Clara, CA 2010年4月創業 Santa Clara • London • Paris • Singapore • Tokyo • Sydney • Wellington オープンソースを基盤とした テクノロジースタックを エンタープライズ向けソリューション として提供 DATASTAX JAPAN 2017年法人設立
専用のベクトルストアでは、データ変更に伴うインデックスの更新による性能影響が顕著。 画像は、DataStaxブログ「5 Hard Problems in Vector Search, and How Cassandra Solves Them」 (https://thenewstack.io/5-hard-problems-in-vector-search-and-how-cassandra-solves-them/)より引用
近似最近傍探索を実装 approximate nearest neighbor (ANN) インデックスを定義 Storage Attached Index SELECT * FROM product ORDER BY item_vector ANN of [3.4, 7.8, 9.1] 新たなオペレーター ANN OFの導入
description, similarity_cosine(item_vector, [0.1, 0.15, 0.3, 0.12, 0.05]) FROM vsearch.products ORDER BY item_vector ANN OF [0.1, 0.15, 0.3, 0.12, 0.05] LIMIT 1;
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
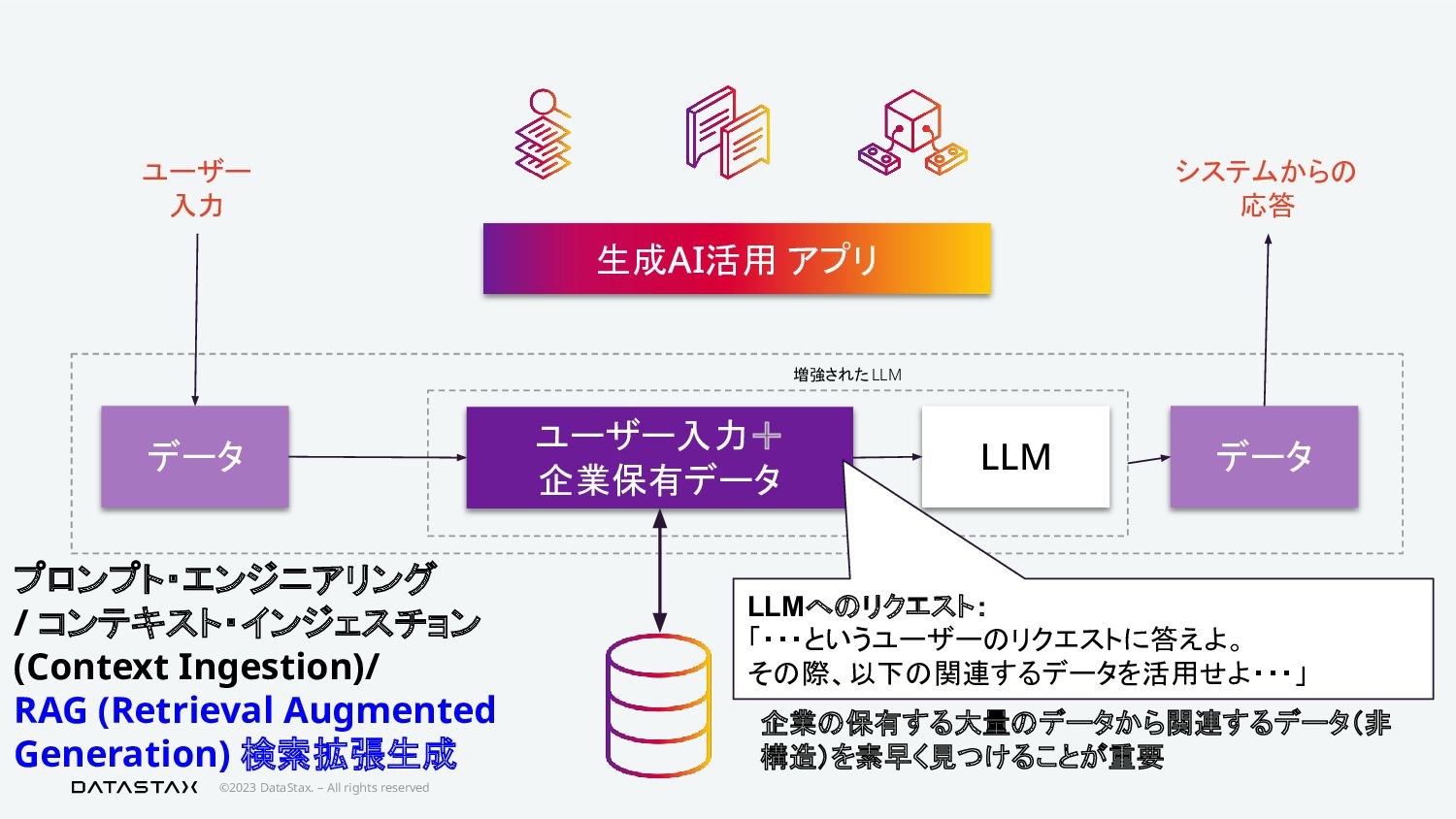{kind=link}
{kind=link}
{kind=link}
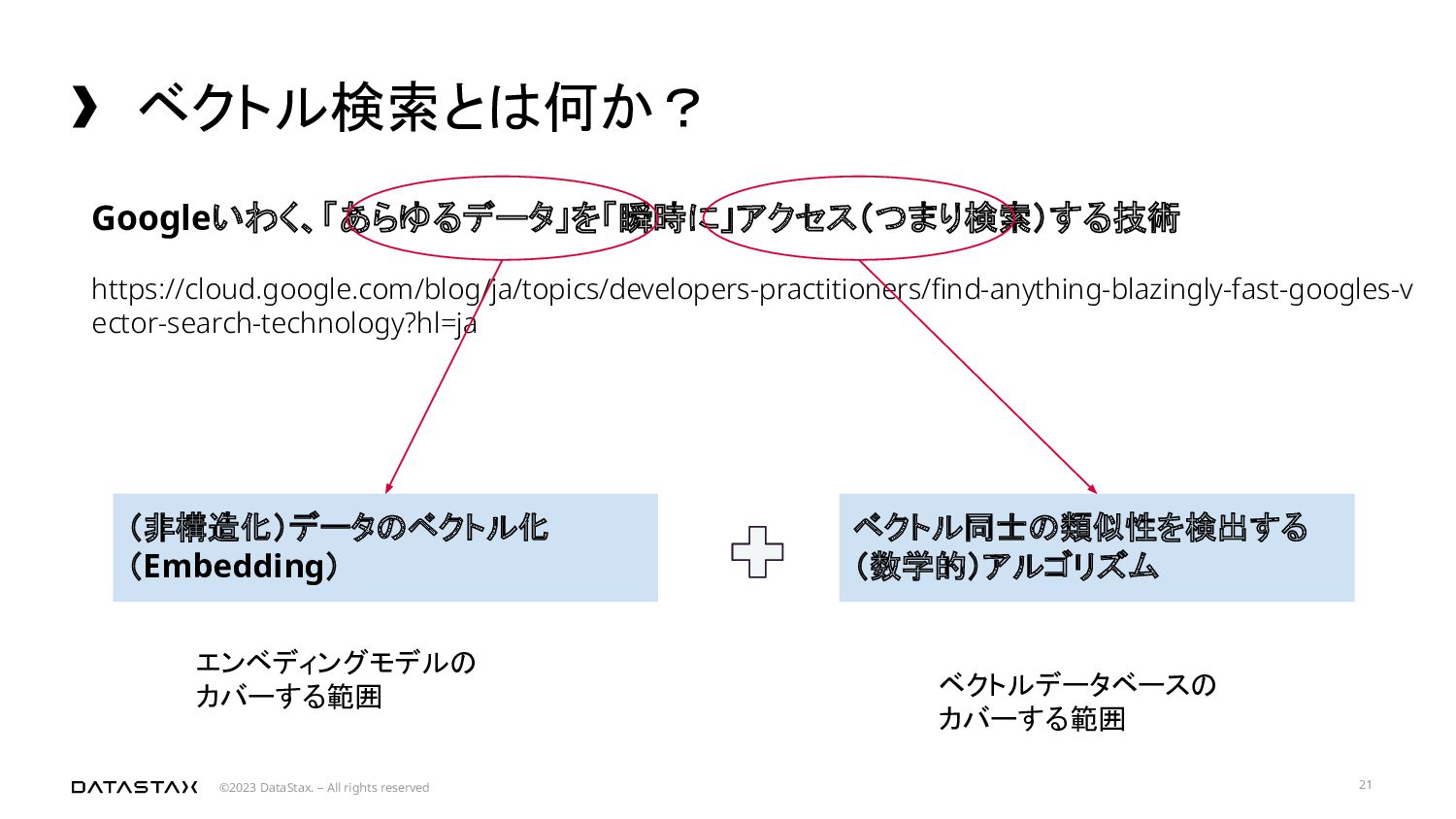{kind=link}
