https://2017.codefest.ru/lecture/1197
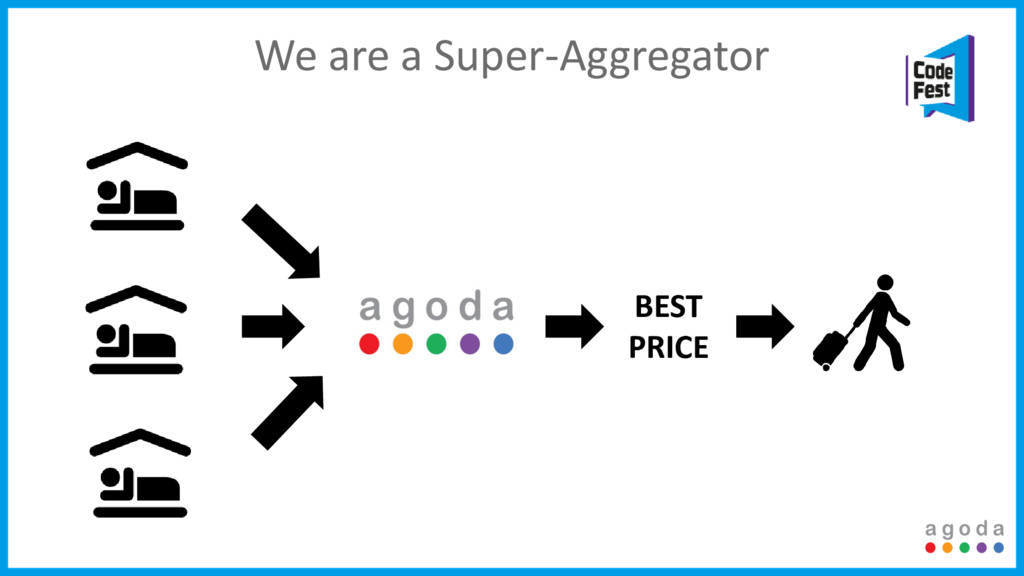
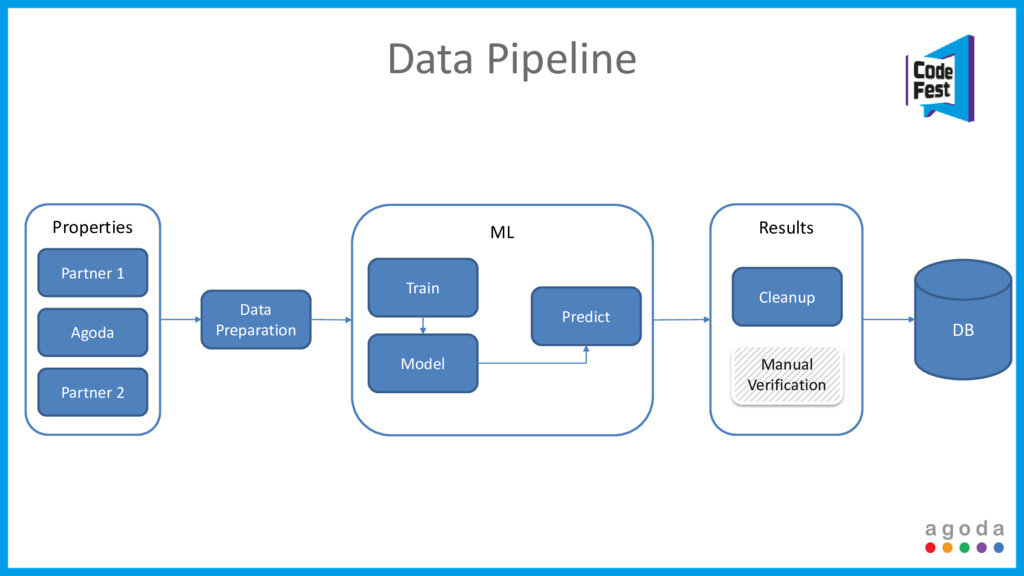
Agoda is experiencing intense growth these days. We add a new partner every one to two weeks that brings with it tens of thousands of properties, many more rooms and allows us to serve our customers the best prices. Do we just kick back and enjoy the results? Not even close.
