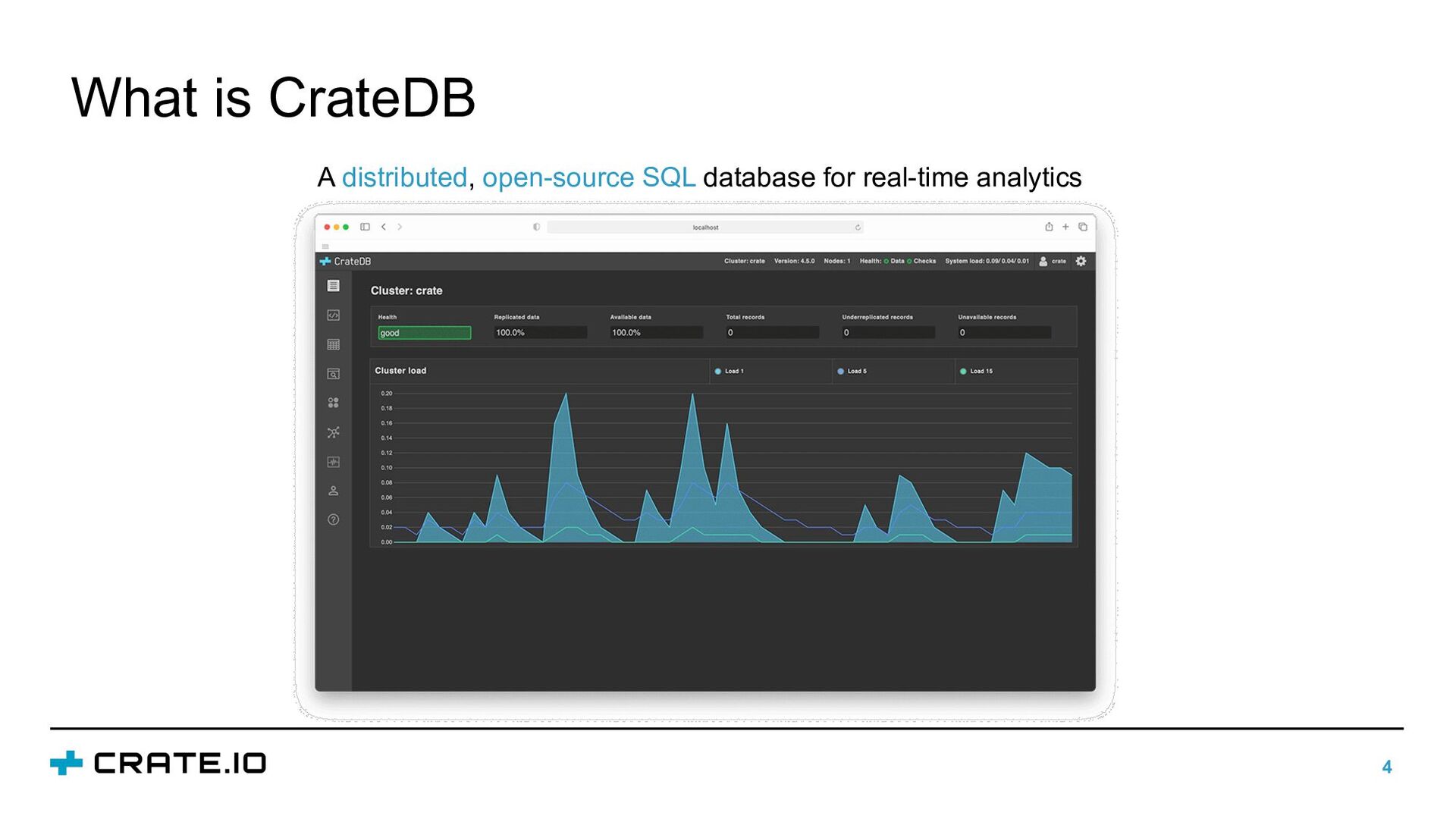
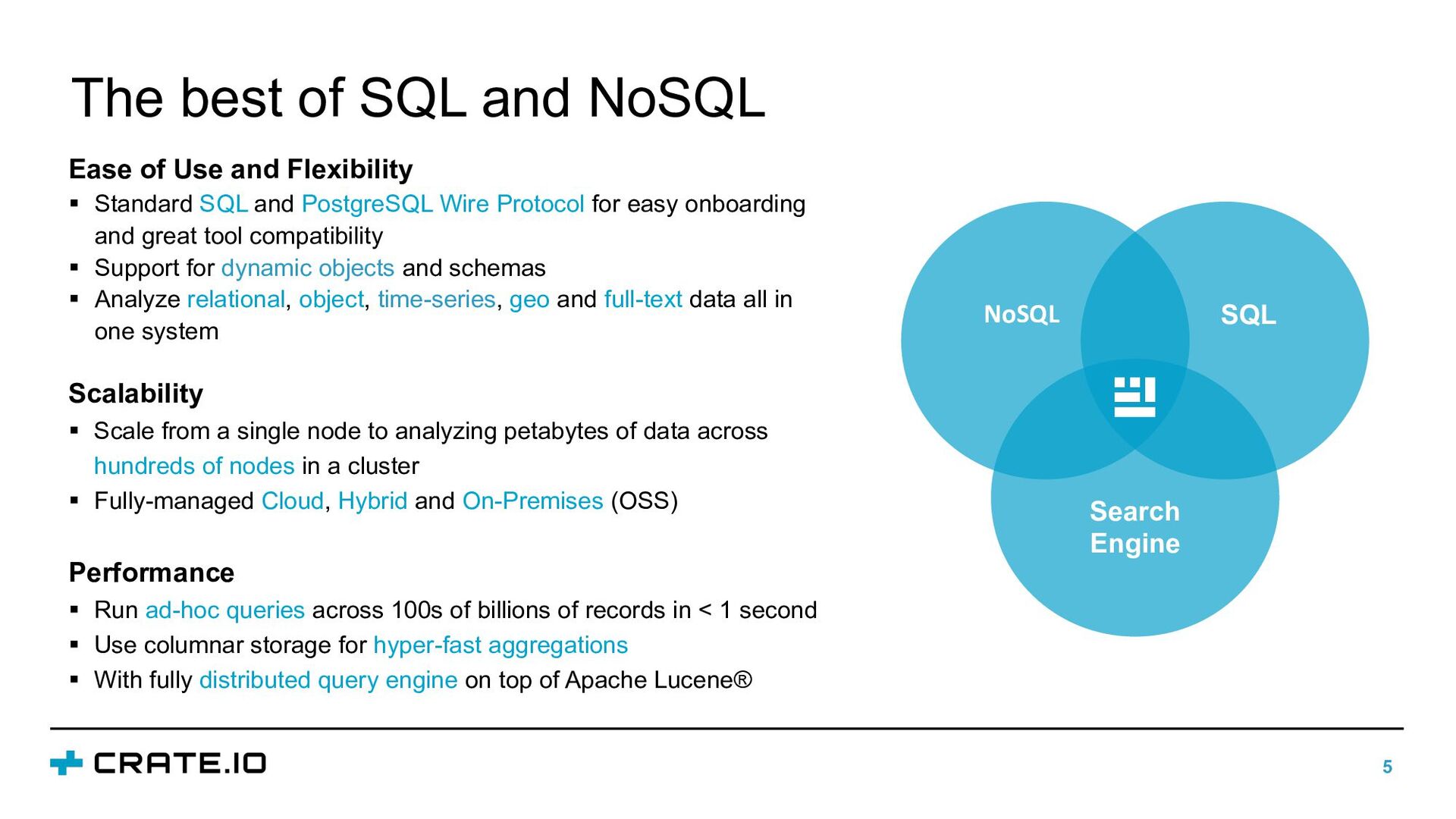
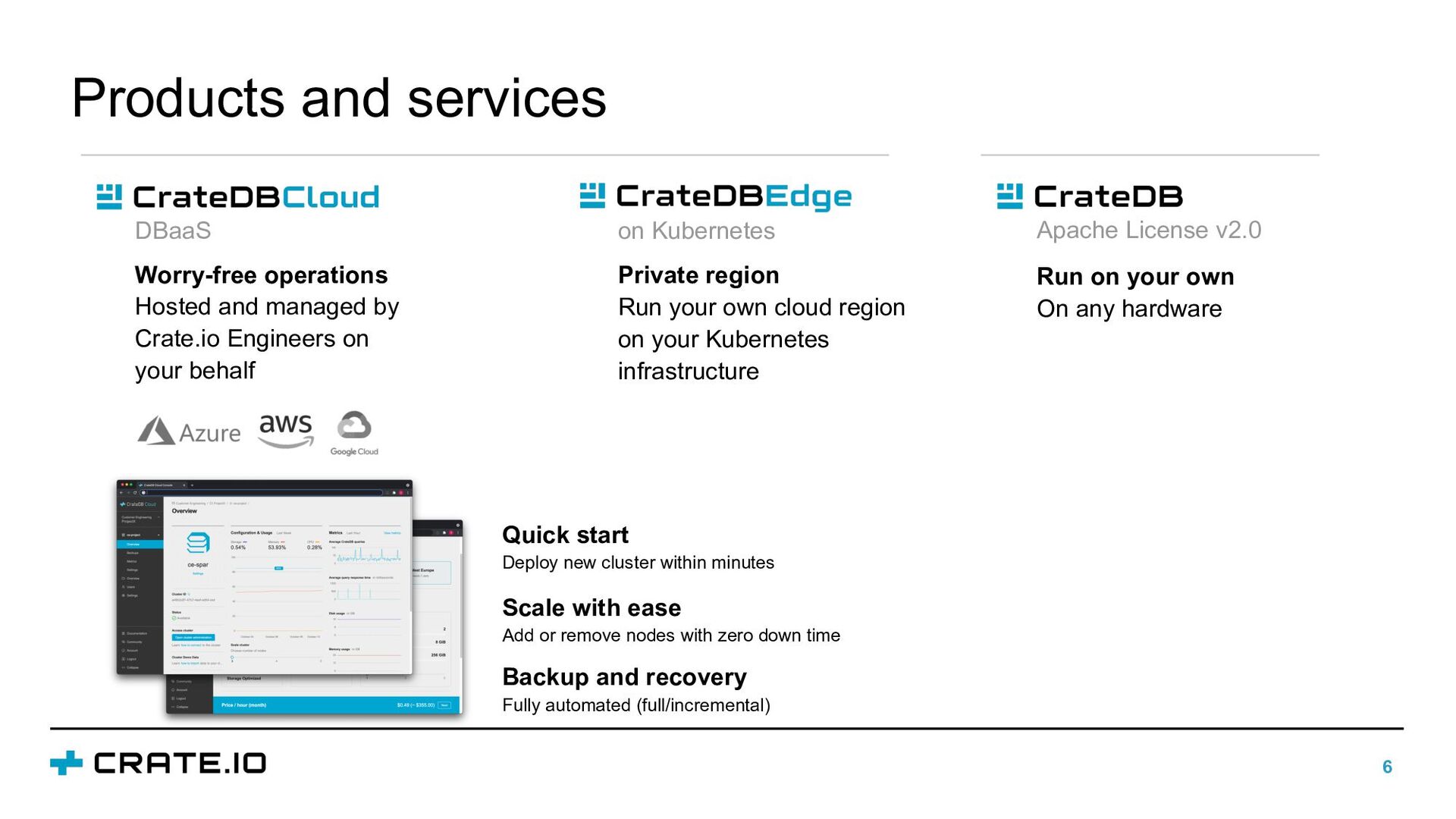
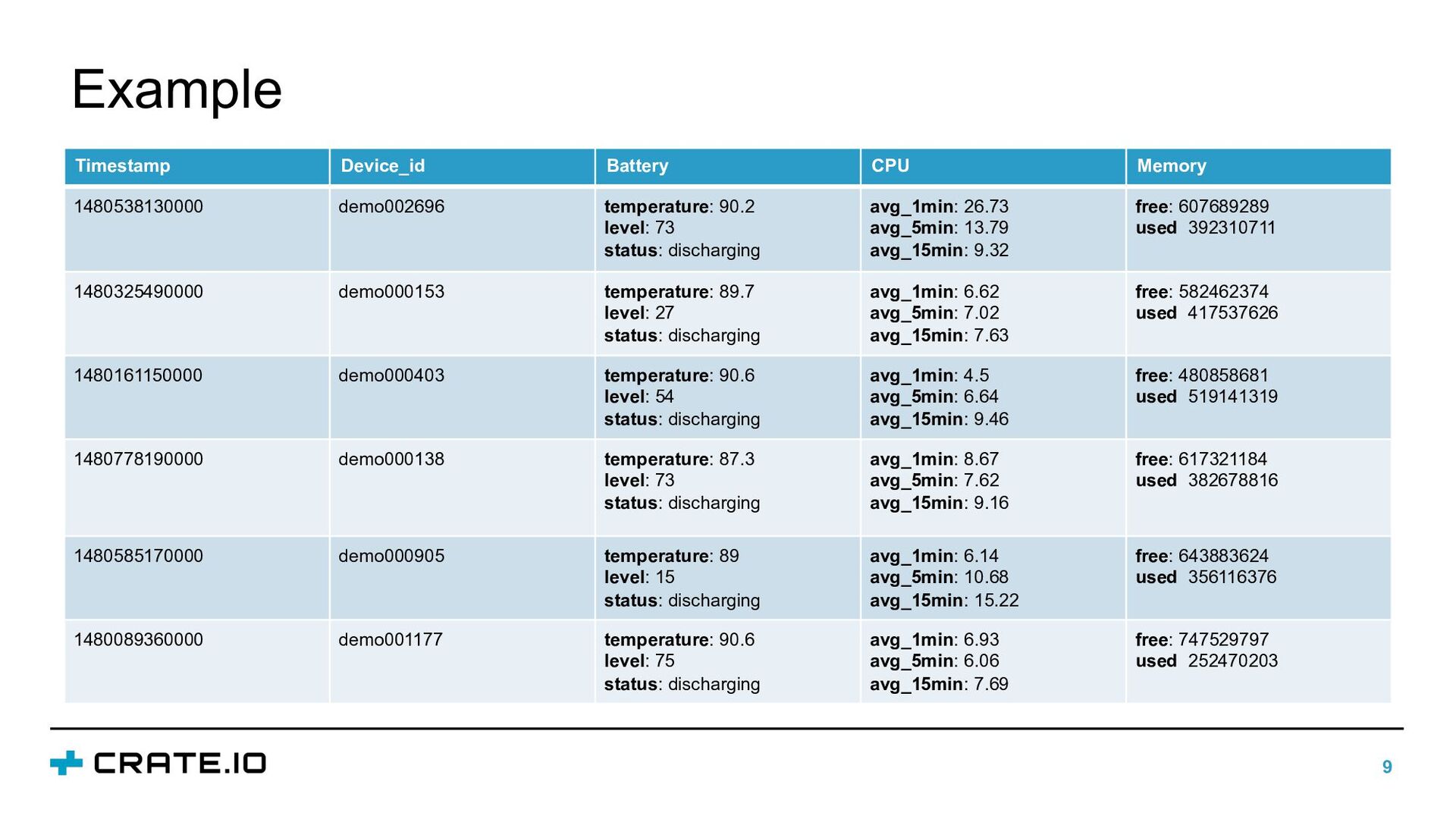
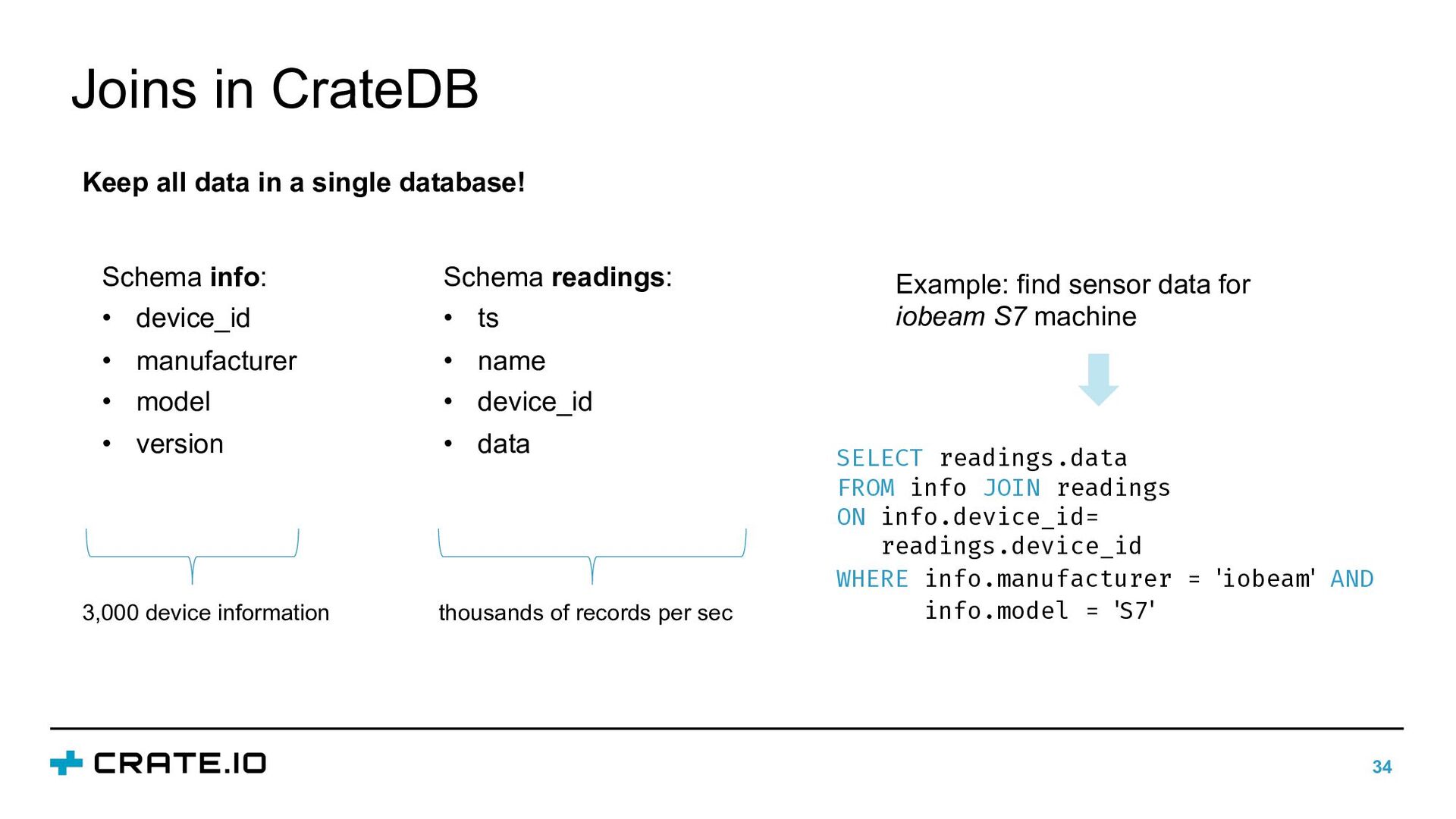
