https://2017.codefest.ru/lecture/1188
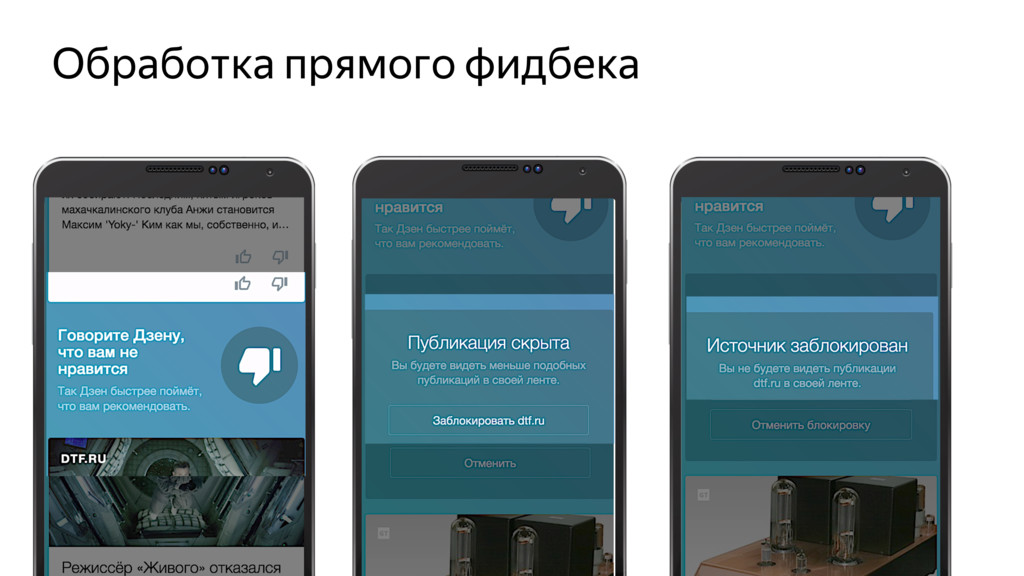
В последние годы big data, машинное обучение и персонализация продукта проникают во всё большее и большее число областей. Персонализированная доставка контента потребителю стала одной из