When ms matter: Maximizing query performance in CrateDB
Achieving optimal execution plans in distributed databases is a challenging task. This talk will focus on CrateDB: a distributed SQL database, and key strategies for optimizing its query performance.
CrateDB • Ph.D. in computer science at TU Darmstadt • Background in software engineering and data science • Interests in big data, community engagement, and helping developers to be successful with CrateDB
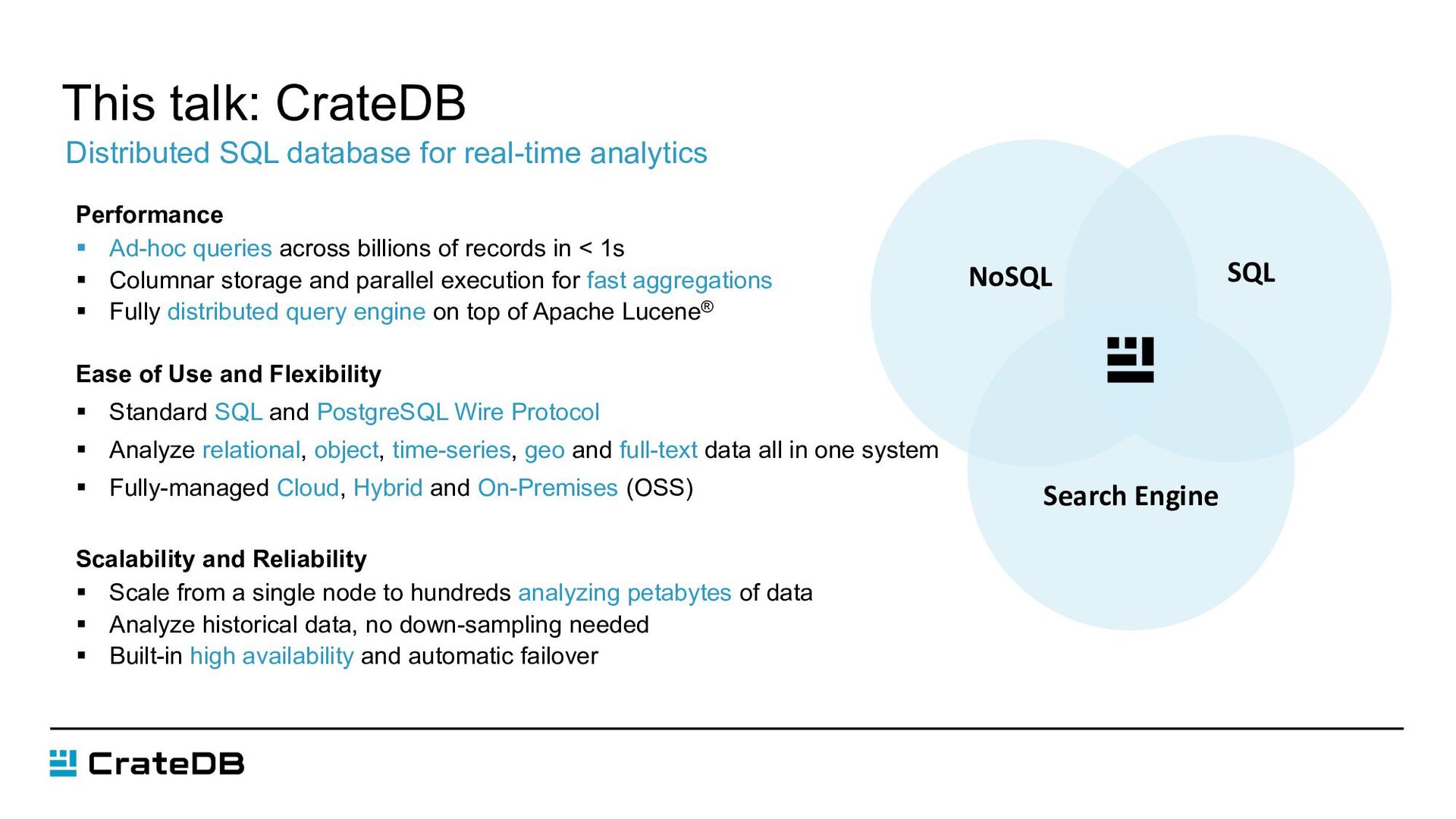
of records in < 1s § Columnar storage and parallel execution for fast aggregations § Fully distributed query engine on top of Apache Lucene® Ease