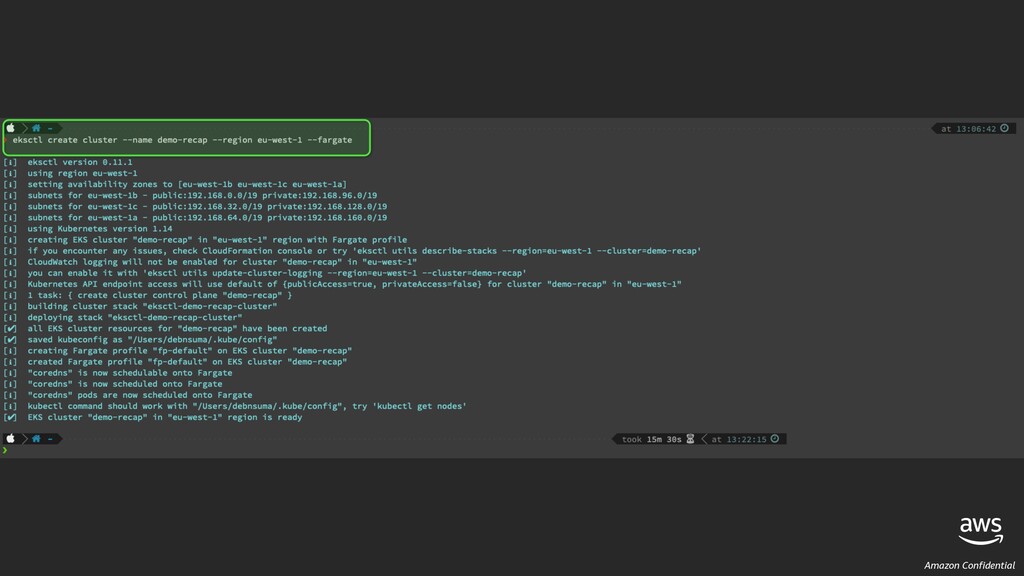
This is the content I presented at the re:Invent re:Cap 2019 events at different cities across India, Sri Lanka and Bangladesh.
Feel free to reach out to me on Twitter(@_sumand) or LinkedIN(/sumand)
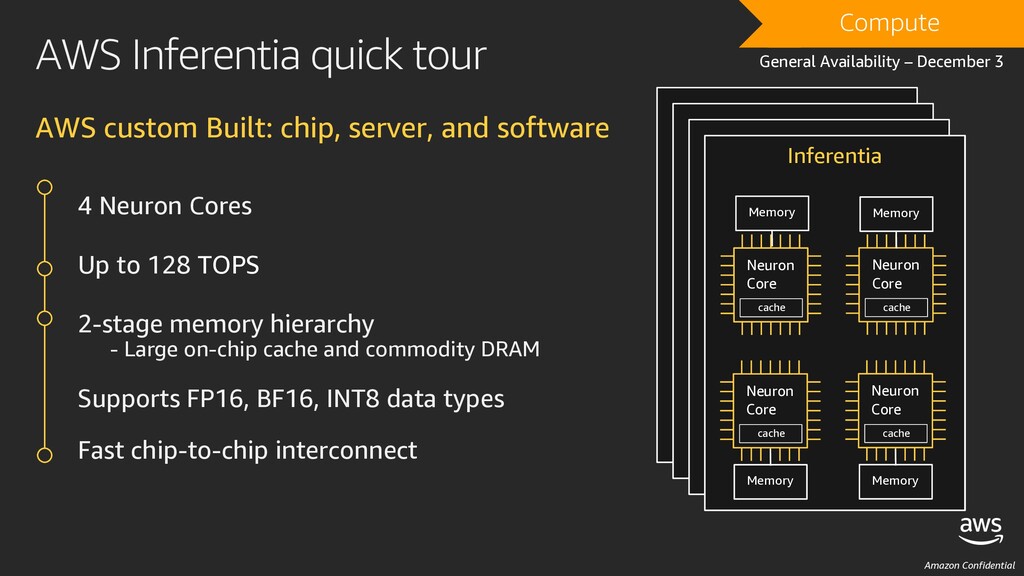
lowest cost machine learning inference in the cloud Featuring AWS Inferentia, the first custom ML chip designed by AWS Inf1 delivers up to 3X higher throughput and up to 40% lower cost per inference compared to GPU powered G4 instances Compute General Availability – December 3 L E A R N M O R E CMP324-R: Deliver high performance ML inference with AWS Inferentia Wednesday, 7pm, Aria Natural language processing Personalization Object detection Speech recognition Image processing Fraud detection
at a very low cost • 64 teraOPS on 16-bit floating point (FP16 and BF16) and mixed-precision data. • 128 teraOPS on 8-bit integer (INT8) data. • Neuron SDK: https://github.com/aws/aws-neuron-sdk • Available in Deep Learning AMIs and Deep Learning Containers • TensorFlow and Apache MXNet, PyTorch coming soon Instance Name Inferentia Chips vCPUs RAM EBS Bandwidth inf1.xlarge 1 4 8 GiB Up to 3.5 Gbps inf1.2xlarge 1 8 16 GiB Up to 3.5 Gbps inf1.6xlarge 4 24 48 GiB 3.5 Gbps inf1.24xlarge 16 96 192 GiB 14 Gbps
for your cloud workloads Graviton1 Processor Graviton2 Processor DRAFT Compute Preview – December 3 L E A R N M O R E CMP322-R: Deep dive on EC2 instances powered by AWS Graviton Wednesday 9:15am, MGM
better price-performance for general purpose, compute intensive, and memory intensive workloads. l M6g C6g R6g DRAFT Built for: General-purpose workloads such as application servers, mid-size data stores, and microservices Instance storage option: M6gd Built for: Compute intensive applications such as HPC, video encoding, gaming, and simulation workloads Instance storage option: C6gd Built for: Memory intensive workloads such as open-source databases, or in-memory caches Instance storage option: R6gd Compute Preview – December 3 L E A R N M O R E CMP322-R: Deep dive on EC2 instances powered by AWS Graviton Wednesday 9:15am, MGM
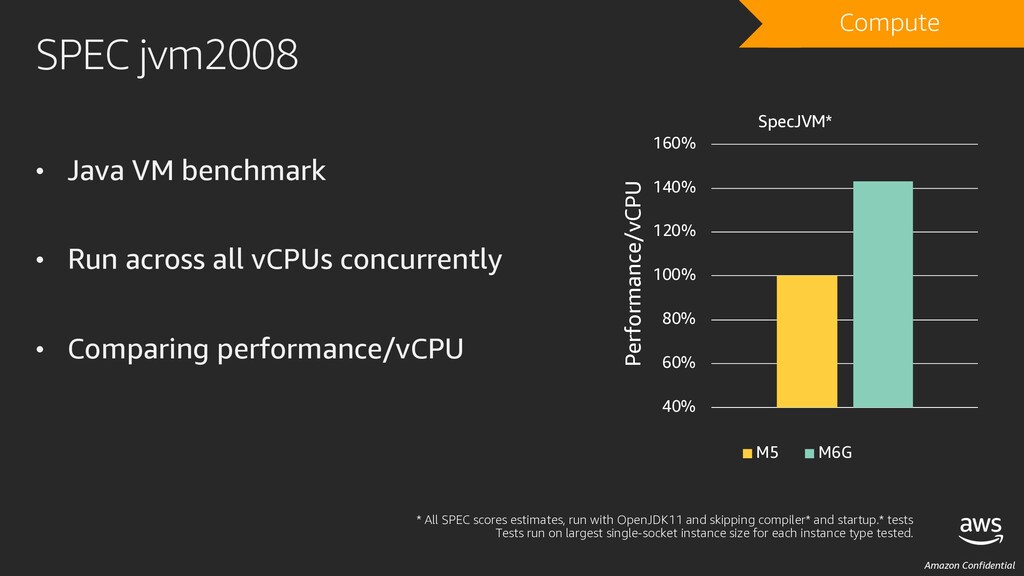
