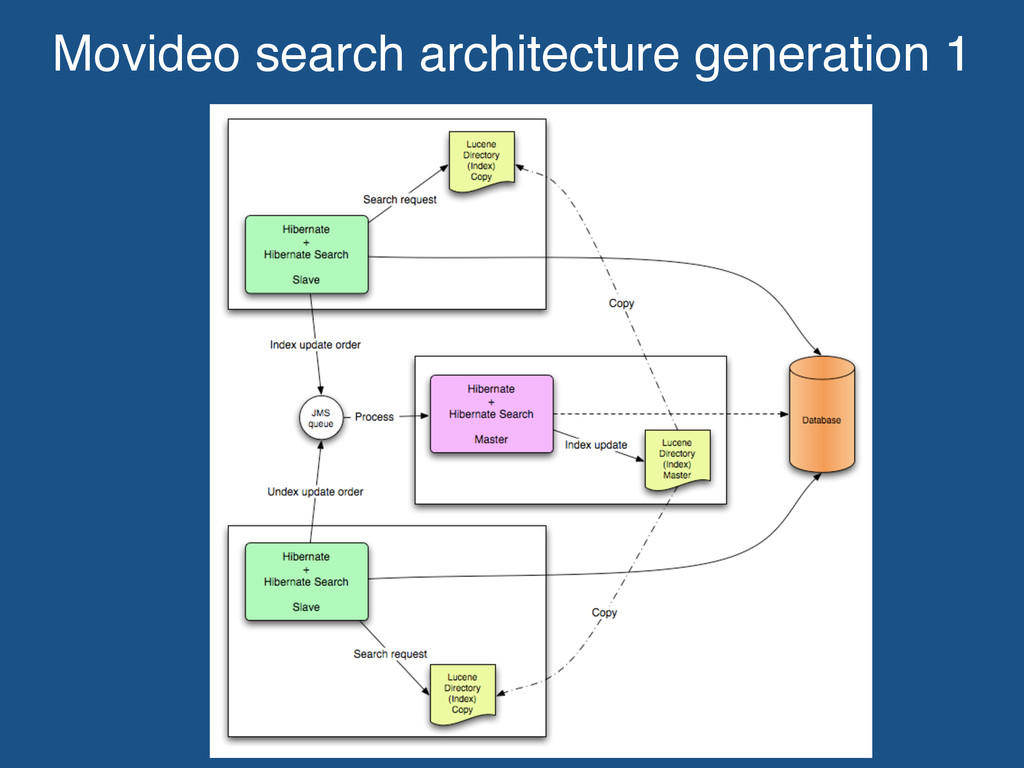
of the box’ solution to use and Lucene is a proven search solution. Movideo utilises Hibernate ORM and the Hibernate Search project allowed for a simple add on of Lucene. No need to implement Lucene directly (confusing for us with no search experience before).
the DB backed model to still be retrieved but by ID instead of a complex query. Reduced load off MySQL / SQL Server onto a local Lucene index. In turn, provided a NoSQL type solution.
years in production with no major issues. Issues only started to occur when index become to large to copy to each instance. Movideo found that 2 x ~7GB index size, issues started to occur. Limitations around consistency and performance. Index replication was at quickest around 2-3min.
index. A fully fledged service for search. Designed for cloud environments from the ground up. Represents documents as JSON. Easily parseable. Can query over http, no more ‘Luke’!
A4 instance sizes. Smaller instance sizes can experience degraded performance from shared network IO. Moved to SSD’s and have improved recovery time with much slow IO.
Currently using Unicast with setting the internal Azure hostname of other nodes. Azure Virtual Network required for internal communication between applications. Elasticsearch Azure plugin can be used for discovery of other nodes (Uses the Azure AppFabric API for discovery).
Lucene, there were version clashes to run single deployment with Hibernate Search and Elasticsearch implementation. 2 separate builds of the web were deployed within same Tomcat instance and Nginx used to redirect requests to specific deployment. Allows for metrics analysis to see if what we did improved performance.
a ‘Search Indexer’ app from the previous Hibernate Search indexer. ‘Search Indexer’ reads batches of records from database, serialises into JSON and bulk indexes these into Elasticsearch. Alias is added on the current production index.
