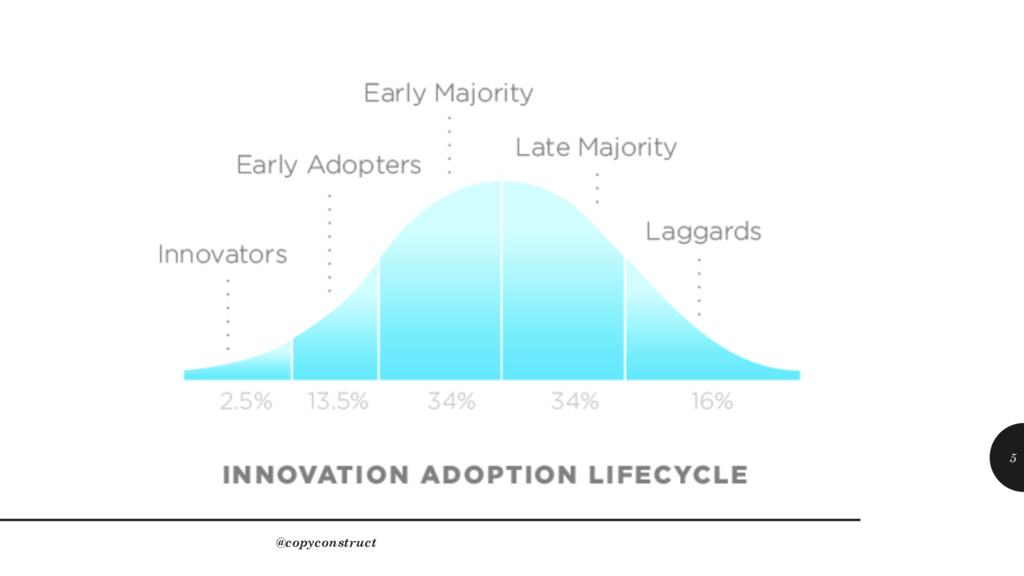
technology that promises the moon, to retrofit our problem space with the solution space of said technology, however minimal or non-existent the intersection @copyconstruct
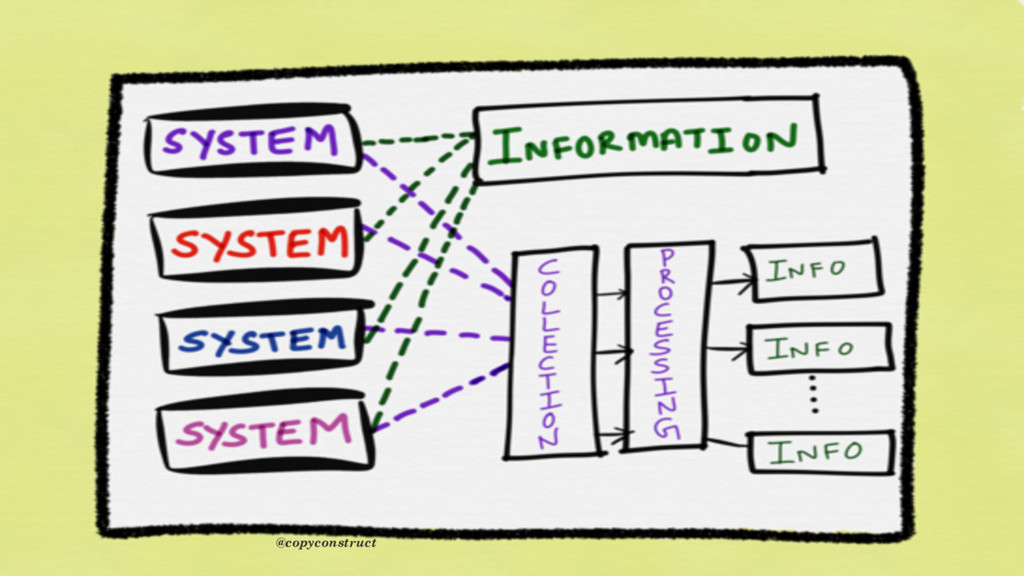
information itself When data are processed, interpreted, organized, structured or