• Run on all vCPUs concurrently • Comparing performance/vCPU * All SPEC scores estimates, compiled with GCC9 -O3 -march=native, run on largest single socket size for each instance type tested. 40% 60% 80% 100% 120% 140% 160% SPECint2017 Rate SPECfp2017 rate Performance/vCPU SPECcpu2017 Rate* M5 M6G DRAFT Compute
across all vCPUs concurrently • Comparing performance/vCPU * All SPEC scores estimates, run with OpenJDK11 and skipping compiler* and startup.* tests Tests run on largest single-socket instance size for each instance type tested. 40% 60% 80% 100% 120% 140% 160% Performance/vCPU SpecJVM* M5 M6G DRAFT Compute
it easy for scientists and developers to explore and experiment with quantum computing. DRAFT Quantum Technology Preview – December 2 LEARN MORE CMP213: Introducing Quantum Computing with AWS Wednesday 11:30am, Venetian
further protect highly sensitive data within EC2 instances Nitro Hypervisor Instance A Enclave A Instance B EC2 Host Additional isolation within an EC2 instance Isolation between EC2 instances in the same host Local socket connection DRAFT Compute Preview – December 3
instances and EC2 Auto Scaling group for your workloads using a ML-powered recommendation engine DRAFT Management Tools General Availability – December 3 LEARN MORE CMP323: Optimize Performance and Cost for Your AWS Compute Wednesday, 10:45am, MGM
recommendations in AWS Cost Explorer Significant savings of up to 72% Flexible across instance family, size, OS, tenancy or AWS Region; also applies to AWS Fargate & soon to AWS Lambda usage Compute/Cost Management LEARN MORE CMP210: Dive deep on Savings Plans Wednesday, 5:30pm Announced – November 6 Simplify purchasing with a flexible pricing model that offers savings of up to 72% on Amazon ECS and AWS Fargate Savings Plans
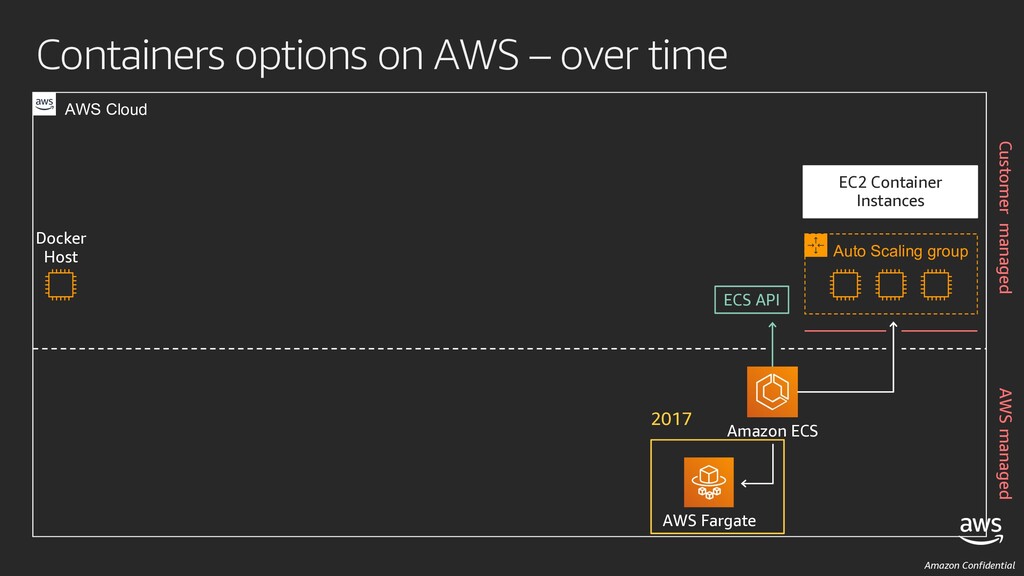
Fargate Amazon ECS EC2 Container Instances Auto Scaling group Worker nodes Auto Scaling group DIY K8S ECS API K8s API Docker Host AWS Cloud AWS managed Customer managed
Fargate Amazon ECS Amazon EKS EC2 Container Instances Auto Scaling group Worker nodes Auto Scaling group DIY K8S 2018 K8s API ECS API K8s API Docker Host AWS Cloud AWS managed Customer managed