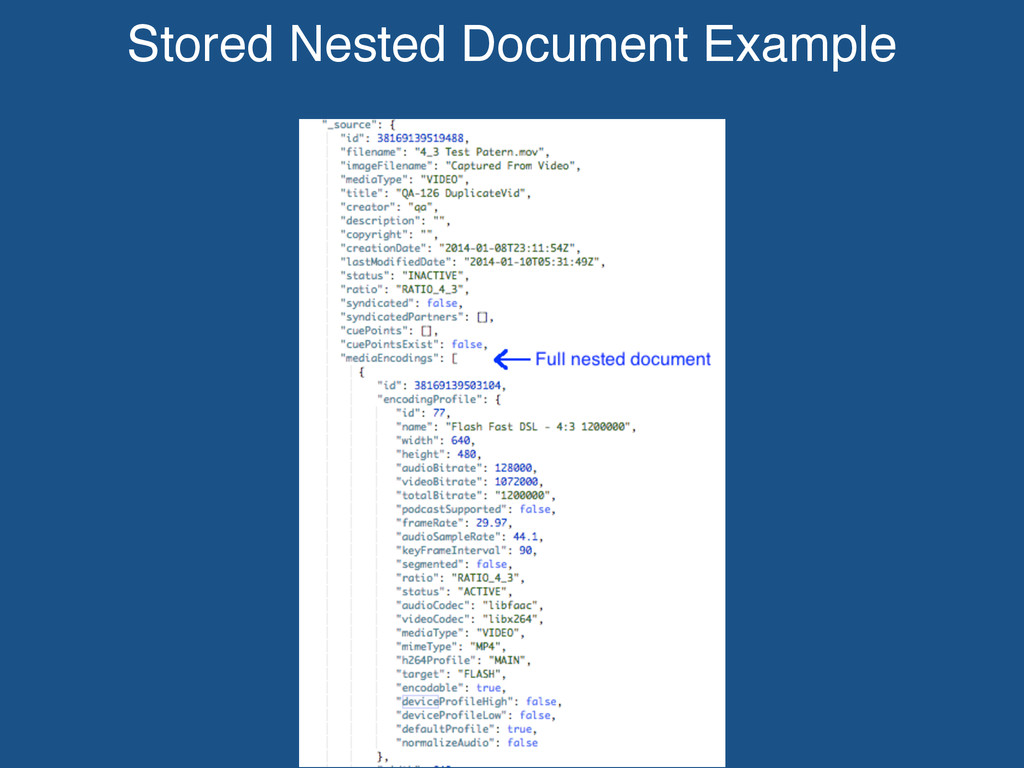
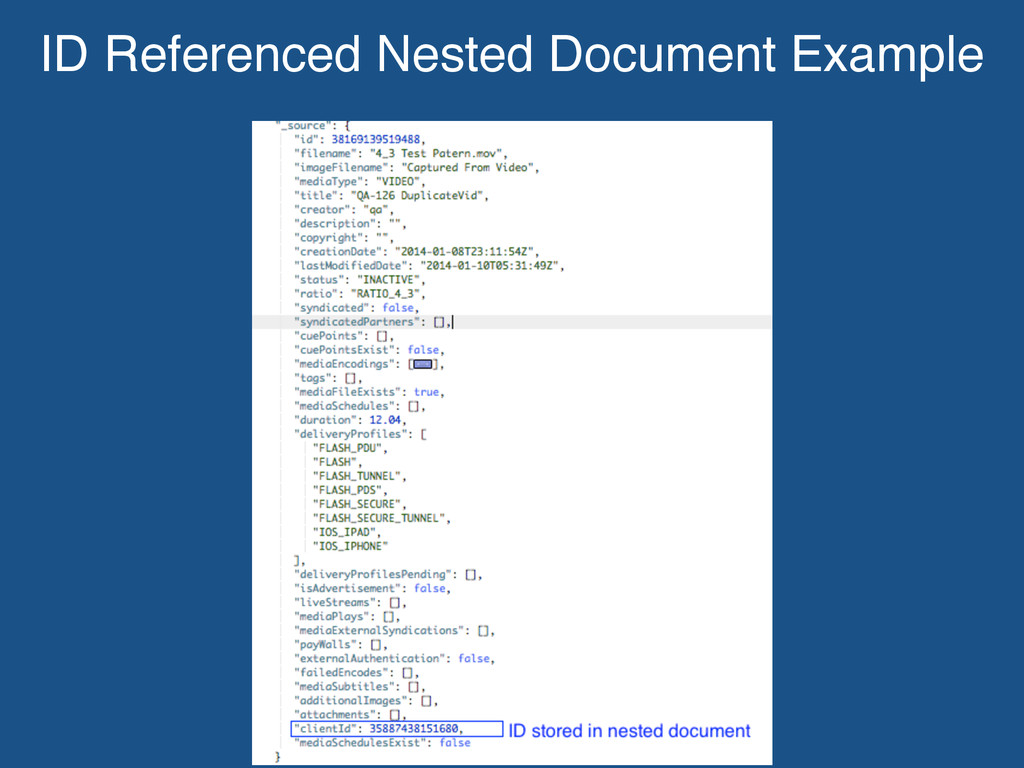
full control over the data structures. Nested documents are based on database relationships. Movideo workflow: If the nested document doesn’t change much as part of business logic, then the full document is stored. If the nested document changes as part of business logic, then a id reference is stored.
