Concurrency and parallelism in Ruby are more and more important in the future. Machines will be multi-core and parallelization is often the way these days to speed things up.
At a hardware level, this parallel world is not always a nice and simple place to live. As Ruby implementations get faster and hardware more parallel, these details will matter for you as a Ruby developer too.
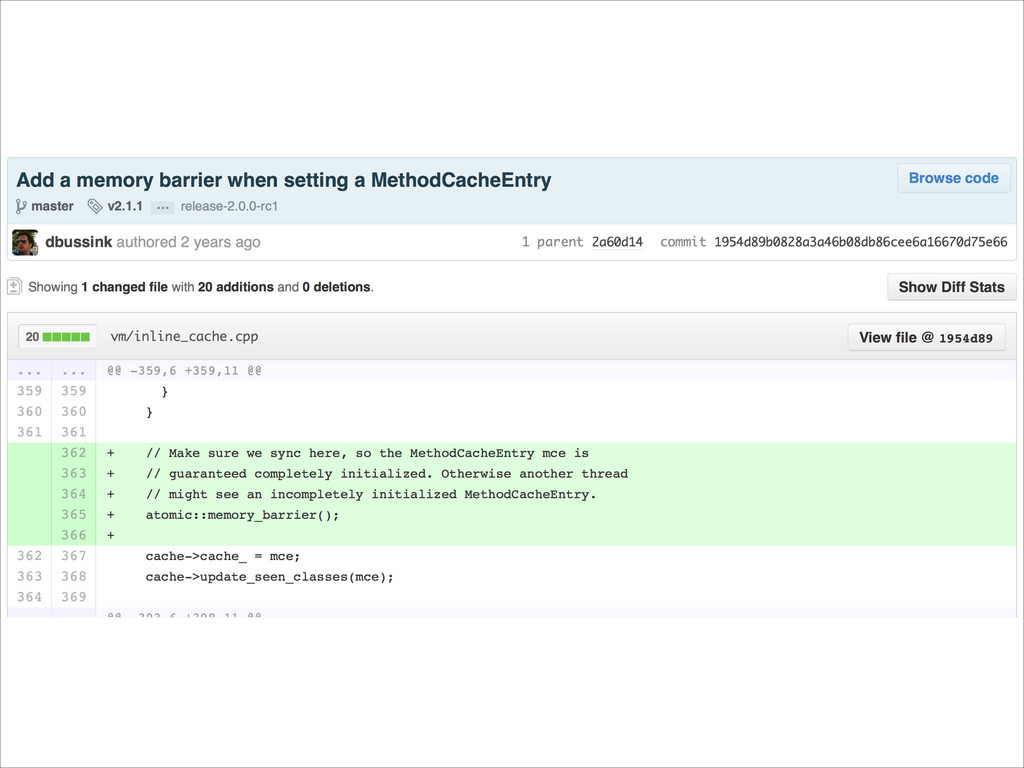
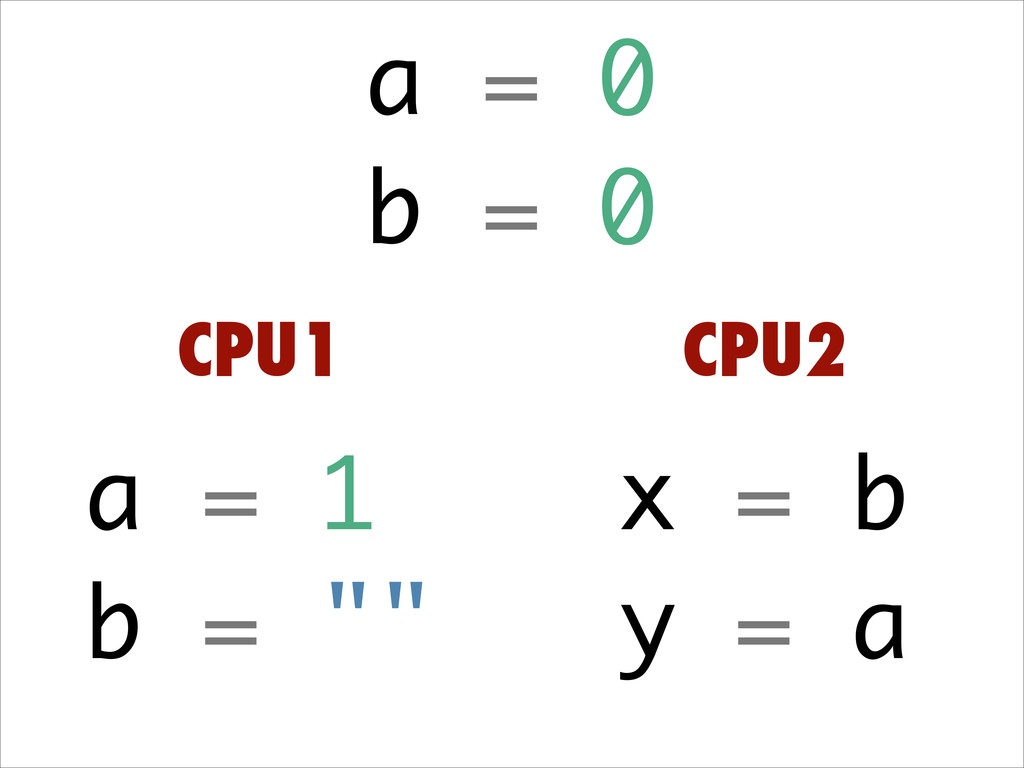