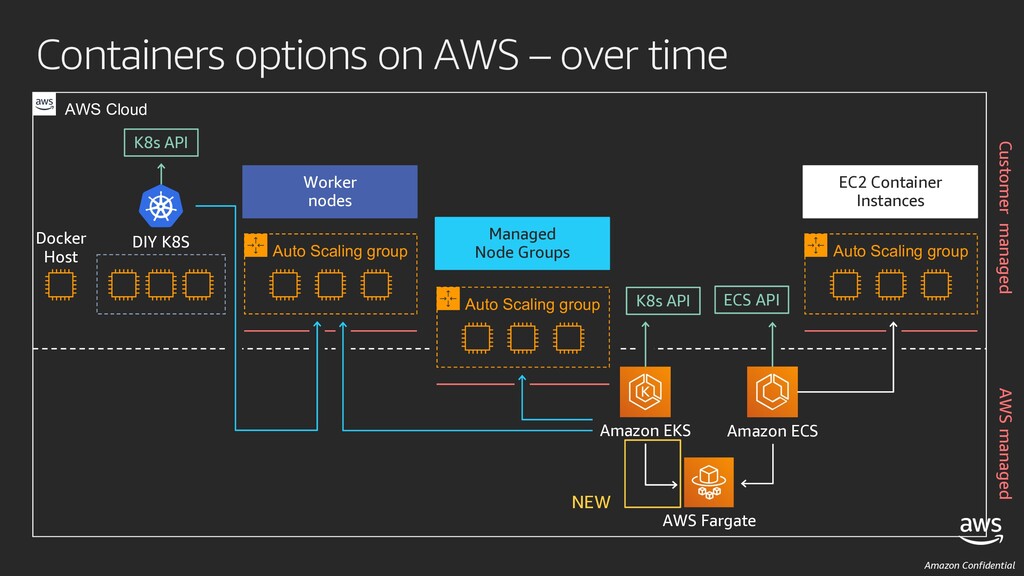
Fargate Amazon ECS Amazon EKS EC2 Container Instances Auto Scaling group Managed Node Groups Auto Scaling group Worker nodes Auto Scaling group DIY K8S 2019 K8s API ECS API K8s API Docker Host AWS Cloud AWS managed Customer managed
Fargate Amazon ECS Amazon EKS EC2 Container Instances K8s API ECS API AWS Cloud Auto Scaling group Managed Node Groups Auto Scaling group Worker nodes Auto Scaling group DIY K8S NEW Docker Host K8s API AWS managed Customer managed
MORE CON-326R - Running Kubernetes Applications on AWS Fargate Wednesday, 4pm, Aria Thursday, 1:45pm, MGM Introducing The only way to run serverless Kubernetes containers securely, reliably, and at scale Amazon EKS for AWS Fargate
access at scale for applications using shared data sets on Amazon S3. Easily create hundreds of access points per bucket, each with a unique name and permissions customized for each application. DRAFT Storage General Availability – December 3
set of APIs that provide access to directly read EBS snapshot data, enabling backup providers to achieve faster backups for EBS volumes at lower costs. L E A R N M O R E CMP305-R: Amazon EBS snapshots: What’s new, best practices, and security Thursday,1:00pm, MGM Up to 70% faster backup times More granular recovery point objectives (RPOs) Lower cost backups Amazon Confidential Compute Easily track incremental block changes on EBS volumes to achieve: General Availability – December 3
highly available, and serverless Apache Cassandra–compatible database service. Run your Cassandra workloads in the AWS cloud using the same Cassandra application code and developer tools that you use today. Apache Cassandra- compatible Performance at scale Highly available and secure No servers to manage DRAFT Databases Preview – December 3 LEARN MORE DAT324: Overview of Amazon Managed Apache Cassandra Service
Machine Learning Integration Simple, optimized, and secure Aurora, SageMaker, and Comprehend (in preview) integration. Add ML-based predictions to databases and applications using SQL, without custom integrations, moving data around, or ML experience.
