This talk will show our approach to implementing distributed equi-join operator in CrateDB that exhibits significant performance improvements compared to the original nested loop algorithm. CrateDB is an open-source, distributed SQL database that runs queries on millions of data records daily. It scales up to hundreds of nodes and PBs of indexed data making the performance of join operators highly important: it is required to have efficient algorithms that can scale with the input size.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
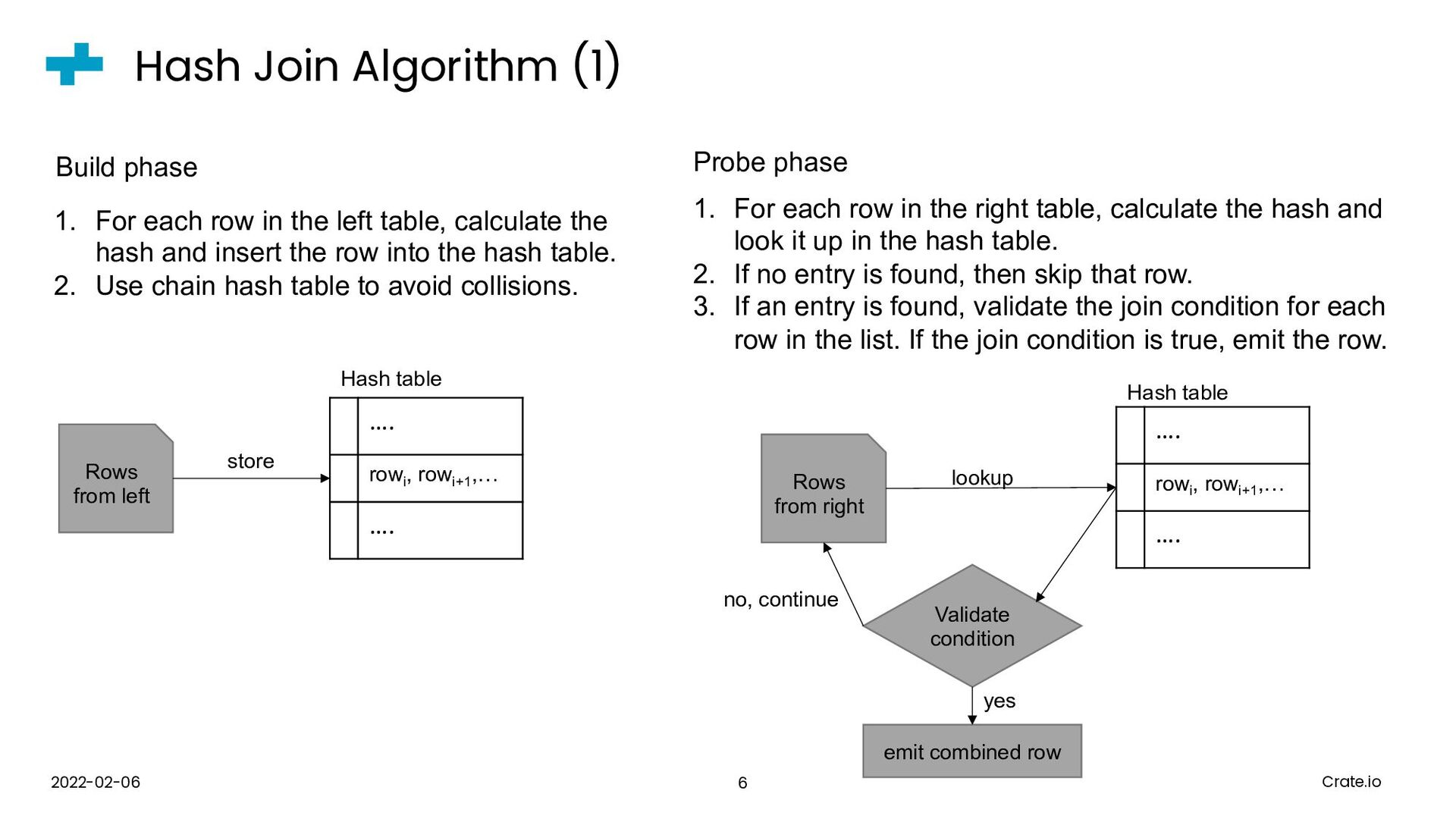{kind=link}
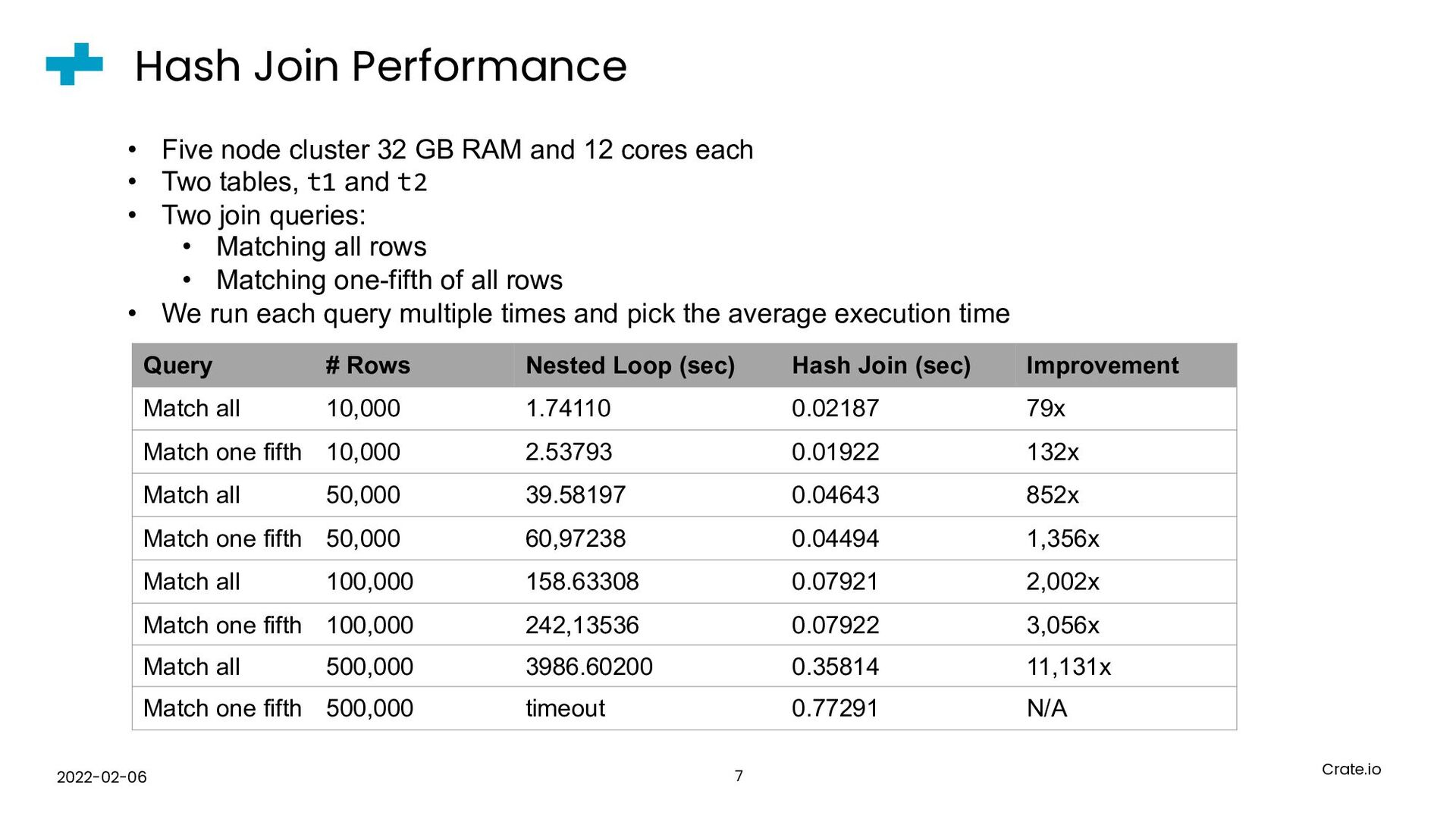{kind=link}
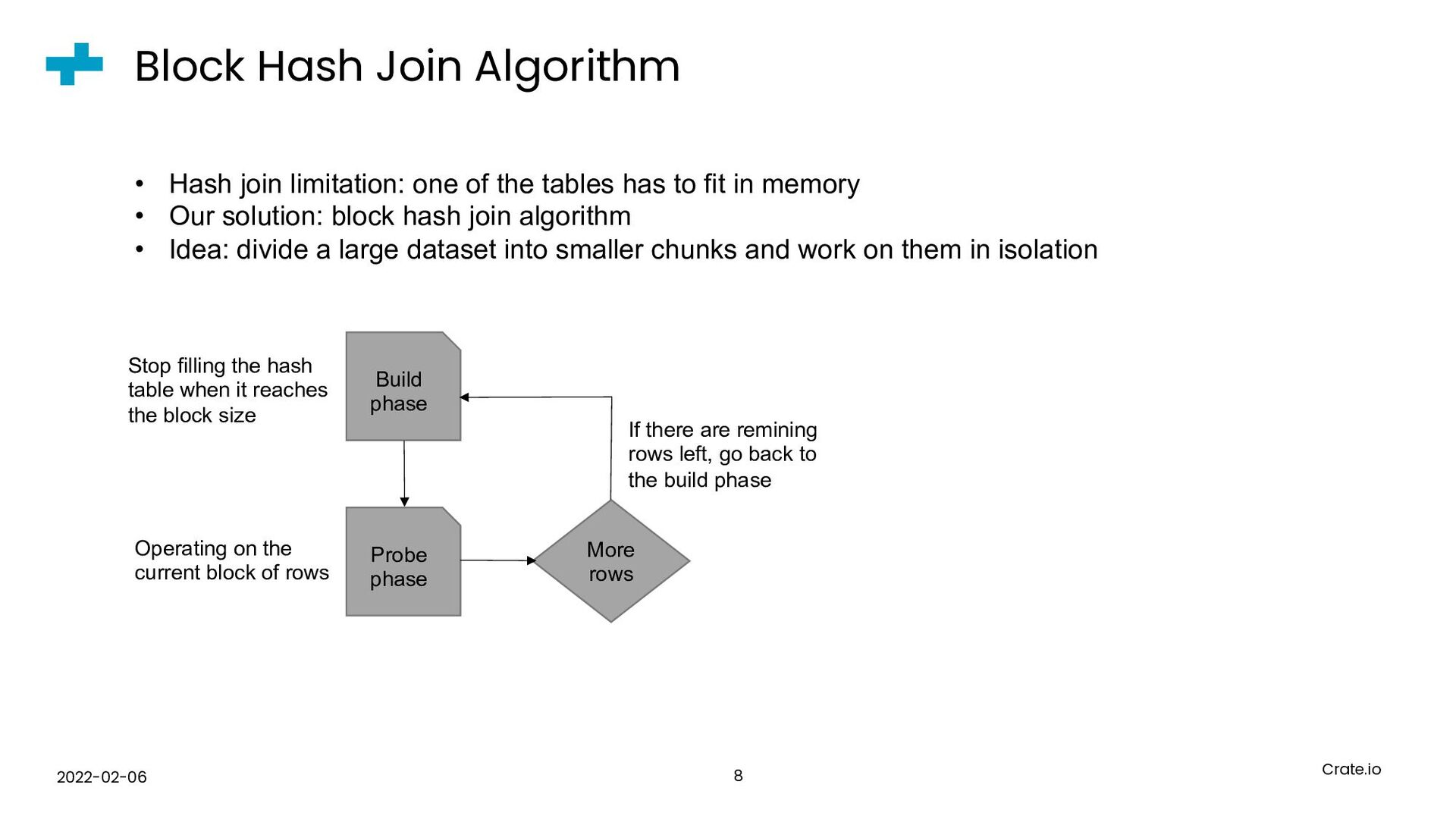{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}