CodeFest 2019. Леонид Кулигин (Google) — Тренировка моделей машинного обучения на больших объемах данных
Объём доступных данных, как и сложность моделей машинного обучения, растёт экспоненциально. Мы поговорим про то, как работает распределённое обучение с TensorFlow, как устроен процессинг данных и какие средства доступны для профайлинга тренировки.
2017 - … Google Cloud, PSO, ML engineer ! 2016-2017 Scout GmbH, Senior Software Engineer ! 2015-2016 HH.RU, Senior Product Manager (Search/ML) ! 2013-2015 Yandex, Team Lead (Data production for Local search) https://www.linkedin.com/in/leonid-kuligin-53569544/
in the largest AI training runs has been increasing exponentially… Since 2012, this metric has grown by more than 300’000X” D. Amodei & D. Hernandez https://blog.openai.com/ai-and-compute/
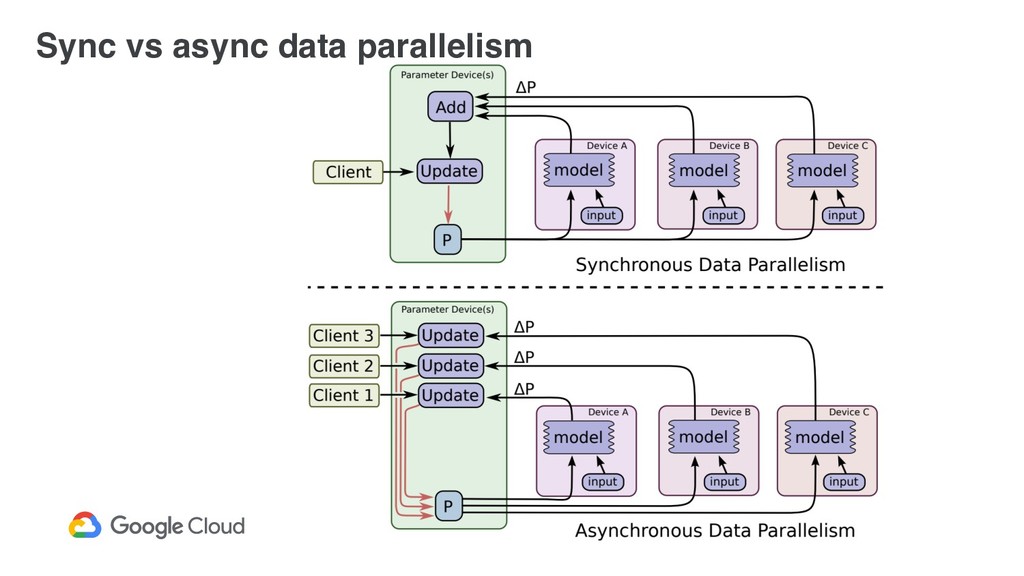
Every worker executes a forward pass on a mini-batch. 3. PS aggregate the results. 4. Every worker executes a backward pass on its mini-batch and send updates to PS.