database proxy feature for Amazon RDS. Pools and shares connections to make applications more scalable, more resilient to database failures, and more secure. DRAFT Databases Public Beta – December 3 LEARN MORE DAT368: Setting up database proxy servers with RDS Proxy
cost, scalable warm storage tier for Amazon Elasticsearch Service. Store up to 10 PB of data in a single cluster at 1/10th the cost of existing storage tiers, while still providing an interactive experience for analyzing logs. DRAFT Analytics Public Beta – December 3 LEARN MORE ANT229: Scalable, secure, and cost-effective log analytics
Storage Optimize your data warehouse costs by paying for compute and storage separately General Availability – December 3 L E A R N M O R E ANT213-R1: State of the Art Cloud Data Warehousing ANT230: Amazon Redshift Reimagined: RA3 and AQUA Wednesday, 10am, Venetian Delivers 3x the performance of existing cloud DWs 2x performance and 2x storage as similarly priced DS2 instances (on-demand) Automatically scales your DW storage capacity Supports workloads up to 8PB (compressed) COMPUTE NODE (RA3/i3en) SSD Cache S3 STORAGE COMPUTE NODE (RA3/i3en) SSD Cache COMPUTE NODE (RA3/i3en) SSD Cache COMPUTE NODE (RA3/i3en) SSD Cache Managed storage $/node/hour $/TB/month Introducing
Redshift runs 10x faster than any other cloud data warehouse without increasing cost DRAFT Analytics Private Beta – December 3 LEARN MORE ANT230: Amazon Redshift Reimagined: RA3 and AQUA Wednesday, 10am, Venetian AQUA brings compute to storage so data doesn't have to move back and forth High-speed cache on top of S3 scales out to process data in parallel across many nodes AWS designed processors accelerate data compression, encryption, and data processing 100% compatible with the current version of Redshift S3 STORAGE AQUA ADVANCED QUERY ACCELERATOR RA3 COMPUTE CLUSTER