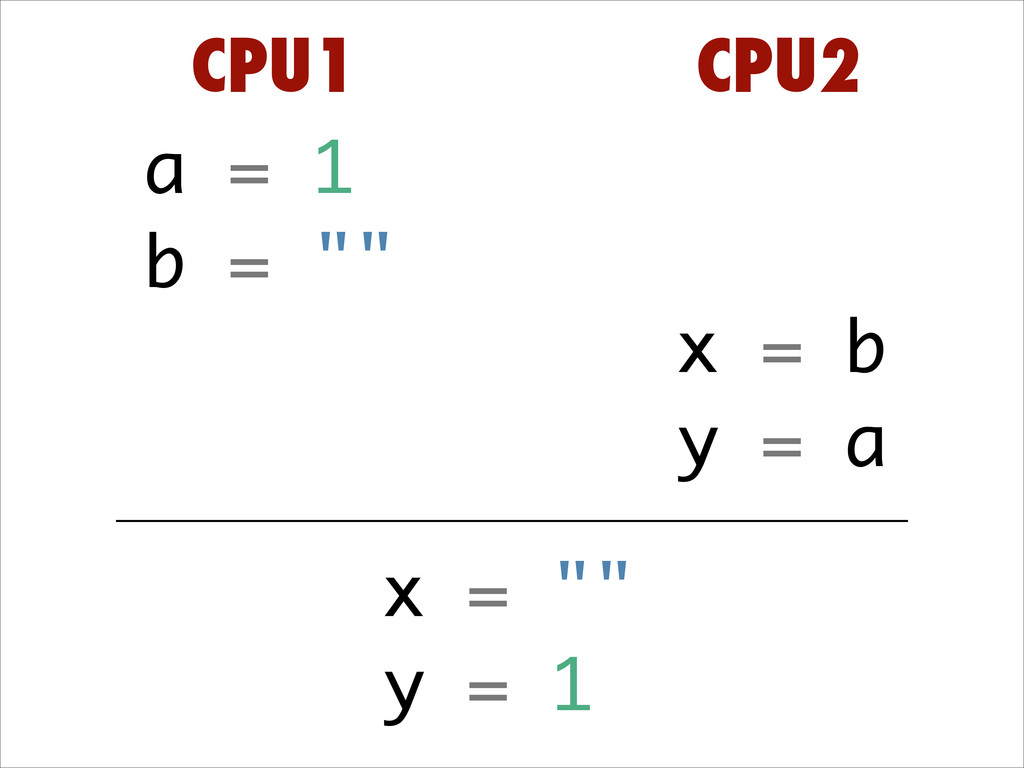
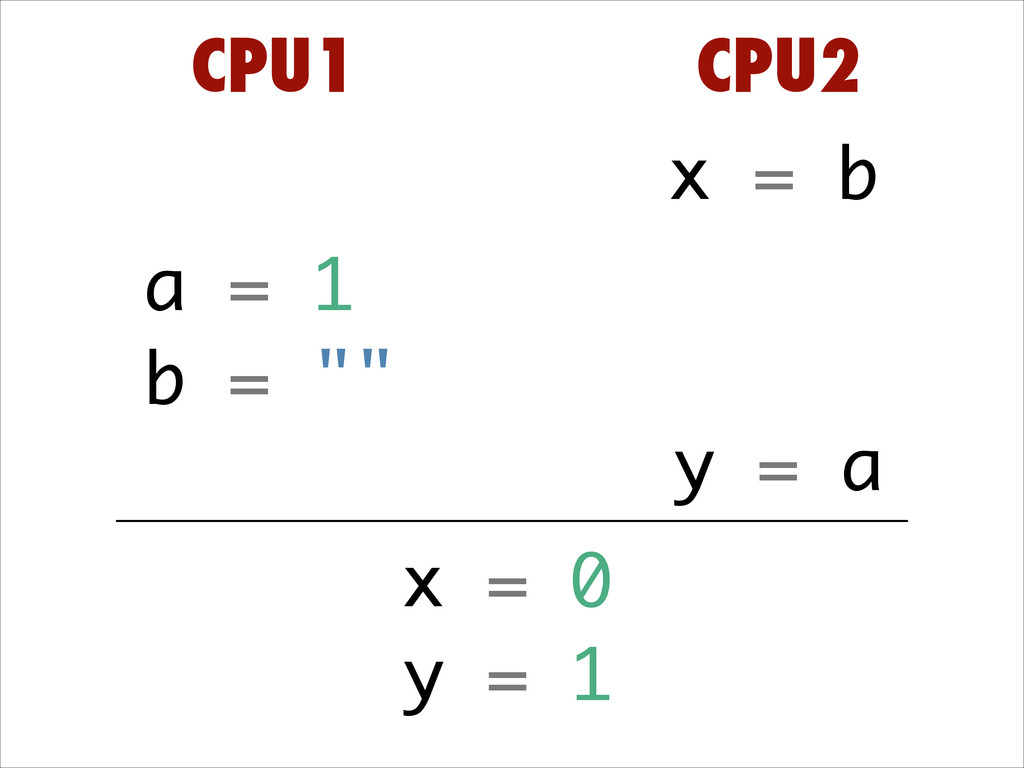
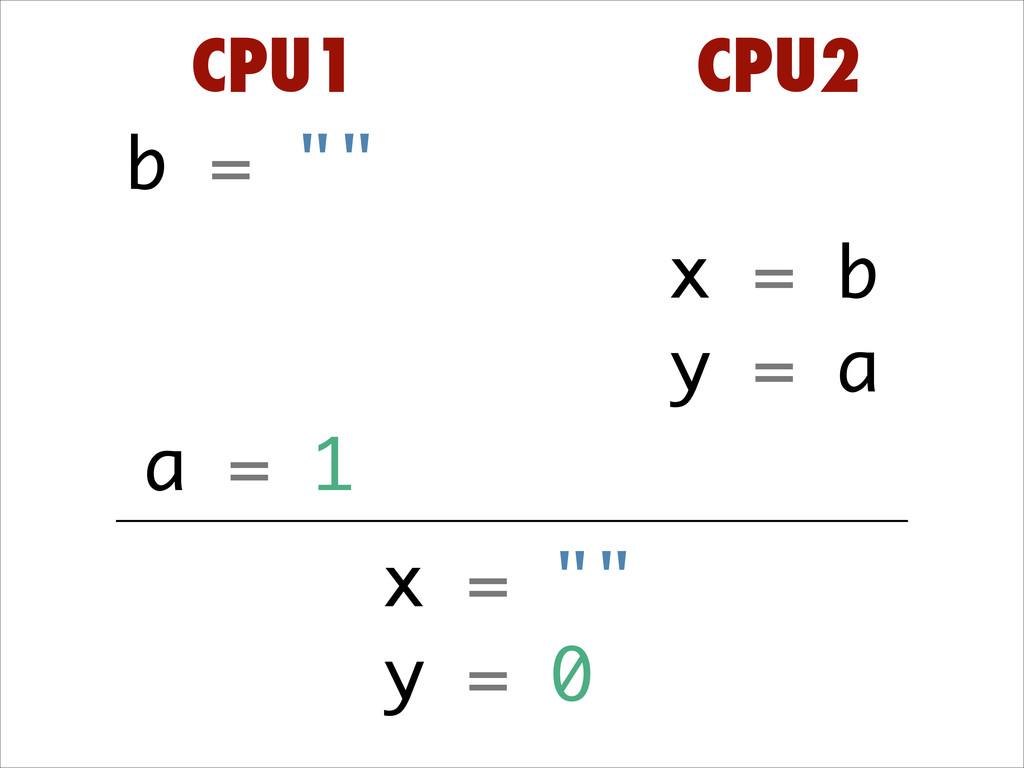
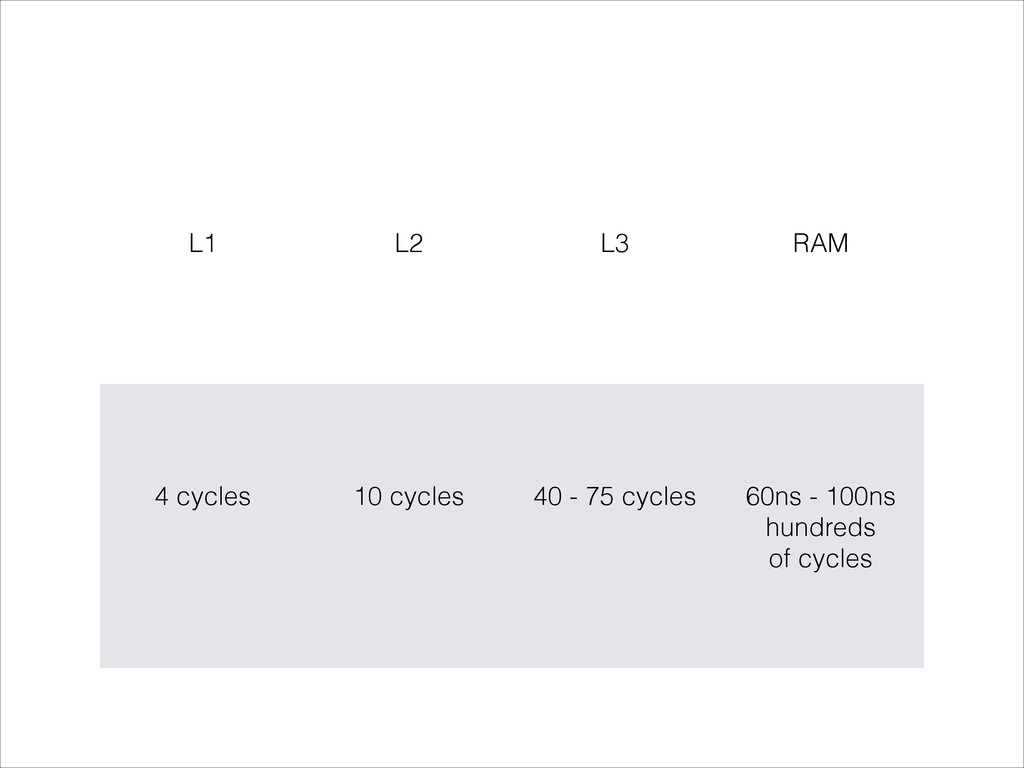
