Clara, CA 2010年4月創業 Santa Clara • London • Paris • Singapore • Tokyo • Sydney • Wellington オープンソースを基盤とした テクノロジースタックを エンタープライズ向けソリューション として提供 DATASTAX JAPAN 2017年法人設立
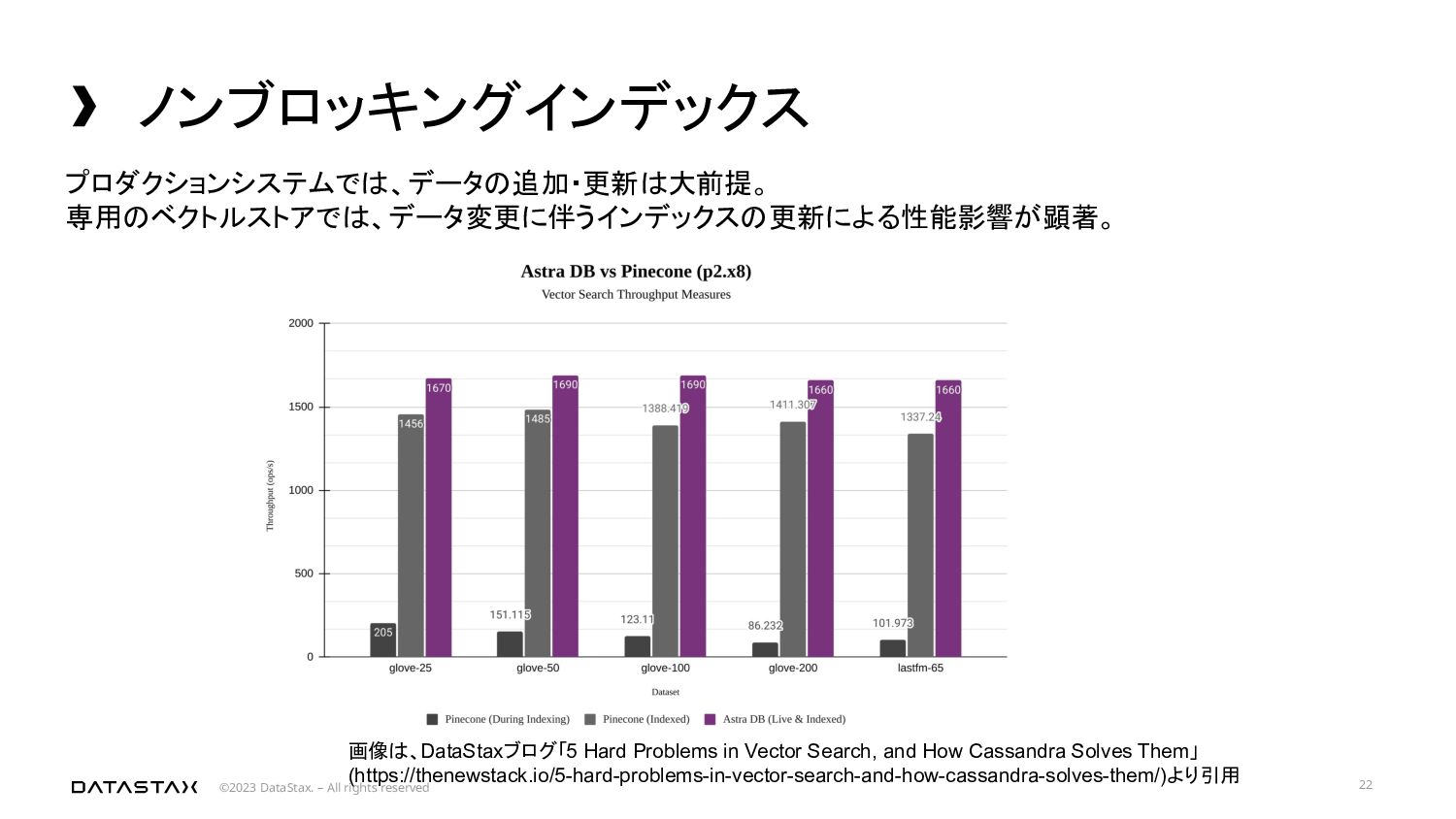
専用のベクトルストアでは、データ変更に伴うインデックスの更新による性能影響が顕著。 