In this talk, we will discuss how different data properties affect solutions for data storage, data retention, and data integration. Furthermore, we will illustrate how the requirements for storing industrial data can be satisfied with CrateDB: an open-source, distributed database that makes storage and analysis of massive amounts of data simple and efficient.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
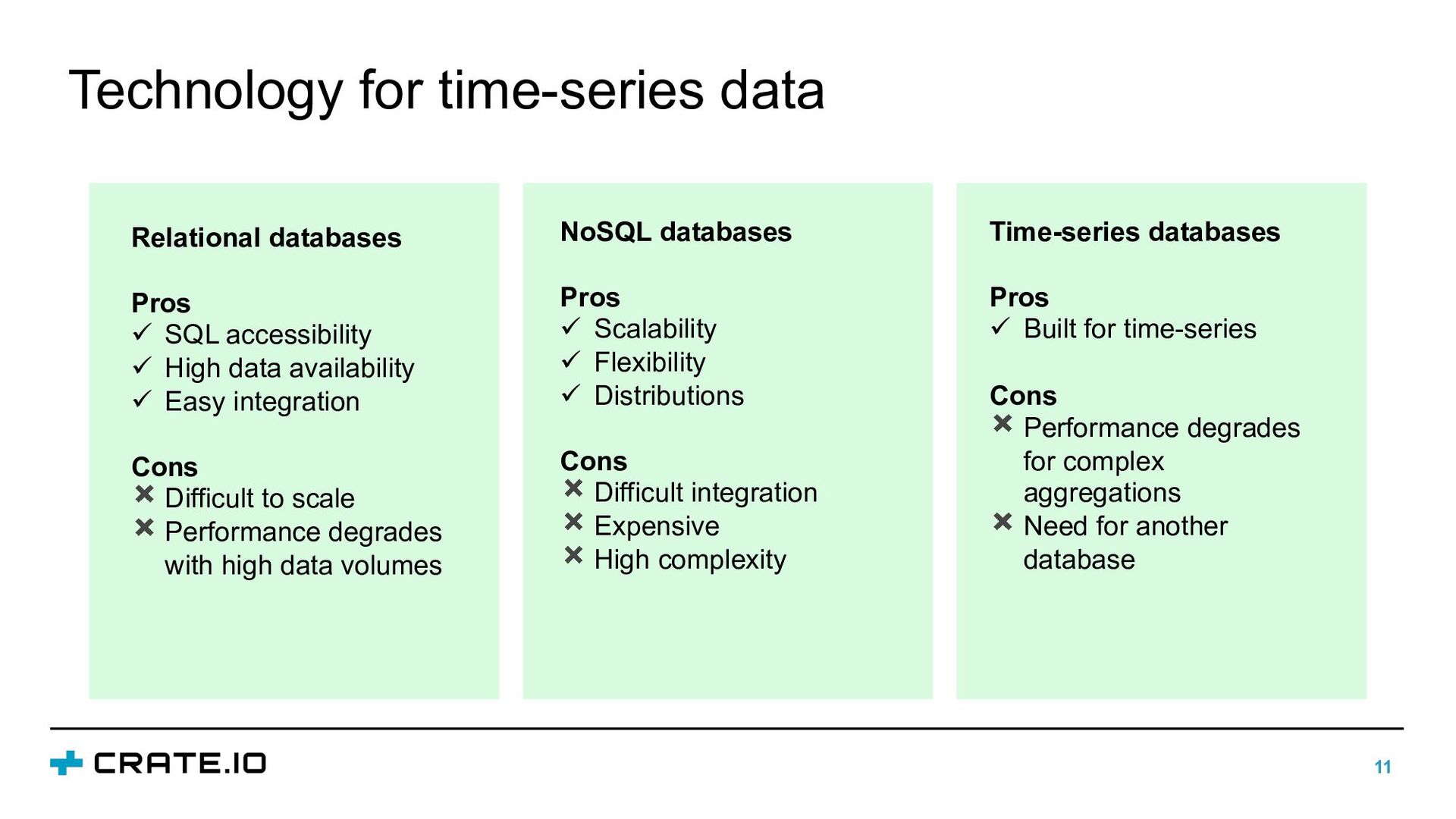{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
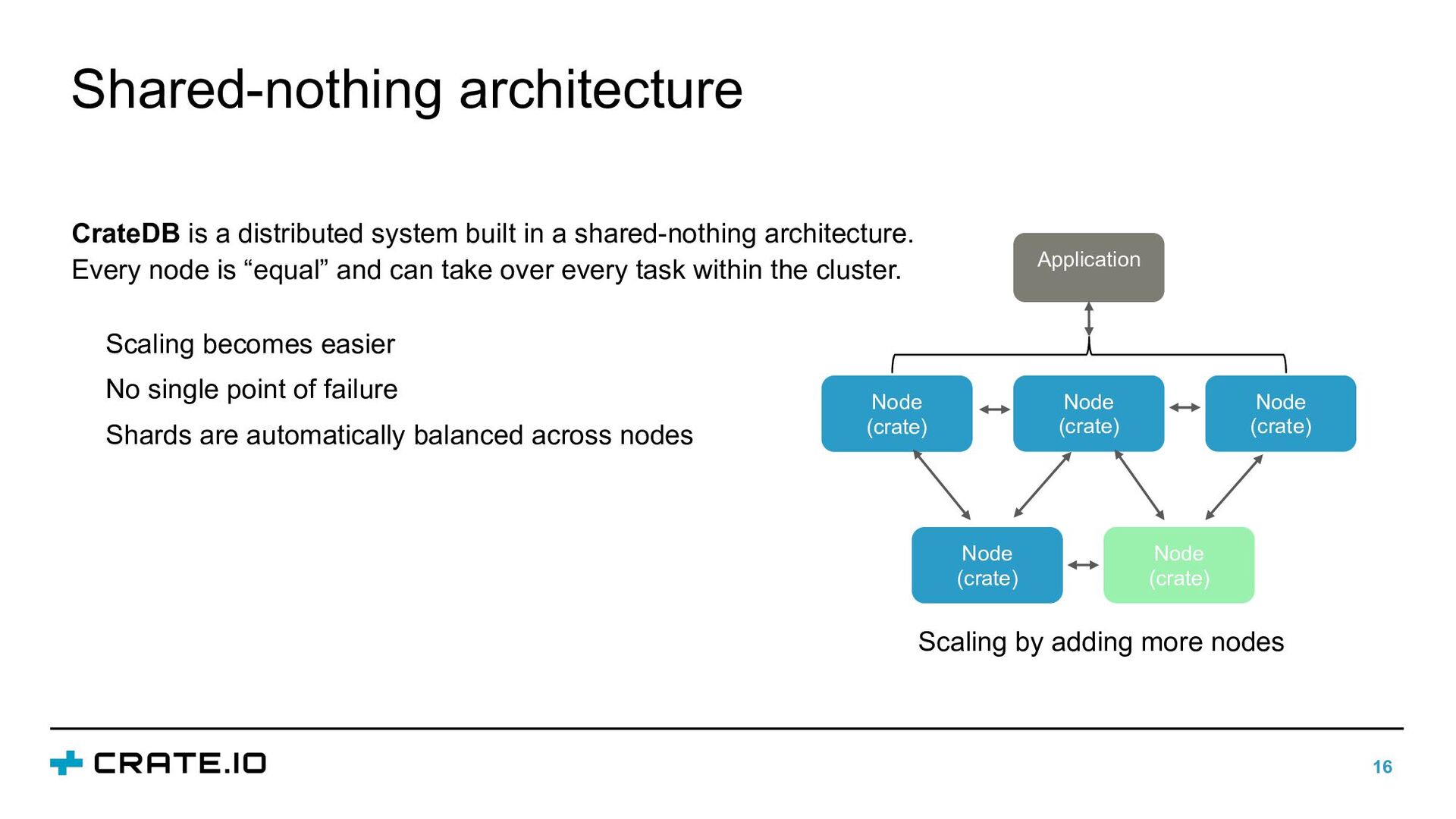{kind=link}