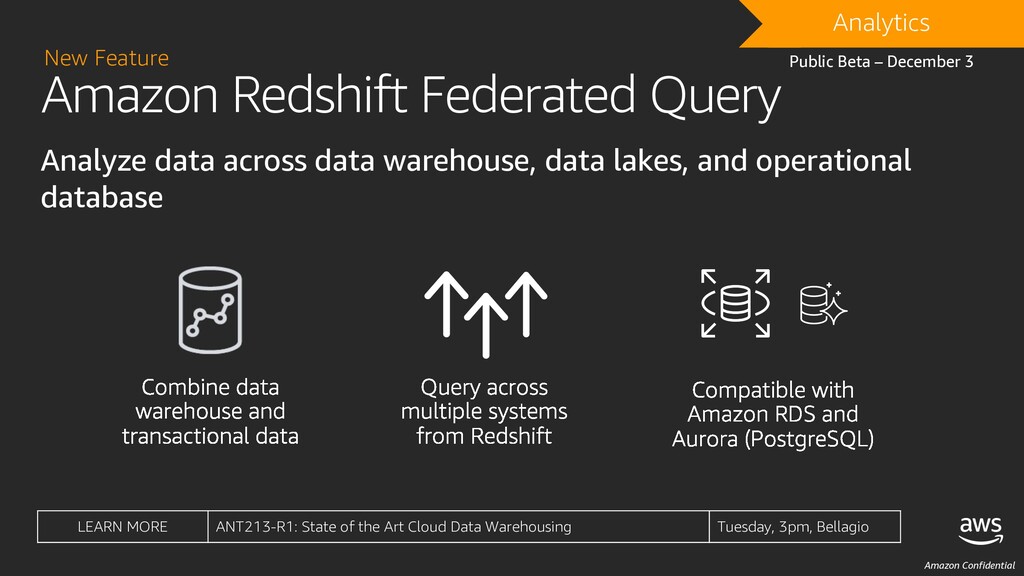
warehouse, data lakes, and operational database New Feature DRAFT Analytics Public Beta – December 3 LEARN MORE ANT213-R1: State of the Art Cloud Data Warehousing Tuesday, 3pm, Bellagio
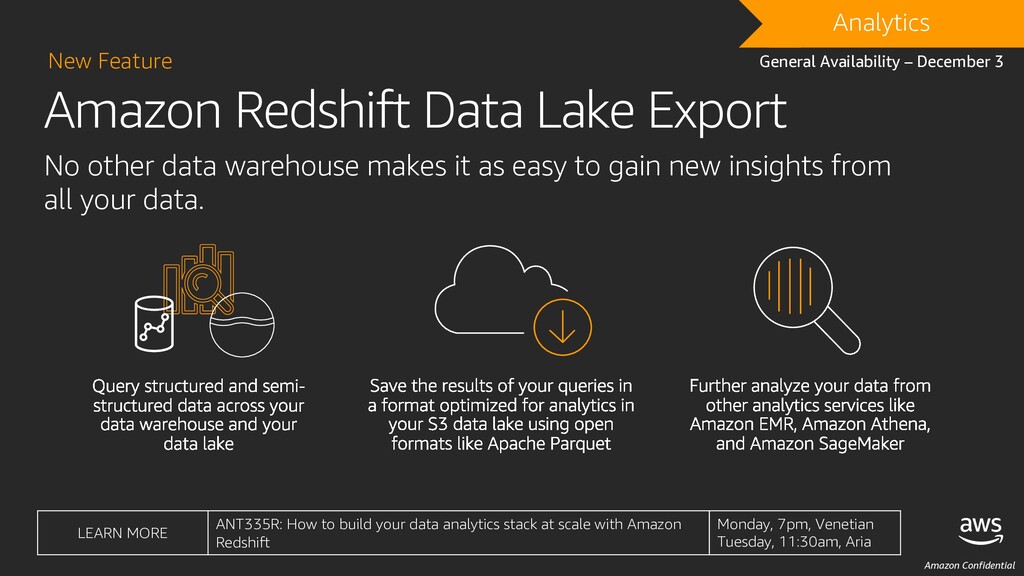
other data warehouse makes it as easy to gain new insights from all your data. DRAFT Analytics General Availability – December 3 LEARN MORE ANT335R: How to build your data analytics stack at scale with Amazon Redshift Monday, 7pm, Venetian Tuesday, 11:30am, Aria
the root cause of security findings and suspicious activities. Automatically distills & organizes data into a graph model Easy to use visualizations for faster & effective investigation Continuously updated as new telemetry becomes available Preview – December 3 DRAFT Security LEARN MORE SEC312: Introduction to Amazon Detective Thursday, 1:45pm, Venetian
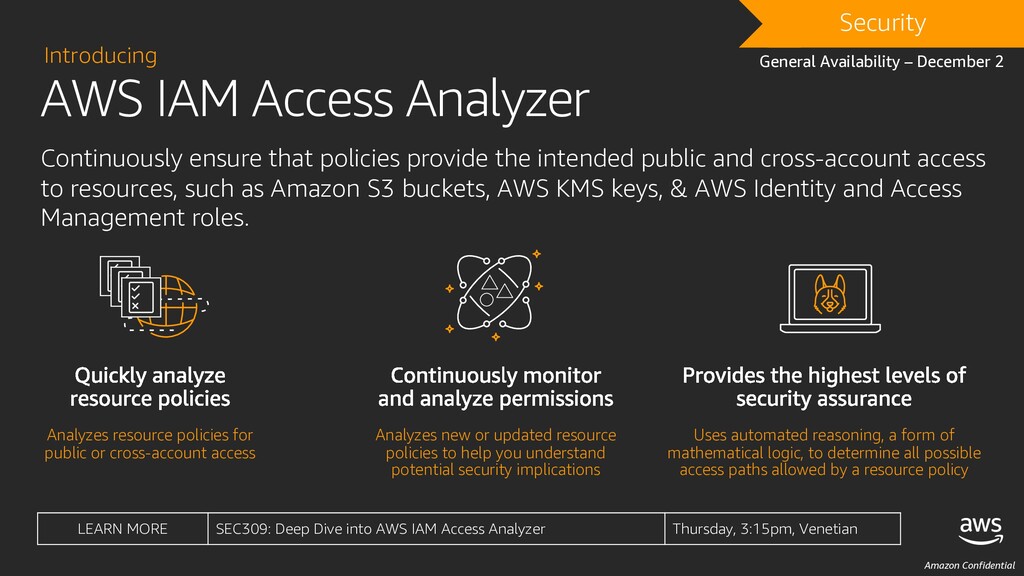
policies provide the intended public and cross-account access to resources, such as Amazon S3 buckets, AWS KMS keys, & AWS Identity and Access Management roles. General Availability – December 2 DRAFT Security Uses automated reasoning, a form of mathematical logic, to determine all possible access paths allowed by a resource policy Analyzes new or updated resource policies to help you understand potential security implications Analyzes resource policies for public or cross-account access LEARN MORE SEC309: Deep Dive into AWS IAM Access Analyzer Thursday, 3:15pm, Venetian
Availability – December 3 DRAFT Networking AWS TRANSIT GATEWAY Inter-Region Peering Build global networks by connecting transit gateways across multiple AWS Regions L E A R N M O R E NET203-L Leadership Session Networking Wednesday, 11:30am, MGM