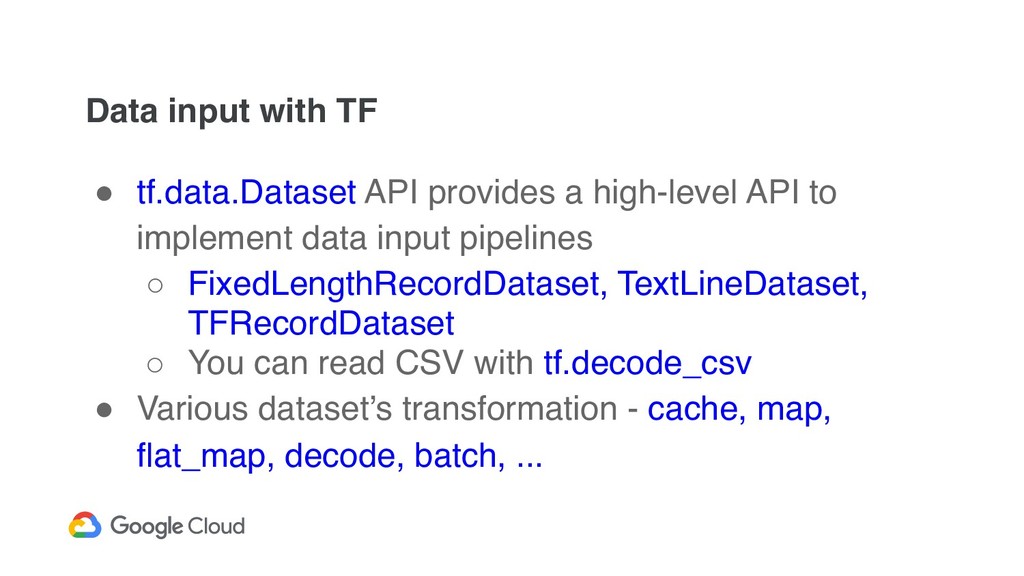
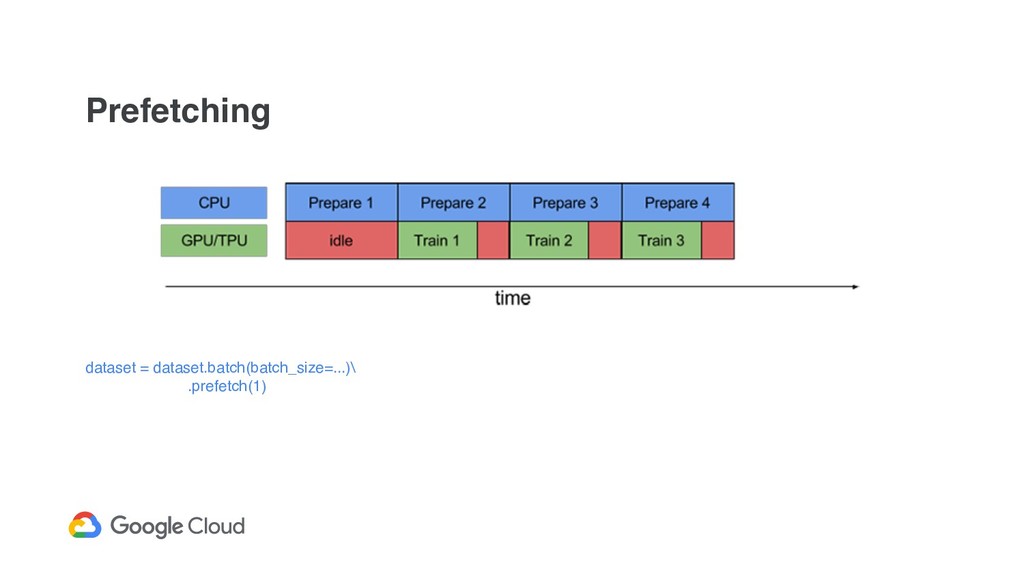
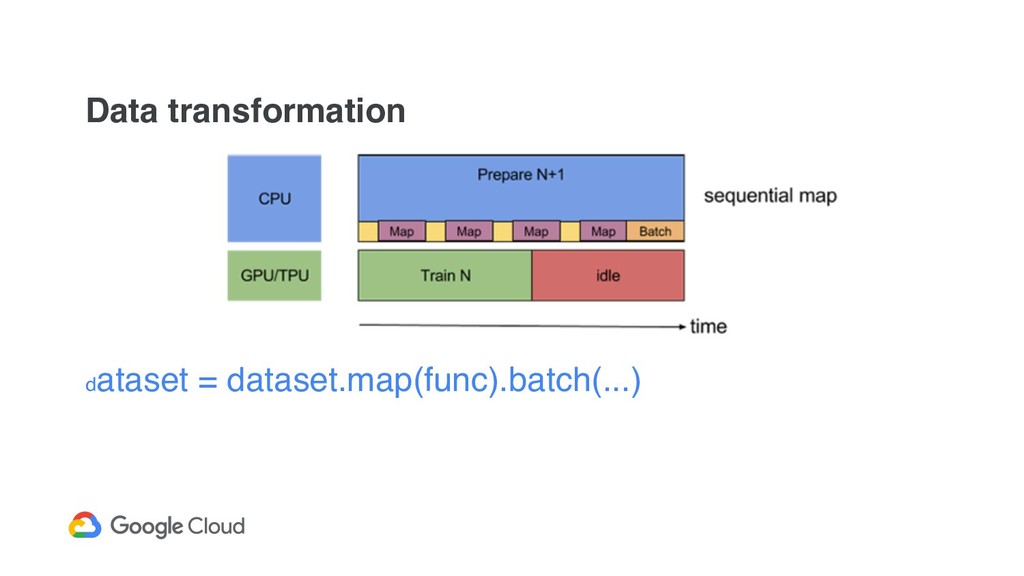
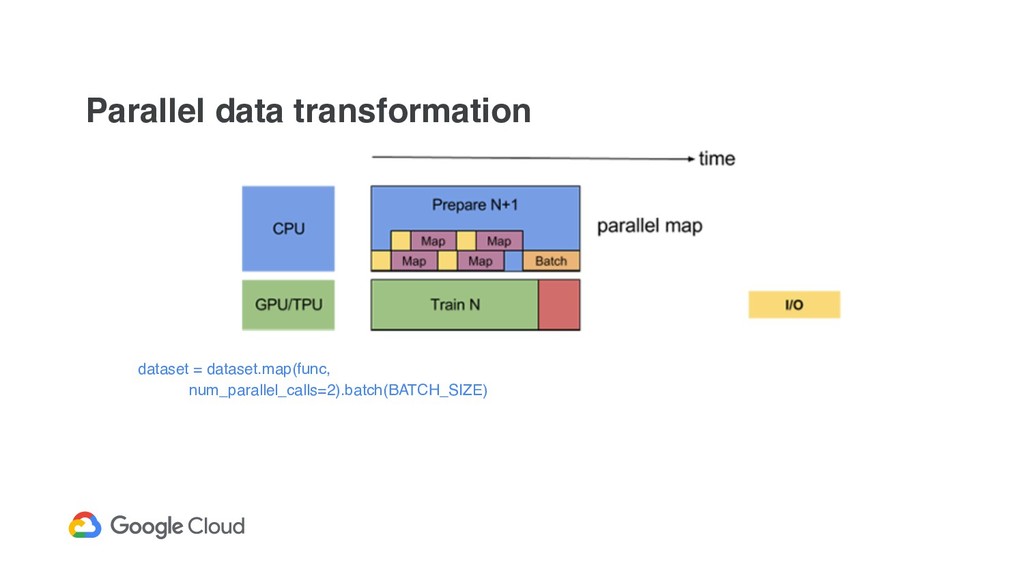
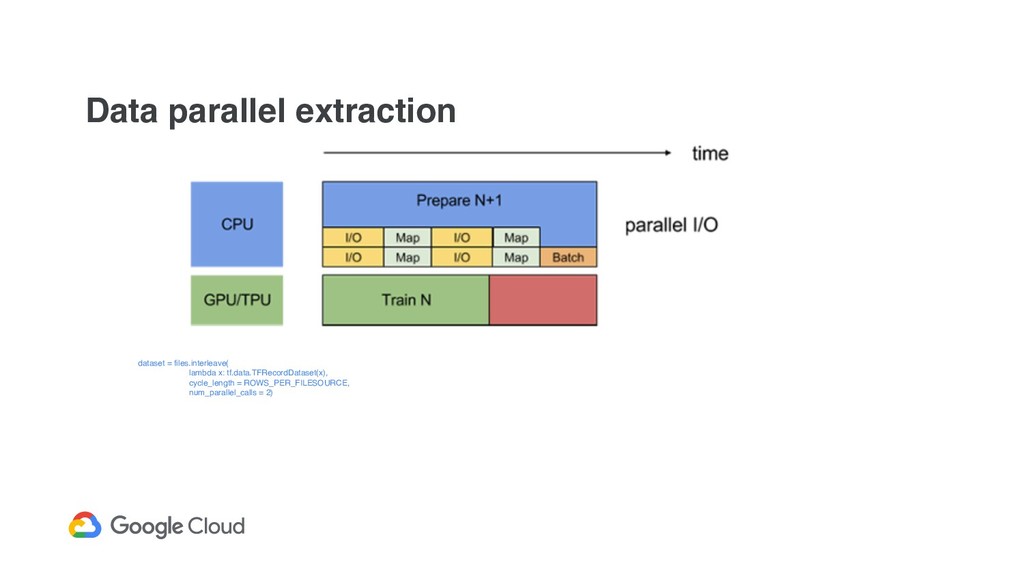
API to implement data input pipelines ◦ FixedLengthRecordDataset, TextLineDataset, TFRecordDataset ◦ You can read CSV with tf.decode_csv ! Various dataset’s transformation - cache, map, flat_map, decode, batch, ...