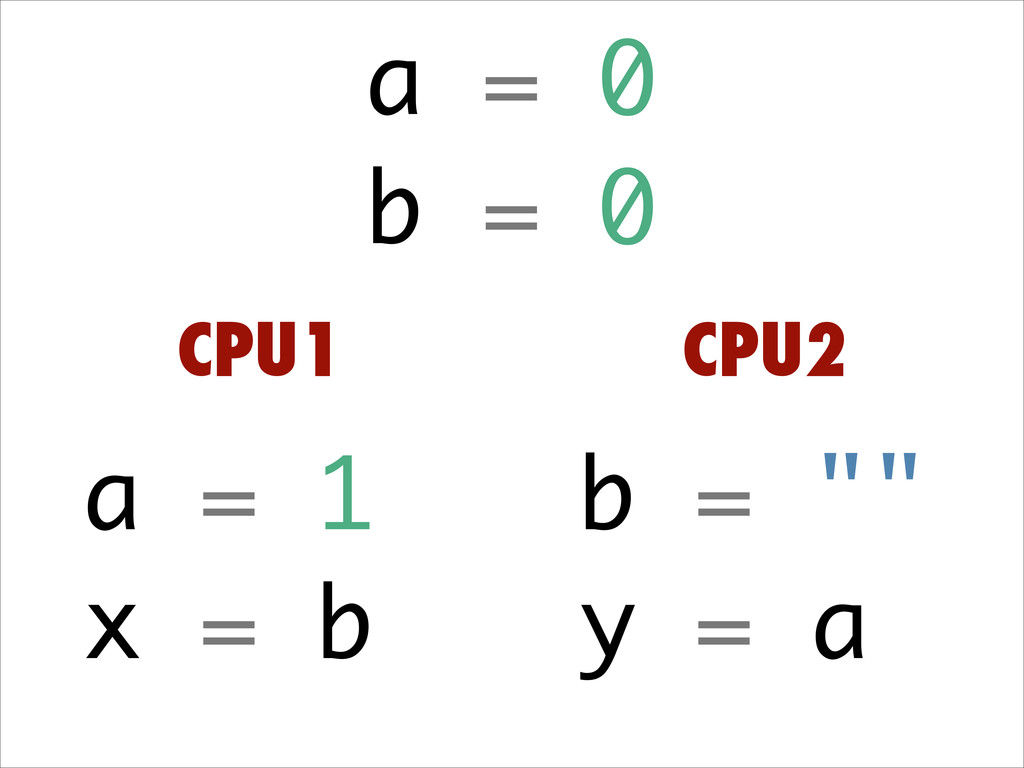
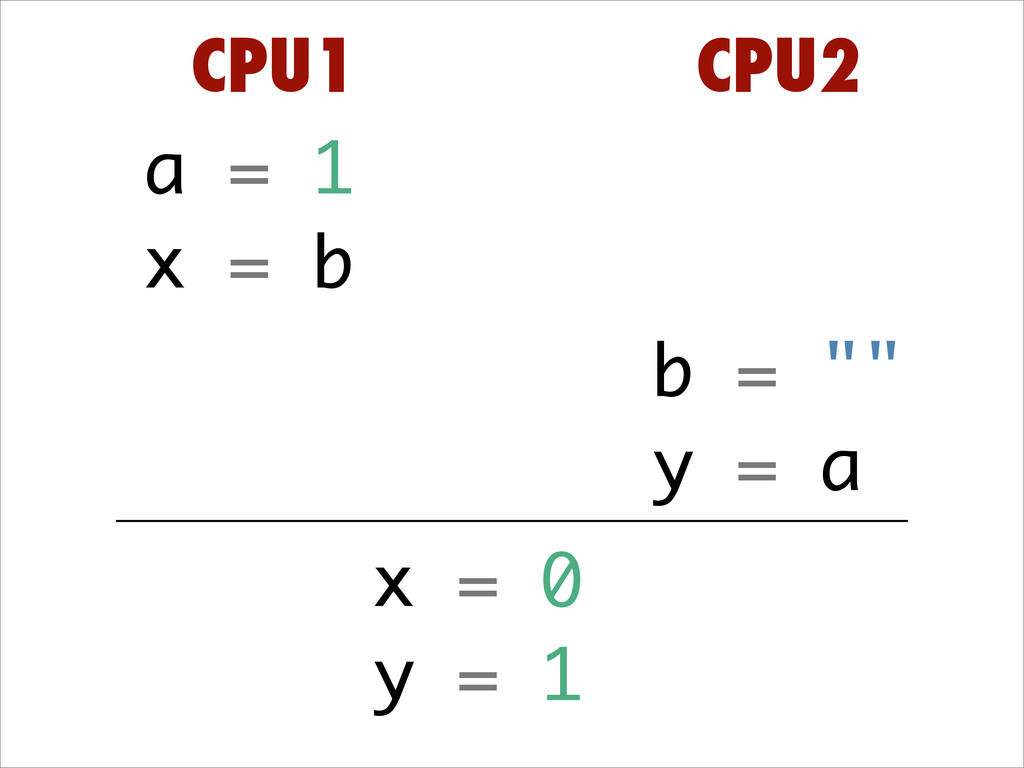
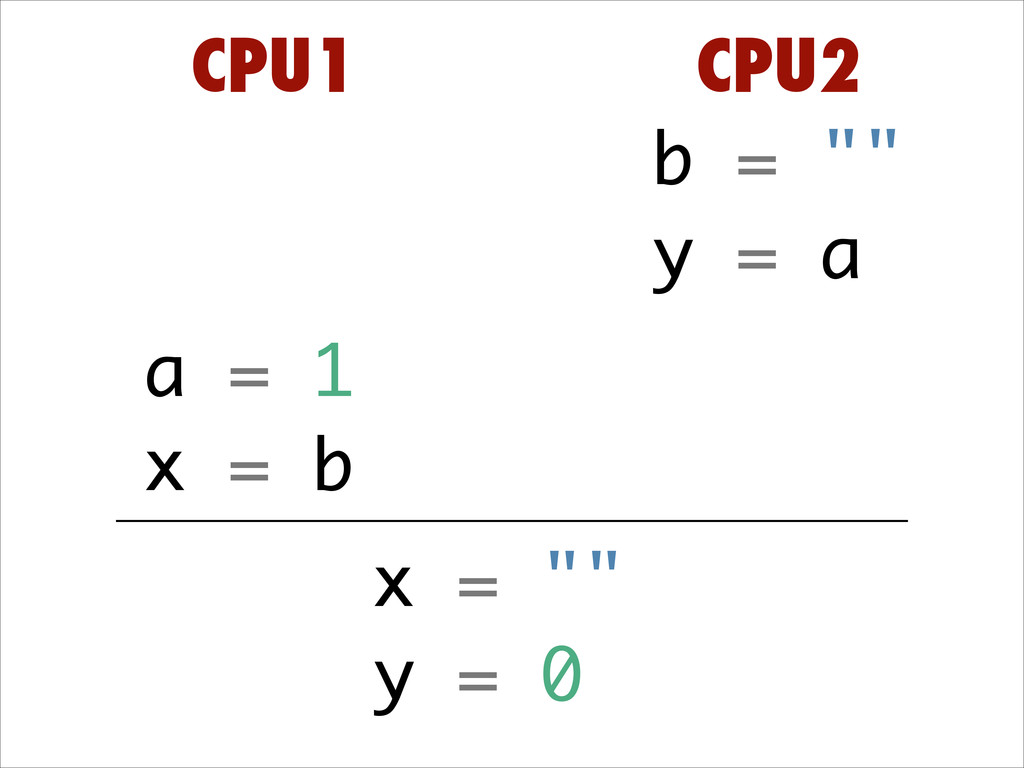