E SVS401 - Optimizing your serverless applications Wednesday, 1:45pm, Mirage Thursday, 3:15pm, Venetian Provisioned Concurrency on AWS Lambda New Feature • Keeps functions initialized and hyper-ready, ensuring start times stay in the milliseconds • Builders have full control over when provisioned concurrency is set • No code changes are required to provision concurrency on functions in production DRAFT Serverless General Availability – December 3
compute, database, and messaging services at rates greater than 100,000 events/second, suitable for high-volume event processing workloads such as IoT data ingestion, streaming data processing and transformation. DRAFT App Integration General Availability – December 3 L E A R N M O R E API321: Event-Processing Workflows at Scale with AWS Step Functions Wednesday, 3:15pm, MGM
extends AWS infrastructure, AWS services, APIs, and tools to virtually any connected customer site. Truly consistent hybrid experience for applications across on-premises and cloud environments. Ideal for low latency or local data processing application needs. Same AWS-designed infrastructure as in AWS regional data centers (built on AWS Nitro System) delivered to customer facilities Fully managed, monitored, and operated by AWS as in AWS Regions Single pane of management in the cloud providing the same APIs and tools as in AWS Regions Compute General Availability – December 3 LEARN MORE CMP302-R: AWS Outposts: Extend the AWS experience to on-premises environments Wednesday at 11:30am, Aria Thursday at 3:15pm, Mirage Friday at 10:45am, Mirage
more locations and closer to your end-users to support ultra low latency application use cases. Use familiar AWS services and tools and pay only for the resources you use. DRAFT Compute General Availability – December 3 The first Local Zone to be released will be located in Los Angeles.
