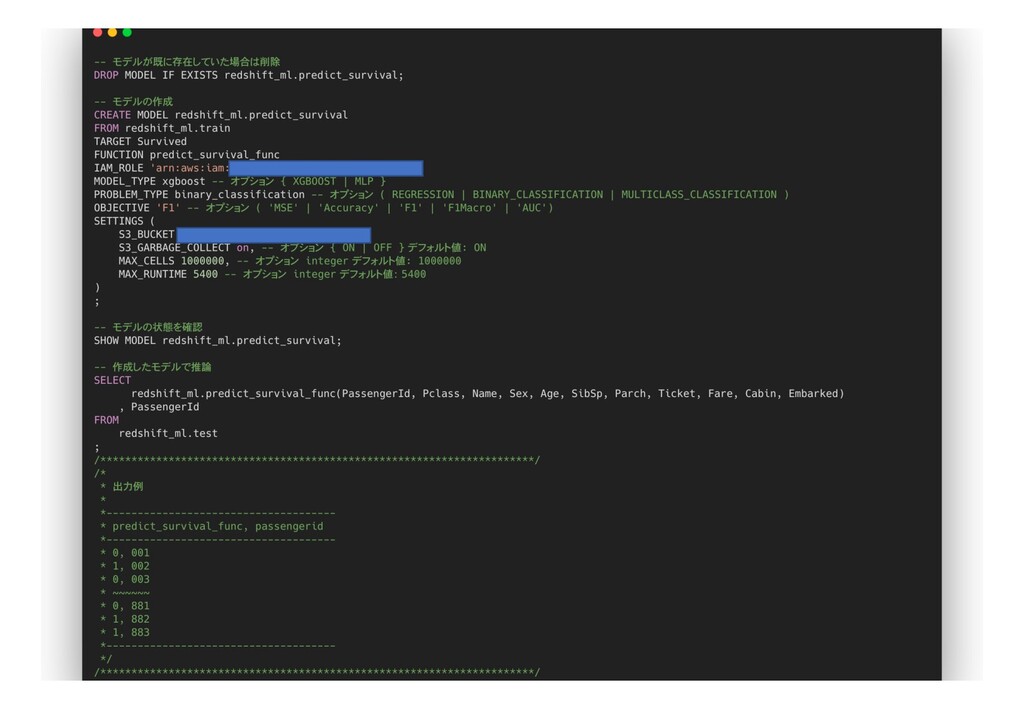
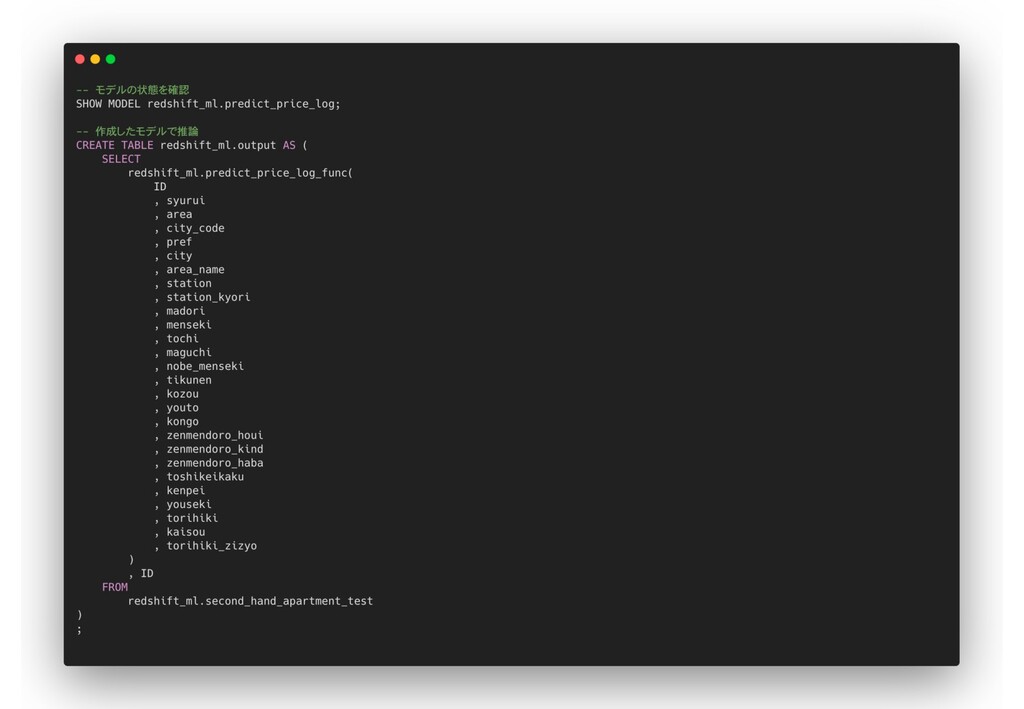
(418⾏ 11列) Ø 列 p PassengerId: 乗客のID p Survived: ⽣存したかどうか(0=No, 1=Yes) p Pclass: チケットのランク(1=1st, 2=2nd, 3=3rd) p Name: 名前 p Sex: 性別 p Age: 年齢 p SibSp: 同乗した兄弟/配偶者の数 p Parch: 同乗した親/⼦どもの数 p Ticket: チケット番号 p Fare: 運賃 p Cabin: 客室番号 p Embarked: 出港地 (C = Cherbourg, Q = Queenstown, S = Southampton) S3に配置してそれぞれ、redshift_ml.train、redshift_ml.testとしてCREATE⽂、COPY⽂を実⾏ Redshift MLを試す kaggleチュートリアルのタイタニックデータでモデルを作成
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}