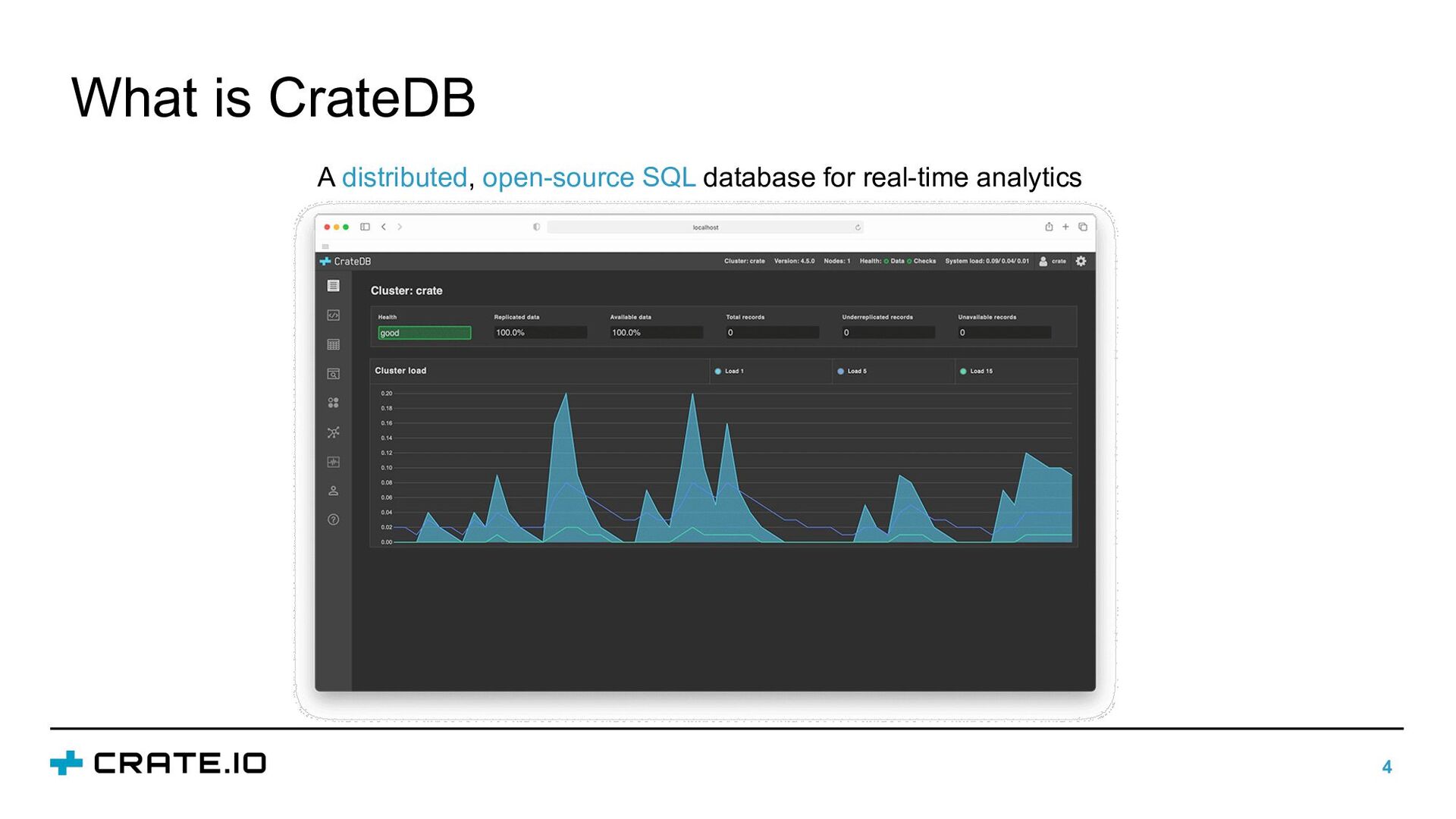
CrateDB: Distributed SQL database built on top of Lucene
Marija Selakovic, Developer Advocate at Crate.io, and Marios Trivyzas, Senior Software Engineer at Crate.io, explain CrateDB in detail as part of the Carnegie Mellon University database seminar series 2022.
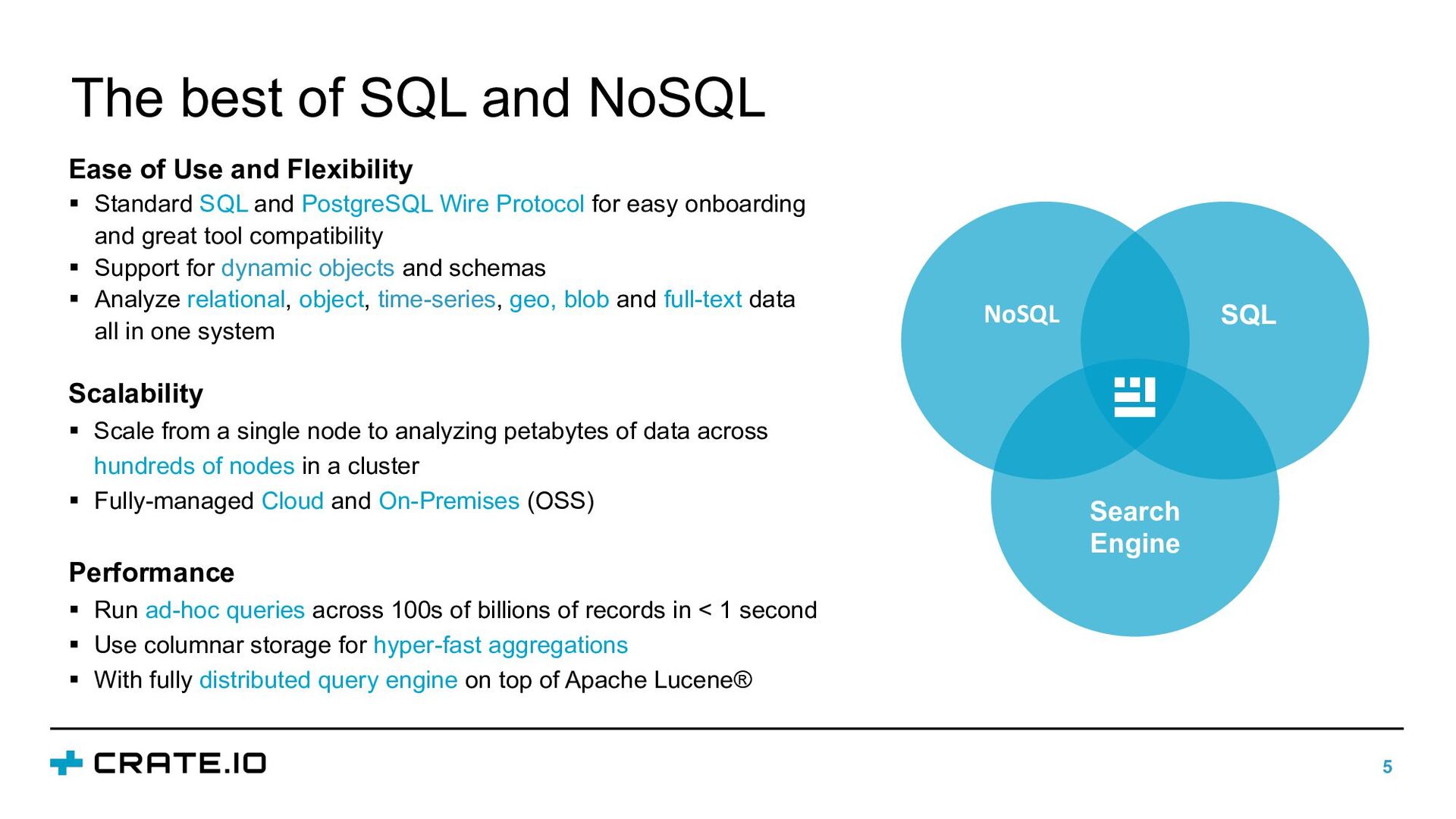
NoSQL Performance § Run ad-hoc queries across 100s of billions of records in < 1 second § Use columnar storage for hyper-fast aggregations § With fully distributed query engine on top of Apache Lucene® Ease of Use and Flexibility § Standard SQL and PostgreSQL Wire Protocol for easy onboarding and great tool compatibility § Support for dynamic objects and schemas § Analyze relational, object, time-series, geo, blob and full-text data all in one system Scalability § Scale from a single node to analyzing petabytes of data across hundreds of nodes in a cluster § Fully-managed Cloud and On-Premises (OSS)
“doc”.“readings” ( “ts” TIMESTAMP WITH TIME ZONE, “device_id” TEXT, “data” OBJECT AS ( “name” TEXT, “value” Number, ) ) • CrateDB stores data in relational format • Objects as JSON-like documents in columns • Arbitrary number of attributes and nesting levels • Also stores original document in JSON format // obj JSON { “name” : “battery”, “value” : “90.2” }