画像は、DataStaxブログ「5 Hard Problems in Vector Search, and How Cassandra Solves Them」 (https://thenewstack.io/5-hard-problems-in-vector-search-and-how-cassandra-solves-them/)より引用
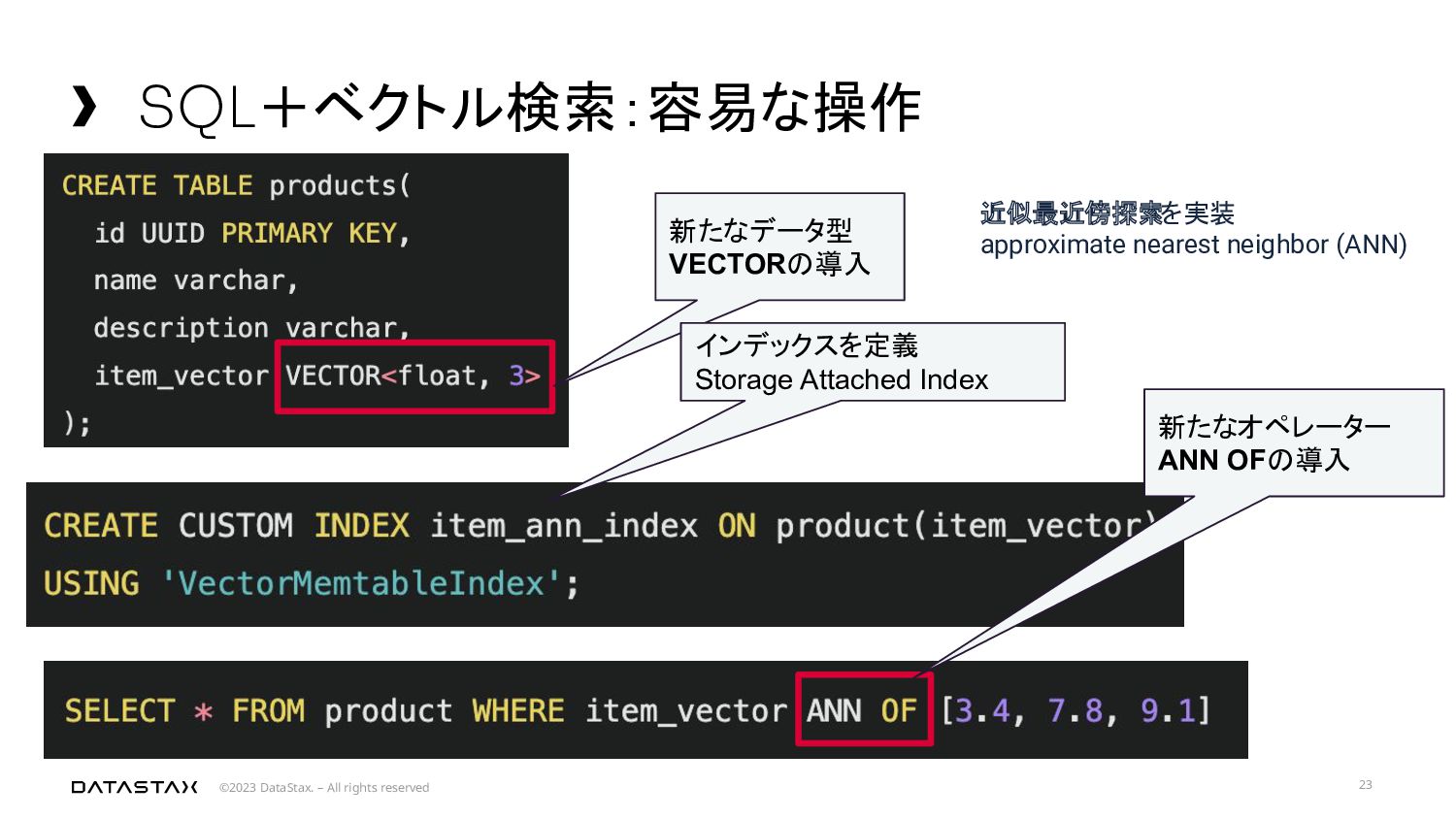
description, similarity_cosine(item_vector, [0.1, 0.15, 0.3, 