inside telco providers’ 5G networks. Enables mobile app developers to deliver applications with single-digit millisecond latencies. Pay only for the resources you use. DRAFT Compute Announcement – December 3
inside telco providers’ 5G networks. Enables mobile app developers to deliver applications with single-digit millisecond latencies. Pay only for the resources you use. DRAFT Compute Announcement – December 3
Amazon Translate: 22 new languages • Amazon Transcribe: 15 new languages, alternative transcriptions • Amazon Lex: SOC compliance, sentiment analysis, web & mobile integration with Amazon Connect • Amazon Personalize: batch recommendations • Amazon Forecast: use any quantile for your predictions With region expansion across the board!
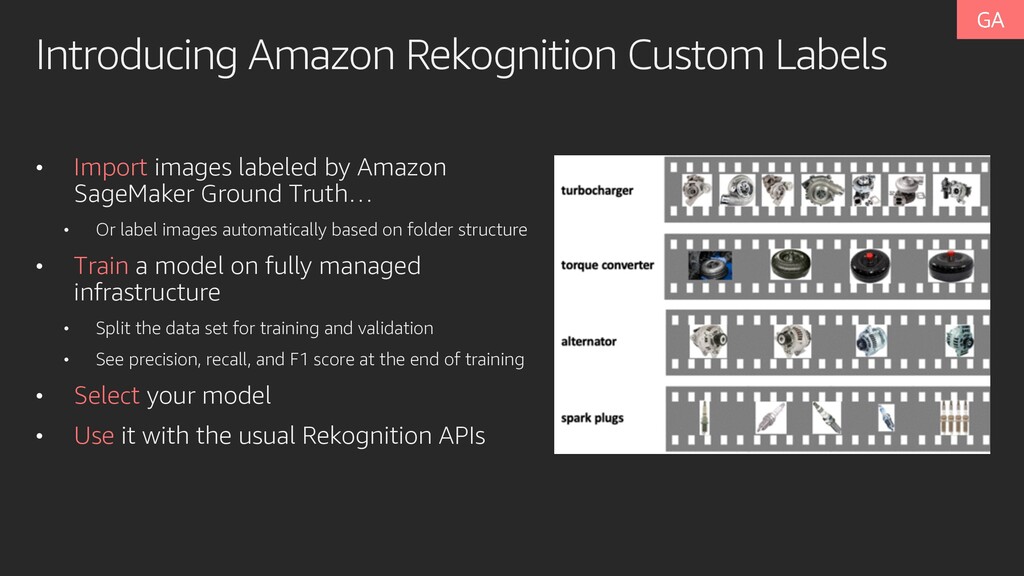
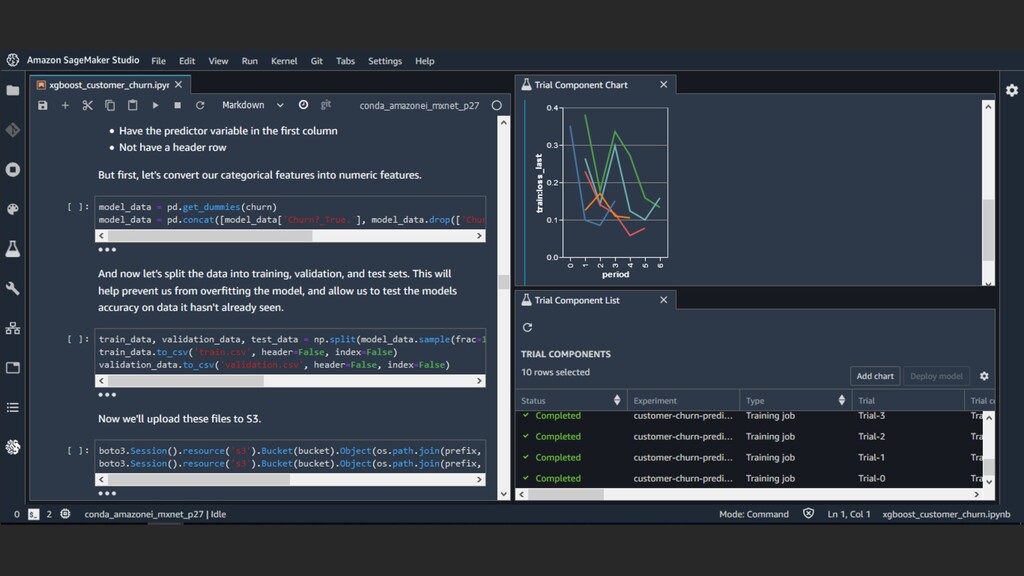
Amazon SageMaker Ground Truth… • Or label images automatically based on folder structure • Train a model on fully managed infrastructure • Split the data set for training and validation • See precision, recall, and F1 score at the end of training • Select your model • Use it with the usual Rekognition APIs
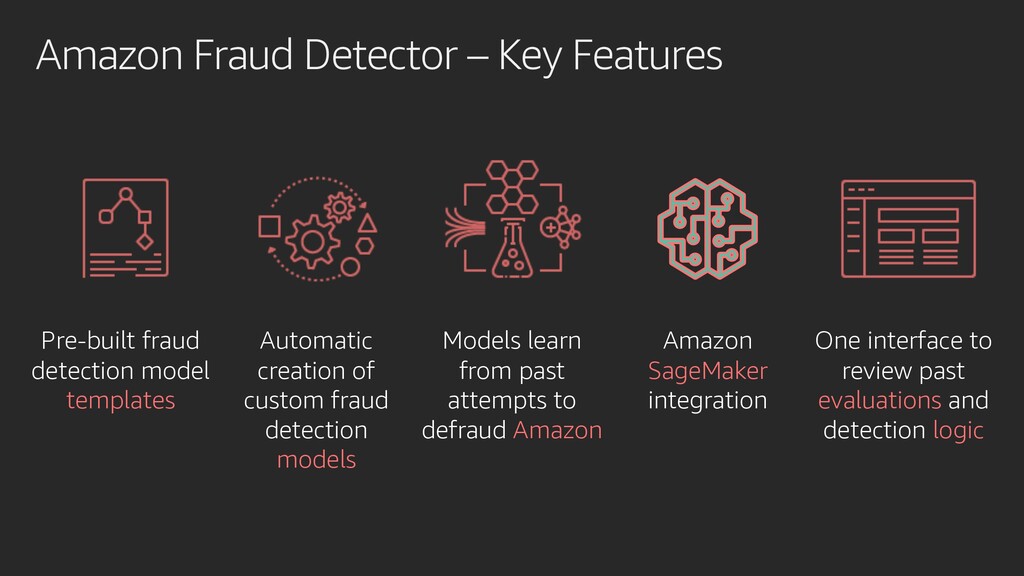
year Online business prone to fraud attacks Bad actors often change tactics Changing rules = more human reviews Dependent on others to update detection logic
are costly & hard to find One-size-fits-all models underperform Often need to supplement data Data transformation + feature engineering Fraud imbalance = needle in a haystack
templates Automatic creation of custom fraud detection models Models learn from past attempts to defraud Amazon Amazon SageMaker integration One interface to review past evaluations and detection logic