presented so as to make them meaningful or useful, they are called information. Information provides context for data. @copyconstruct
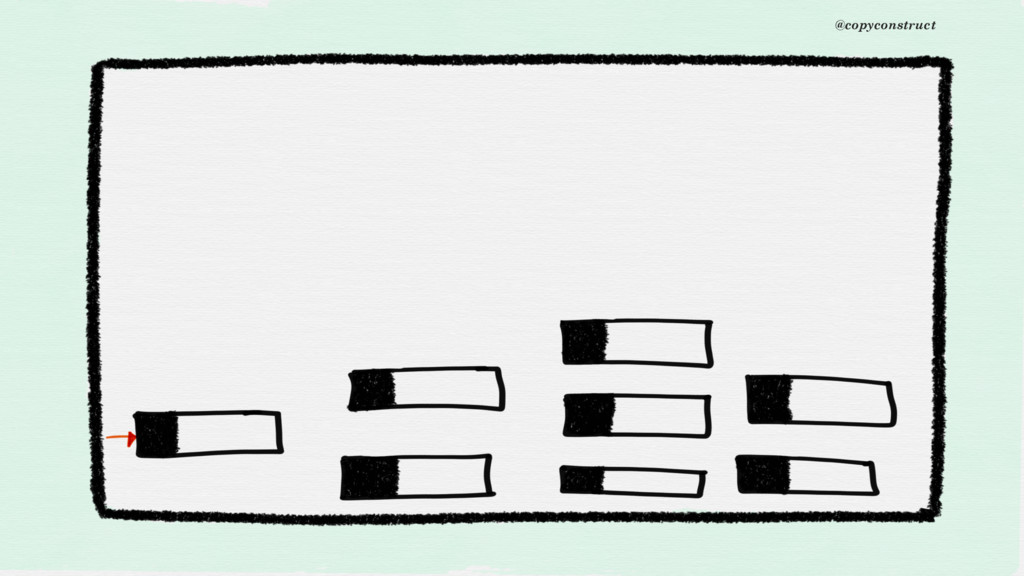
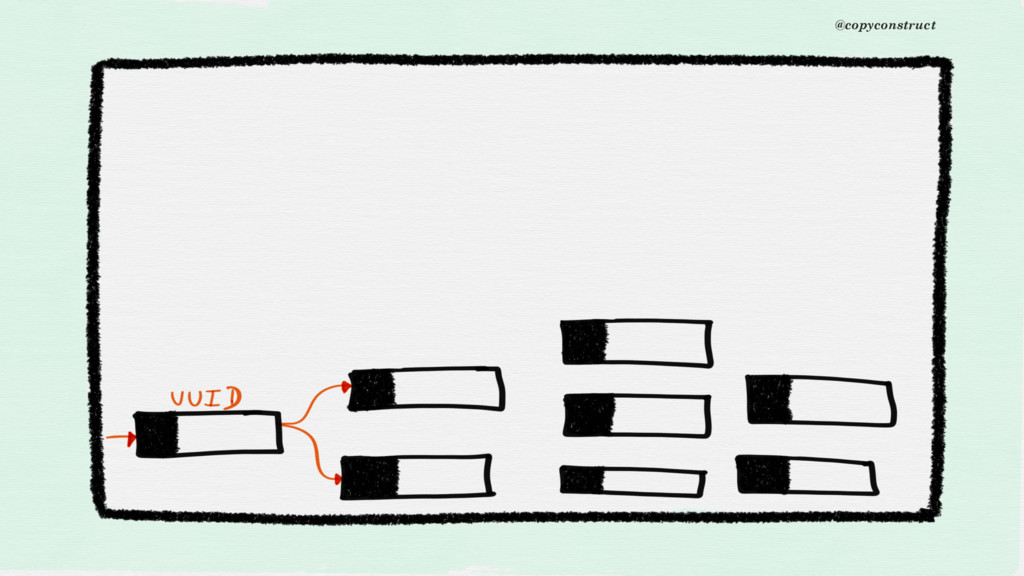
is recorded at regular periods of time and then studied. Time series are typically used to study, for example, sales, orders, income, etc.” @copyconstruct