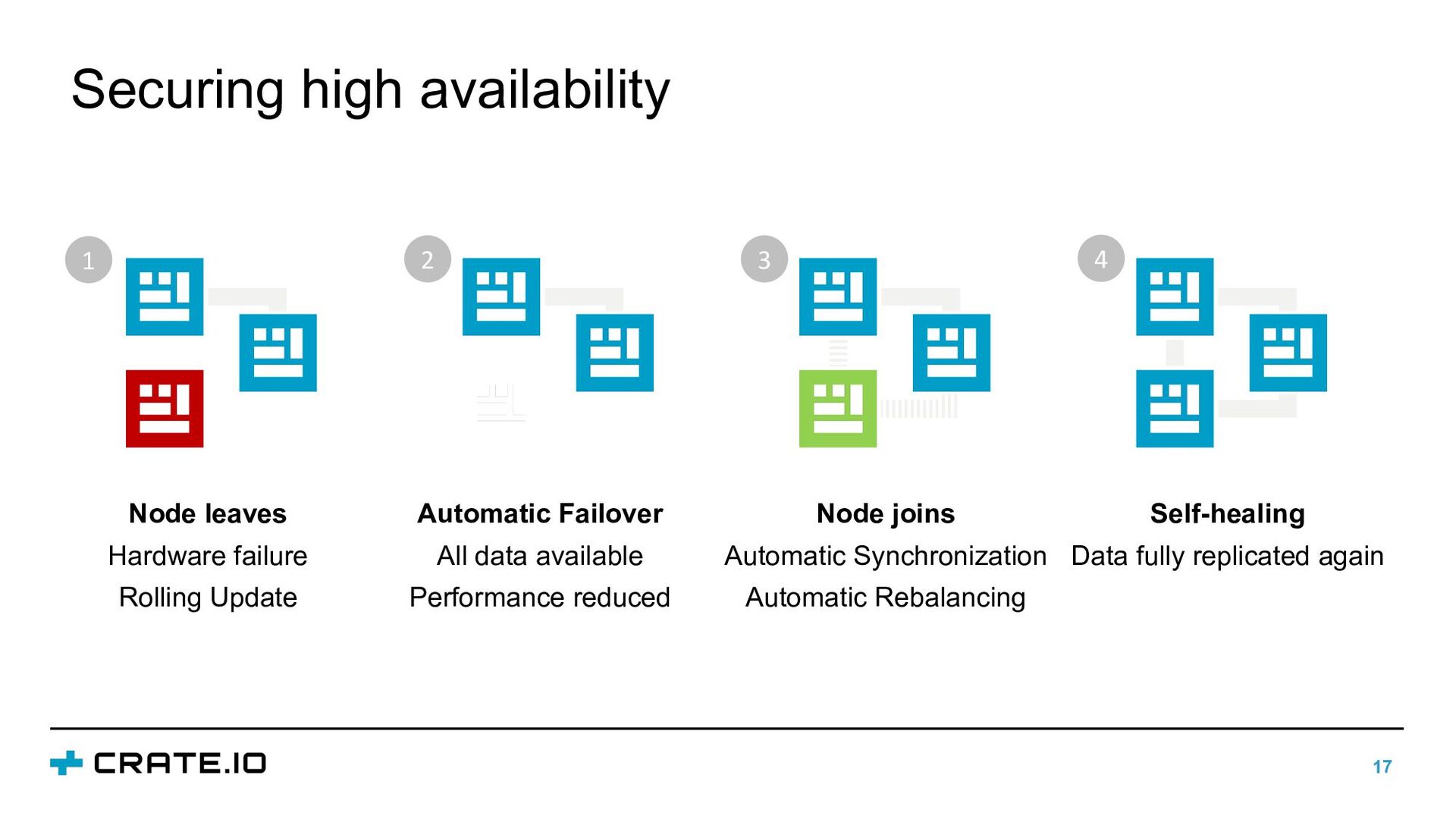{kind=link}
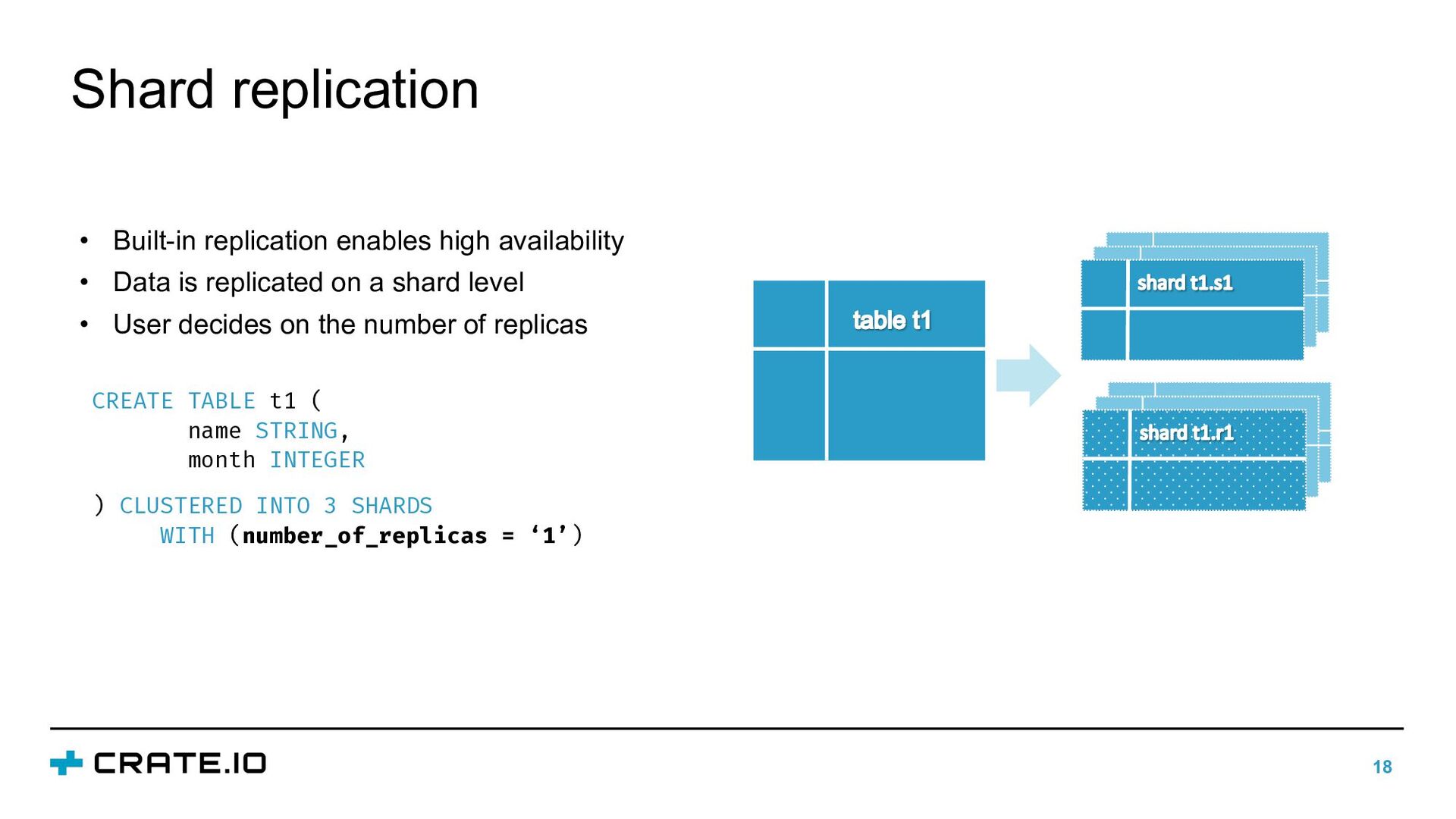{kind=link}
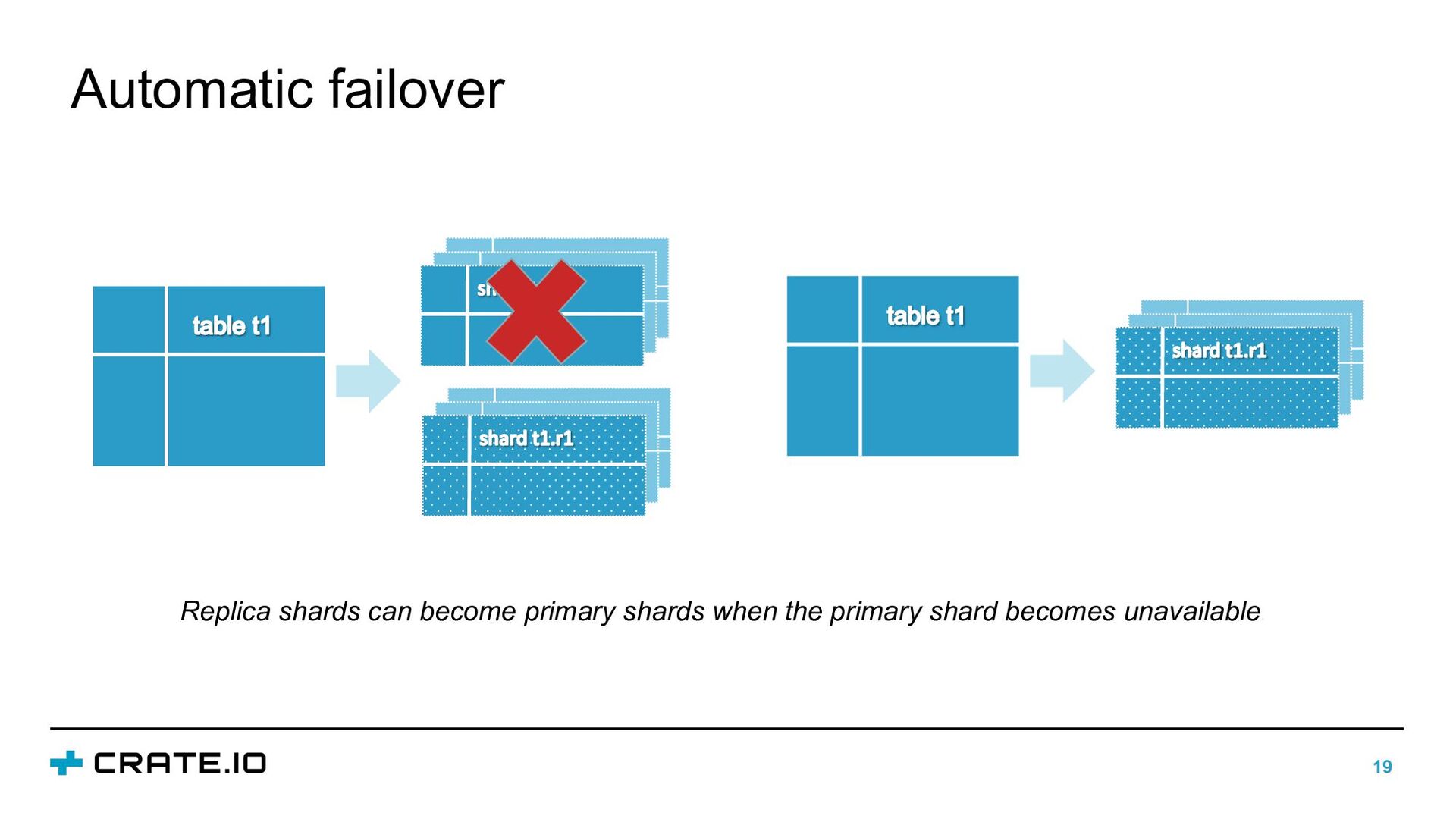{kind=link}