важнейших задач для практически любого производителя/поставщика этого самого контента.
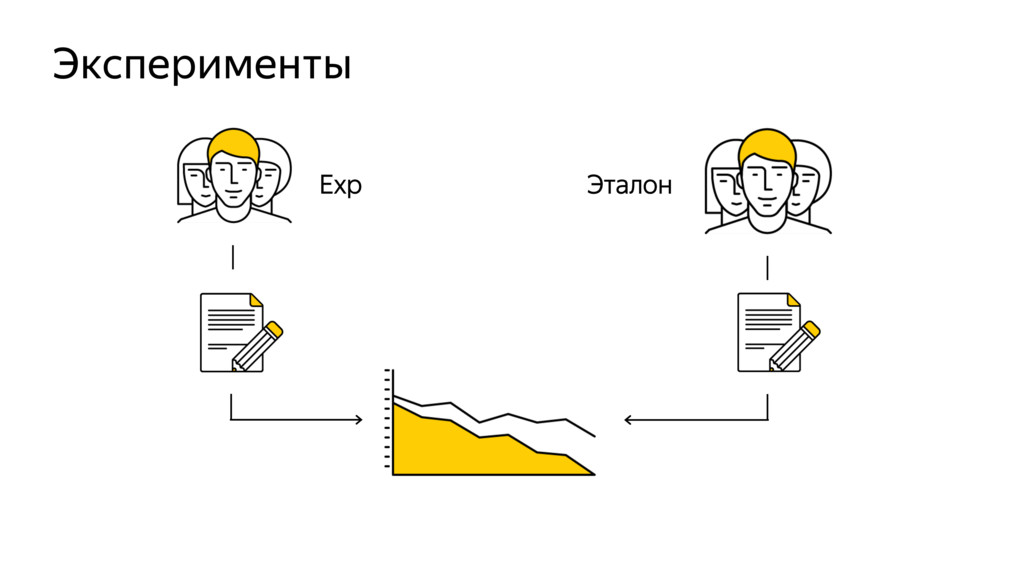
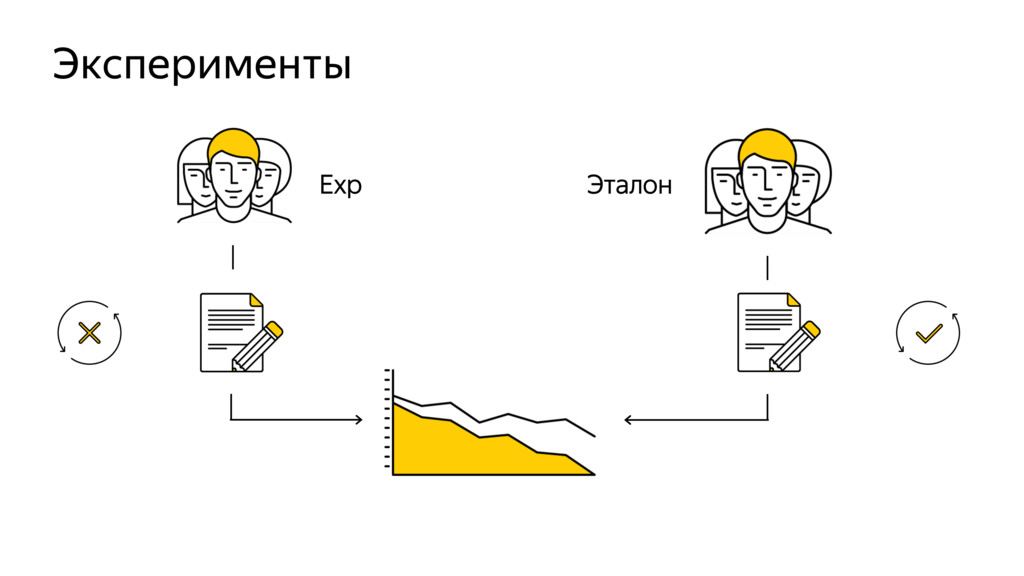
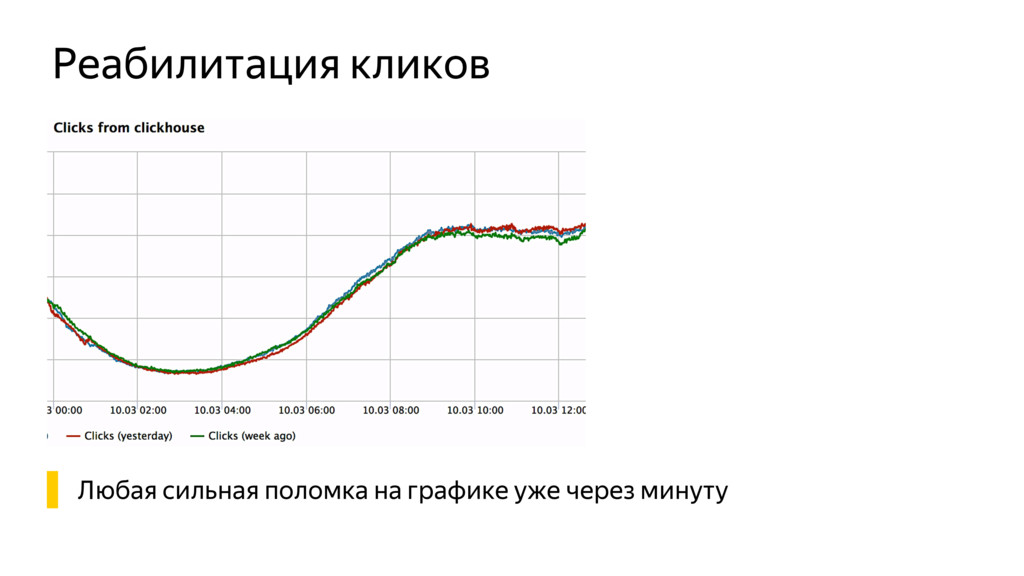
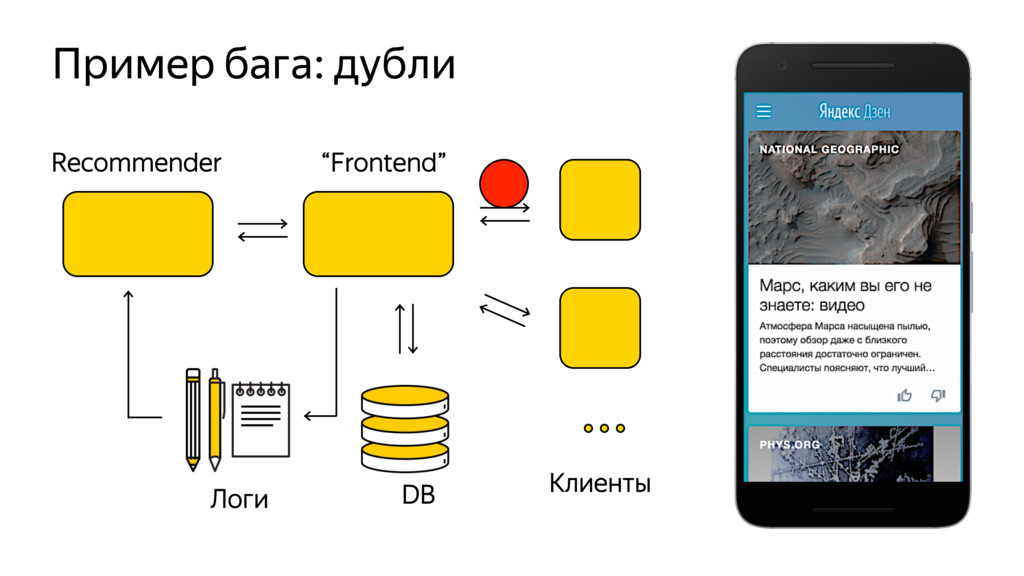