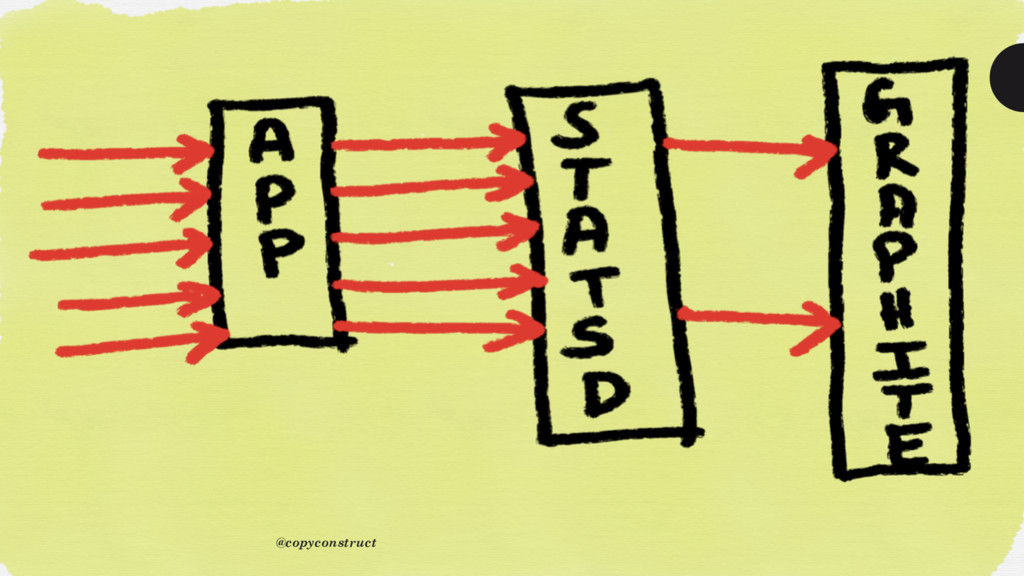
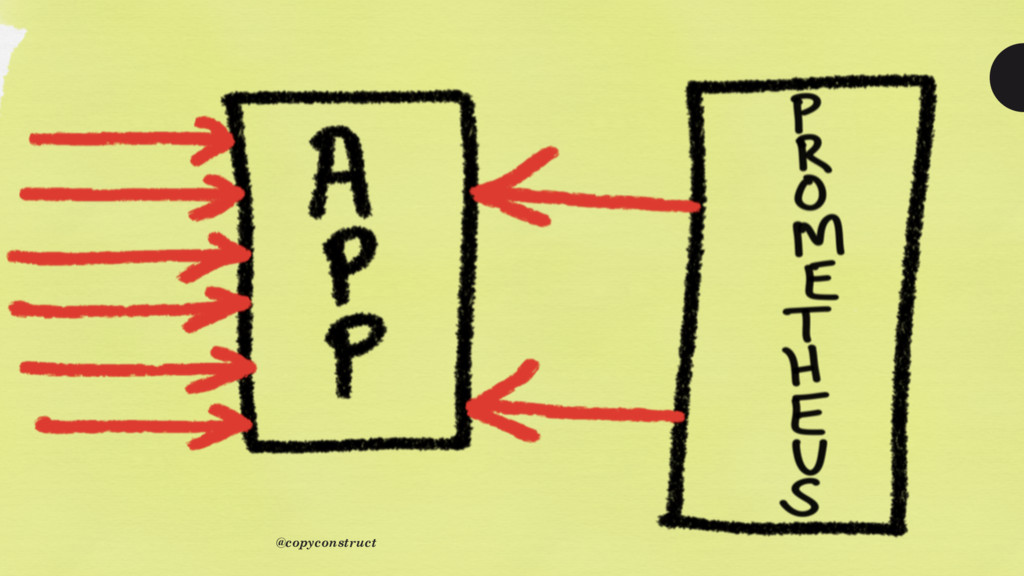
that turning off most logging almost doubled performance on the instances we were running on because logs ate through AWS’ EC2 classic’s packet allocations like mad. It was interesting for us to discover that more than 