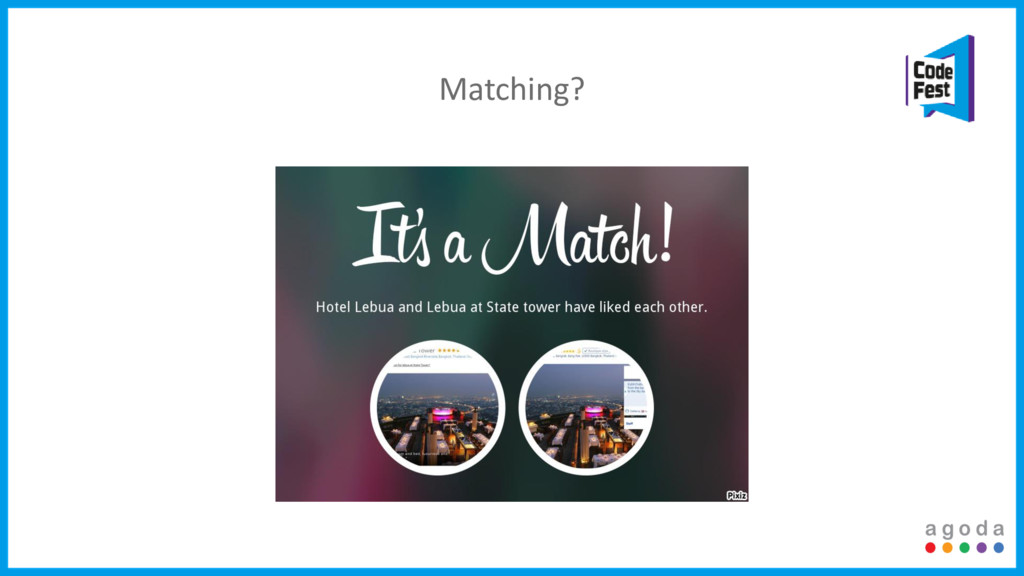
Every integration creates possibly thousands of duplicate properties. Once we identify these duplicates we create even more problems, hundreds of thousands of duplicate rooms. Add in data integrity issues, lack of consistent standards, the scale we operate in, and it never stops.
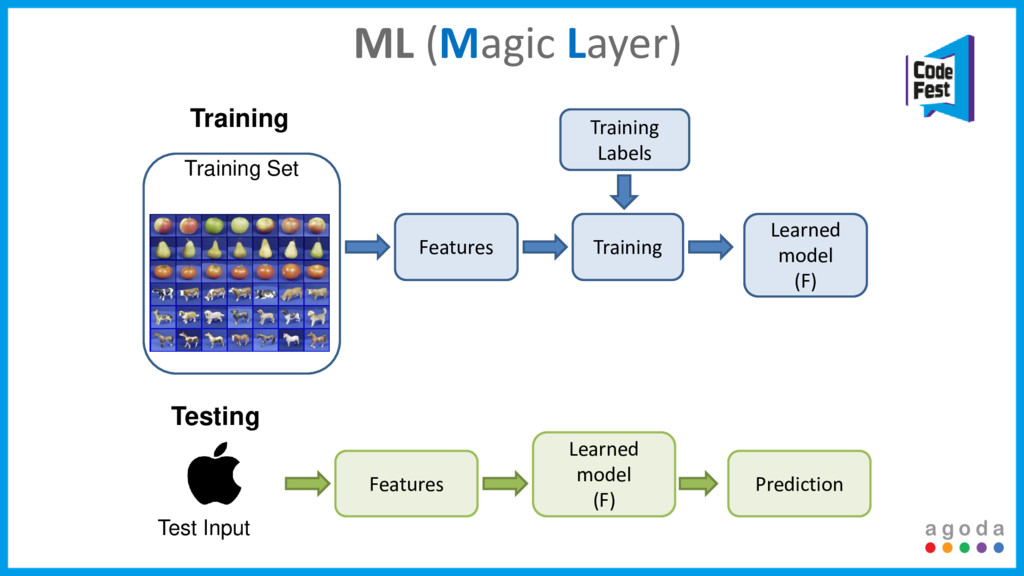
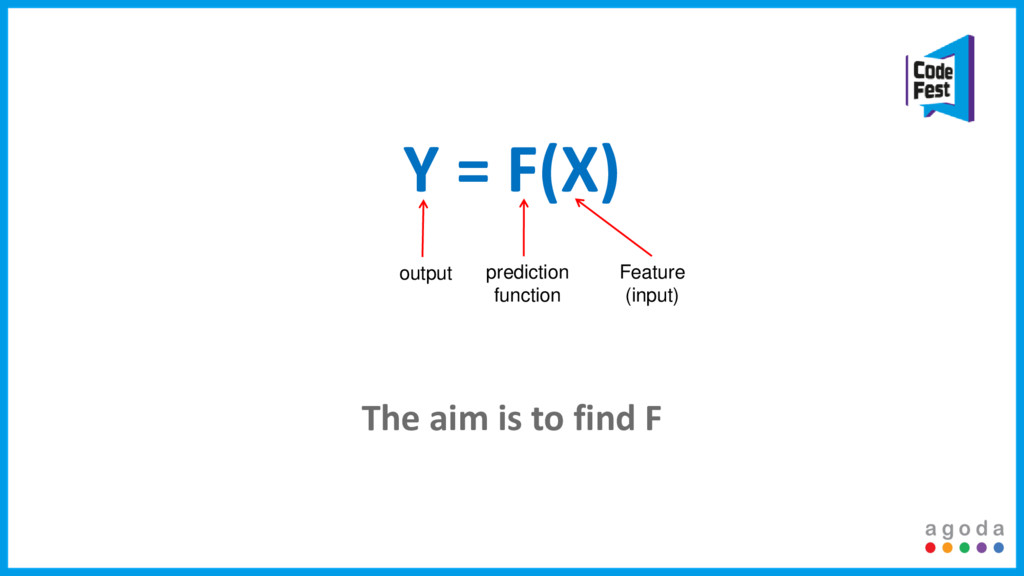
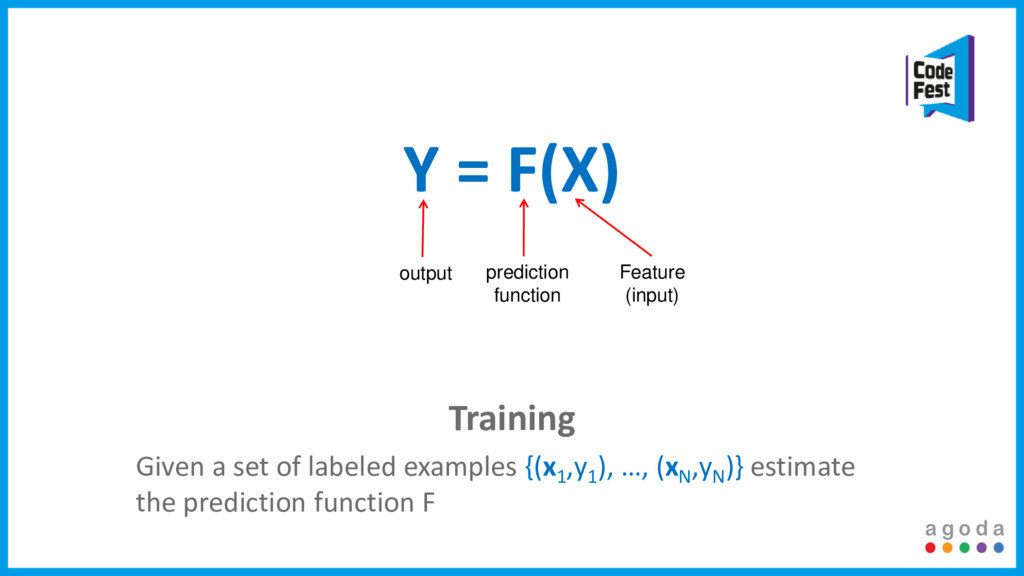
The answer to our problems? Machine learning, Big Data tools and an almost fully automated process. This talk will focus on how we tackled all these issues, the compromises we had to make and most importantly how we are scaling it to support our growth.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Questions? [email protected] Levon Ter-Isahakyan](https://files.speakerdeck.com/presentations/8f10394442374118a5c63d0813cbaa89/slide_52.jpg){kind=link}