TABLE IF NOT EXISTS “doc”.“readings” ( “ts” TIMESTAMP WITH TIME ZONE, ”device_id” TEXT, ”data” OBJECT(DYNAMIC) AS ( ”sensor” OBJECT(STRICT), ”event” OBJECT(IGNORED) ) ) DYNAMIC • Highest flexibility • New columns allowed STRICT • Must follow column definition • Lowest flexibility IGNORED • Indexes columns that follow the definition • Ignores the ones that don’t
about tables, partitions, columns, constraints • System tables • sys.cluster • sys.nodes • sys.shards • sys.jobs • sys.operations • KILL job_id stops single job • KILL ALL stops every single job on each node
Fast queries and aggregations Full-text search SQL as a query language Geospatial data Logical replication Hybrid deployments High-availability and scalability Use cases not supported by CrateDB: Transactional workloads (OLTP) Highly hierarchical/normalized data models Foreign Keys
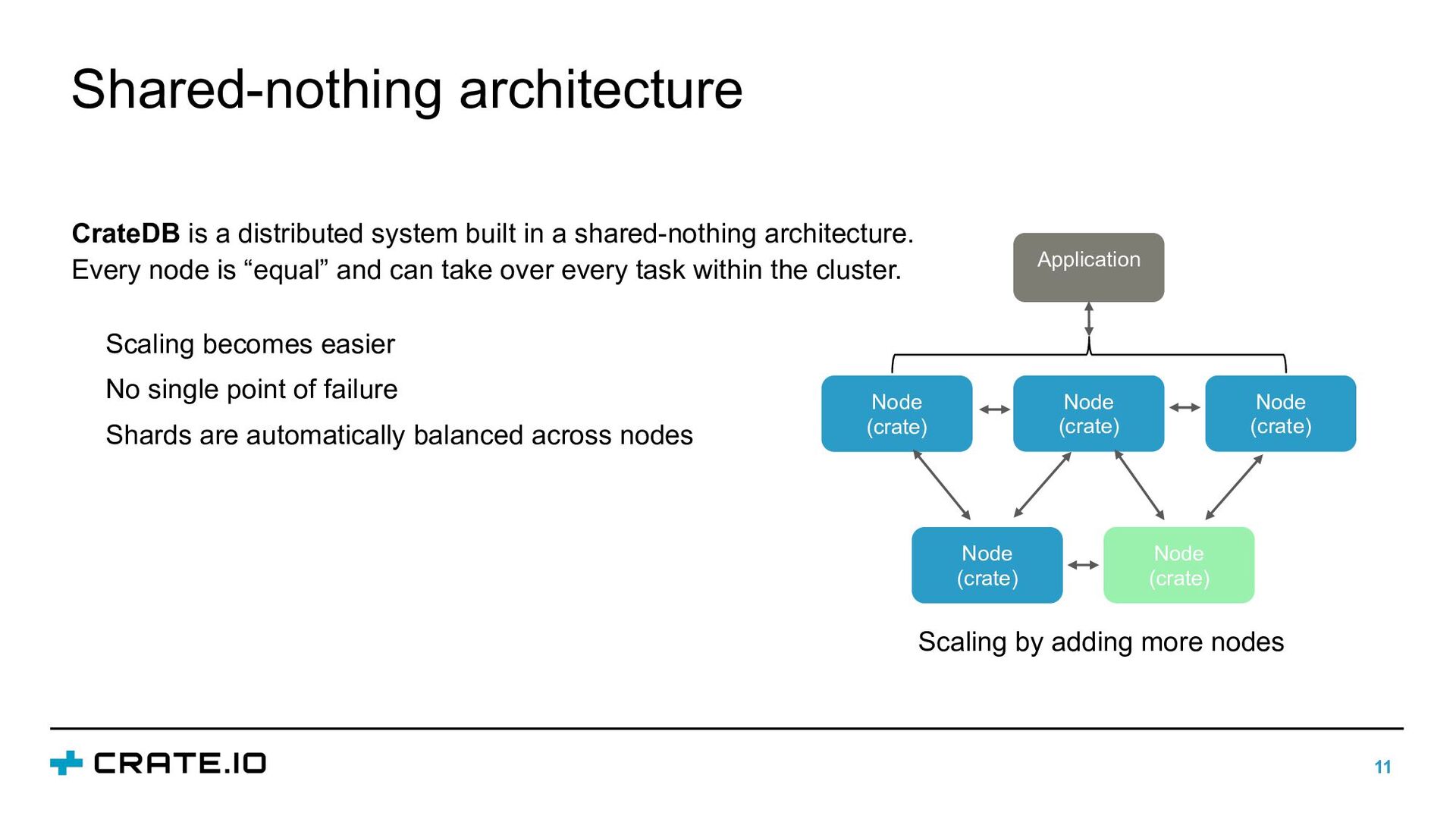
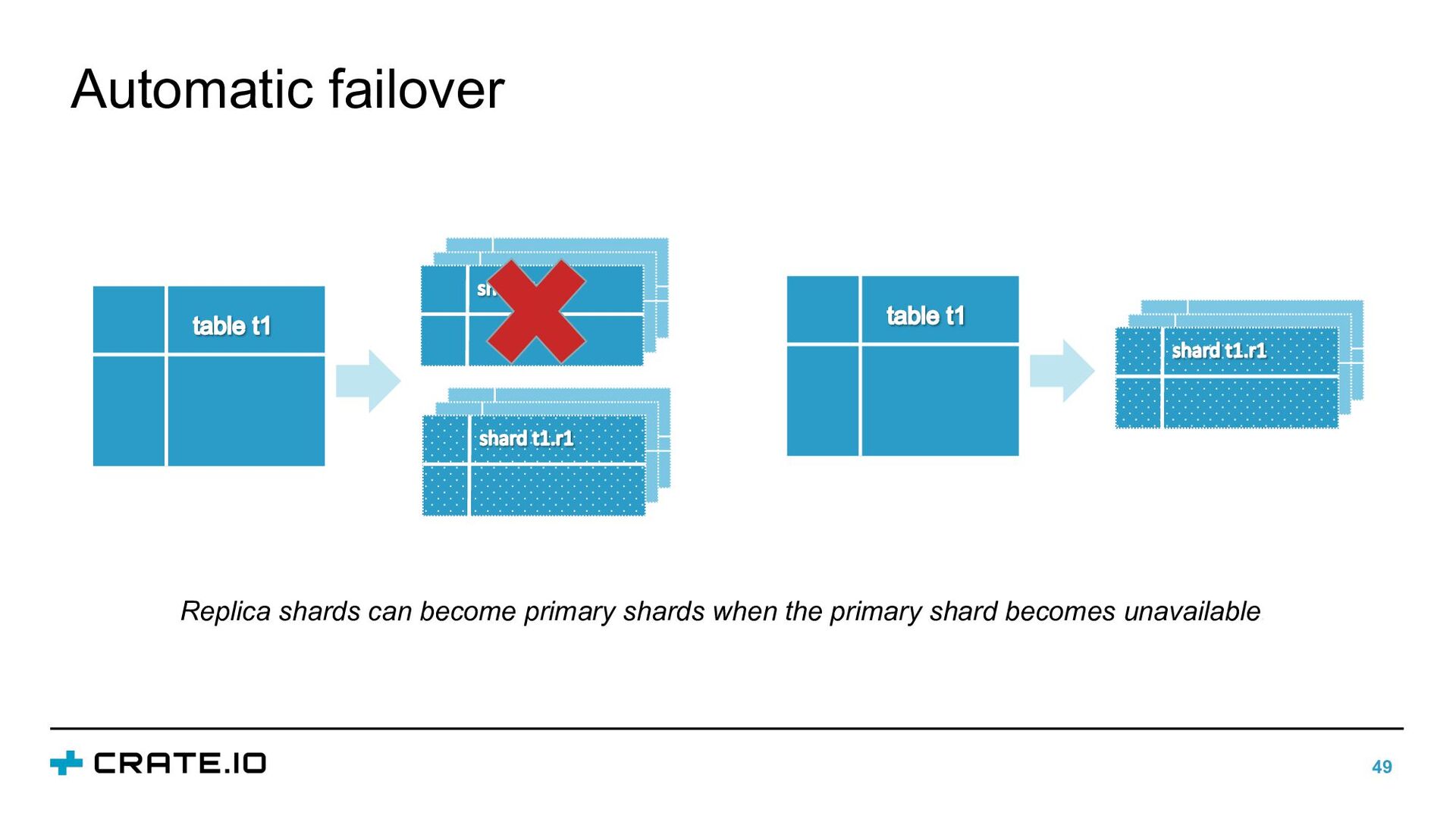
(crate) Node (crate) Application Scaling by adding more nodes CrateDB is a distributed system built in a shared-nothing architecture. Every node is “equal” and can take over every task within the cluster. Scaling becomes easier No single point of failure Shards are automatically balanced across nodes
Blob Storage Distributed Execution Engine PostgreSQL Wire Protocol HTTP Endpoint Client Client Client Client Client Parses SQL statement and creates AST Semantic processing of the statement Execution plan and optimizations Executes the plan in the cluster CrateDB node