50% of our performance would be lost to trying to control and monitor performance” @copyconstruct
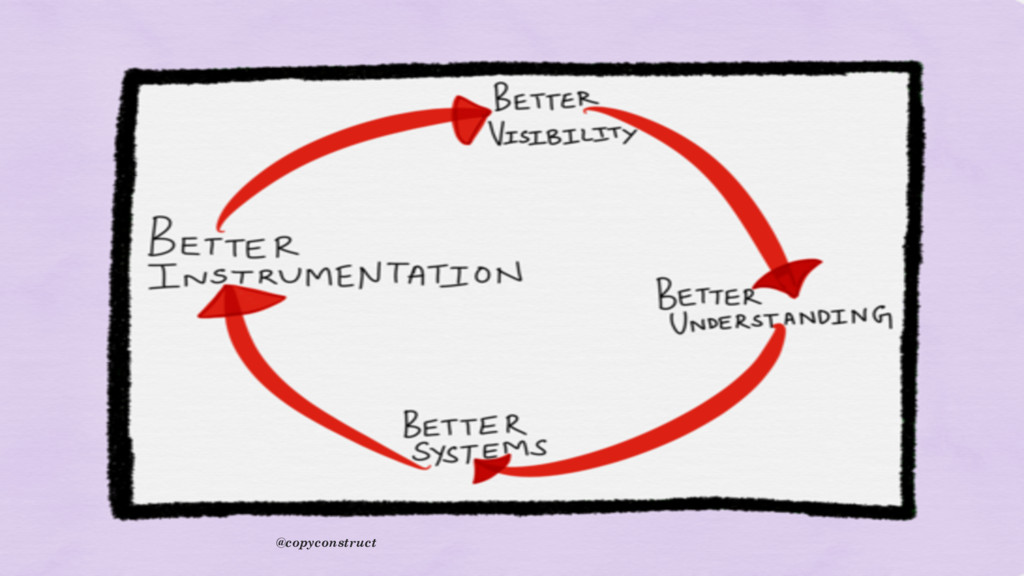
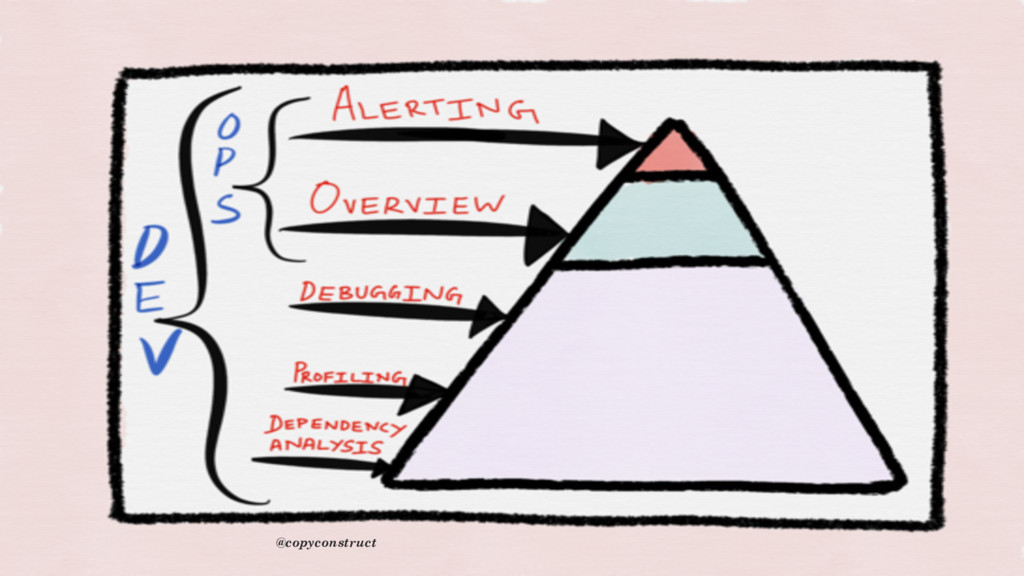
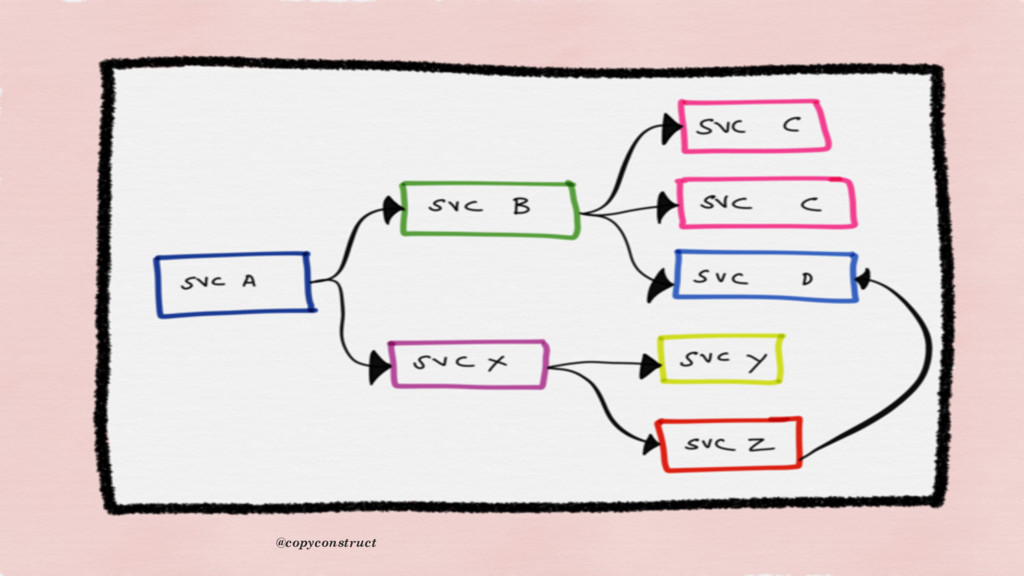
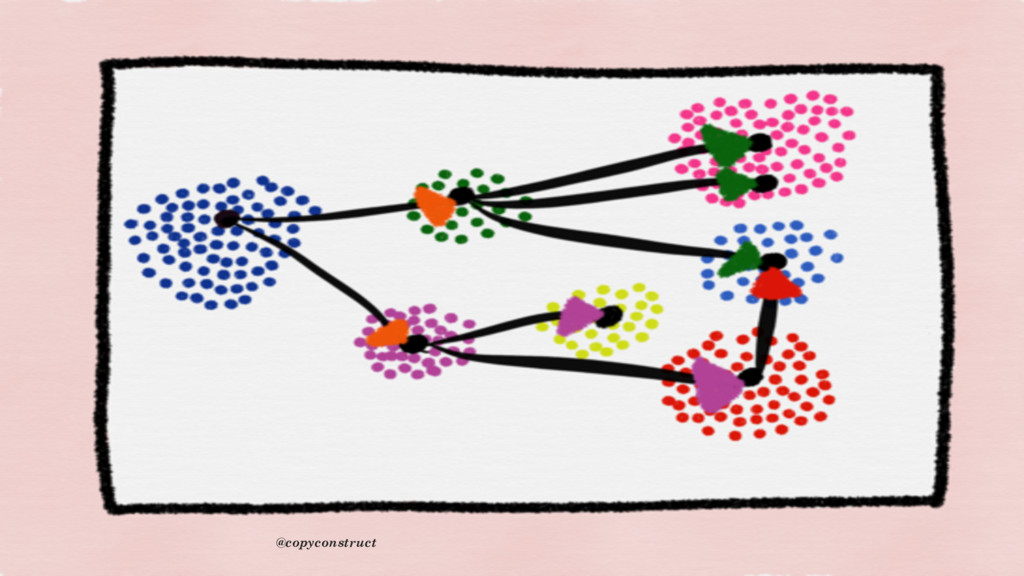
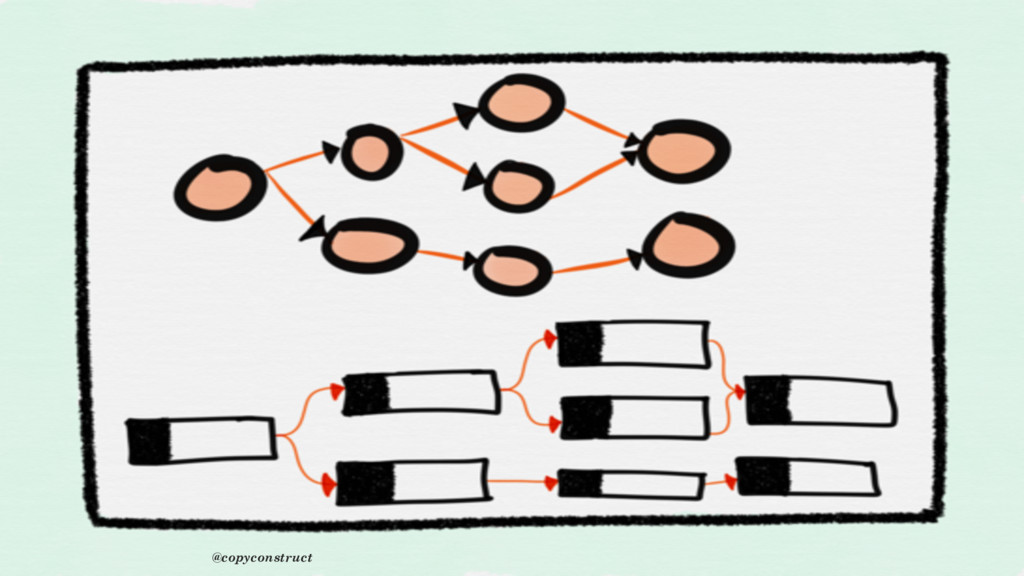