of Use and Flexibility § Standard SQL and PostgreSQL Wire Protocol § Analyze relational, object, time-series, geo and full-text data all in one system § Fully-managed Cloud, Hybrid and On-Premises (OSS) Scalability and Reliability § Scale from a single node to hundreds analyzing petabytes of data § Analyze historical data, no down-sampling needed § Built-in high availability and automatic failover This talk: CrateDB Distributed SQL database for real-time analytics
execution, the query may need to be rerun on a different node High memory usage Critical utilization of node memory Resource contention Multiple queries trying to access the same resource simultanously leads to longer execution times
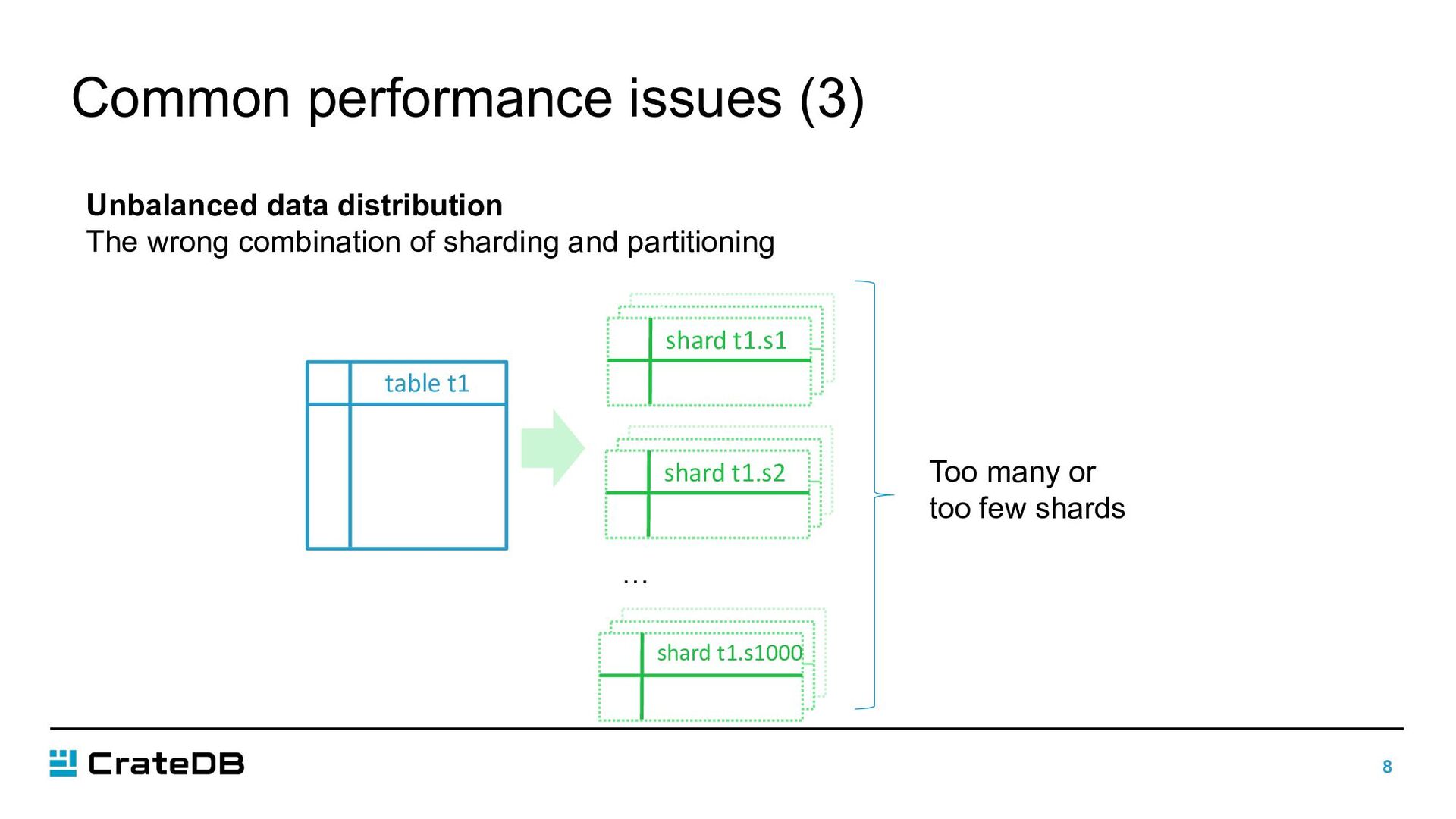
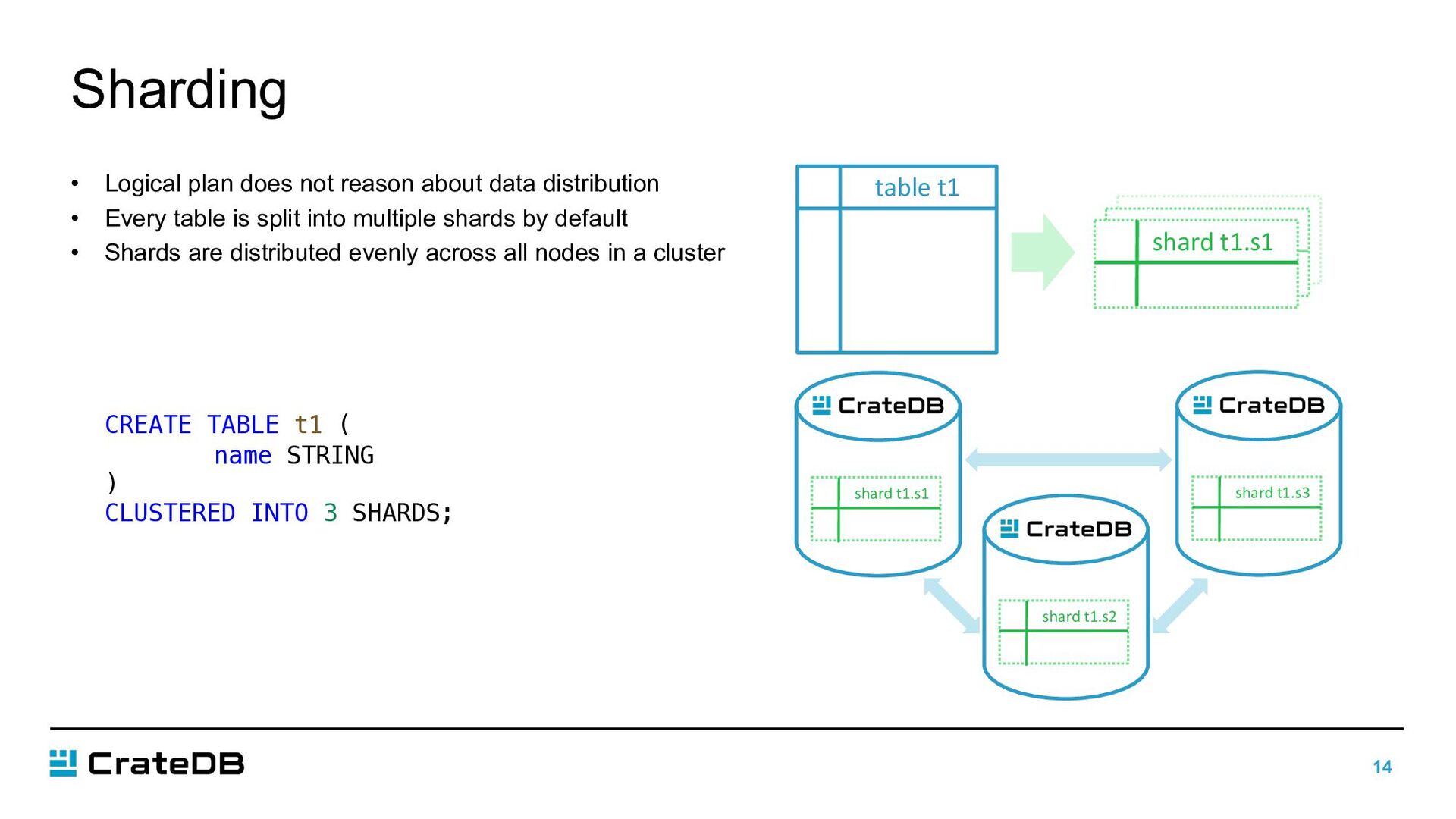
distribution • Every table is split into multiple shards by default • Shards are distributed evenly across all nodes in a cluster CREATE TABLE t1 ( name STRING ) CLUSTERED INTO 3 SHARDS; table t1 shard t1.s1 shard t1.s1 shard t1.s2 shard t1.s3
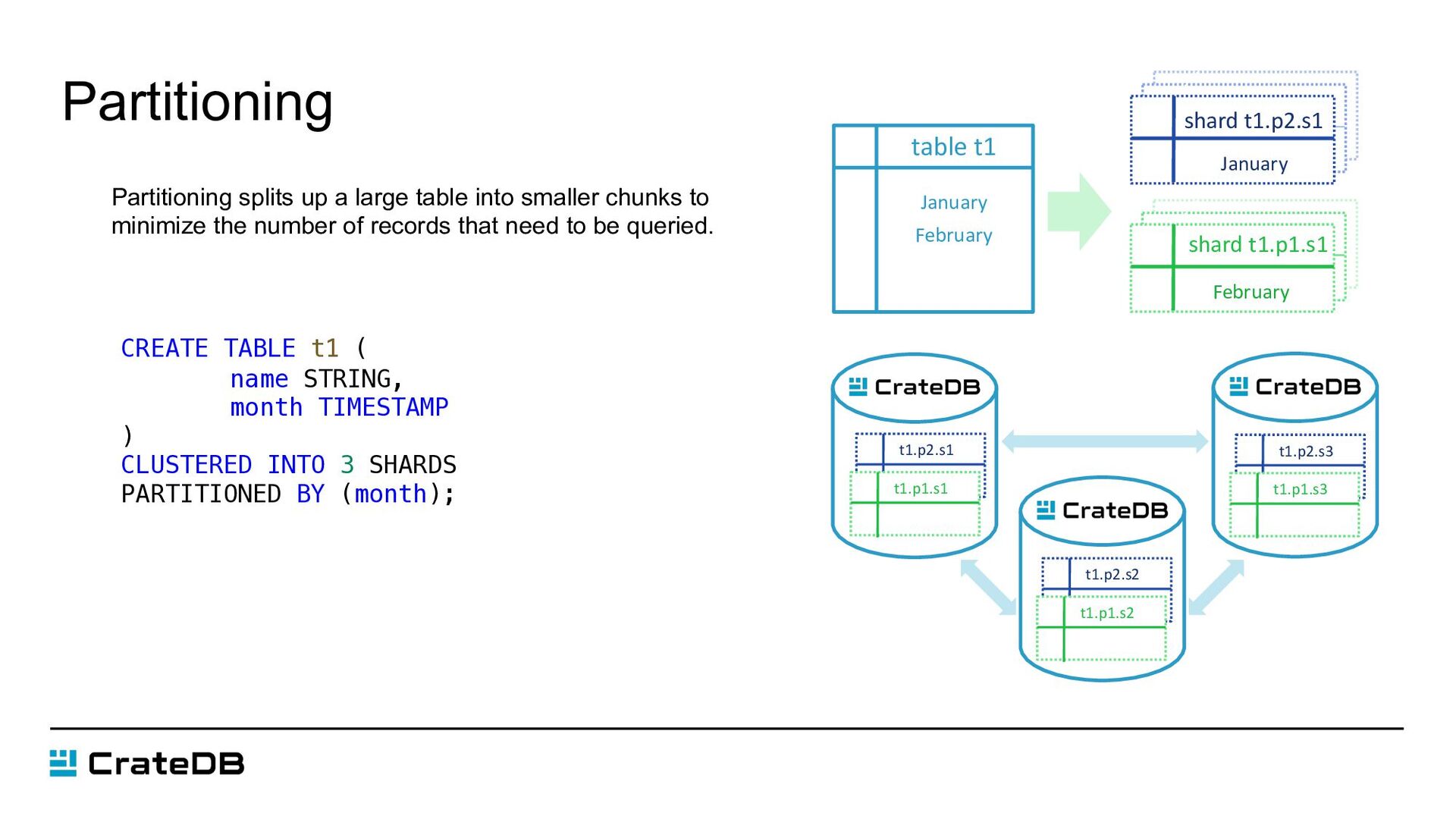
minimize the number of records that need to be queried. Partitioning table t1 January February shard t1.p1.s1 February shard t1.p2.s1 January t1.p2.s1 t1.p1.s1 t1.p2.s2 t1.p1.s2 t1.p2.s3 t1.p1.s3 CREATE TABLE t1 ( name STRING, month TIMESTAMP ) CLUSTERED INTO 3 SHARDS PARTITIONED BY (month);