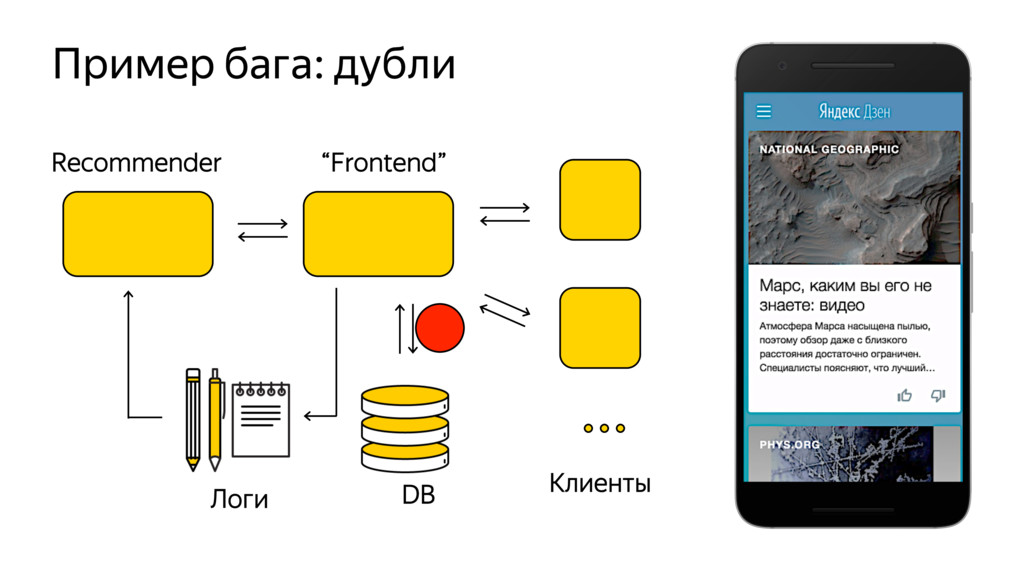
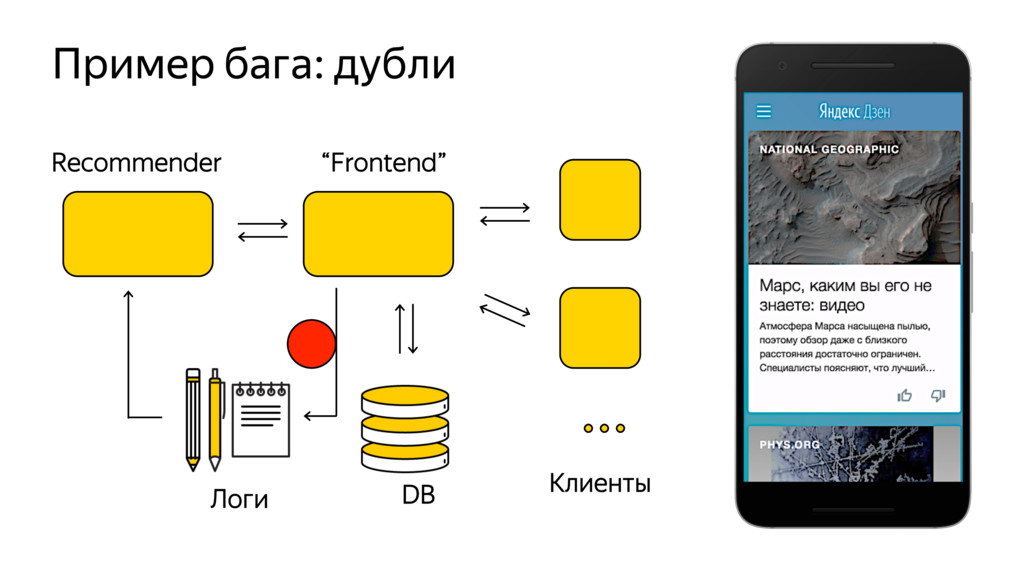
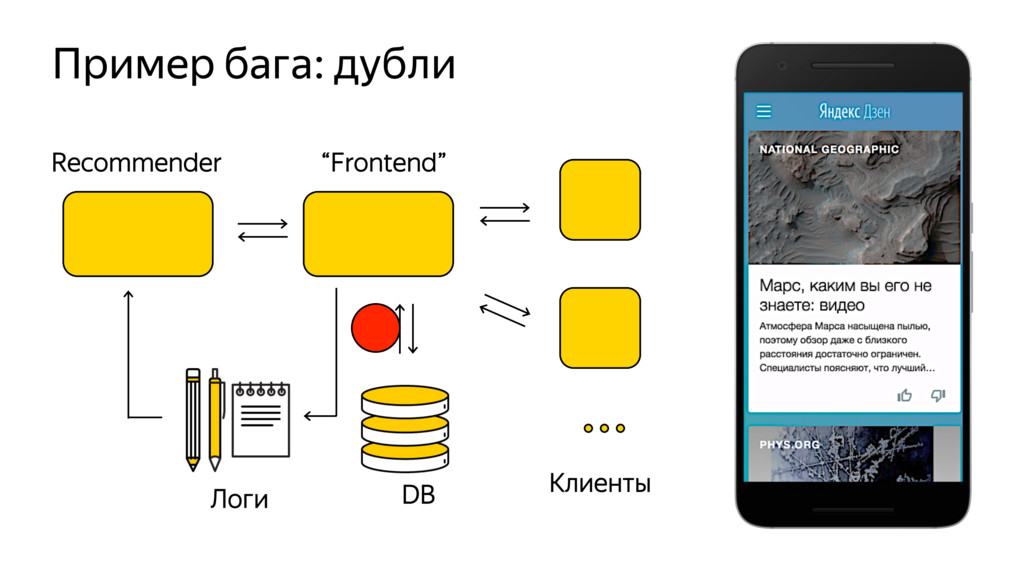
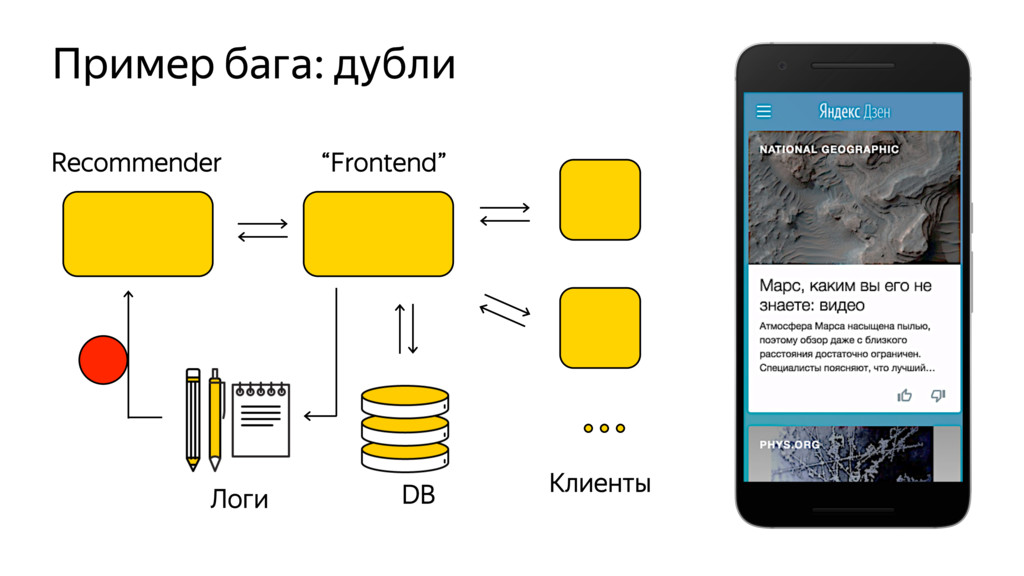
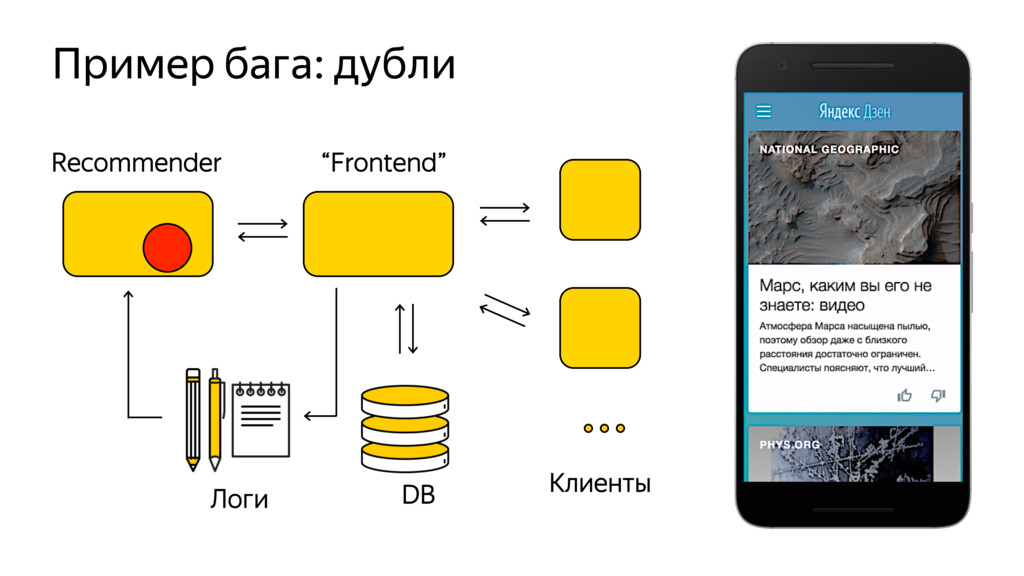
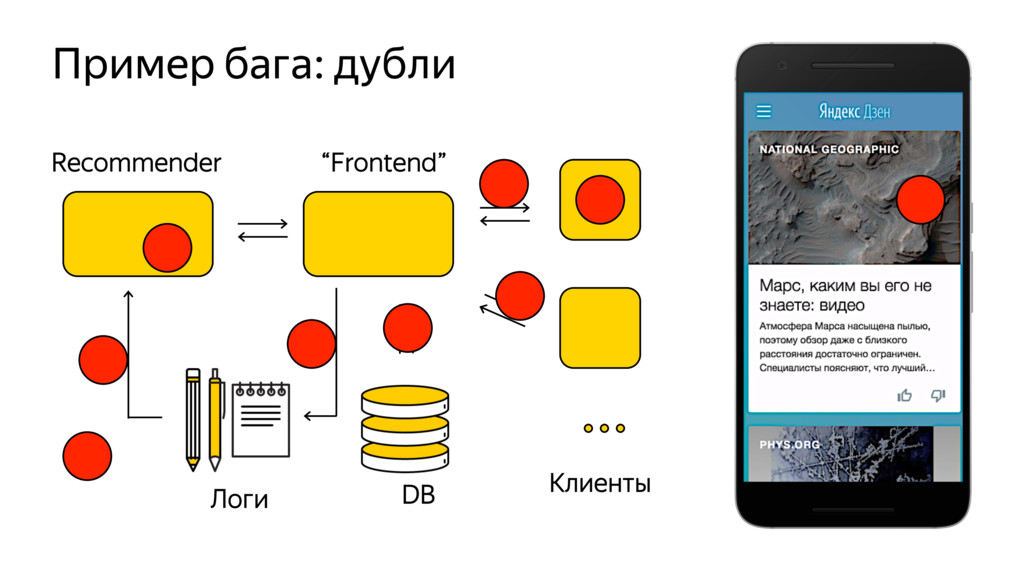
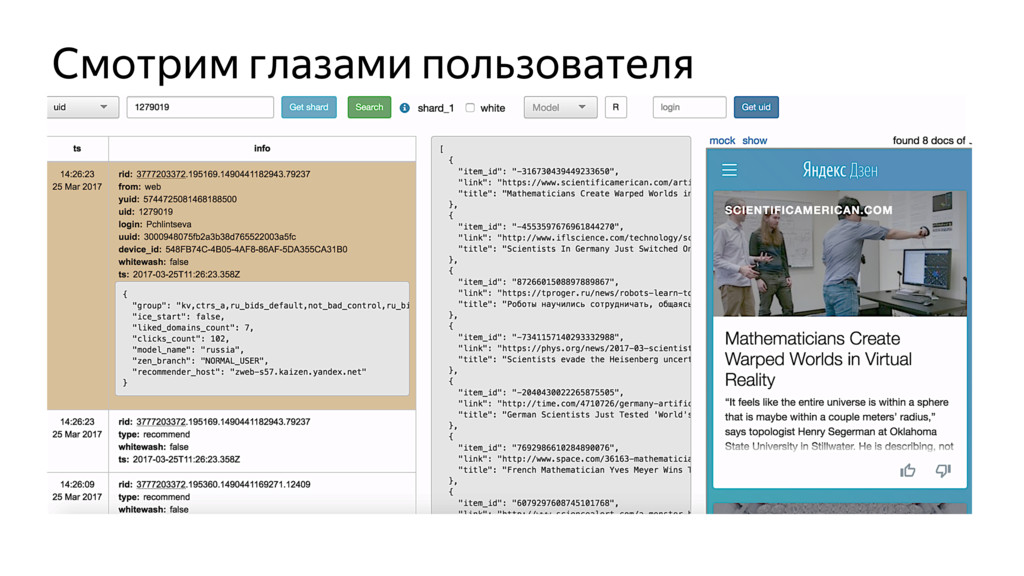
