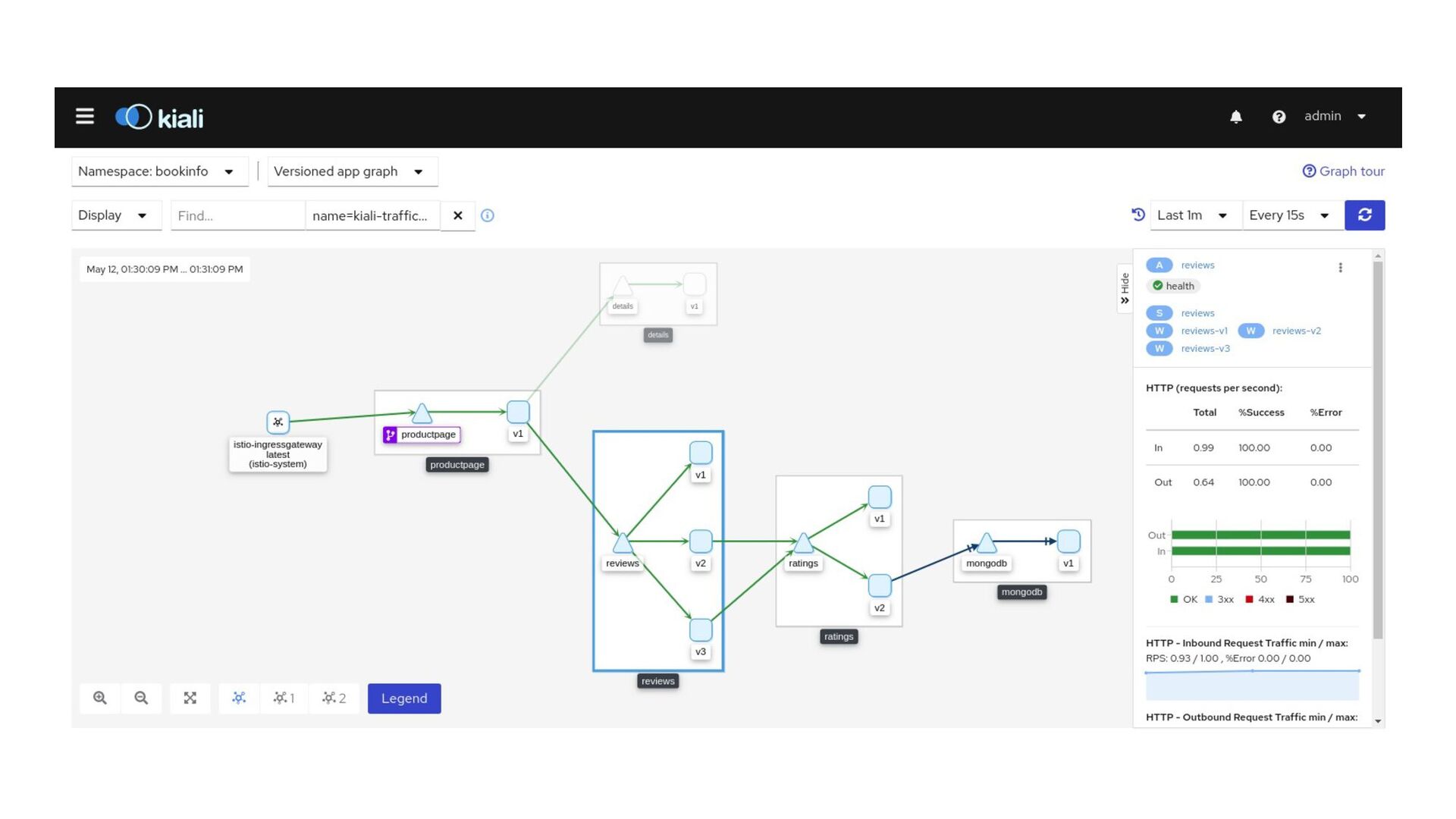
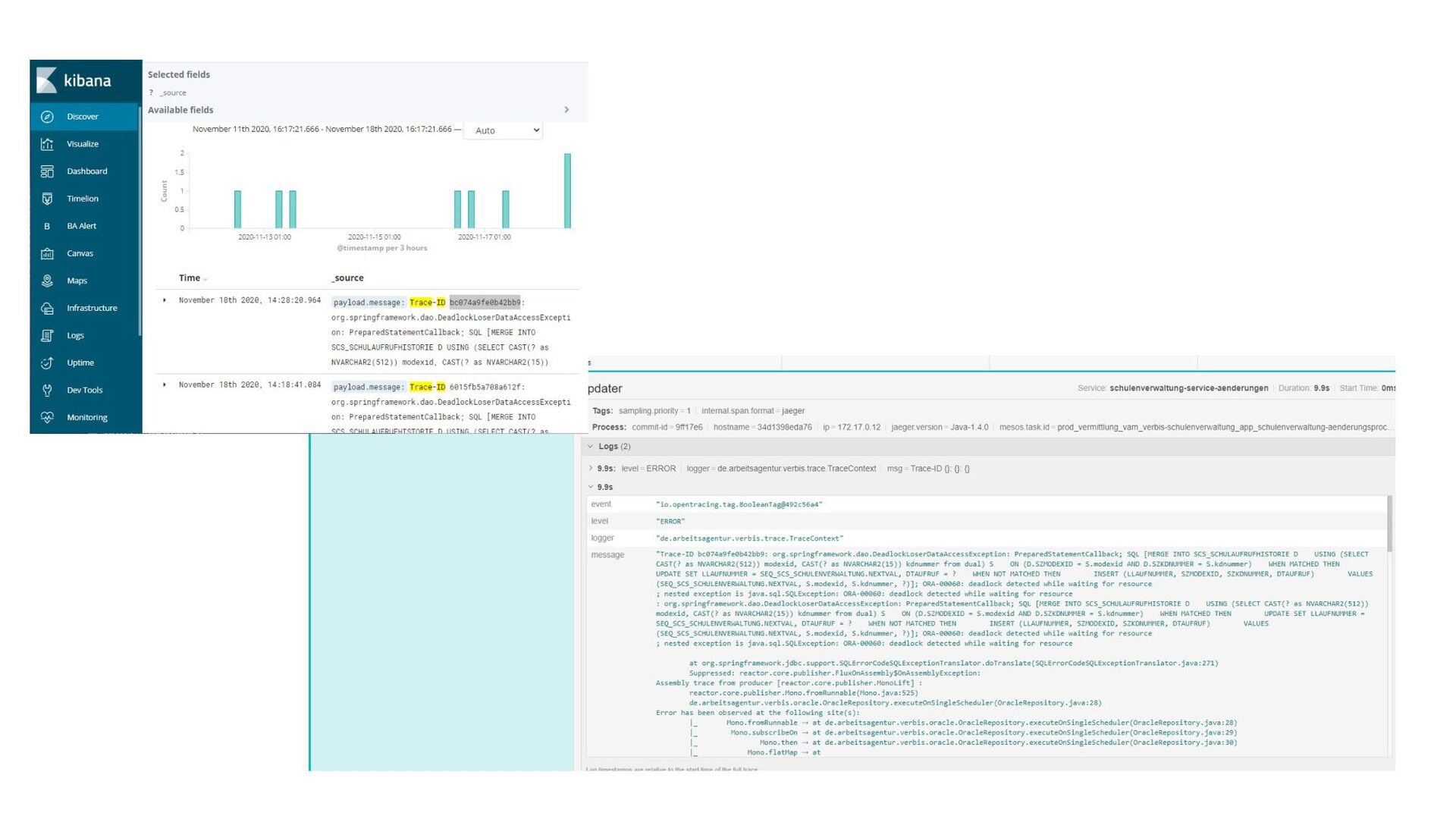
erzeugte Traces • Agent, Collector, Query, Graph + Datenbank • OpenTelemetry • Funktioniert über weiterreichen von Header (HTTP, Kafka, …) • Sampling der Traces • Integriert in Service Meshes wie Istio • Basiert auf instrumentierung von Anwendungs Libraries (z.B. Proxy JdbcConnection)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}