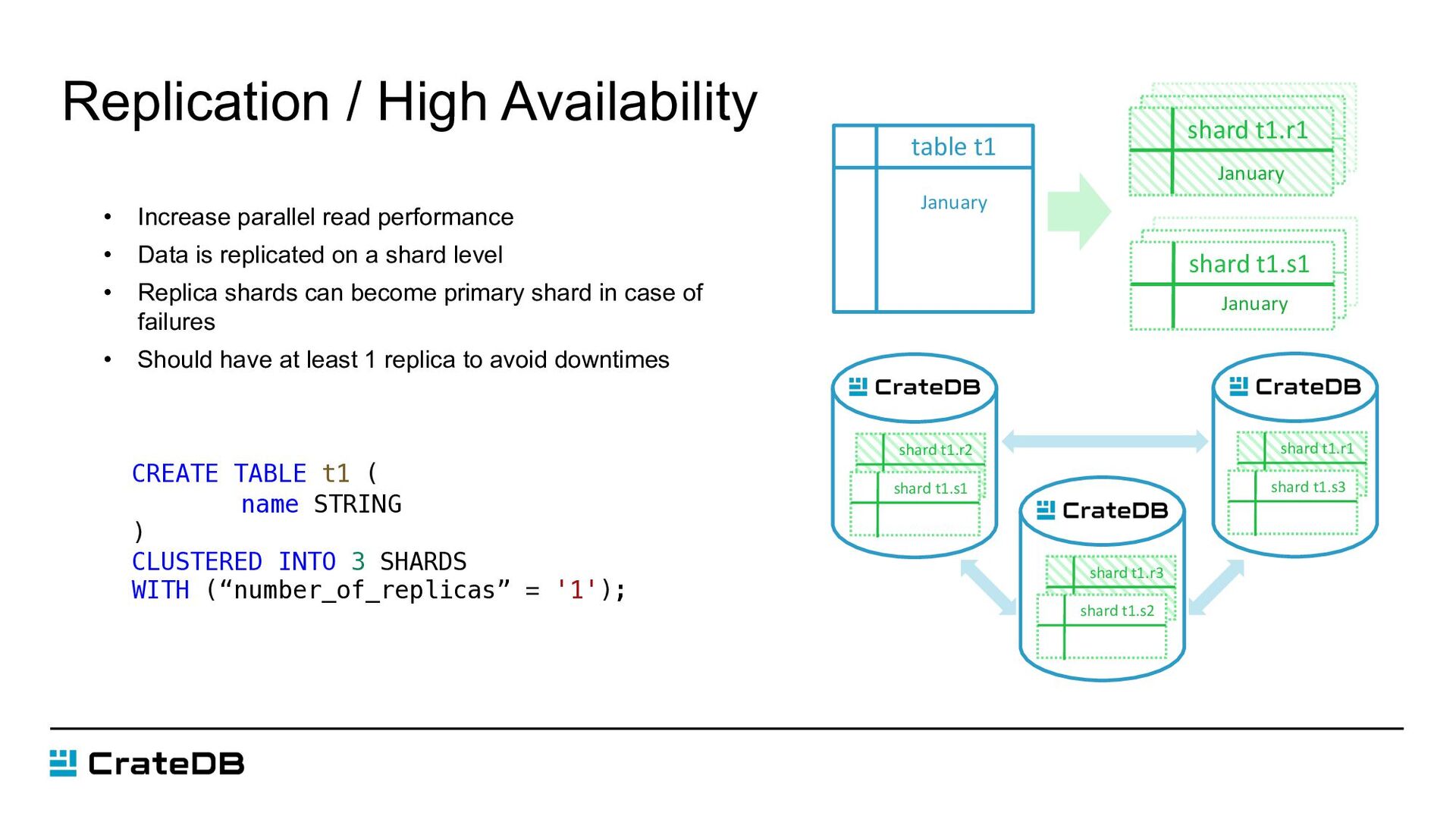
shard t1.r2 shard t1.s1 shard t1.r3 shard t1.s2 shard t1.r1 shard t1.s3 January January January CREATE TABLE t1 ( name STRING ) CLUSTERED INTO 3 SHARDS WITH (“number_of_replicas” = '1'); • Increase parallel read performance • Data is replicated on a shard level • Replica shards can become primary shard in case of failures • Should have at least 1 replica to avoid downtimes
node, you want to have #shards = #CPU cores • Plan for the future, #tables, #of concurrent queries on those tables • Use dedicated master (master-eligible) nodes in the