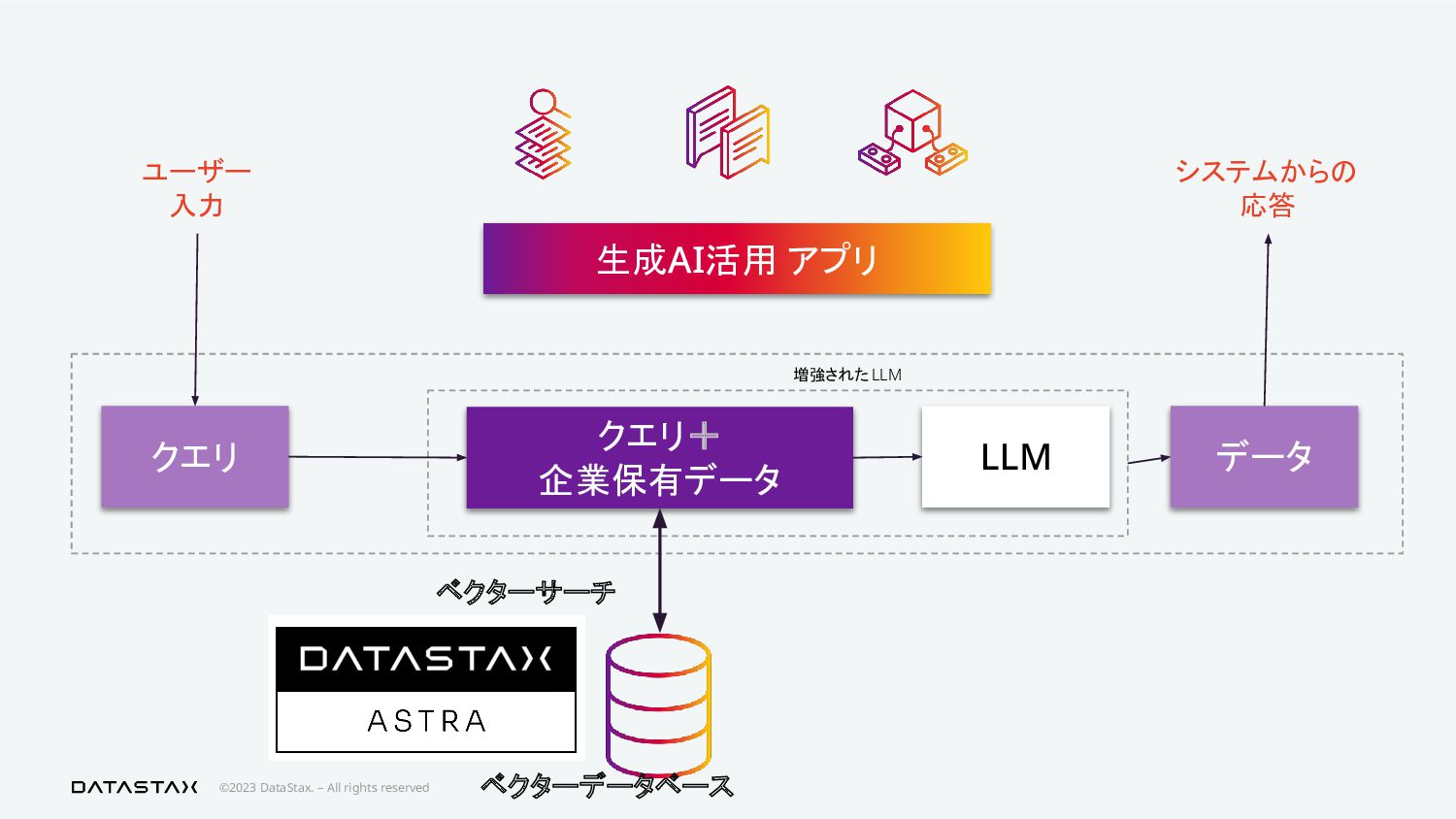{kind=link}
{kind=link}
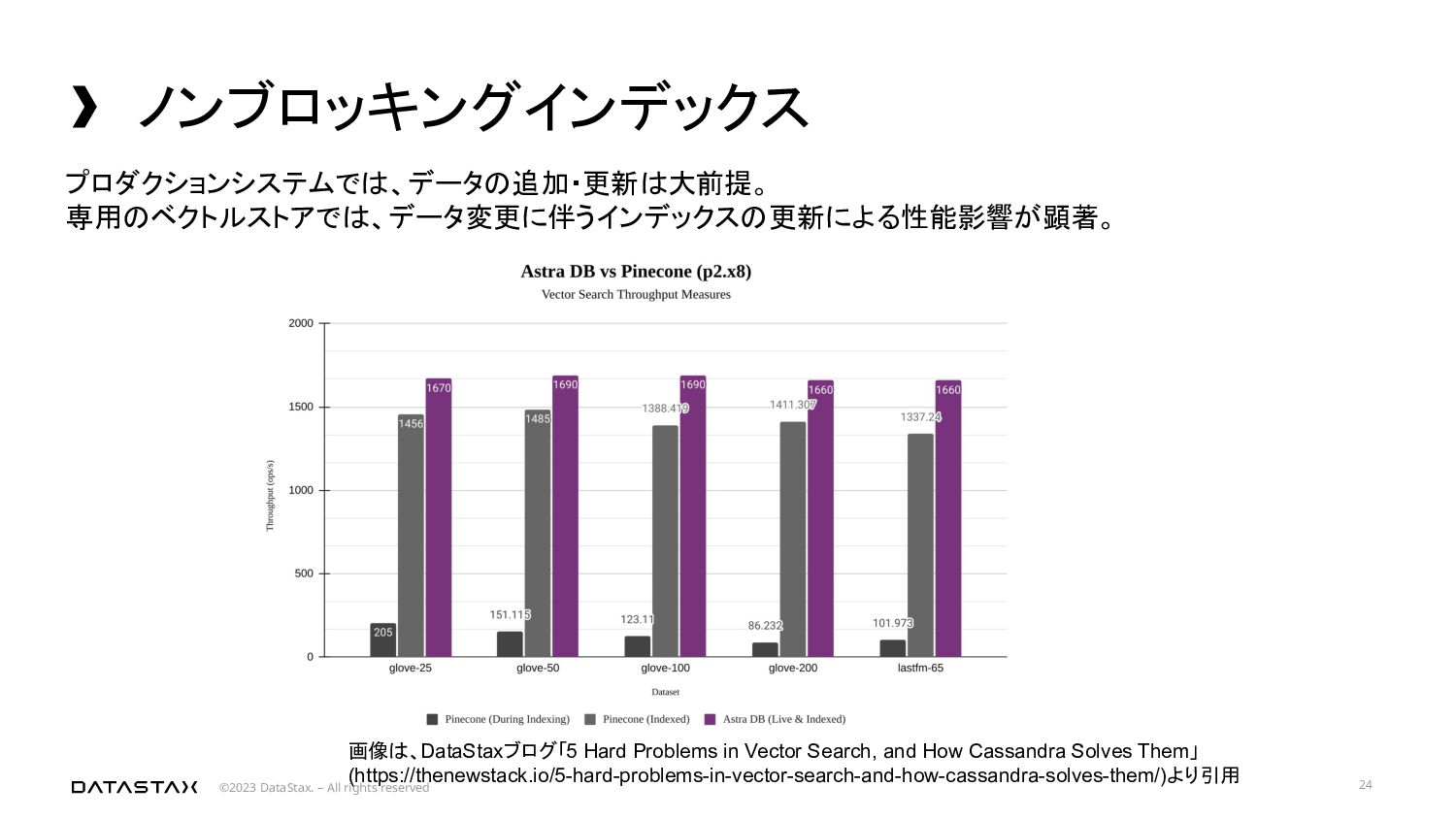{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