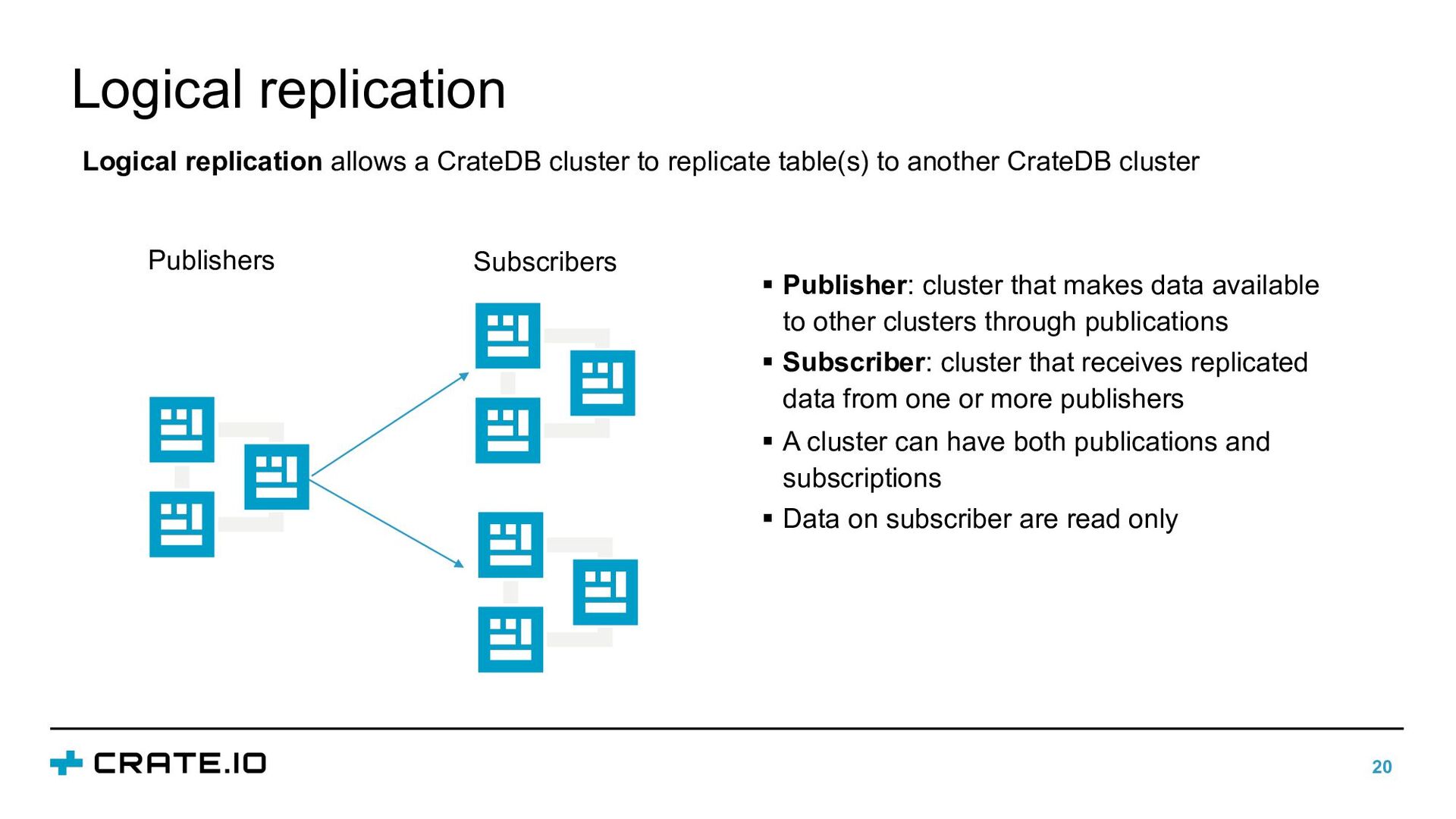{kind=link}
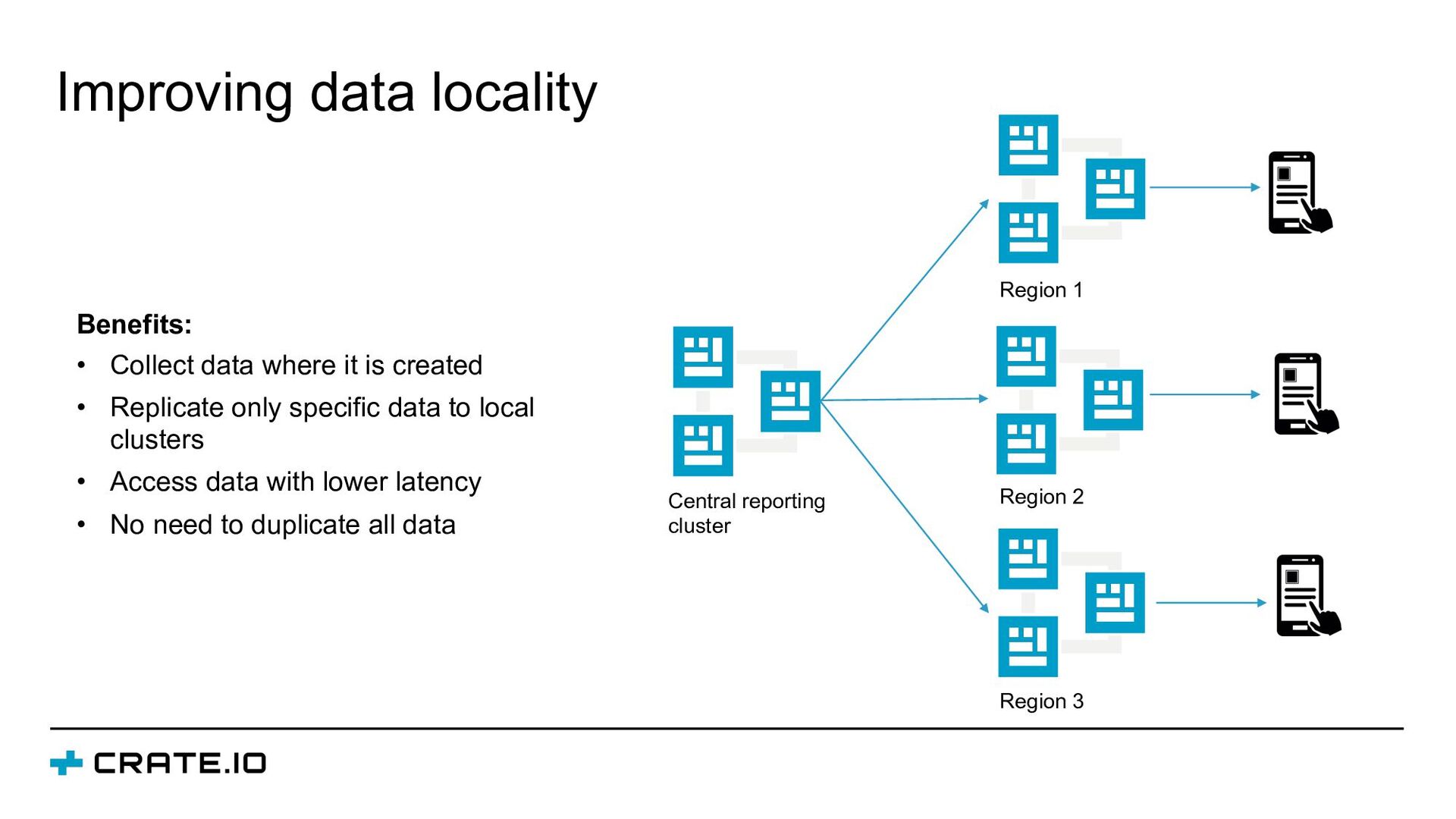{kind=link}
{kind=link}
{kind=link}
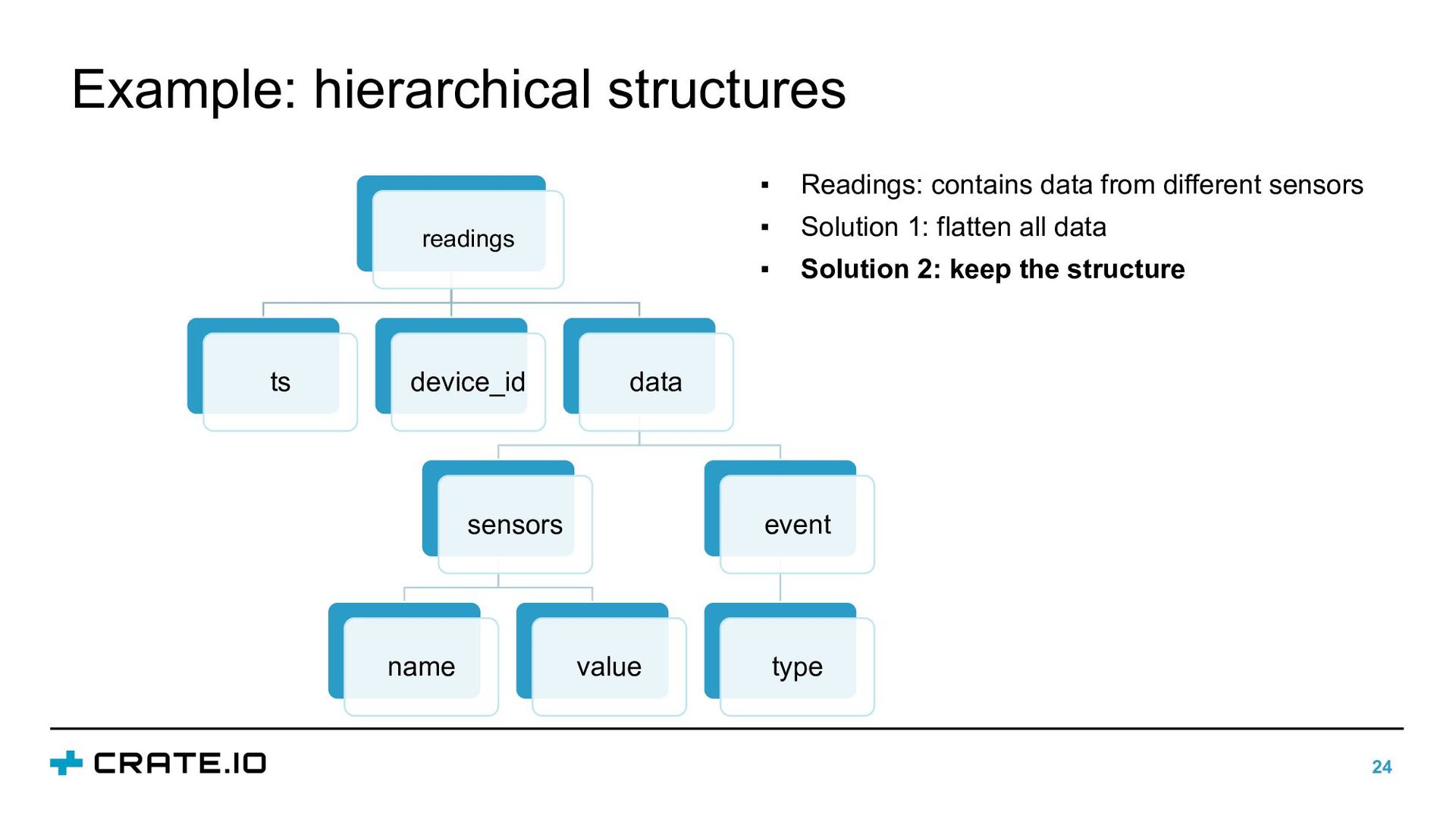{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