cluster • 1GB heap on dedicated master servers ~ 3000 shards Size of Shards • Too large shards can result in long delays during cluster recovering • Better to plan ahead than increasing/decreasing #shards on a production cluster • Aim for 10GB-50GB shards
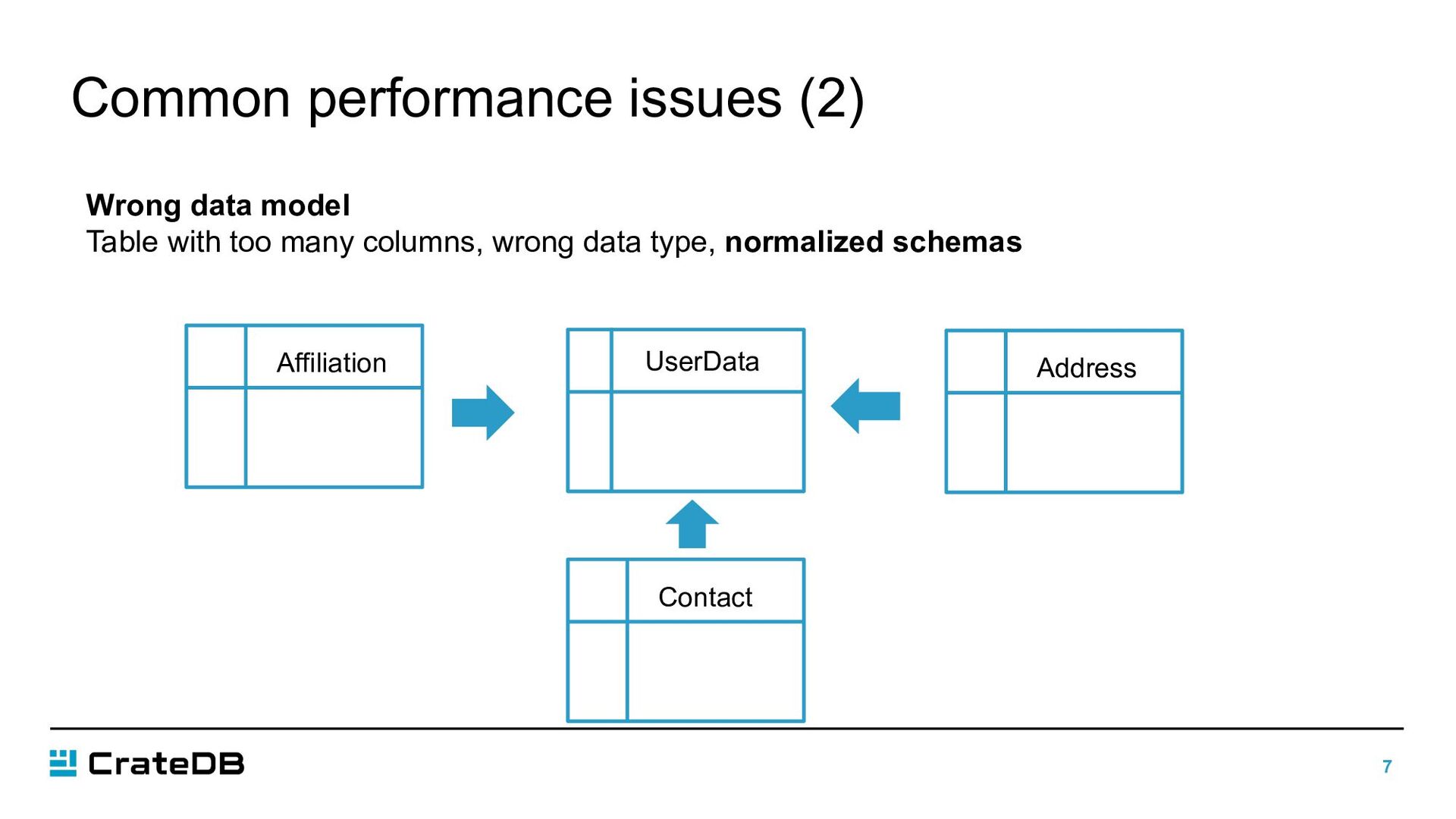
another table which each own shards § A table with 20 partitions and 10 shards has 200 shards § Choose the correct scheme for your needs, e.g.,: § daily partitions could be too fine grain and you end up with lots of shards. § Changing the partitioning scheme #shards/#replicas only apply to new partitions § Snapshot and close/drop old partitions, if needed to query on archived data, restore the partitions you need