of the supported protocols (PostgreSQL, HTTP, Transport) • The encryption protocol is TLSv1.2 • Configuration via host-based authentication • For the transport protocol, trust and cert are valid authentication methods • If enabled, transport protocol encryption applies to the whole cluster
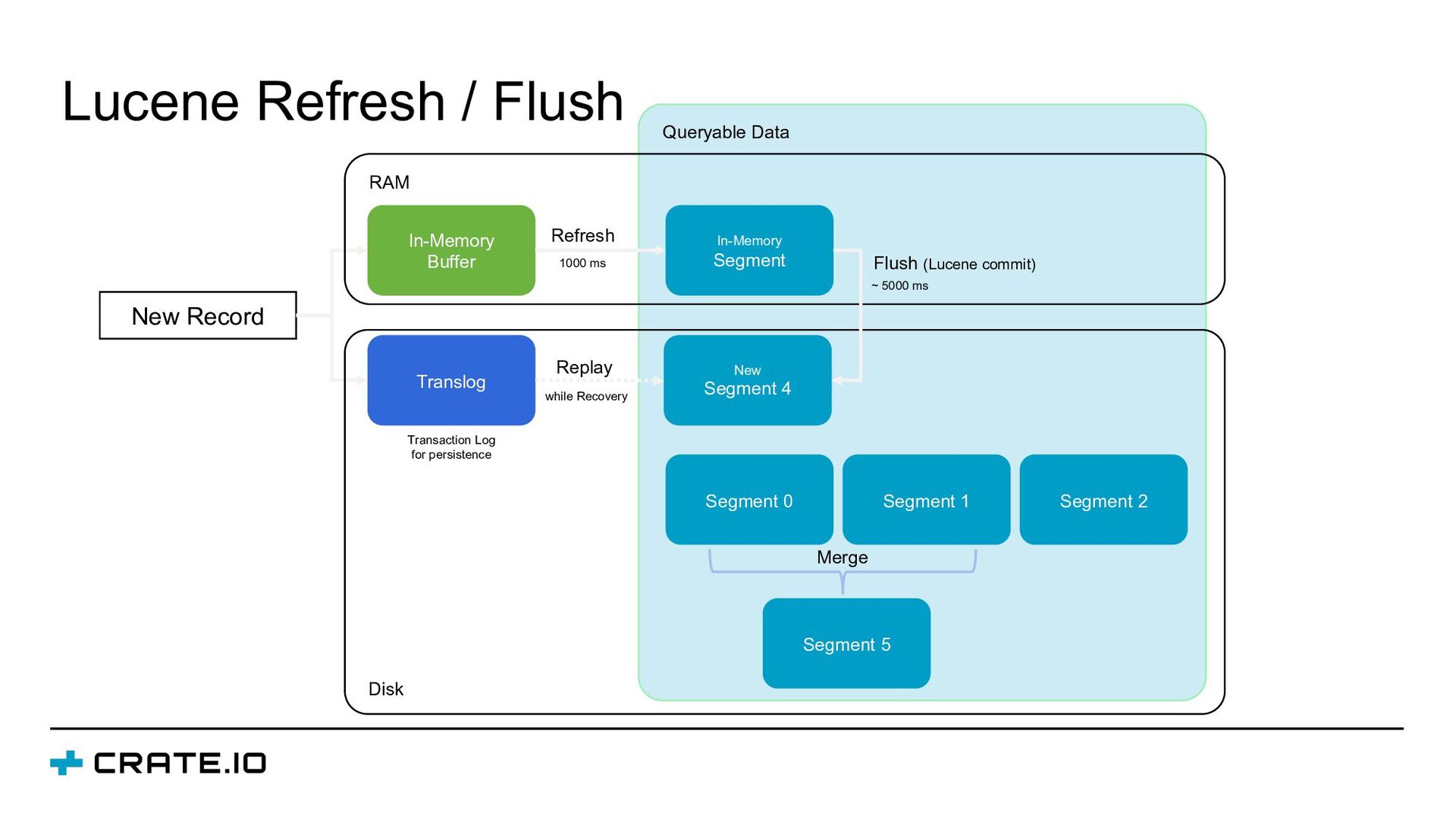
storage engine ▪ Indexing strategy based on Lucene: o Inverted index for text values o Block KD-Trees for numerical values (including timestamps, geo-points, geo- shapes, etc.) ▪ Column-based data storage is built for more effective sorting and aggregations. Known as doc values. ▪ Doc values are enabled per default and currently can be disabled only for text fields
tokens, which are then searched ▪ Consists of: o Tokenizer o Zero or more token filters o Zero or more char filters The quick brown fox jumps Over the lAzY DOG. quick, brown, fox, jumps, lazy, dog Standard analyzer: o standard tokenizer o lowercase filter o stop token filter
in the database ▪ Plain (default) and fulltext ▪ Fast search in billions of records ID model quantity 1 Almond Milk 60 2 Almond Flour 50 3 Milk 20 name IDs Almond 1, 2 Milk 1, 3 Flour 2 name IDs Almond Milk 1 Almond Flour 2 Milk 3 Fulltext index Plain index
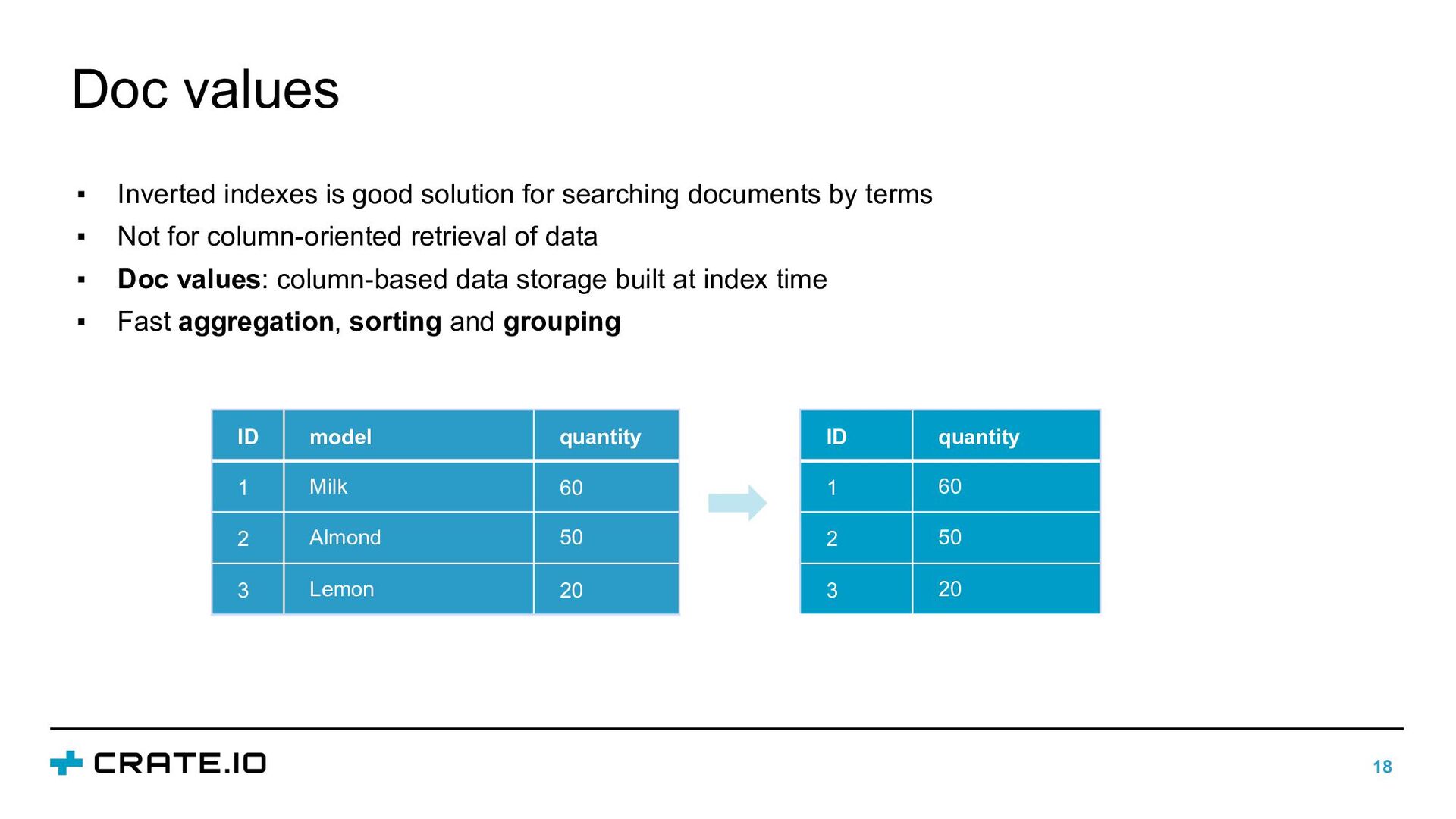