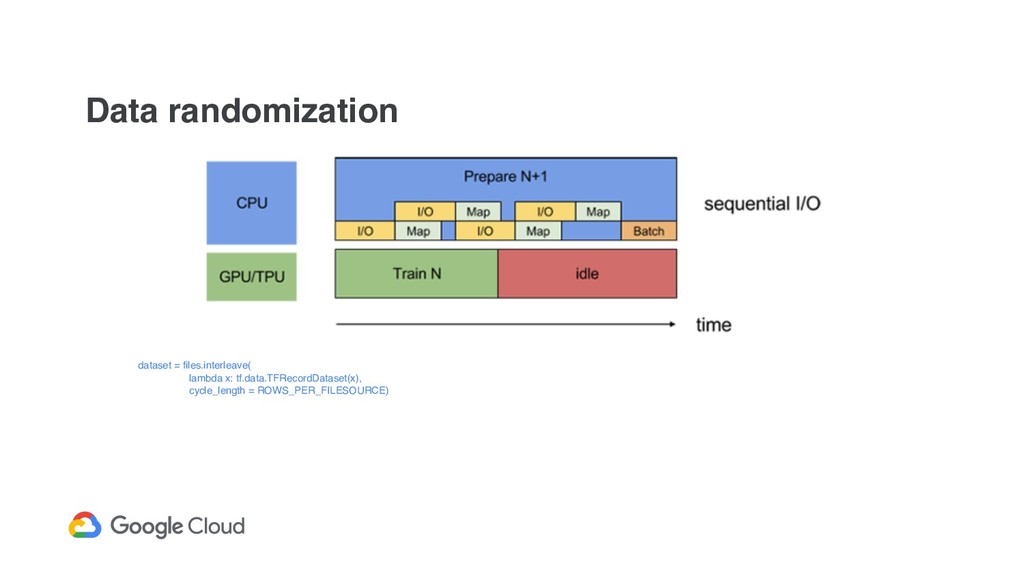
within a single batch you use data from ~N different files • shuffle the in-memory portion of loaded data on every worker • interleave on every worker means to consume data from different files within a single minibatch
a separate json file ! You can manually inspect its visualization with chrome://tracing • Unlocked Memory/Compute tabs at the Graph visualization with Tensorboard
its dependencies • Tensor tab ◦ Creation/deallocation timestamps ◦ Shapes/memory/... as at the snapshot timestamp • Allocators tab ◦ Allocated memory over time
execution time/memory/… consuming ops • Profile device placement and your model architecture (tensor shapes, memory allocated, etc.) ◦ Attribution to python code ◦ Filtering by regexp • Explore other options in the documentation