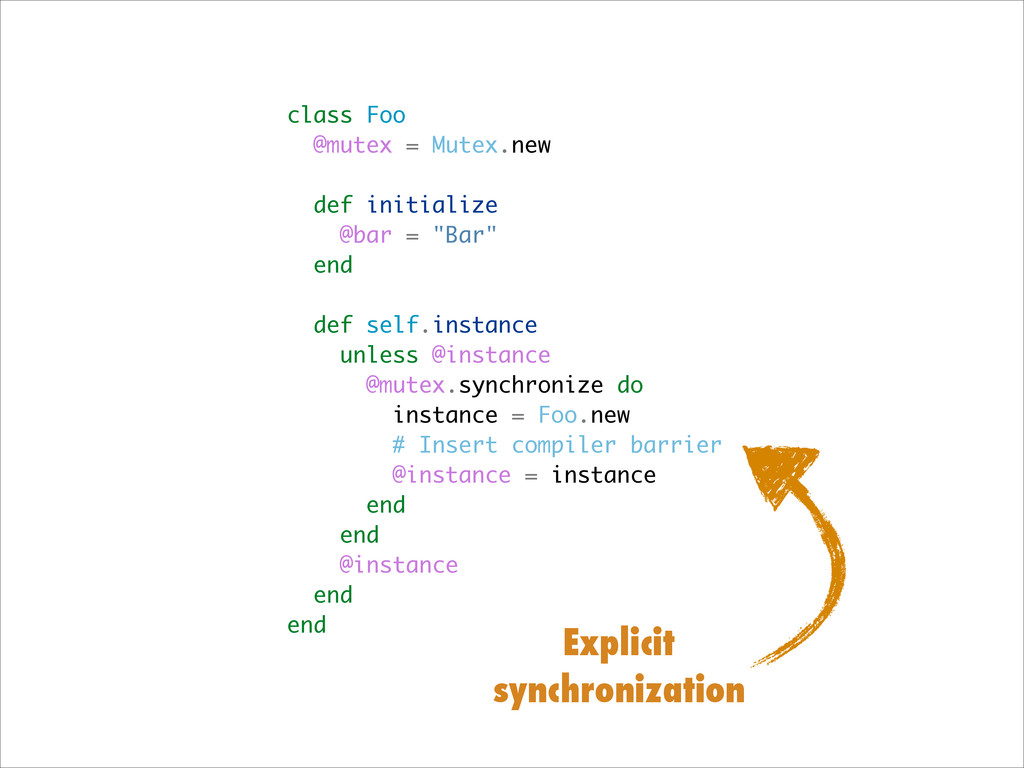
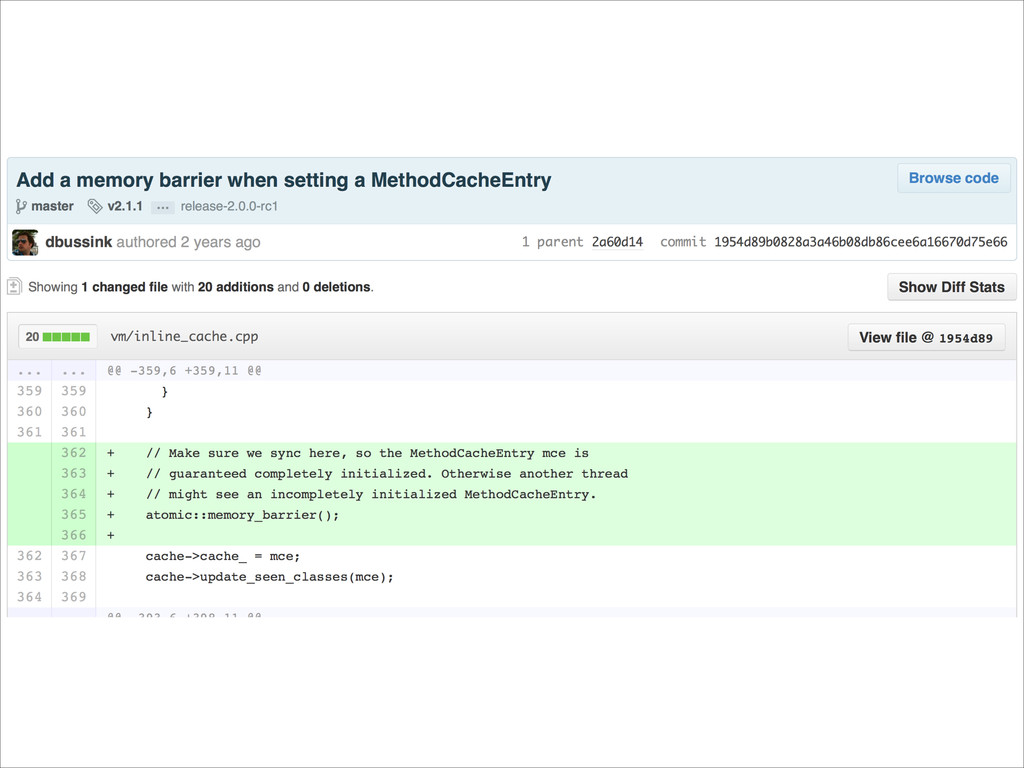
Want to know about the pitfalls are of double check locking? No idea what out of order execution means? How CPU cache effects can lead to obscure crashes? What this thing called a memory barrier is? How false sharing can cause performance issues?