year and it’s not complete yet. The challenge with these type of tools is that, we need to add code around each span to truly understand what’s happening during the lifetime of our requests. The frustrating part is that if the code is not instrumented or header is not carrying the id, that code becomes a risky blind spot for operations” @copyconstruct
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
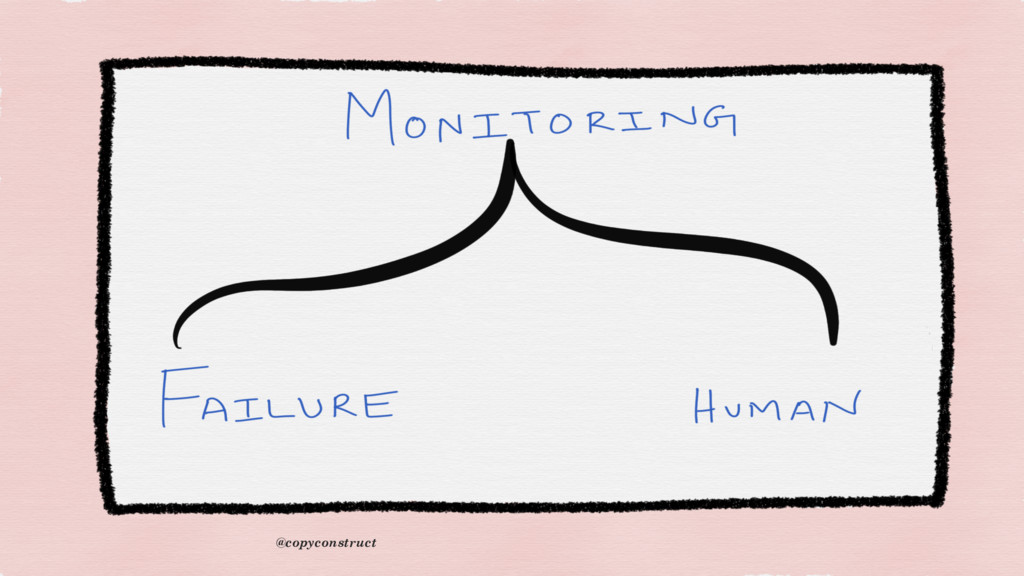{kind=link}
{kind=link}
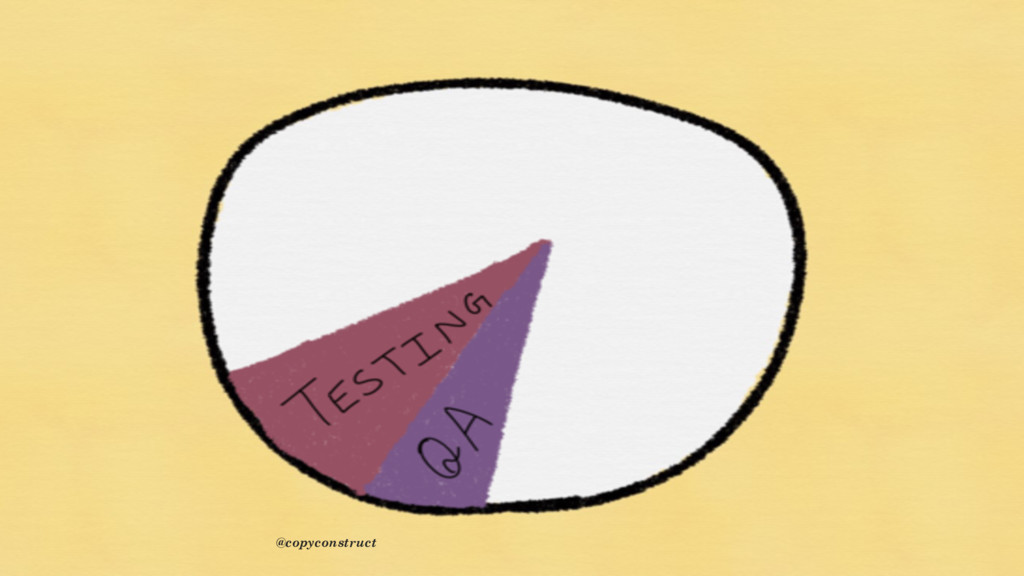{kind=link}
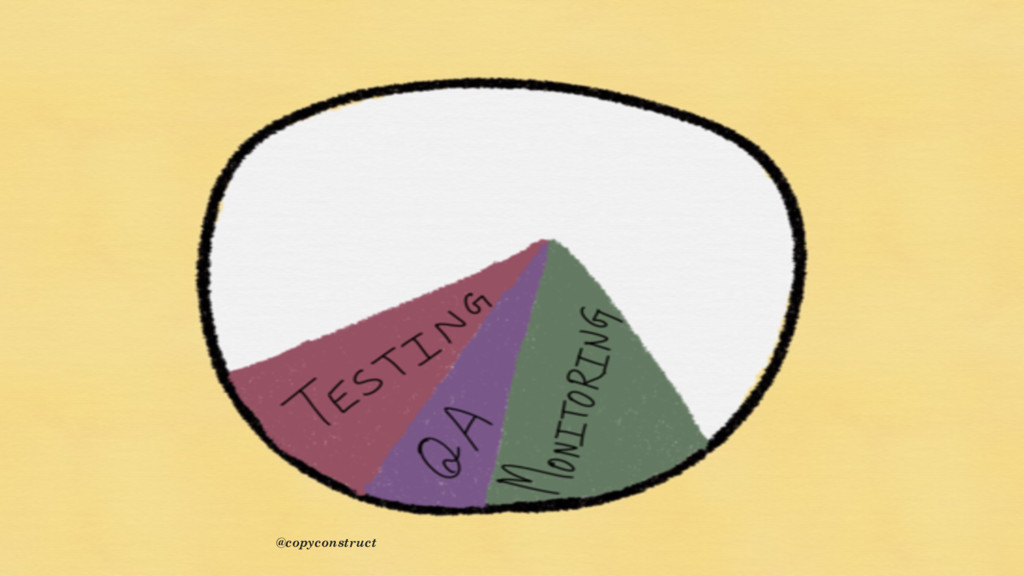{kind=link}
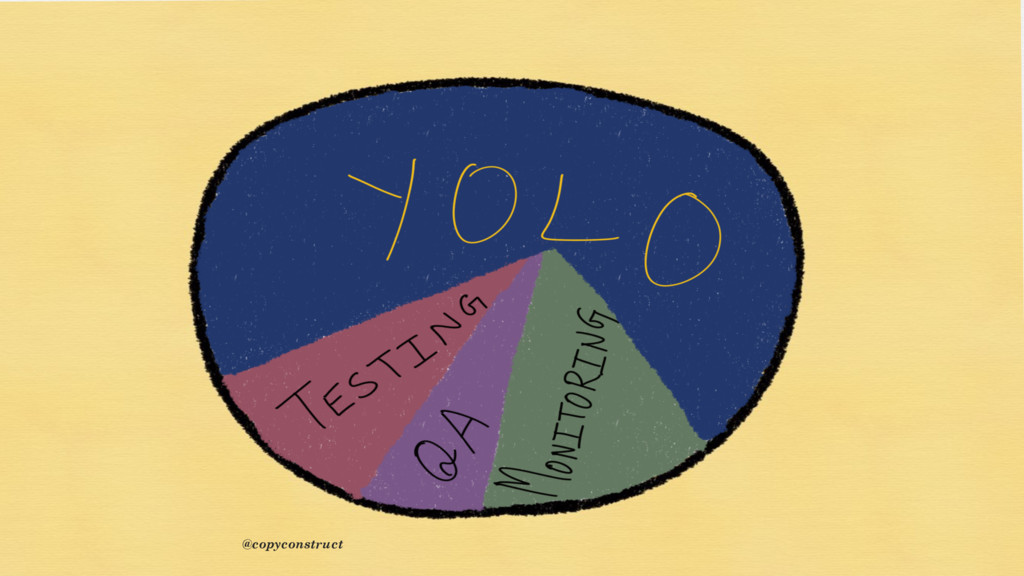{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![“A fun thing I had seen while at [redacted] was](https://files.speakerdeck.com/presentations/ada73a6939cb410bb3bdad0d57e0d049/slide_80.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
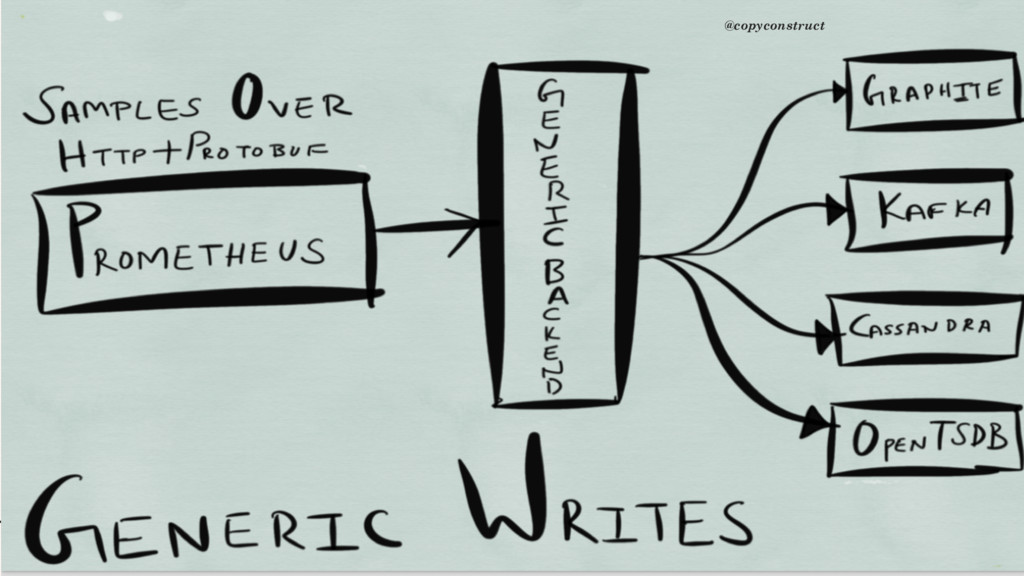{kind=link}
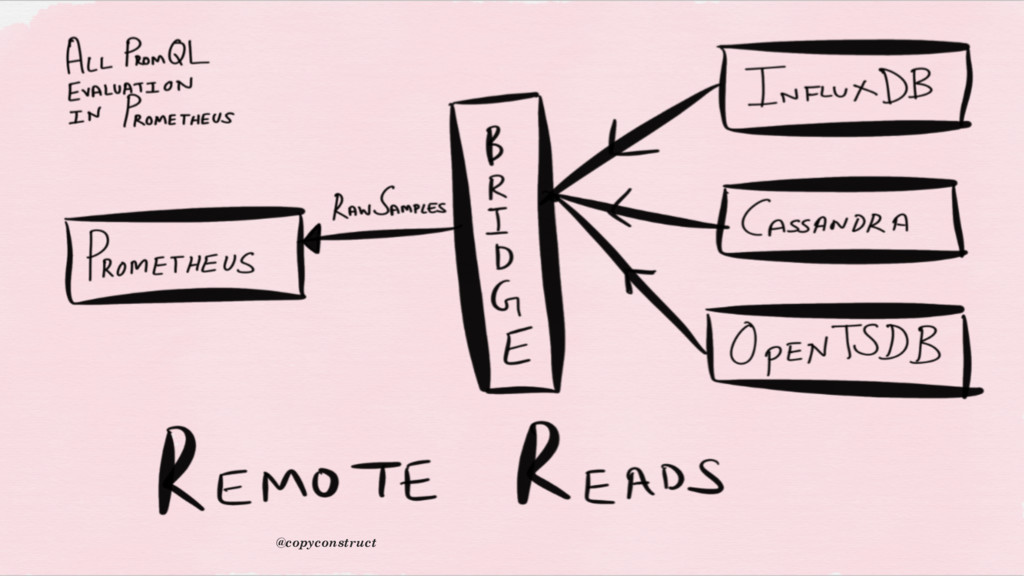{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
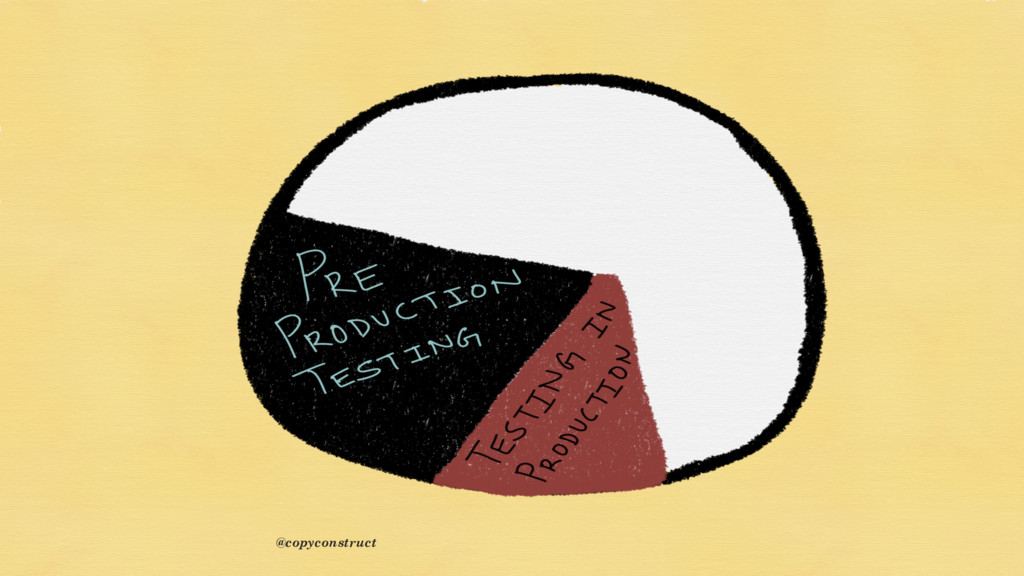{kind=link}