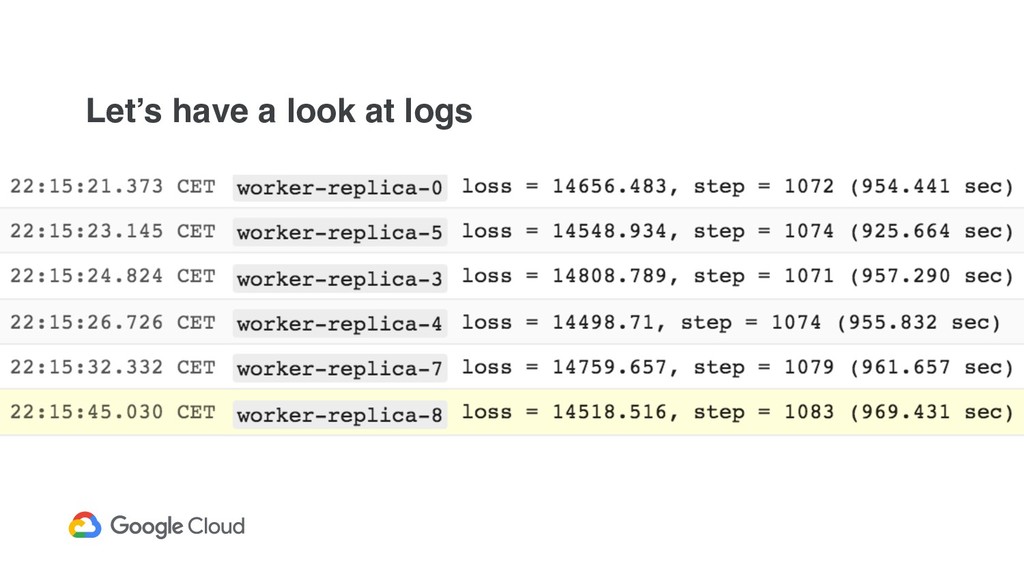
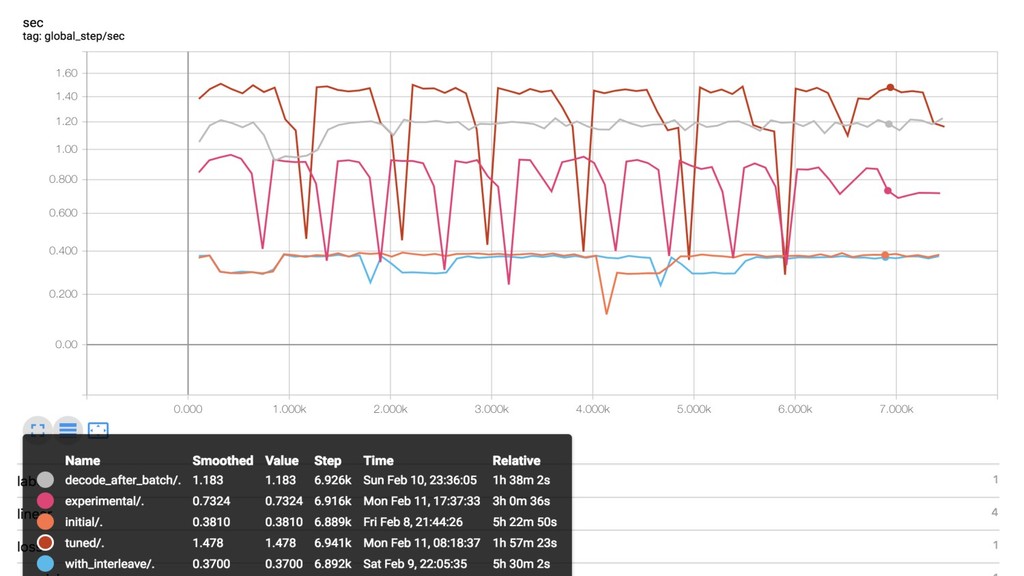
when training in a distributed mode (adjust batch_size and data sharding if needed) ! Profile your models during training in order to optimize for bottlenecks (e.g,. the input data pipeline)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Using with high-level API with tf.contrib.tfprof.ProfileContext( ''.join([output_dir, 'profiler']), trace_steps=range(1050,1100), dump_steps=[1100])](https://files.speakerdeck.com/presentations/91a03c7ab98b4d548585f986f6ebdc9a/slide_39.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}