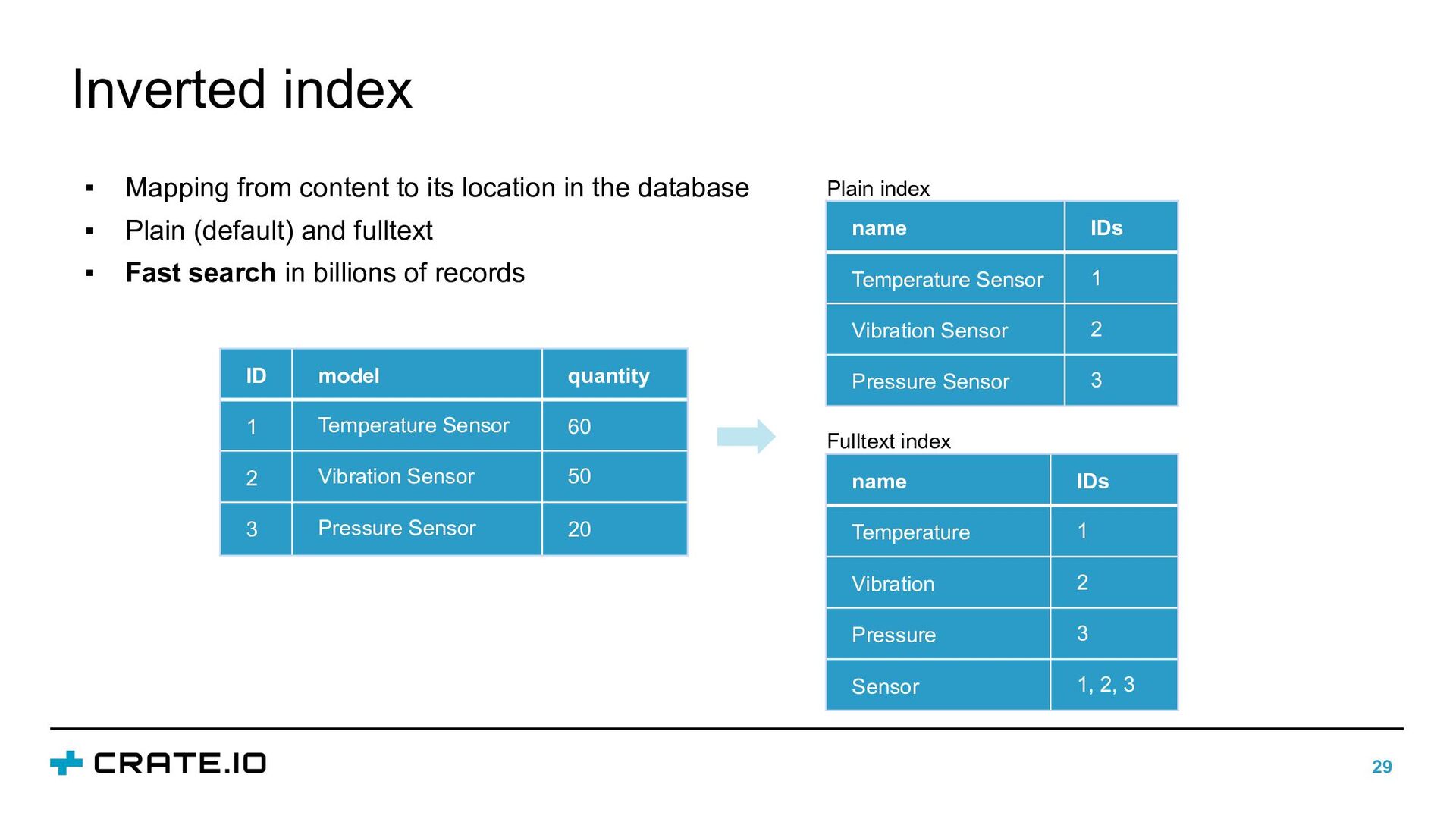{kind=link}
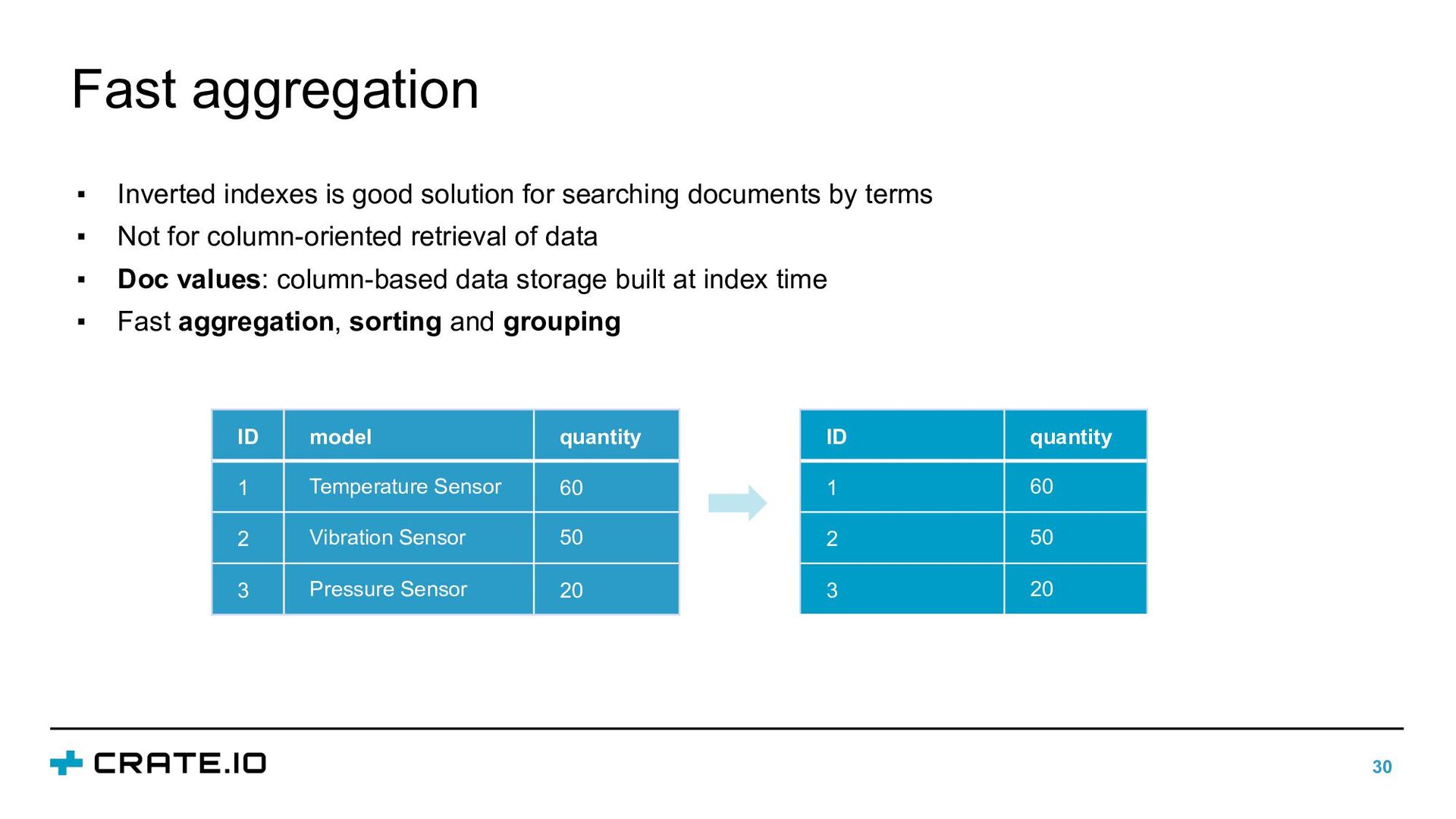{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Join our community: community.crate.io Contact: [email protected] Thank you! Contribute: https://github.com/crate/crate](https://files.speakerdeck.com/presentations/acb78531a07e4238ac662539b0c23609/slide_38.jpg){kind=link}