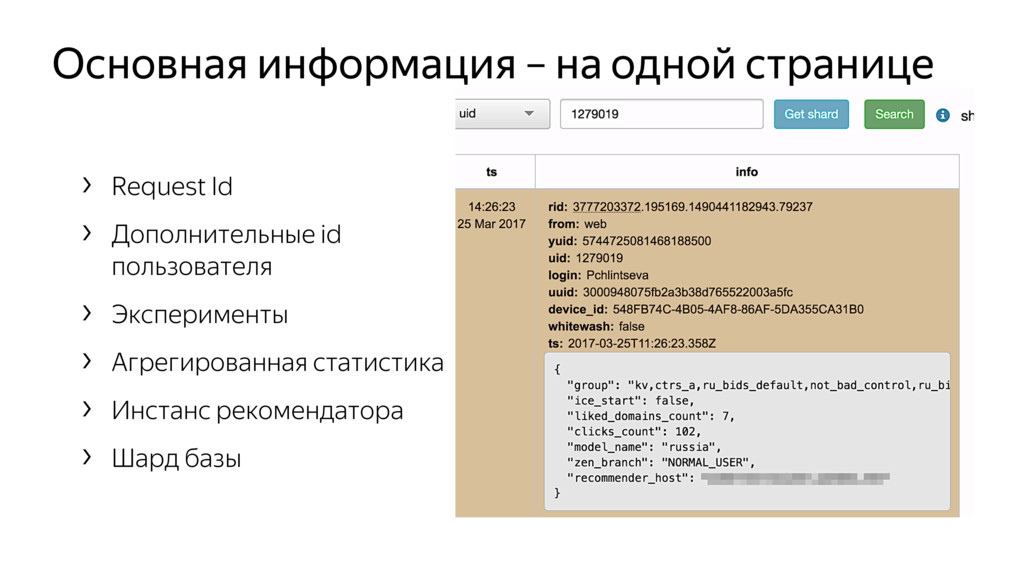
Новые технологии требуют новых подходов к тестированию и, возможно, переосмысления роли функционального тестировщика. Значительная часть качества продукта лежит в области с недетерминированным "правильным" поведением. Как понять, что экспериментальная рекомендательная выдача для Васи П. лучше текущей?
Я расскажу про специфику тестирования рекомендательных систем, метрики качества и уязвимые места, с примерами из жизни высоконагруженного рекомендательного сервиса Яндекс.Дзен.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![telegram.me/blindsight [email protected] Cпасибо за внимание! Пчелинцева Ирина Руководитель группы тестирования](https://files.speakerdeck.com/presentations/271f575e5ccd4c609e0397062ddc5466/slide_45.jpg){kind=link}