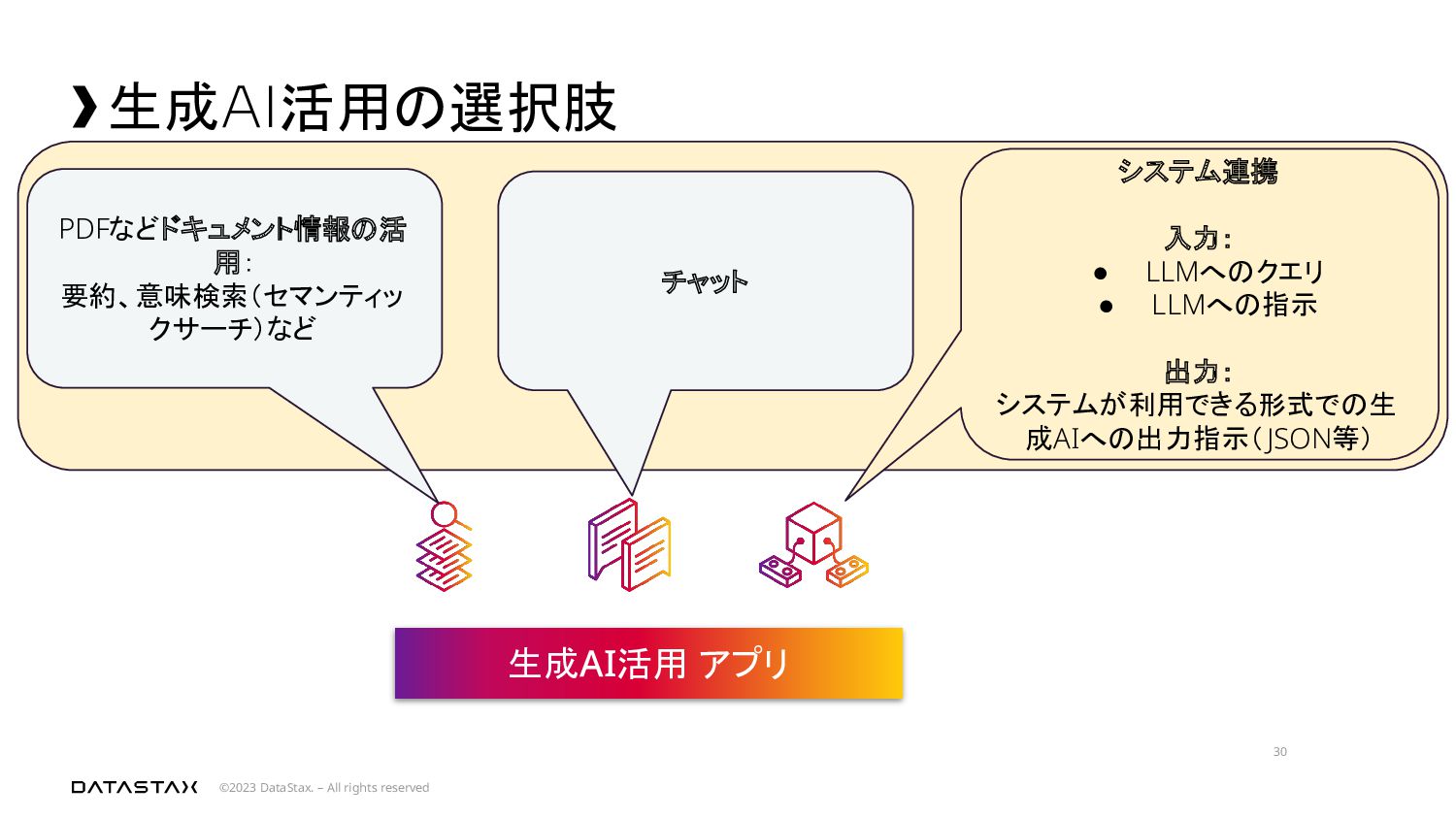{kind=link}
{kind=link}
{kind=link}
{kind=link}
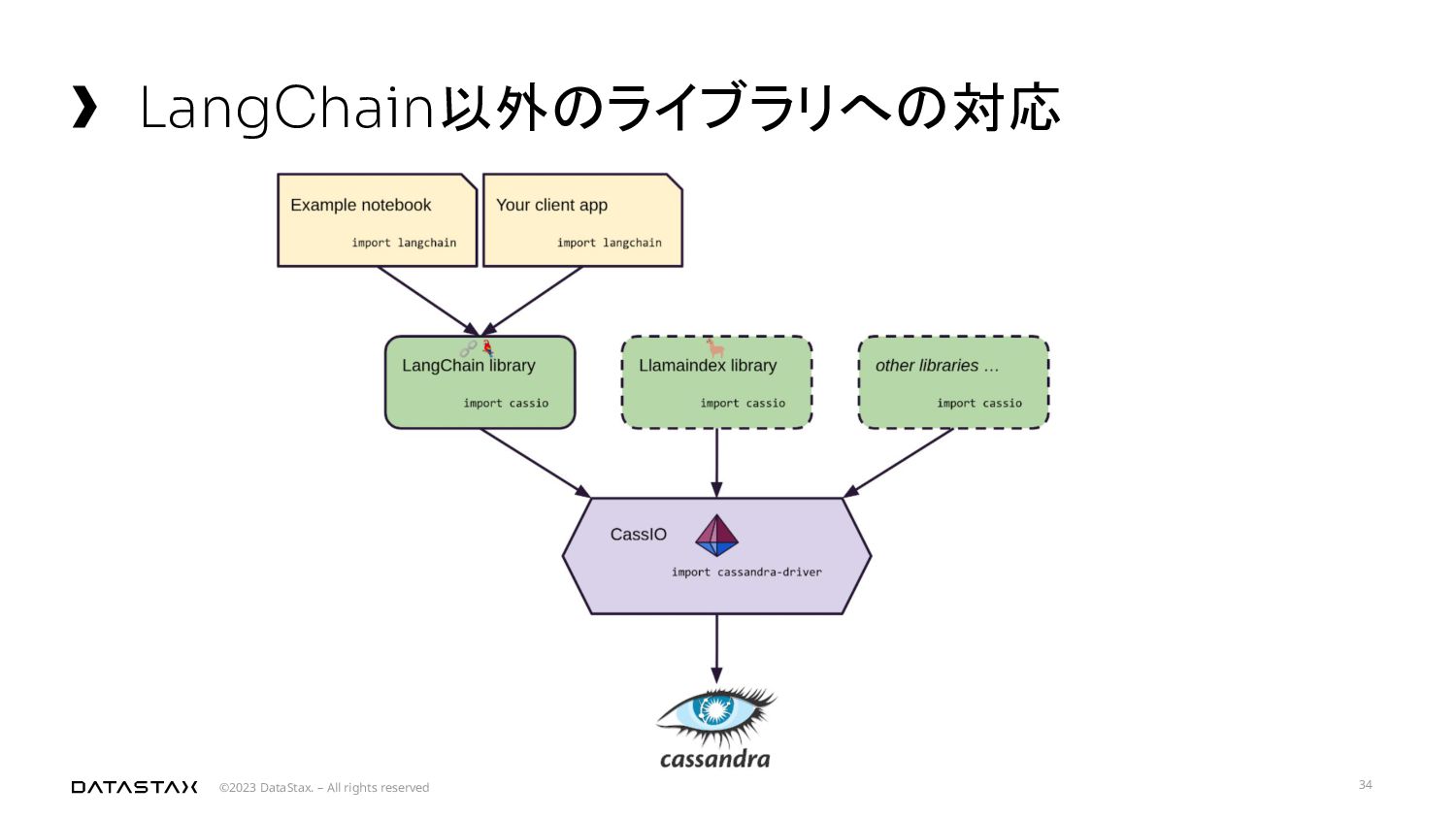{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