Come listen if you want to know about nitty gritty details that can affect your Ruby application in the future.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
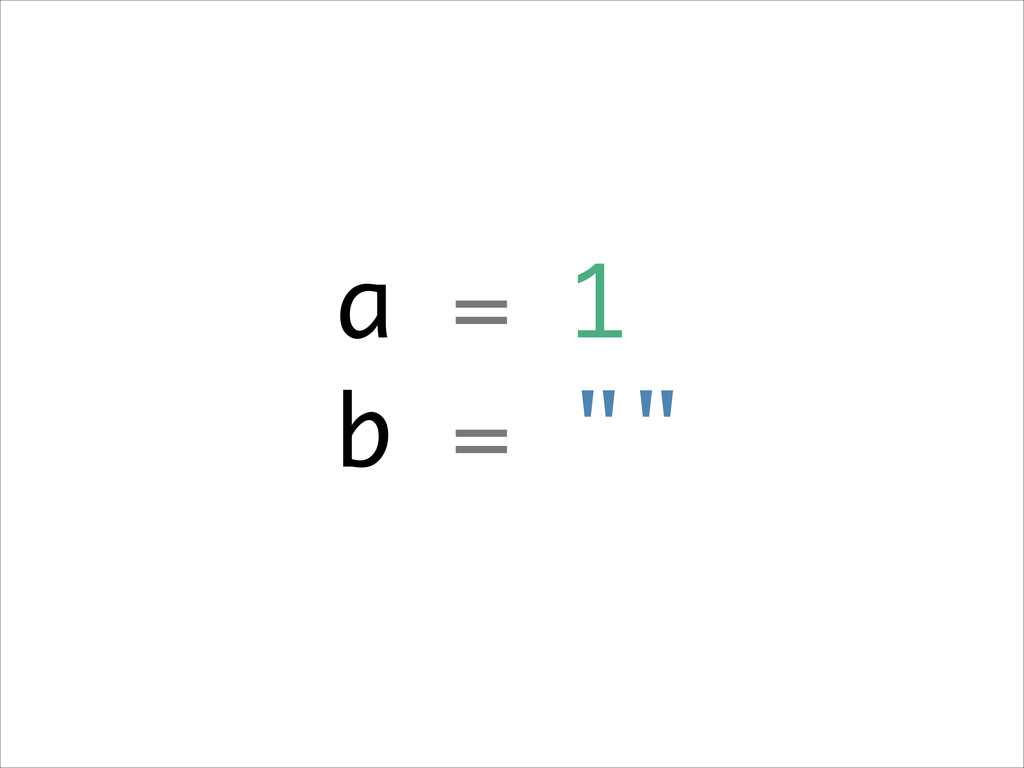{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
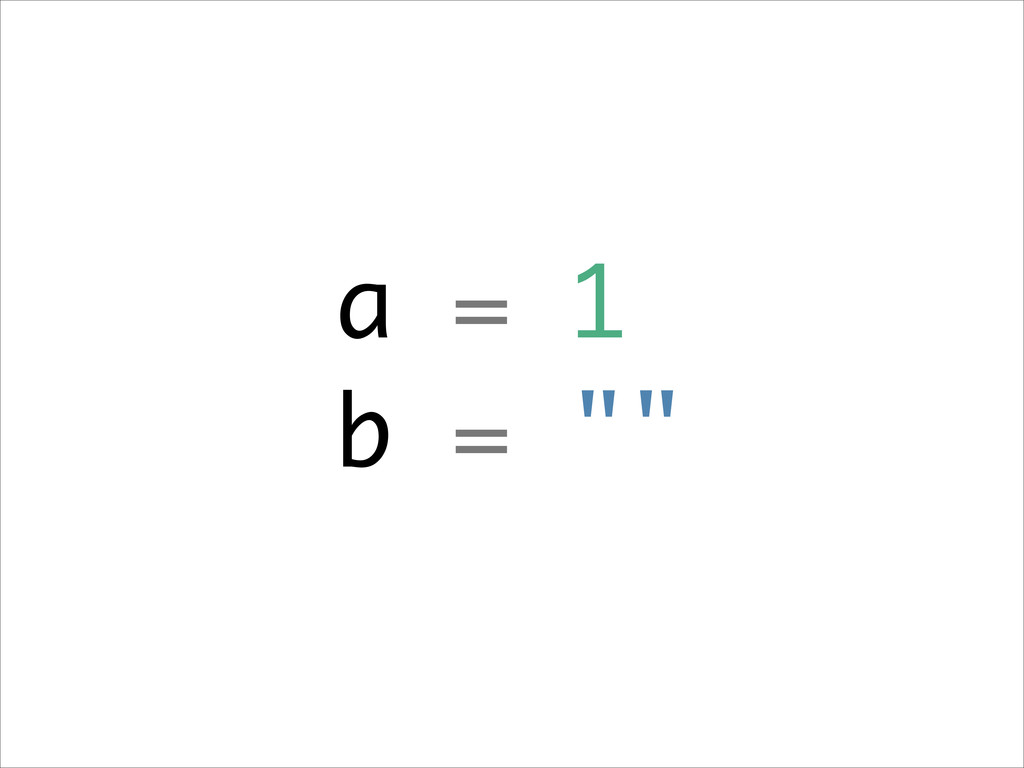{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}