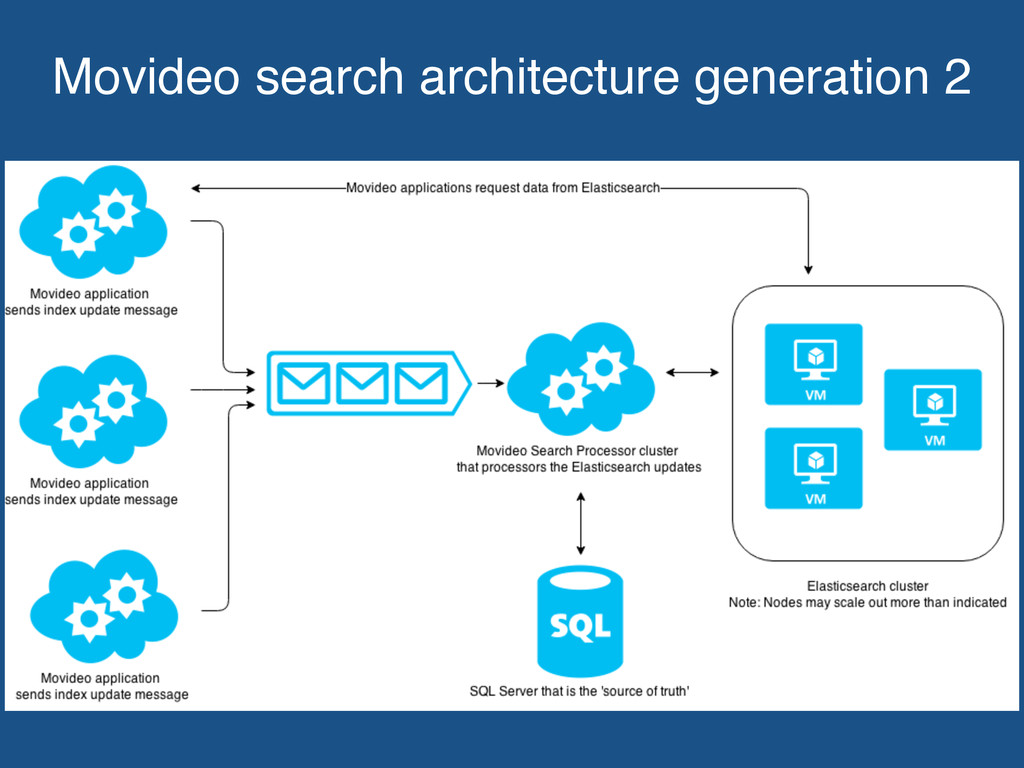
message queues to send index update messages. Search Processor application processes messages and indexes data into Elasticsearch. Use of queues give us durability around index updates.
much as possible as filters are cacheable. If there is no need for relevance score, then use ‘match_all’ query with filters. We use a simple aggregation to get duration of all media, which cleaned up application code as well.
outta here! Hibernate search would do a single query and then get the attached objects from the database by id. Found that the bottleneck isn’t the database for single queries, it’s the lazy loading object retrieval. Elasticsearch initial query will return JSON that gets deserialised into a model with id references to other related models. We use ‘multi-get’ queries to get the other models data from Elasticsearch.