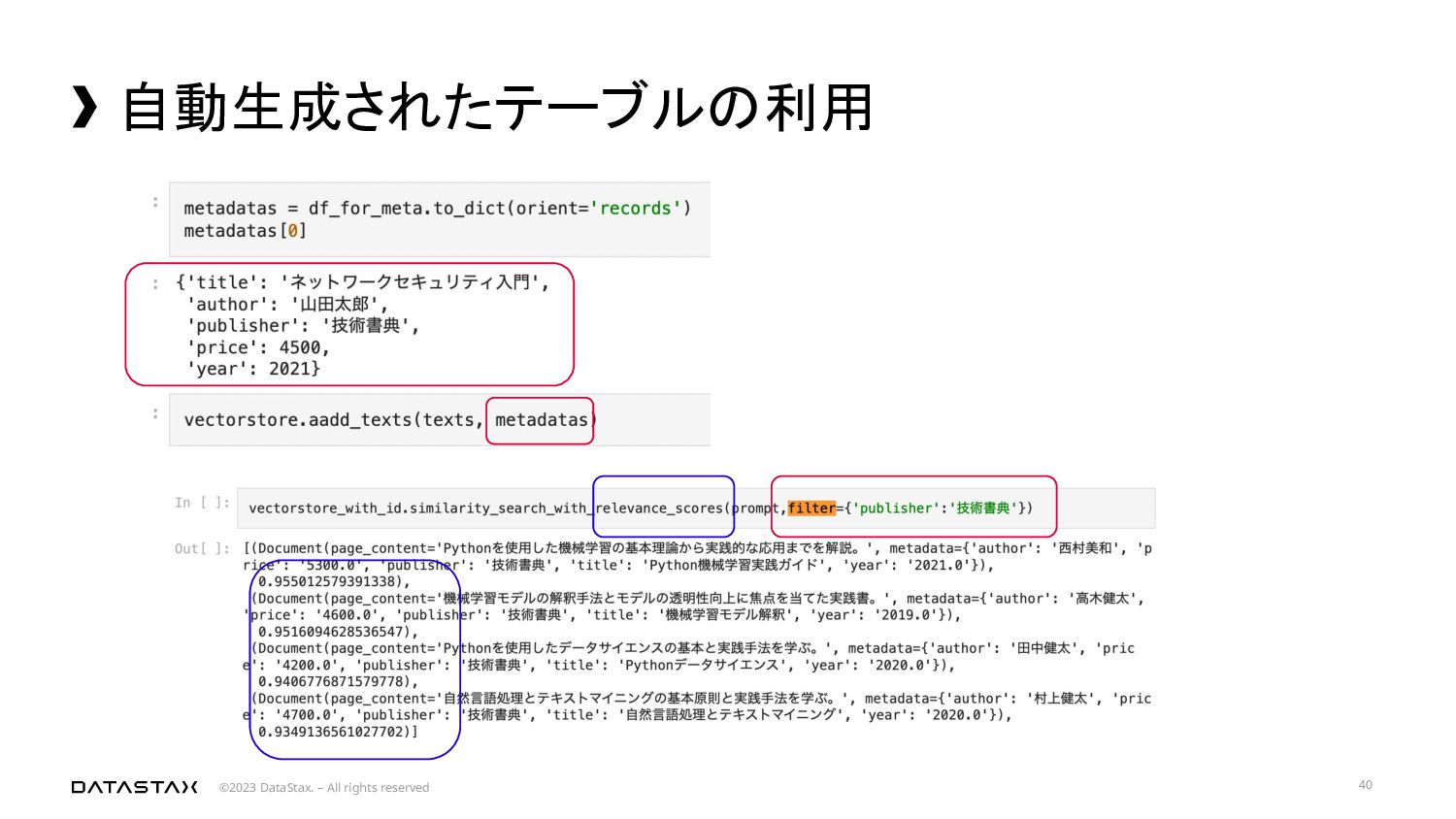{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
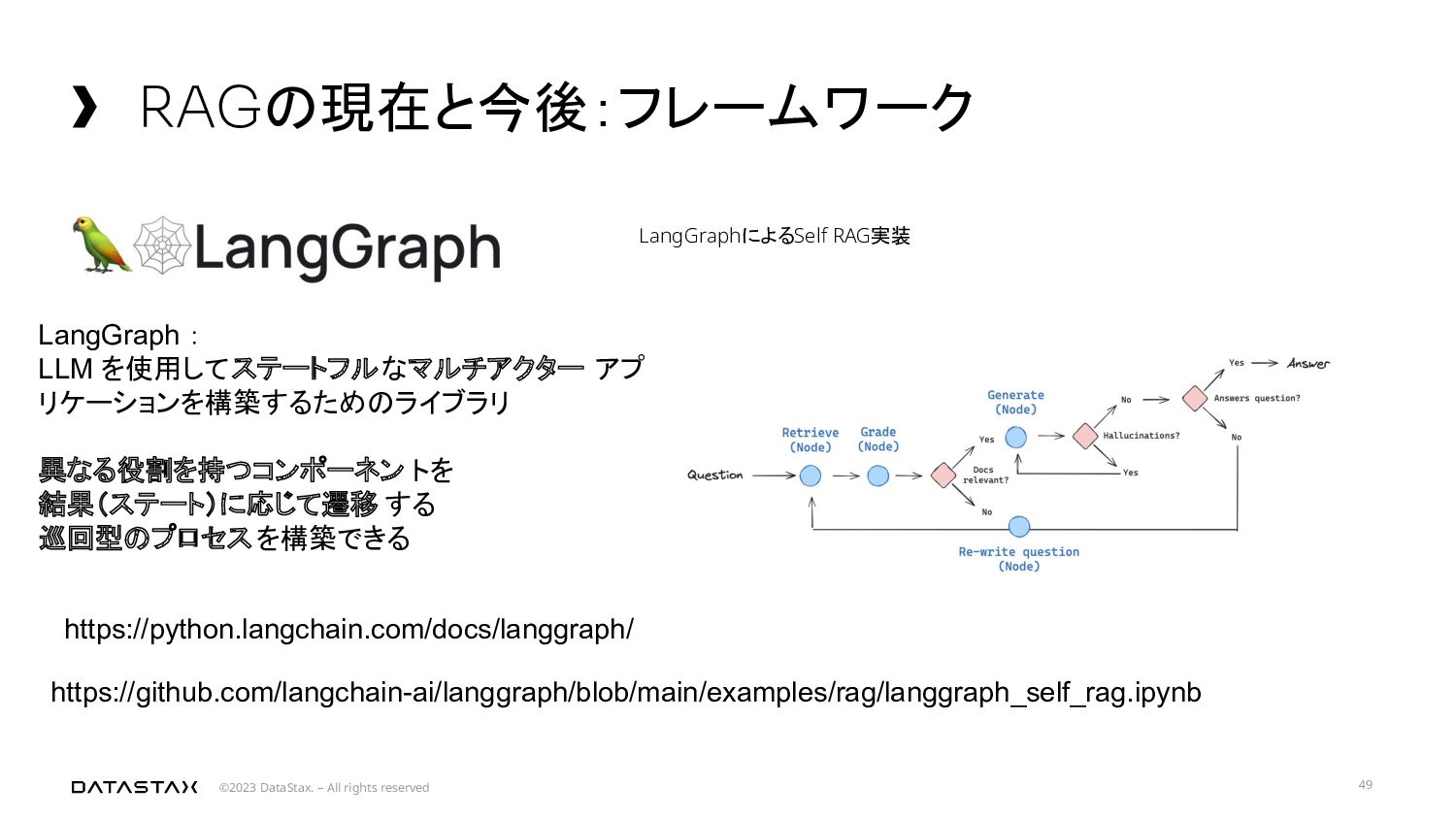{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}