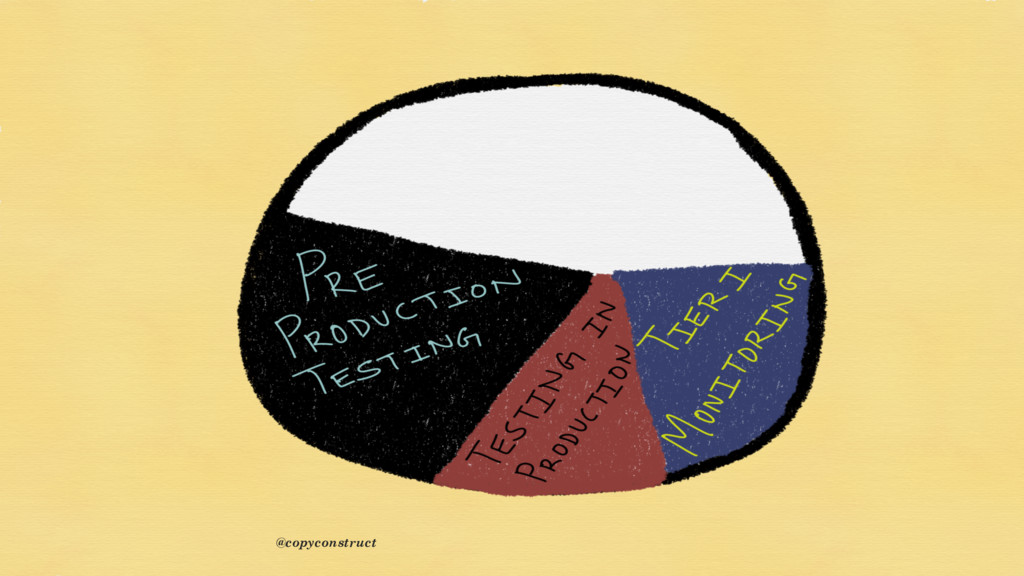{kind=link}
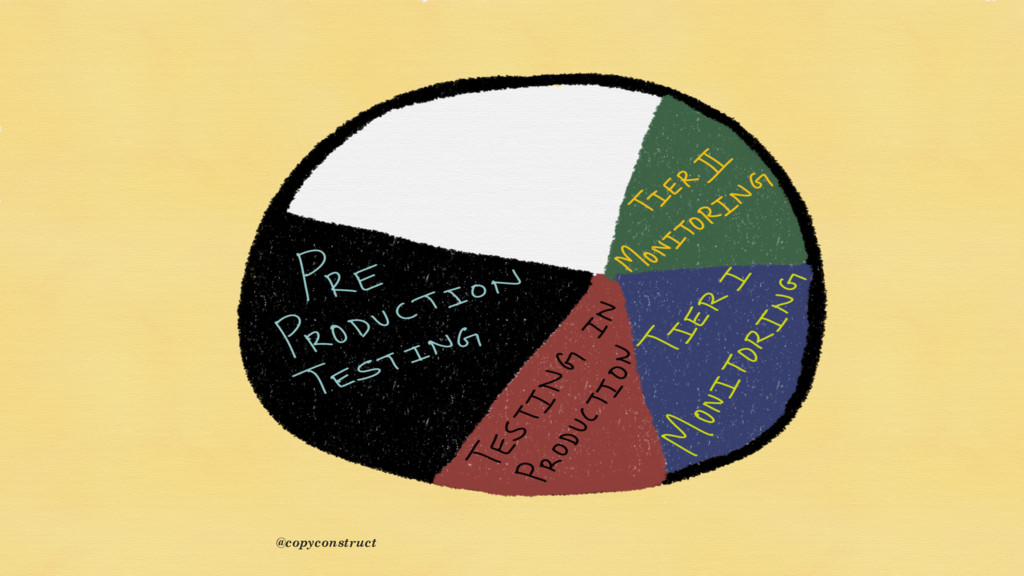{kind=link}
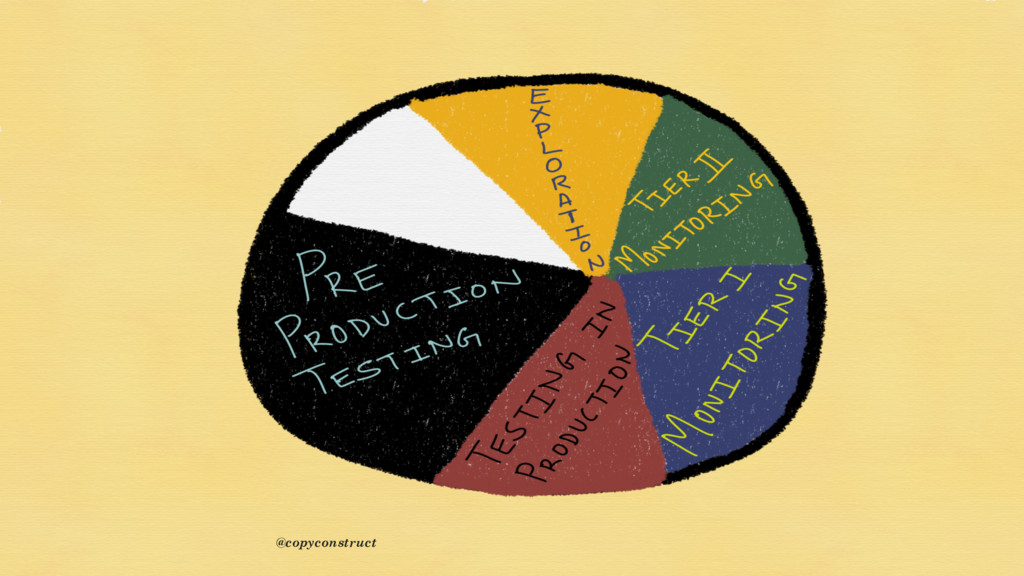{kind=link}
{kind=link}
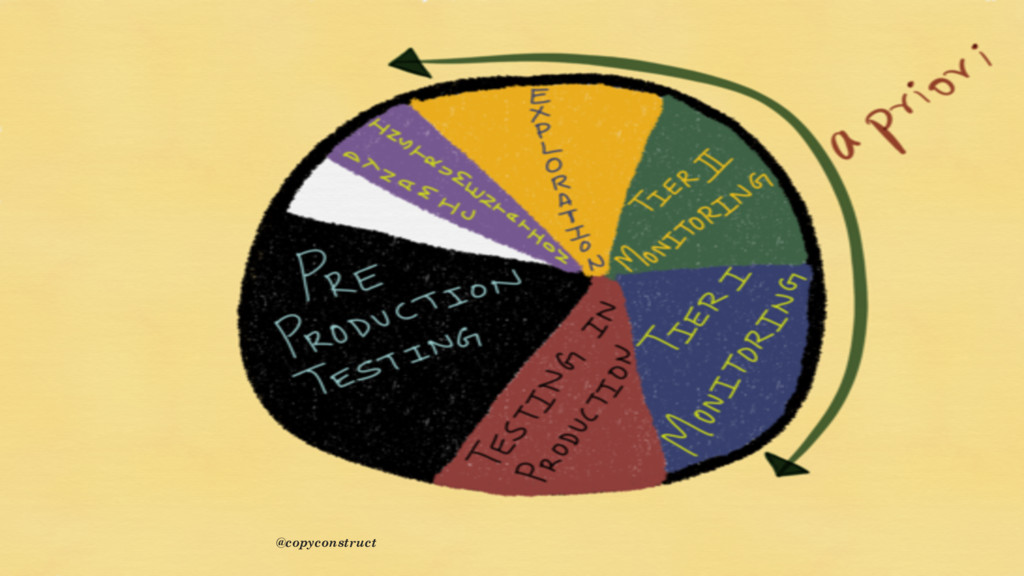{kind=link}
{kind=link}
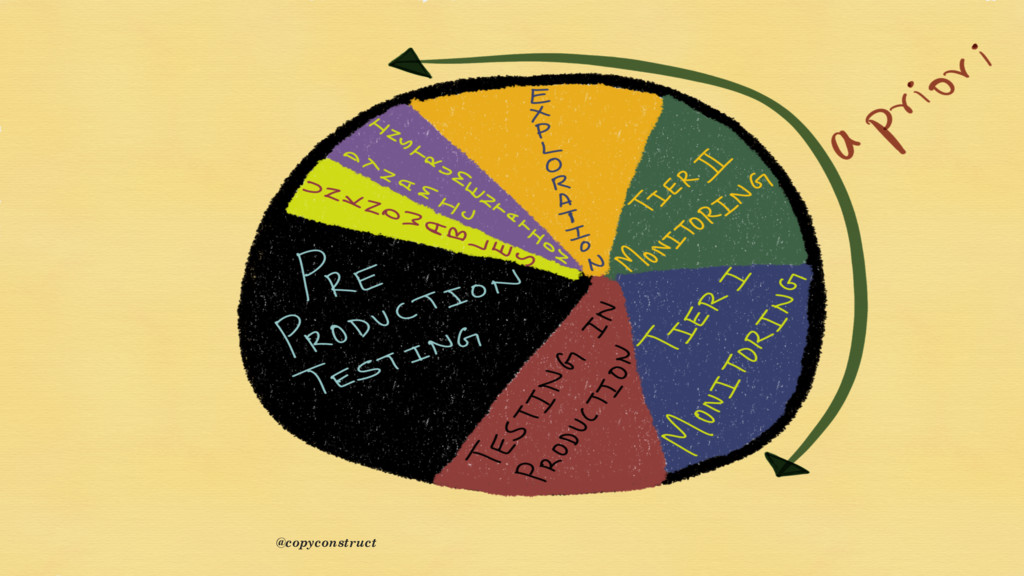{kind=link}
{kind=link}
{kind=link}
{kind=link}