searching documents by terms ▪ Not for column-oriented retrieval of data ▪ Doc values: column-based data storage built at index time ▪ Fast aggregation, sorting and grouping ID model quantity 1 Milk 60 2 Almond 50 3 Lemon 20 ID quantity 1 60 2 50 3 20
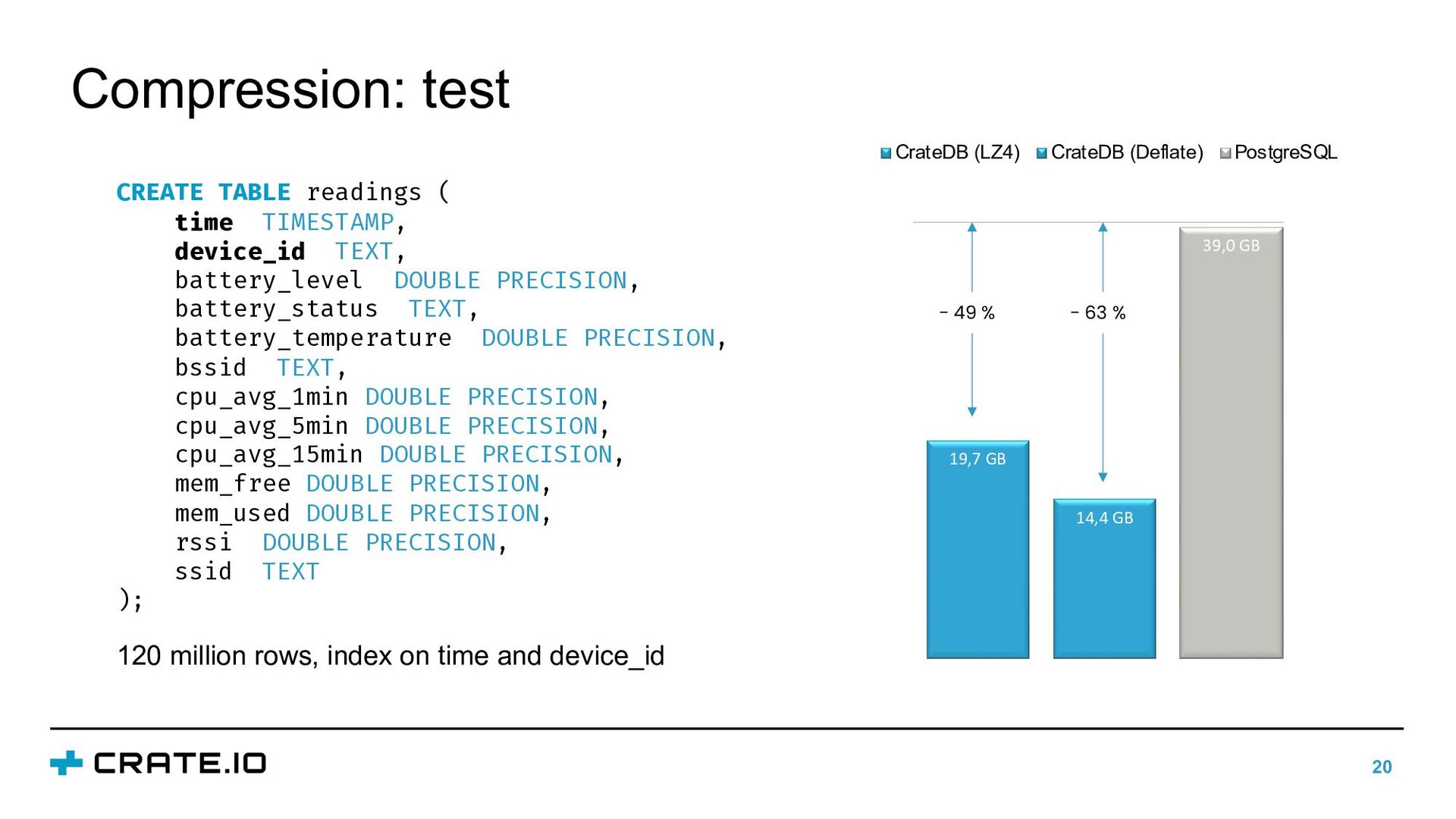
LZ4 (default): Good tradeoff between storage efficiency and query performance • Deflate: More aggressive compression at the cost of query performance • Doc values are delta-encoded, bit-packing and GCD compressed
FROM users WHERE age = 30) AS n WHERE n.name = 'foo'; Rename[name] AS n └ Collect[doc.users | [name] | ((name = 'foo') AND (age = 30)) Two predicates got merged to reduce the number of rows to be collected
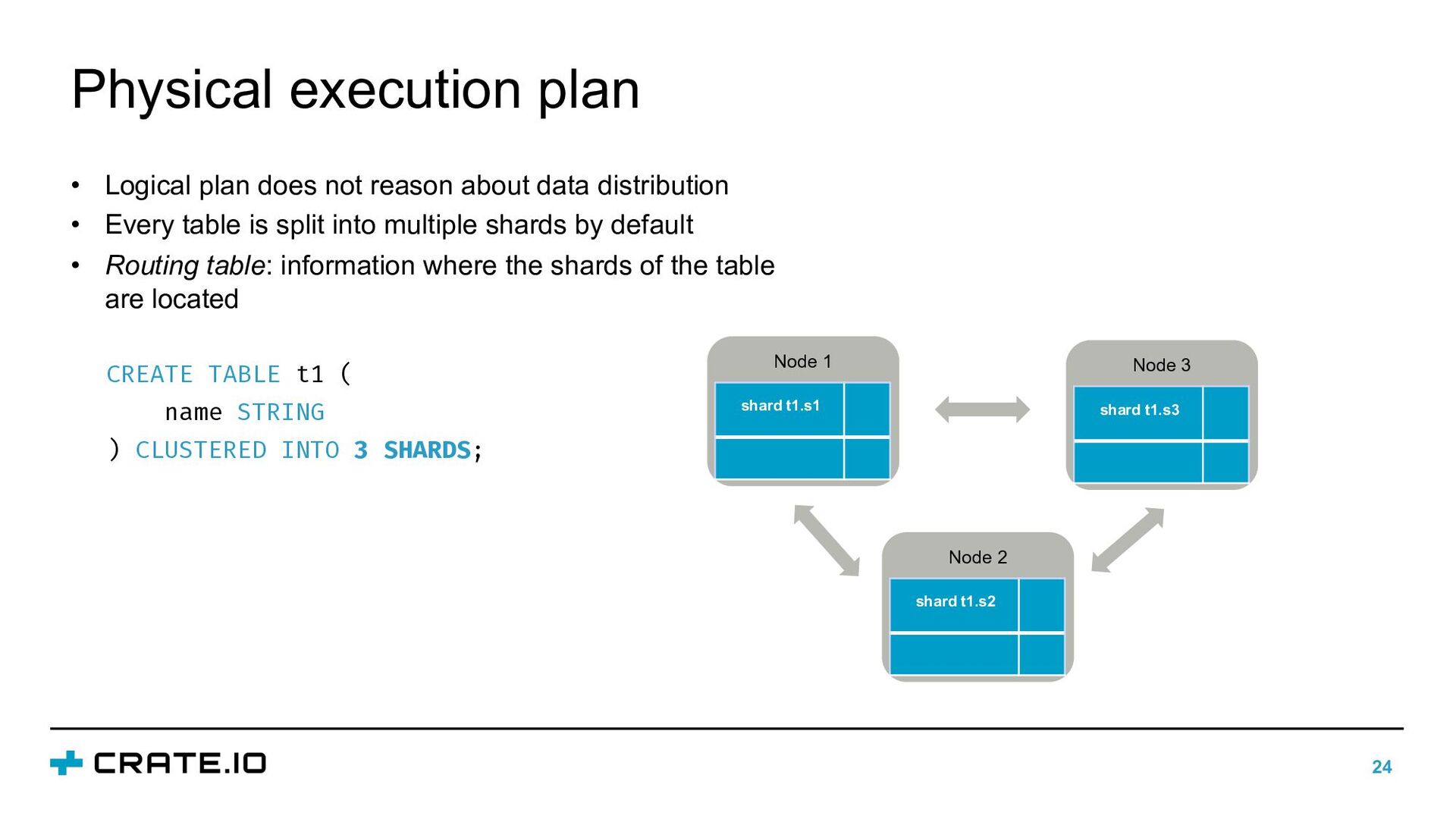
about data distribution • Every table is split into multiple shards by default • Routing table: information where the shards of the table are located CREATE TABLE t1 ( name STRING ) CLUSTERED INTO 3 SHARDS; Node 3 shard t1.s3 Node 2 shard t1.s2 Node 1 shard t1.s1
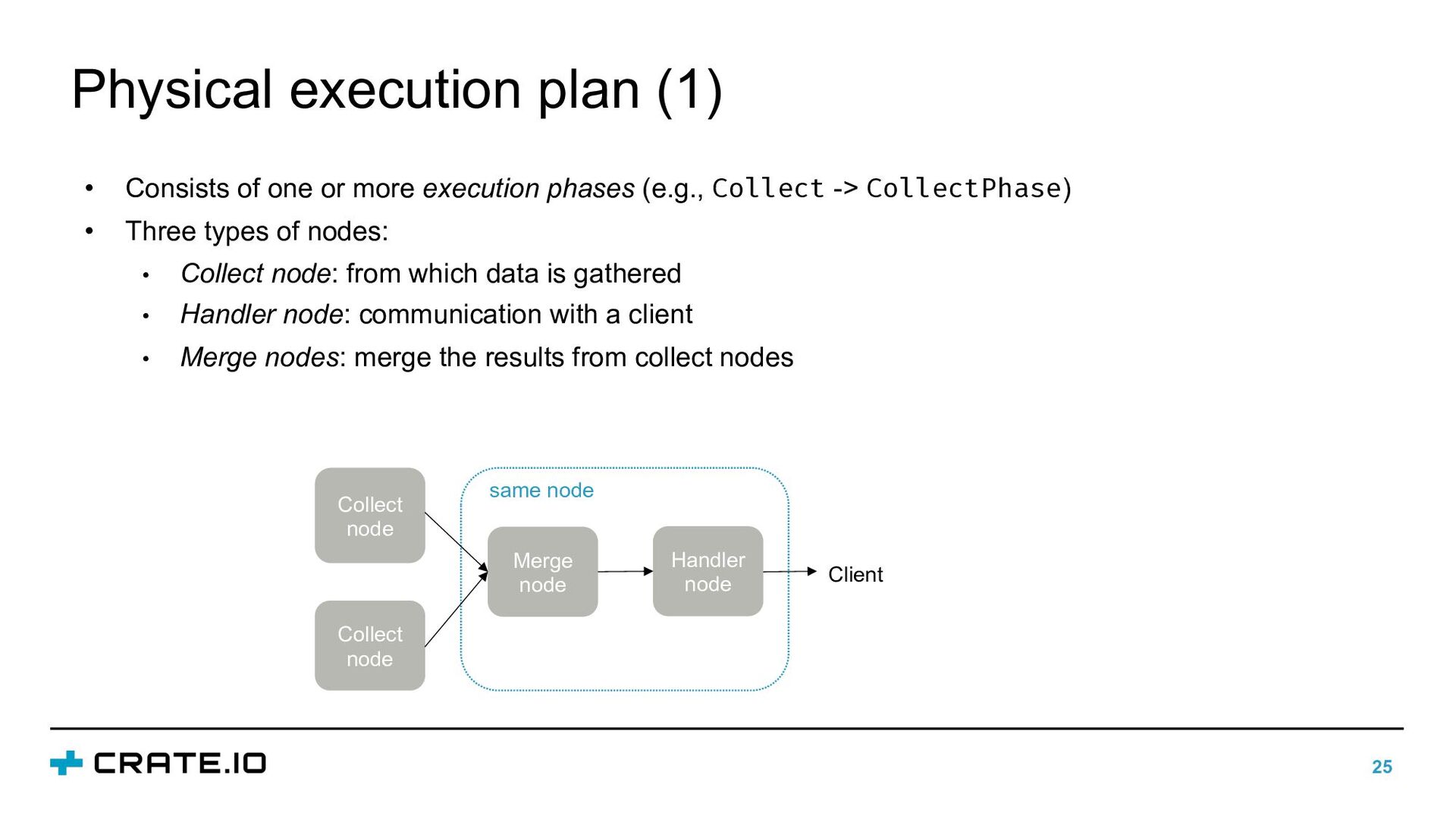
more execution phases (e.g., Collect -> CollectPhase) • Three types of nodes: • Collect node: from which data is gathered • Handler node: communication with a client • Merge nodes: merge the results from collect nodes Collect node Collect node Merge node Handler node Client same node
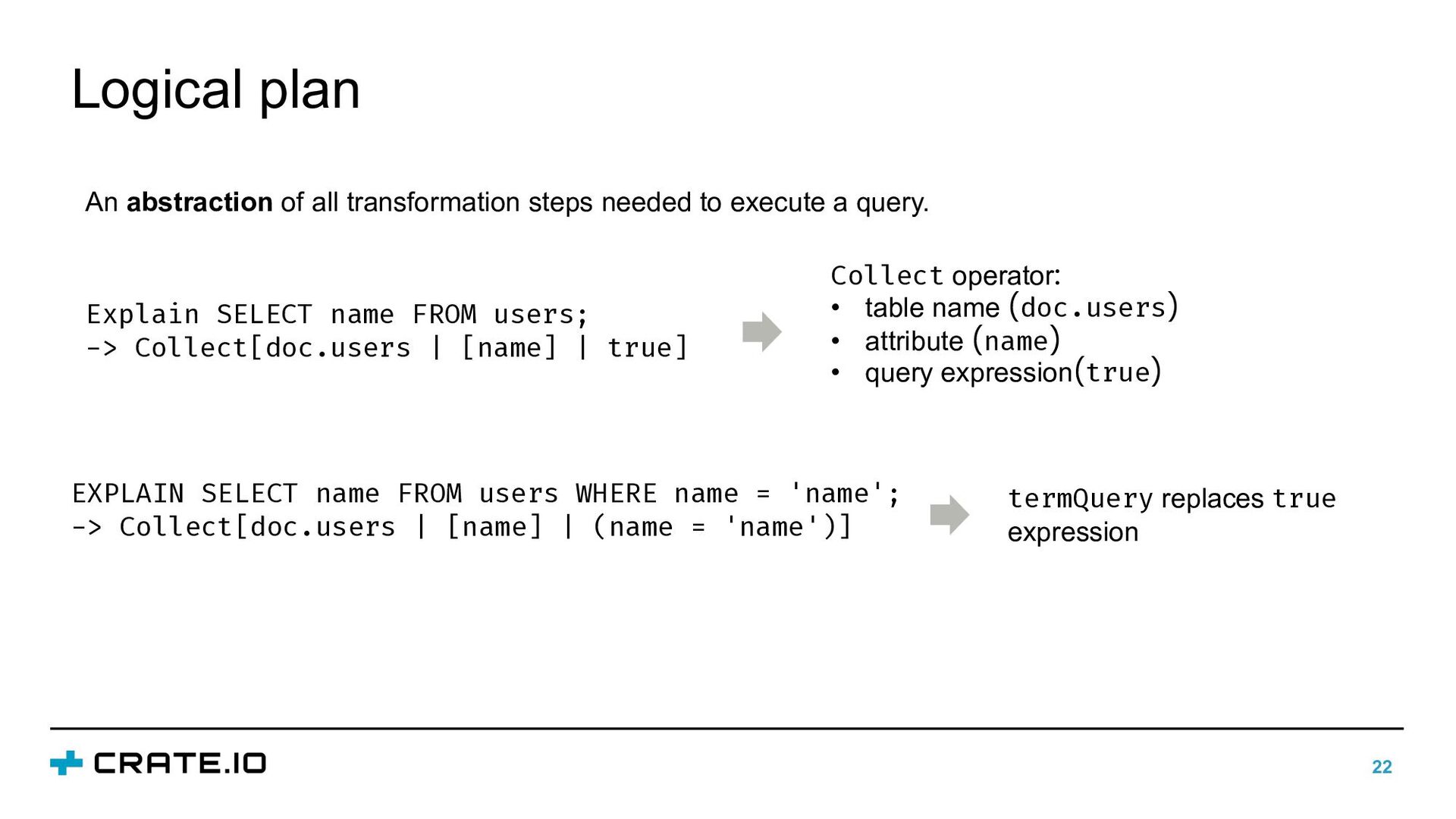