0.12, 0.05]) FROM vsearch.products ORDER BY item_vector ANN OF [0.1, 0.15, 0.3, 0.12, 0.05] LIMIT 1;
![©2023 DataStax. – All rights reserved LLMフレームワークLangChain入門 〜生成AIアプリ開発手法とベクトル検索 河野泰幸<[email protected]>](https://files.speakerdeck.com/presentations/d06de19c2e4d4f60bc6c9bcff65c05ec/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
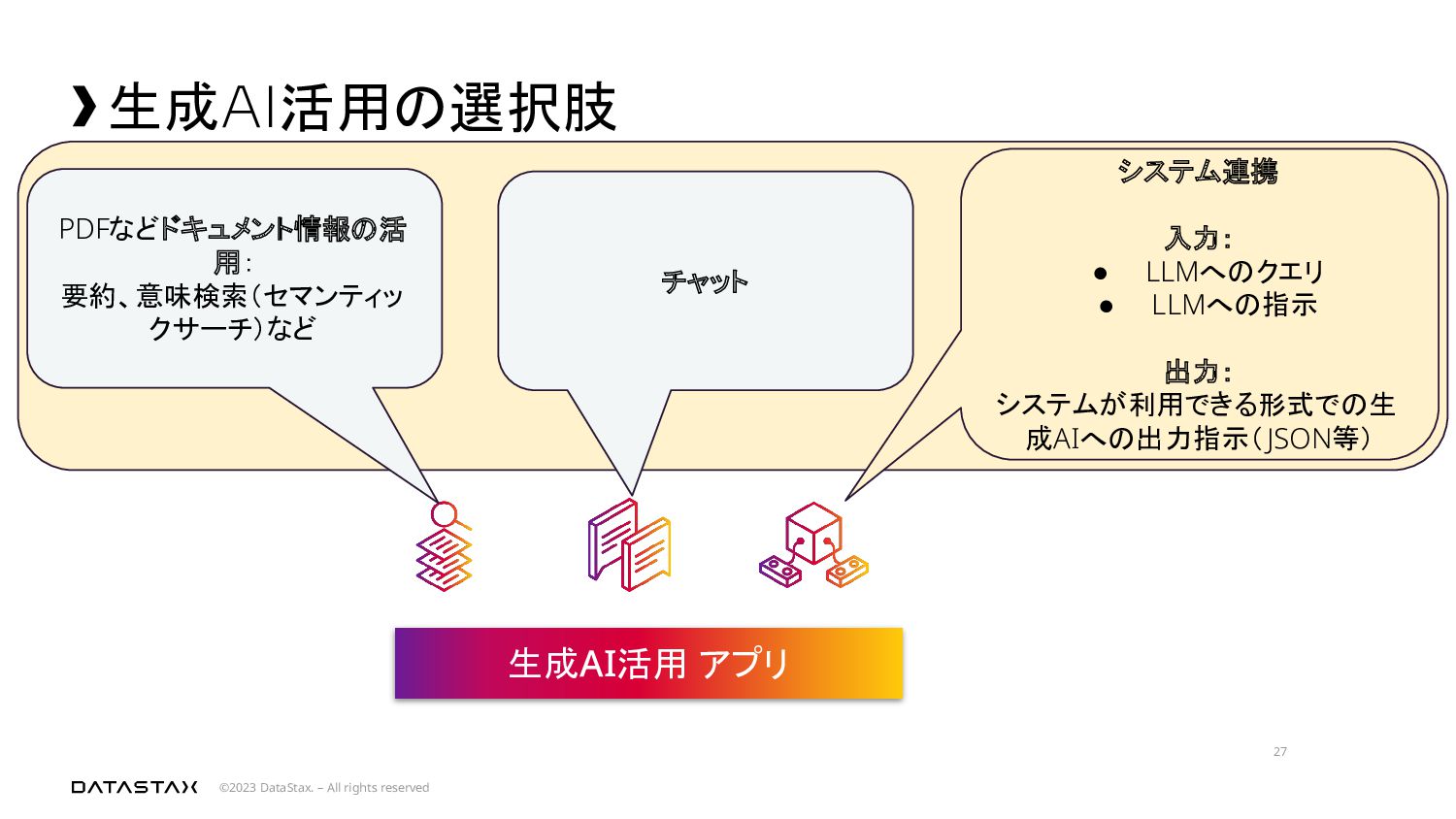{kind=link}
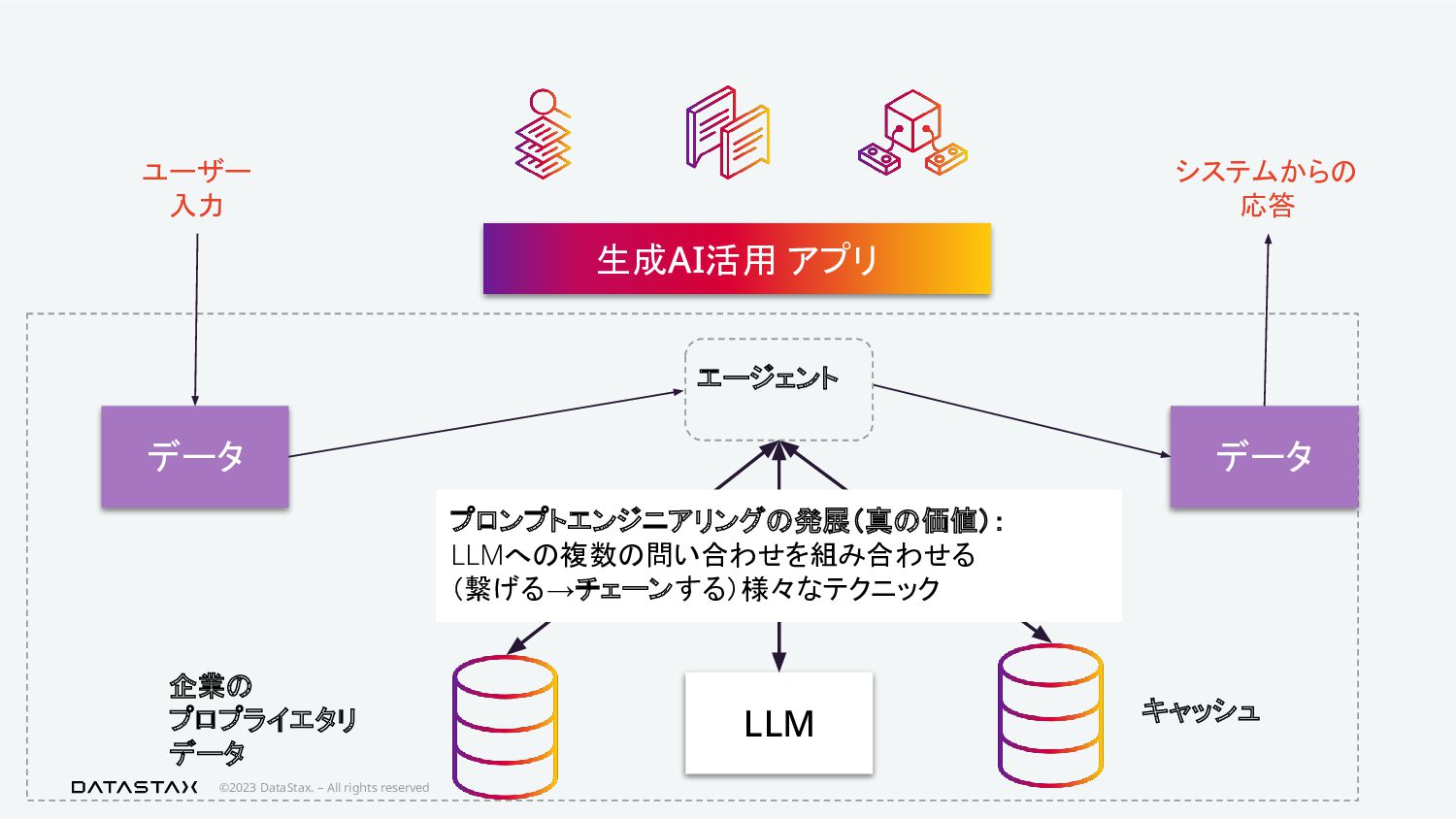{kind=link}
{kind=link}
{kind=link}
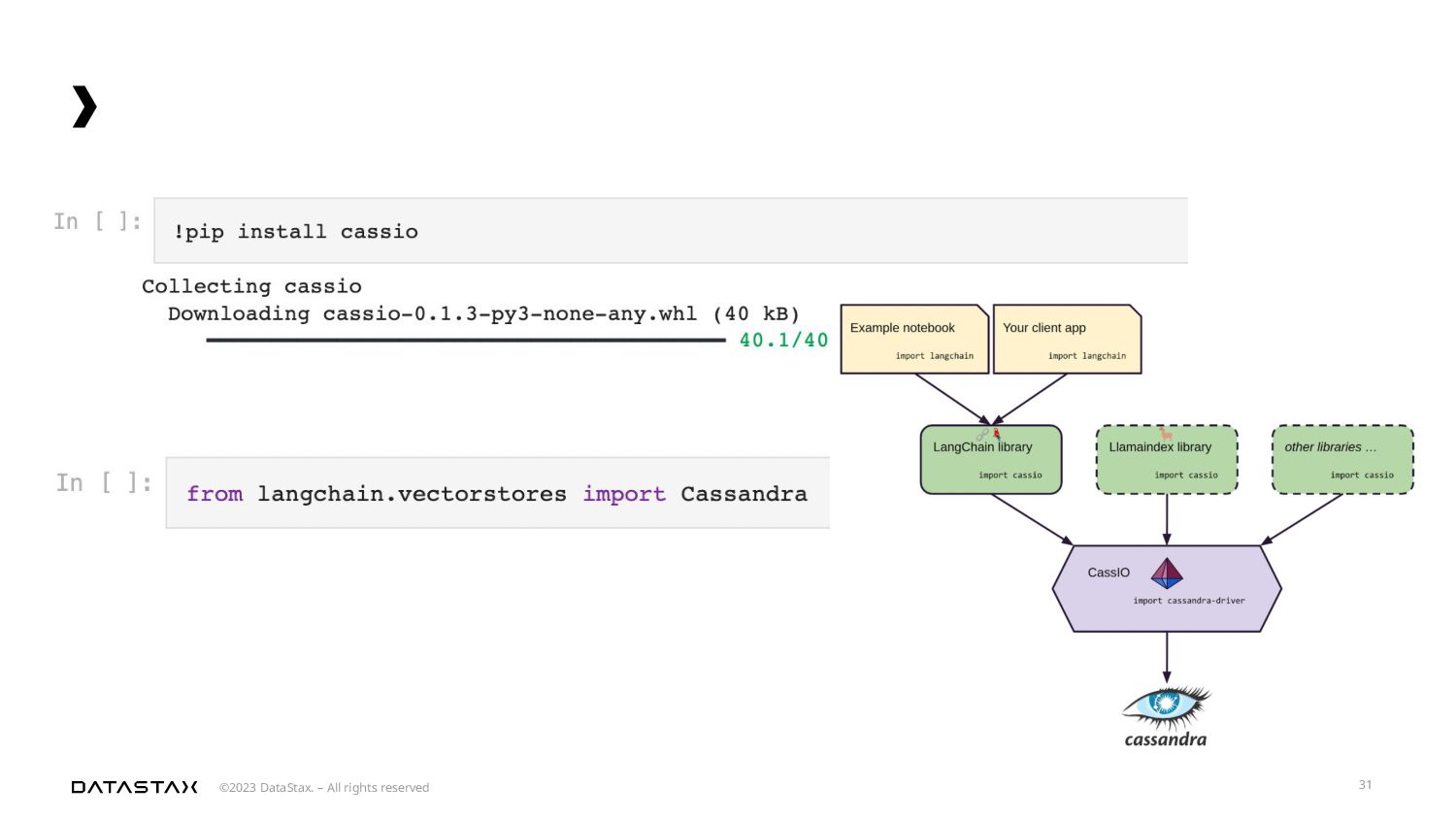{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![©2023 DataStax. – All rights reserved 生成AI・ベクトル検索にDataStaxの技術を! 49 ご質問・デモ・ご商談のご依頼は、[email protected]へお問合せください。](https://files.speakerdeck.com/presentations/d06de19c2e4d4f60bc6c9bcff65c05ec/slide_48.jpg){kind=link}
{kind=link}