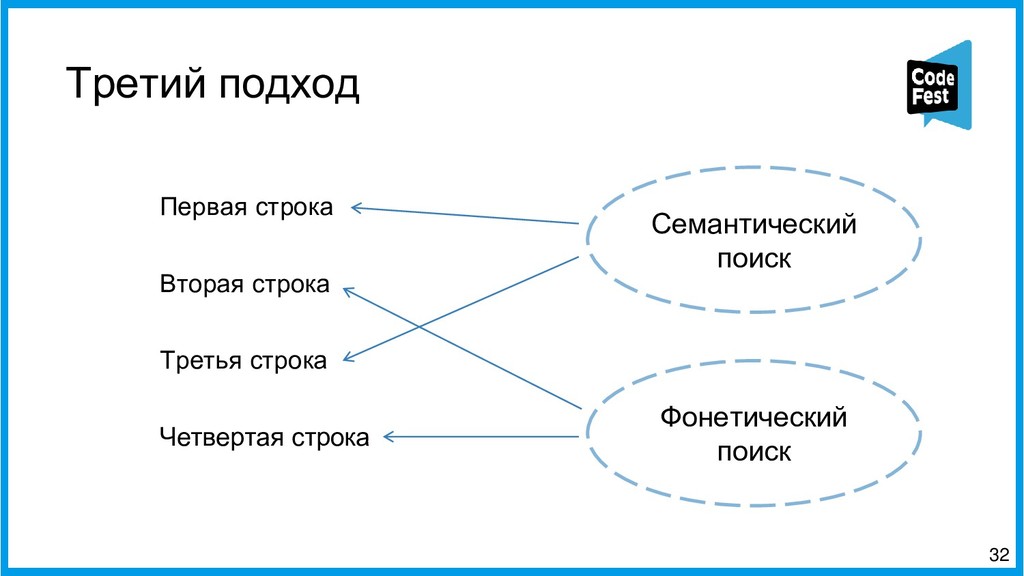
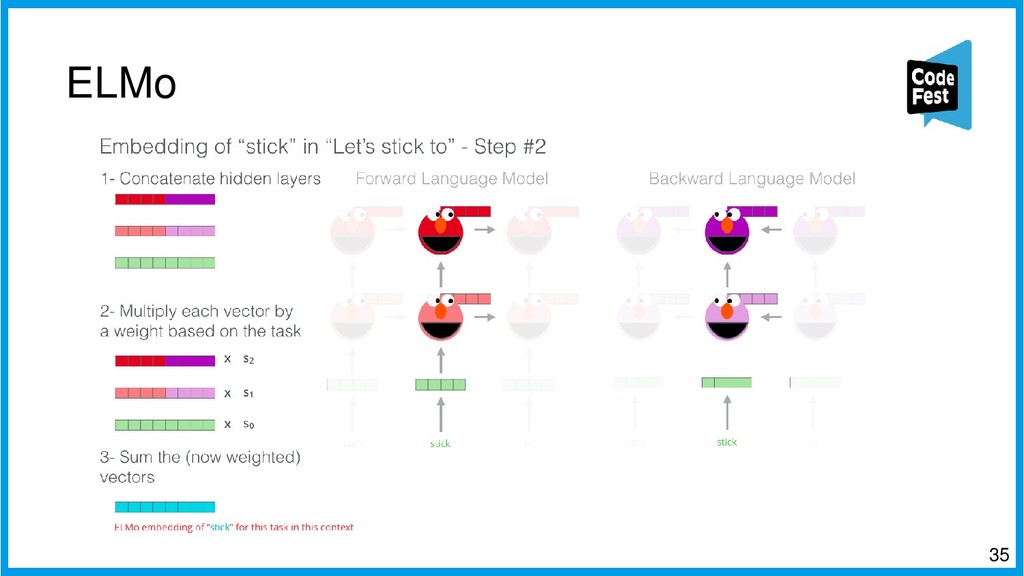
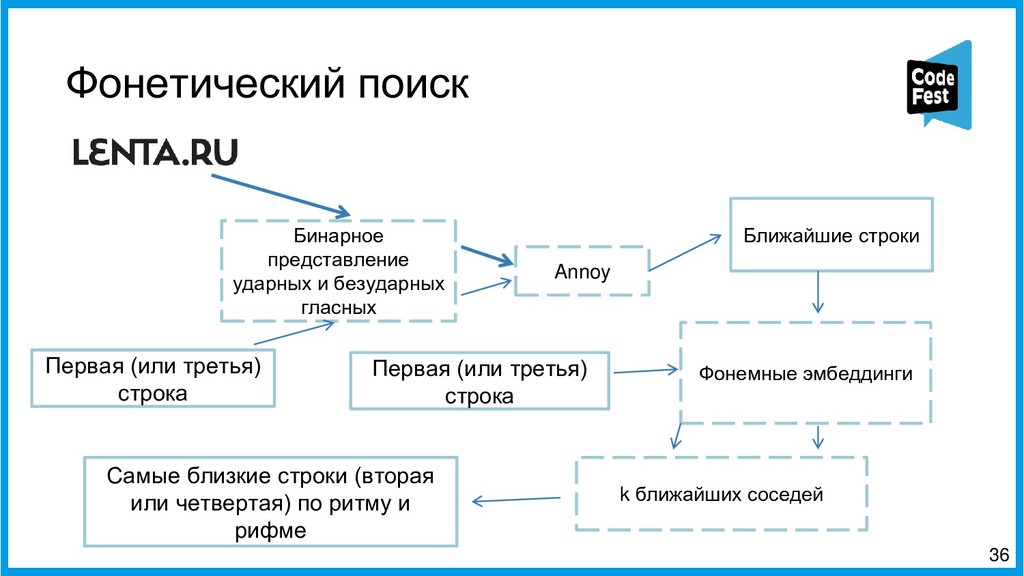
Вторая часть представит новый подход к созданию автопоэта, где это задание представляется как задача информационного поиска. Эта версия сначала находит в новостном корпусе все семантически близкие строчки к строкам исходного стихотворения автора с помощью эмбеддингов eLMO и метода k-ближайших соседей и из двух наиболее близких строит первую и третью строки будущего стихотворения, затем в корпусе идёт поиск наиболее фонетически близких строчек к двум уже полученным, и две самые близкие образуют вторую и третью строки. Таких вариантов генерируется несколько, и затем, с помощью логистической регрессии, осуществляется ранжирование получившихся стихотворений, и самое похожее на заданную тему выдаётся как итоговый вариант.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Семантический поиск [2] 33 Annoy Тема + Первая строка Третья](https://files.speakerdeck.com/presentations/e2f1a39ae21d4864aa4667284d349a87/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Анна Мосолова Аналитик DataMonsters Вопросы? [email protected] @anyabelk](https://files.speakerdeck.com/presentations/e2f1a39ae21d4864aa4667284d349a87/slide_41.jpg){kind=link}