-> Collect[doc.users | [name] | true] RoutedCollectPhase: toCollect: [Ref{name}] routing: node-0: users: [0, 1] node-1: users: [2, 3] MergePhase: executionNodes: [node-0] numUpstreams: 2 Logical plan Physical execution plan attribute name nodes that should be queried shard ids of the tables handler node: node that merges data
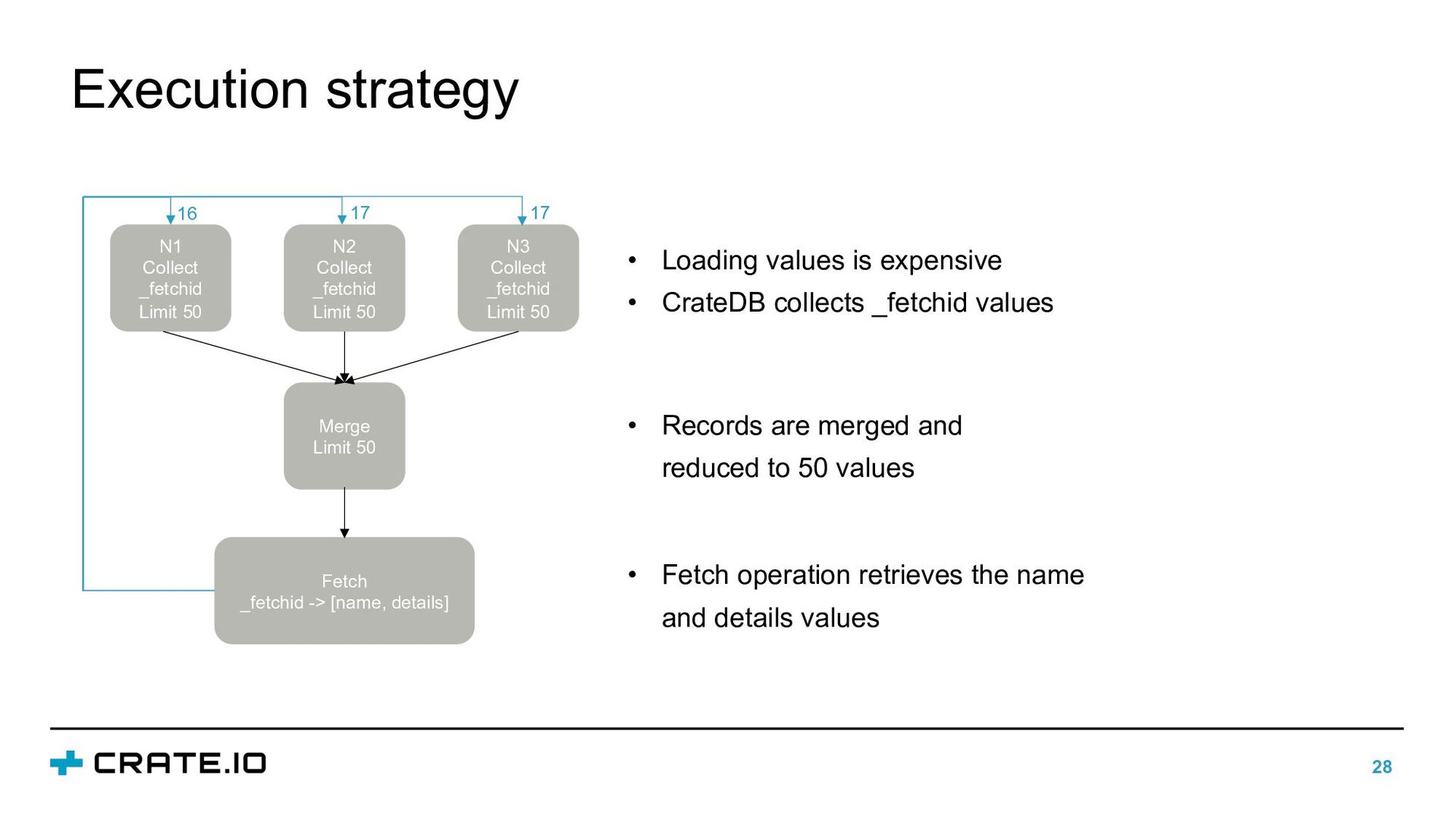
FROM users WHERE name LIKE 'A%' ORDER BY id LIMIT 50 Eval[name, age] └ Fetch[name, age, id] └ Limit[50::bigint;0] └ OrderBy[id ASC] └ Collect[doc.users | [_fetchid, id] | (name LIKE 'A%')] Logical plan • _fetchid: system column used to fetch values of other attributes • Fetch operator: returns one or more _fetchid columns • Limit operator: limits the output to at most 50 records • OrderBy operator: returns the _fetchids ordered by id column
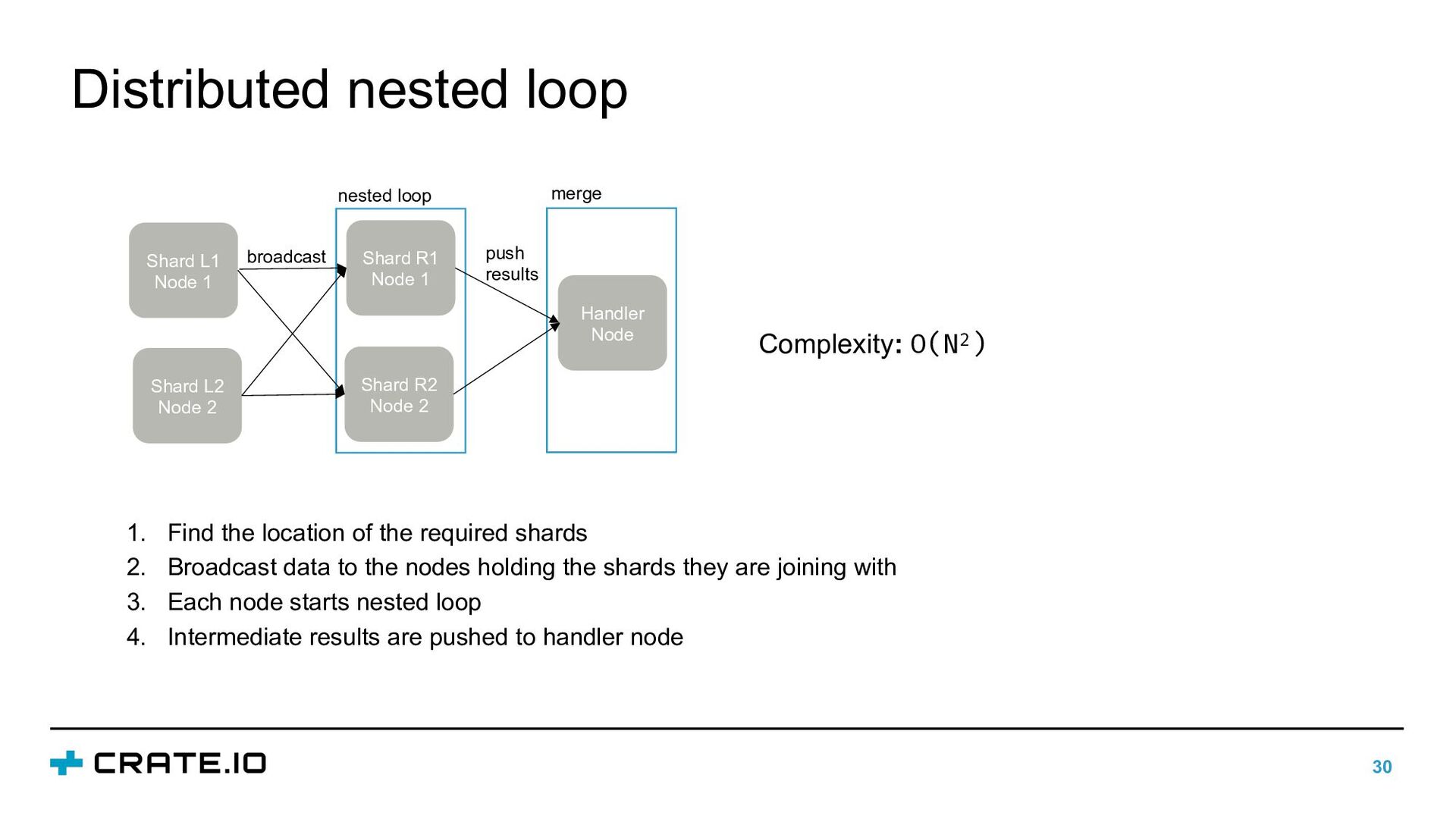
L do for each tuple r ∈ R do if l.a Θ r.b put tuple(l, r) in Q • Default algorithm: nested loop • Each tuple in inner relation is compared with each tuple in outer relations • For some tables, nested loop can be executed on the handler node
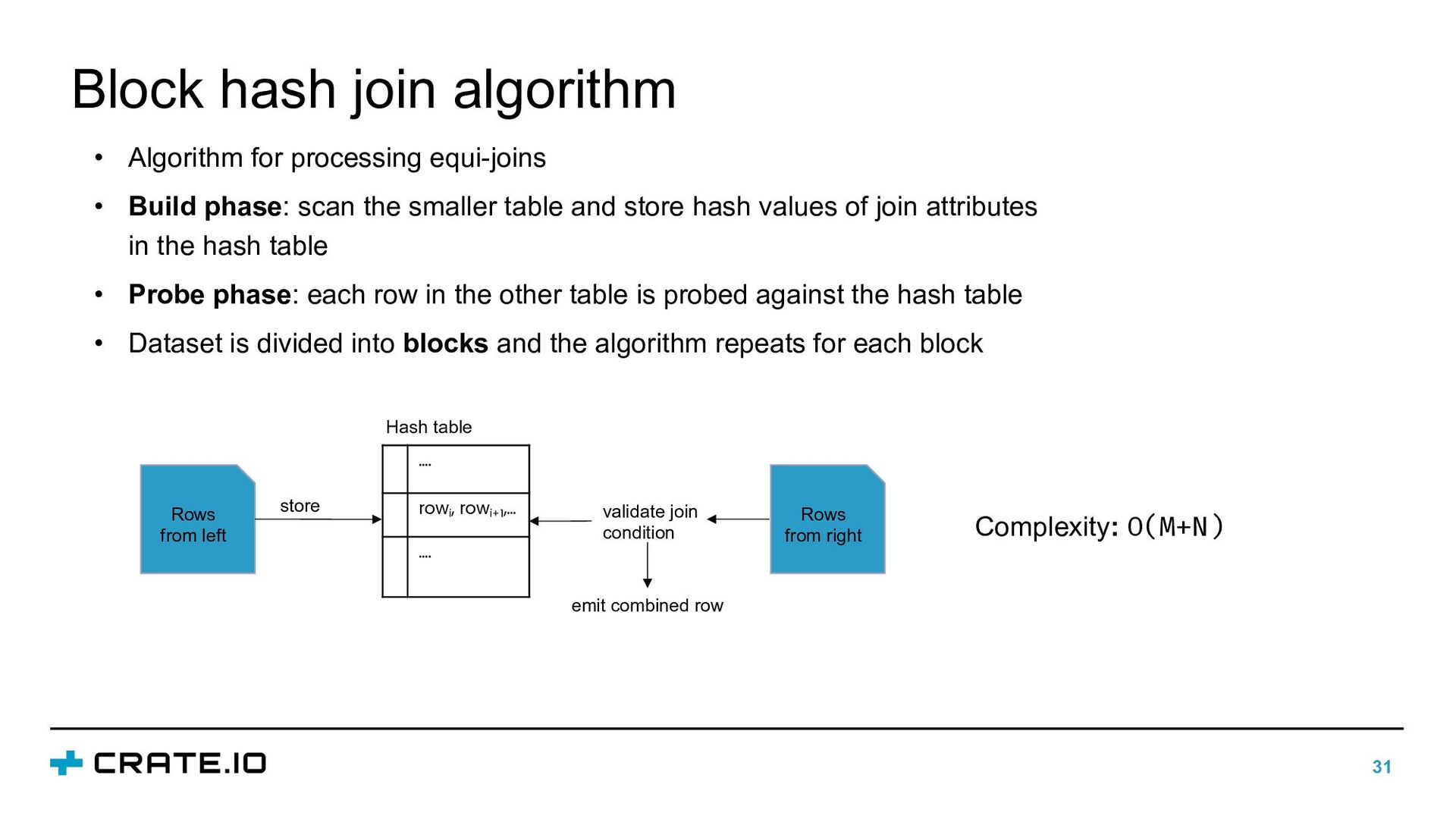
• Build phase: scan the smaller table and store hash values of join attributes in the hash table • Probe phase: each row in the other table is probed against the hash table • Dataset is divided into blocks and the algorithm repeats for each block …. rowi , rowi+1 ,… …. Rows from left store Hash table Rows from right validate join condition emit combined row Complexity: O(M+N)