join column. Tag services want unique results. Storing a document per tag row would have duplicates. So we can’t just do a row = document representation. ID NS Predicate Value Media ID 1 music artist Pearl Jam 123123123 2 music genre Rock 123123123 3 music artist Pearl Jam 82399239 4 music genre Grunge 82399239
of tags from database If exists, get existing document and create ‘elasticsearch’ model else create a new ‘elasticsearch’ model of tag Loop through other tags and determine if ‘elasticsearch’ document exists for the tag and if so, add model details Index into Elasticsearch Check Elasticsearch for tag by ID (full:tag=value-MEDIA)
‘taggable' object is being updated by the ‘search processor’, index update message is sent for each tag on the object if exists, get existing document and create ‘elasticsearch’ model else create new ‘elasticsearch’ model When indexing, optimistic concurrency is upheld with a version check. If there is a version exception, the tag is retrieved again from Elasticsearch and attempted to be indexed. ‘Tag update message’ is processed by checking Elasticsearch for tag by custom ID
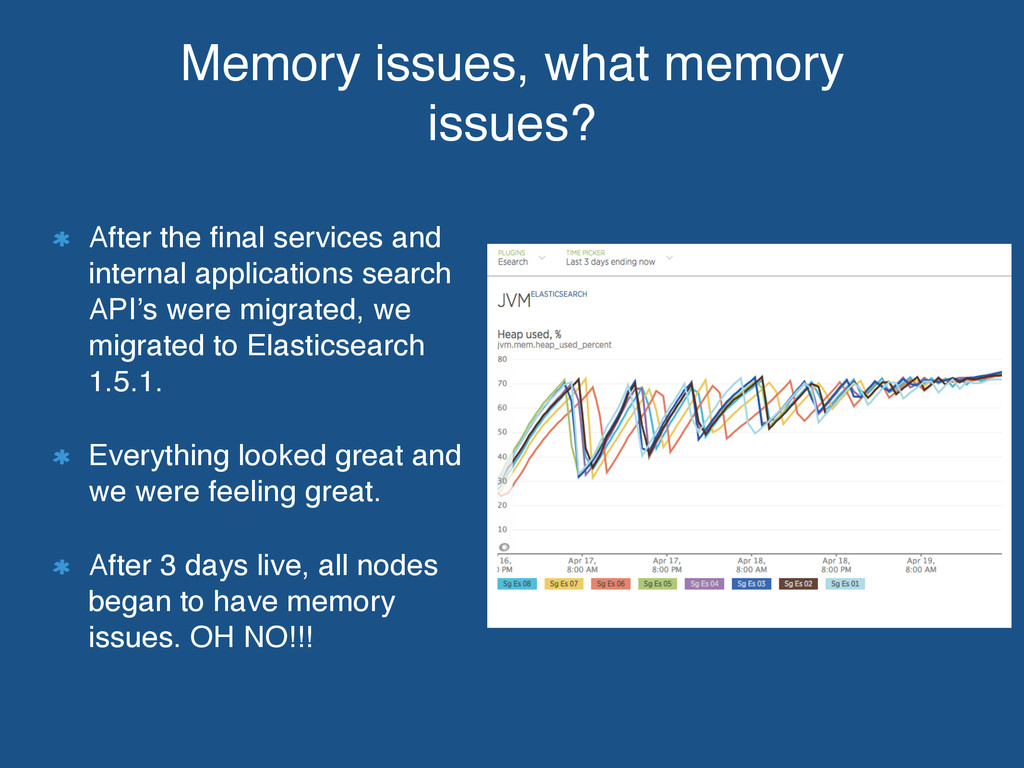
internal applications search API’s were migrated, we migrated to Elasticsearch 1.5.1. Everything looked great and we were feeling great. After 3 days live, all nodes began to have memory issues. OH NO!!!
parent and child documents to be in memory. If there are lots of child documents, this requires a lot more to be cached. Elasticsearch can’t currently get around this due to dependancy on Lucene 4.X. A fix is currently in master due to Lucene 5.X being used. Work arounds for now are to have more heap memory, re-design the index layout to not require nested sorting or manually clear filter cache.
query your data and test queries (use an isolated cluster for experimenting with queries) _cat API should be used with alerting system to alert about ‘all the things’
snapshot and restore API. Snapshot and restore API allowed to take a snapshot of index at ‘point in time’ and allow to restore later. We have used the Azure Snapshot and Restore plugin to allow snapshots directly to blob storage.
‘real time’, allow direct indexing into Elasticsearch and explicit ‘refresh’. Use ‘scrutineer by Aconex’ application to compare data between the database and Elasticsearch.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}