a % 10) CLUSTERED INTO 5 shards PARTITIONED BY (b); EXPLAIN ANALYZE SELECT * FROM t1 WHERE a = 11; 50x "QueryDescription": "a:[11 TO 11]", "QueryName": "PointRangeQuery" Hits 10 partitions, 50 shards EXPLAIN ANALYZE SELECT * FROM t1 WHERE a = 11 AND b=1; Hits 1 partition, 5 shards 5x "QueryDescription": "a:[11 TO 11]", "QueryName": "PointRangeQuery"
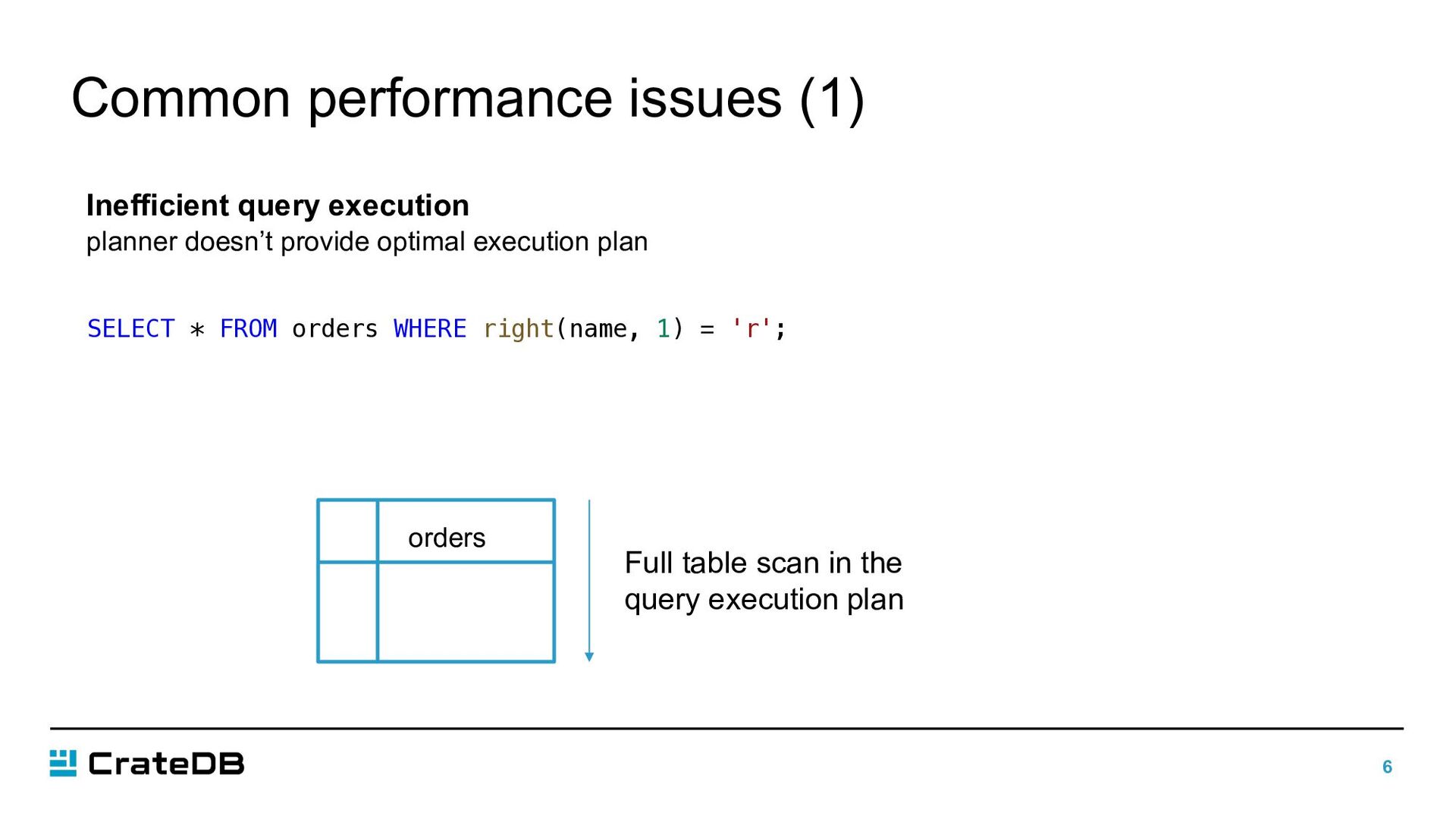
more than rarely 10k rows are needed • Try to avoid joins as much as possible, use denormalized table schemes • Make use of the right function/operator EXPLAIN ANALYZE SELECT * FROM t1 WHERE s LIKE '%r'; EXPLAIN ANALYZE SELECT * FROM t1 WHERE right(s, 1) = 'r'; "QueryDescription": "s:*r", "QueryName": "MultiTermQueryConstantScoreBlendedWrapper" "QueryDescription": "(right(s, 1) = r)", "QueryName": "GenericFunctionQuery"
INTO 1 SHARDS; • Consider cases that involve NULL and 3-value logic • ignore3vl function elimitates 3-value logic on the whole tree of operators EXPLAIN ANALYZE SELECT * FROM t1 WHERE NOT 5 = ANY(a); EXPLAIN ANALYZE SELECT * FROM t1 WHERE NOT IGNORE3vl(5 = ANY(a)); 3 nested queries Running time: >1.3s 2 nested queries, eliminates 3-value logic Running time: <0.03s
• WITH CTE provides more opportunity to optimize the logical plan (from 19s to 6s) • Further replacing BETWEEN with simpler filter (i.e., > and <=) reduces the execution time to 200 ms!
more • Documentation: https://crate.io/docs/crate/ • Visit https://crate.io/docs/crate/howtos/en/latest/performance/index.html to learn more about performance Try CrateDB • In the cloud for free: https://crate.io/lp-free-trial • On-premise: https://crate.io/download#cratedb Contact us: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Lucene vs SQL CREATE TABLE t1(x int, a int[]) CLUSTERED](https://files.speakerdeck.com/presentations/85571c426ab640a8a790a2ea2e33fdbf/slide_22.jpg){kind=link}
{kind=link}
{kind=link}