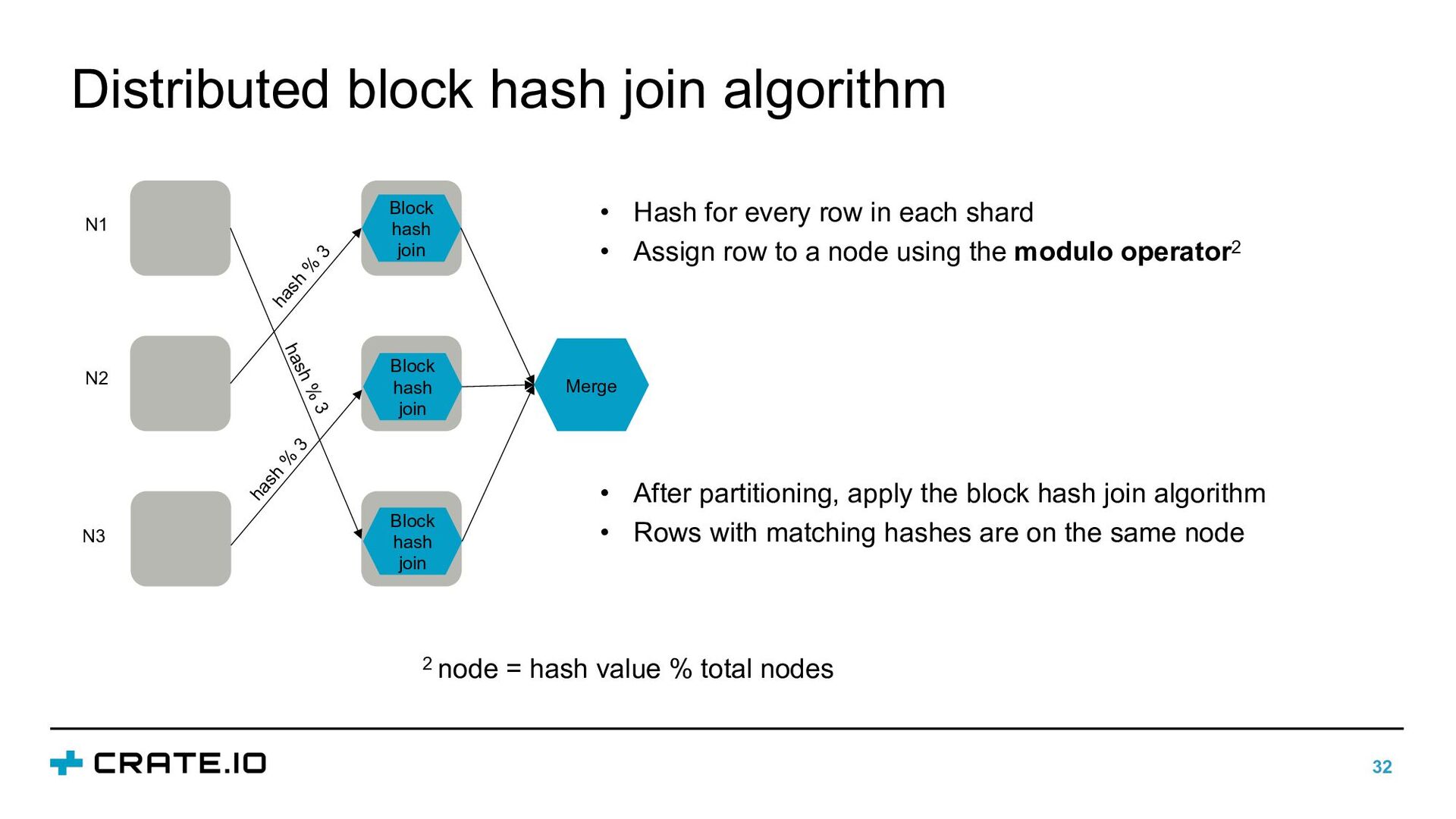
hash join Block hash join Block hash join hash % 3 hash % 3 hash % 3 Merge • After partitioning, apply the block hash join algorithm • Rows with matching hashes are on the same node 2 node = hash value % total nodes • Hash for every row in each shard • Assign row to a node using the modulo operator2
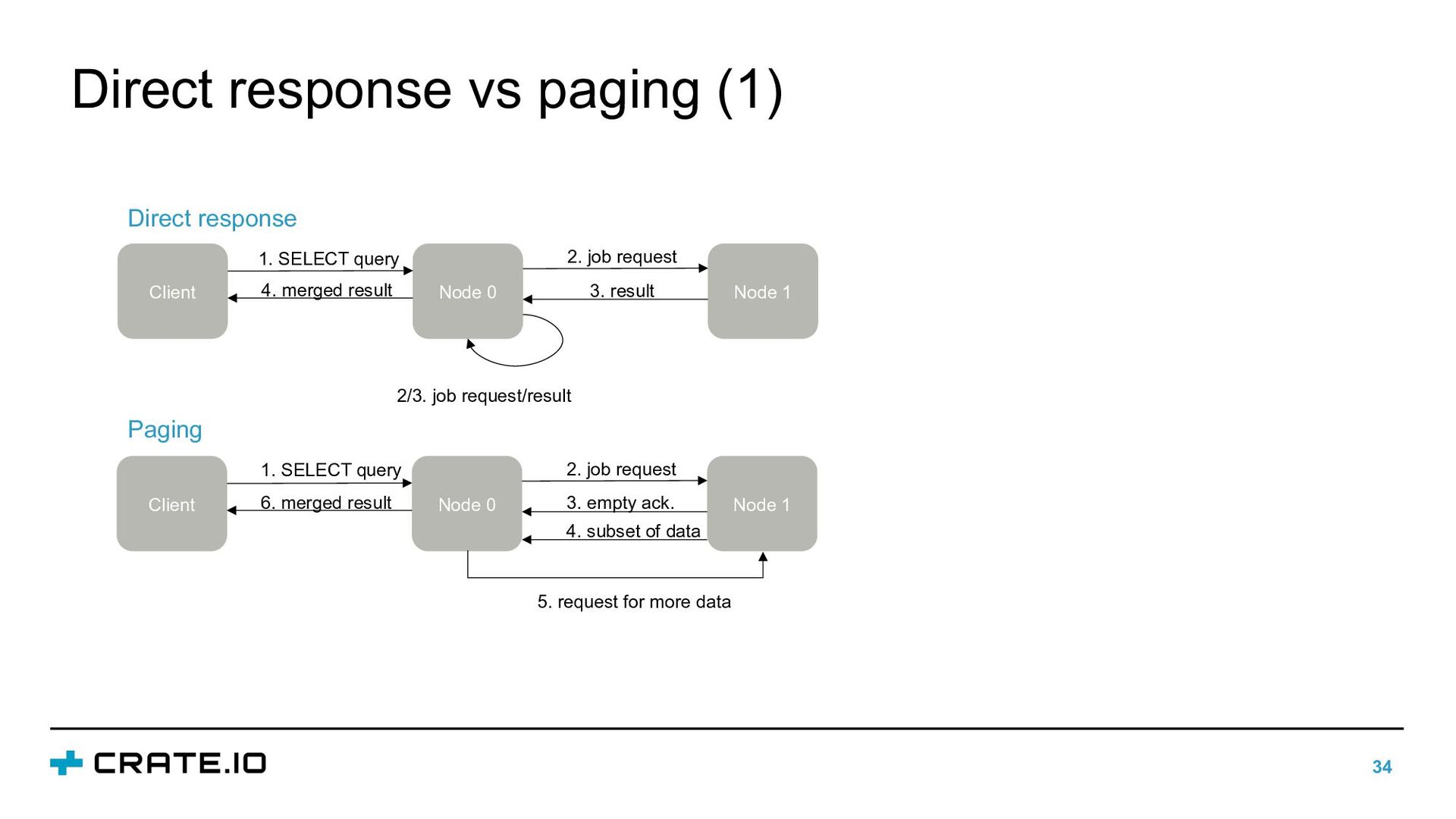
of individual data rows • Two modes for SELECT queries: • Direct response: collect node sends the full result to the handler • Paging: collect node sends results in batches • Which mode is used depends on the query (LIMIT), number of nodes and shards • Idea: if not so many results are expected direct response performs better
1 1. SELECT query 2. job request 3. empty ack. 6. merged result 4. subset of data 5. request for more data Client Node 0 Node 1 1. SELECT query 2. job request 2/3. job request/result 3. result 4. merged result Direct response Paging
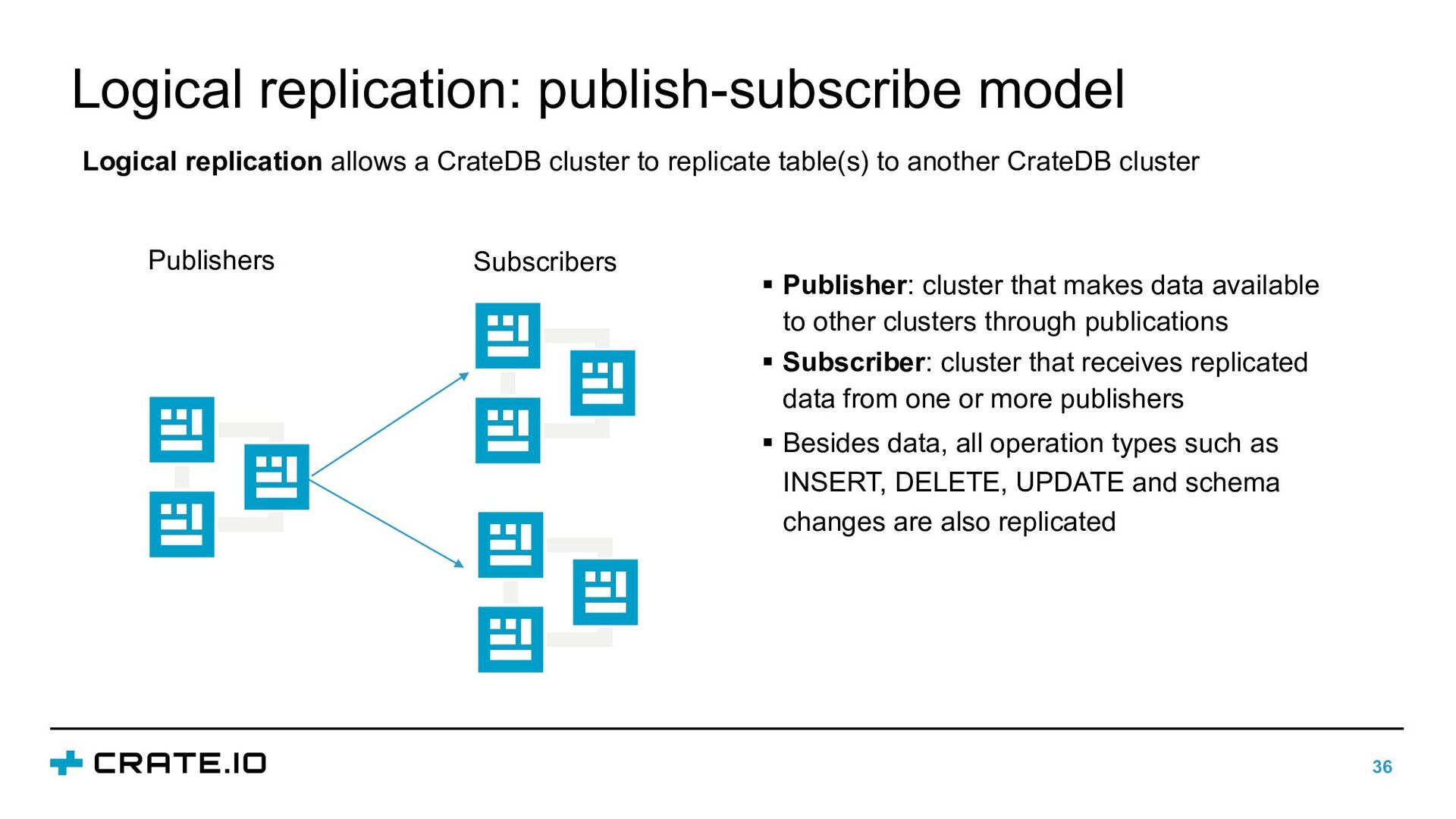
cluster to replicate table(s) to another CrateDB cluster Publishers Subscribers § Publisher: cluster that makes data available to other clusters through publications § Subscriber: cluster that receives replicated data from one or more publishers § Besides data, all operation types such as INSERT, DELETE, UPDATE and schema changes are also replicated
tables, subset of tables or no tables § No aggregations during replication § Tables on the subscriber are read-only § Connection string contains parameters in the key- value format § WITH enabled parameter: it specifies whether the subscription should be actively replicating CREATE PUBLICATION name {FOR TABLE table_name [,…] | FOR ALL TABLES} CREATE SUBSCRIPTION name CONNECTION ‘path_to_publisher’ PUBLICATION publication_name [, …] [WITH (parameter_name [= value], [,…], …]
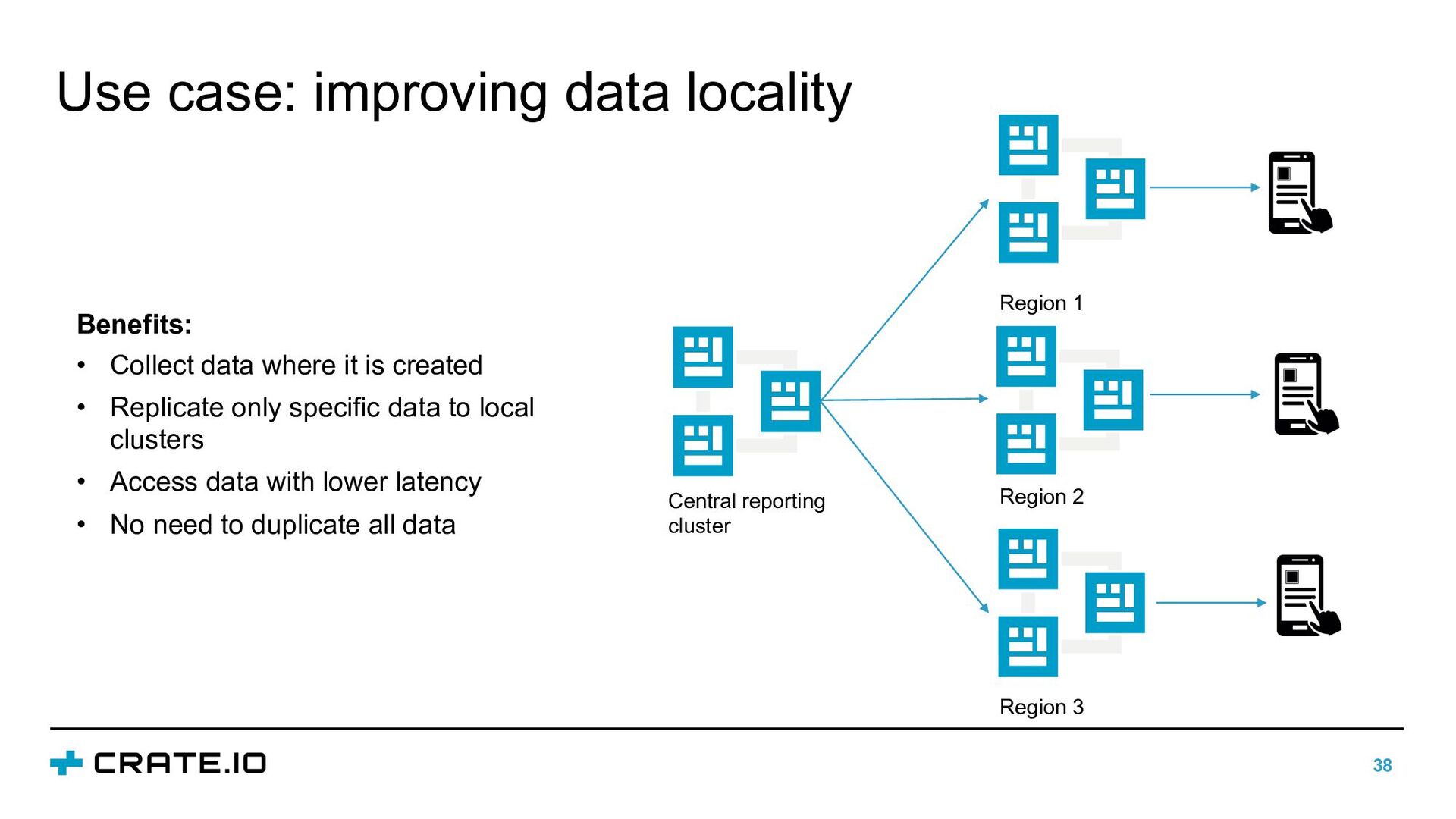
where it is created • Replicate only specific data to local clusters • Access data with lower latency • No need to duplicate all data Central reporting cluster Region 1 Region 2 Region 3
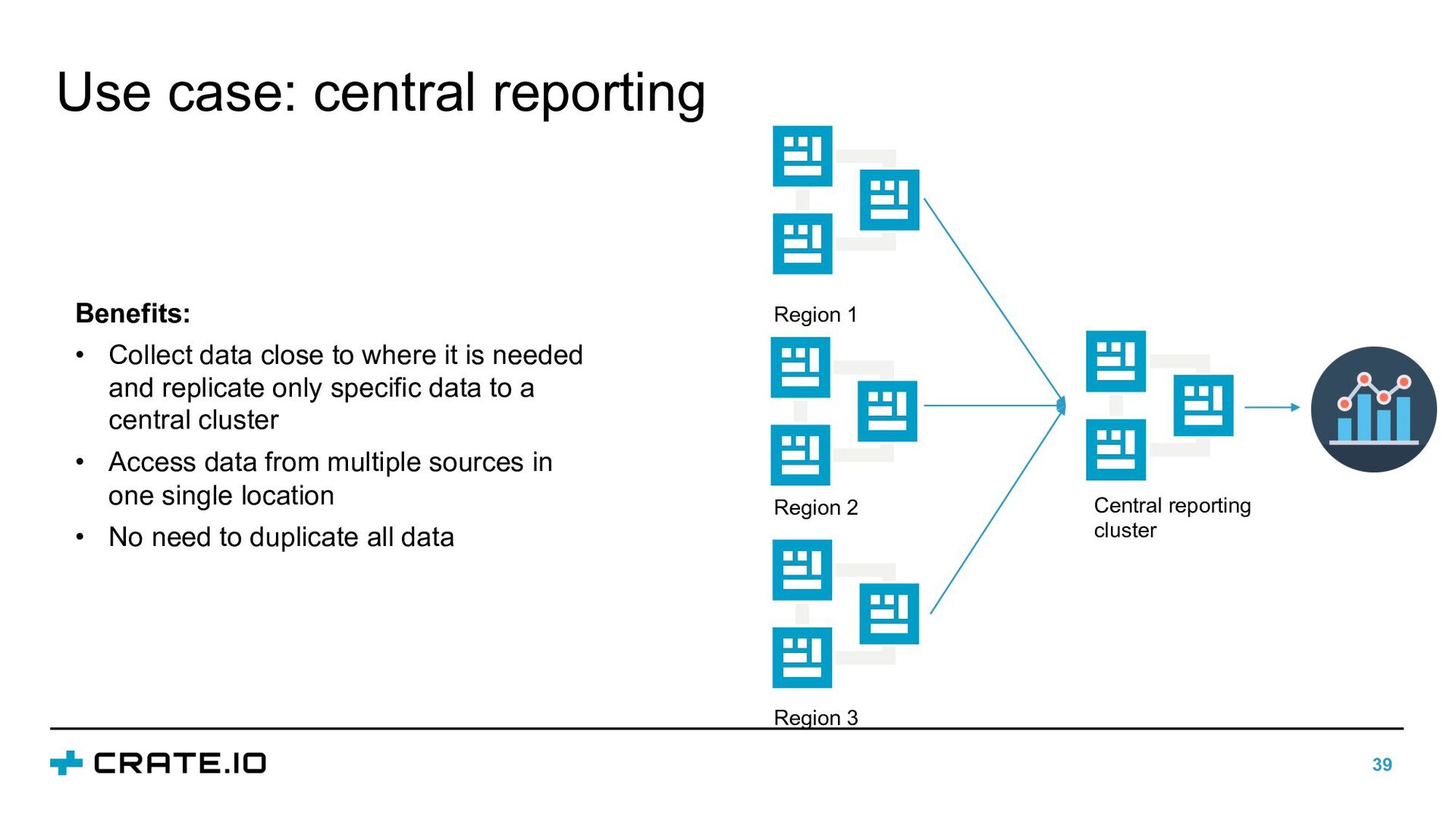
to where it is needed and replicate only specific data to a central cluster • Access data from multiple sources in one single location • No need to duplicate all data Central reporting cluster Region 1 Region 2 Region 3
many tools ▪ SQL queries must be supported by CrateDB’s SQL dialect ▪ Some limitations: o No support for TIME without a time zone o No support for multidimensional arrays o No support for INTERVAL input units (e.g., MILLISECONDS, MICROSECONDS) [1] https://crate.io/docs/crate/reference/en/5.0/interfaces/postgres.html
CrateDB integrations with more systems & tools ▪ Improve user experience and functionality of COPY FROM/TO ▪ Optimize source parsing to improve insert/update performance ▪ Further optimizations on distributed query execution
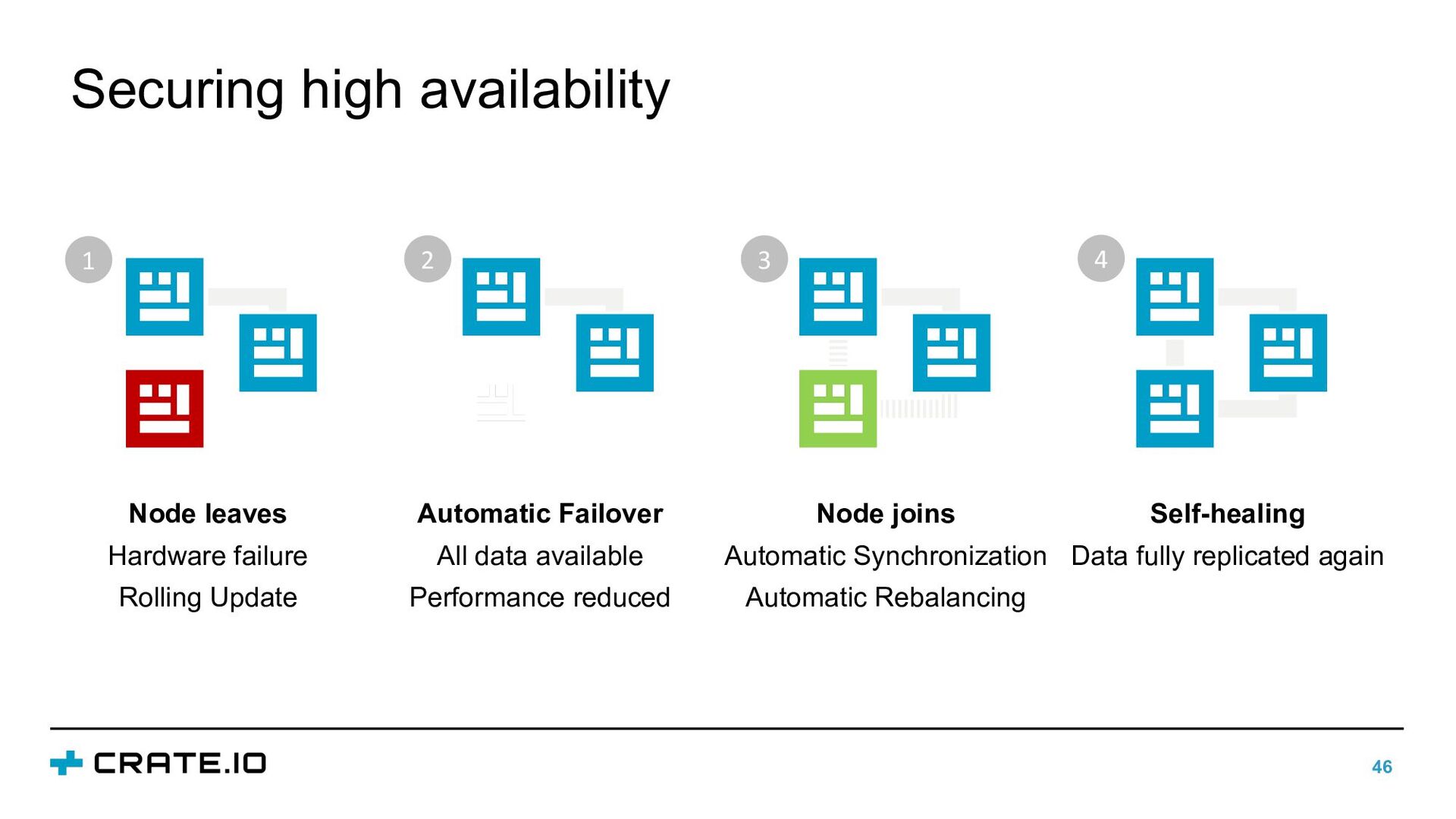
Self-healing Data fully replicated again Node joins Automatic Synchronization Automatic Rebalancing Automatic Failover All data available Performance reduced 2 1 3 4
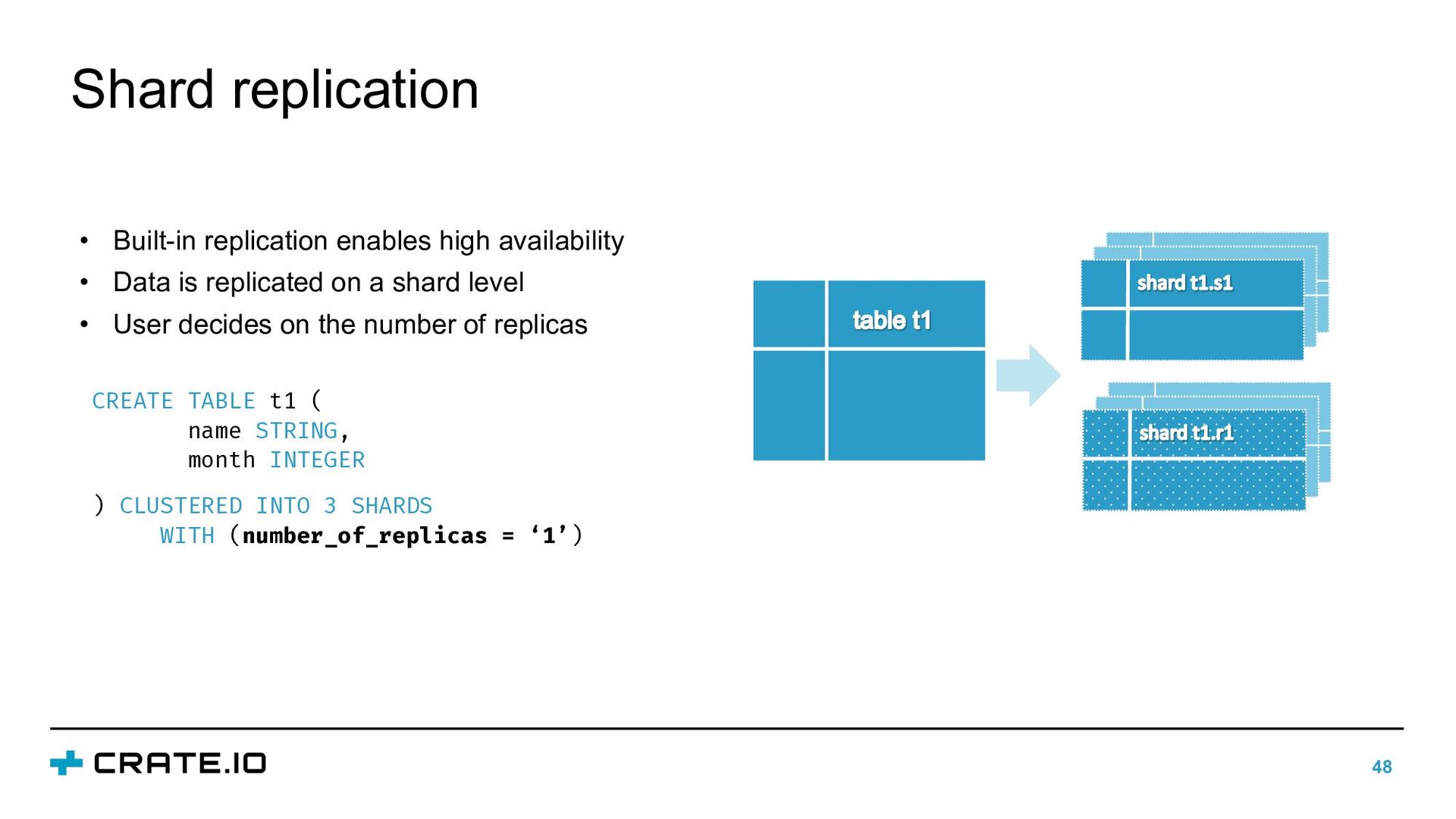
INTEGER ) CLUSTERED INTO 3 SHARDS WITH (number_of_replicas = ‘1’) • Built-in replication enables high availability • Data is replicated on a shard level • User decides on the number of replicas
user-defined functions • Example: filter all elements in an array within a given range CREATE OR REPLACE FUNCTION filter(ARRAY(INTEGER), INTEGER, INTEGER) RETURNS ARRAY(INTEGER) LANGUAGE JAVASCRIPT AS 'function array_filter(array_integer, min, max) { return array_integer.filter(el => el >= min && el <= max); }';
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![42 Ecosystem ▪ PostgreSQL wire protocol v3[1] => compatibility with](https://files.speakerdeck.com/presentations/63661647c22f497ebf0b99a0d8349c7c/slide_41.jpg){kind=link}
{kind=link}
![Join our community: community.crate.io [email protected] [email protected] Thank you!](https://files.speakerdeck.com/presentations/63661647c22f497ebf0b99a0d8349c7c/slide_43.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}