call transcription Automated contact categorization Enhanced Contact Search Real-time sentiment dashboard and alerting Presents recurring issues based on Customer feedback Identify call types such as script compliance, competitive mentions, and cancellations. Filter calls of interest based on words spoken and customer sentiment View entire call transcript directly in Amazon Connect Quickly identify when customers are having a poor experience on live calls Easily use the power of machine learning to improve the quality of your customer experience without requiring any technical expertise
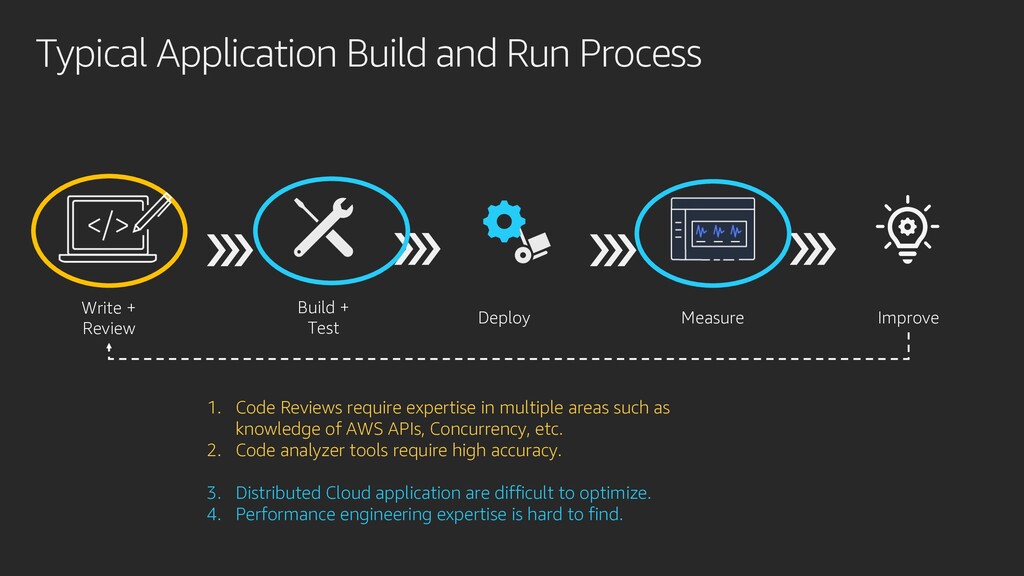
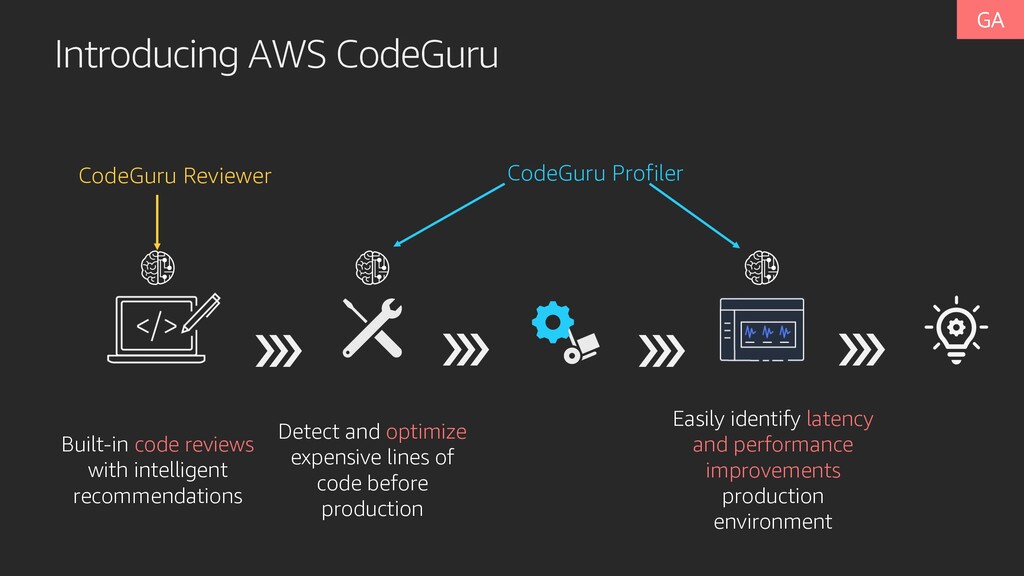
+ Test Deploy Measure Improve 1. Code Reviews require expertise in multiple areas such as knowledge of AWS APIs, Concurrency, etc. 2. Code analyzer tools require high accuracy. 3. Distributed Cloud application are difficult to optimize. 4. Performance engineering expertise is hard to find.
and optimize expensive lines of code before production Easily identify latency and performance improvements production environment CodeGuru Reviewer CodeGuru Profiler
= ddbClient.describeTable(new DescribeTableRequest().withTableName(tableName)); String status = describe.getTable().getTableStatus(); if (TableStatus.ACTIVE.toString().equals(status)) { return describe.getTable(); } if (TableStatus.DELETING.toString().equals(status)) { throw new ResourceInUseException("Table is " + status + ", and waiting for it to become ACTIVE is not useful."); } Thread.sleep(10 * 1000); elapsedMs = System.currentTimeMillis() - startTimeMs; } while (elapsedMs / 1000.0 < waitTimeSeconds); throw new ResourceInUseException("Table did not become ACTIVE after "); This code appears to be waiting for a resource before it runs. You could use the waiters feature to help improve efficiency. Consider using TableExists, TableNotExists. For more information, see https://aws.amazon.com/blogs/developer/waiters-in-the-aws-sdk-for-java/ Recommendation Code We should use waiters instead - will help remove a lot of this code. Developer Feedback
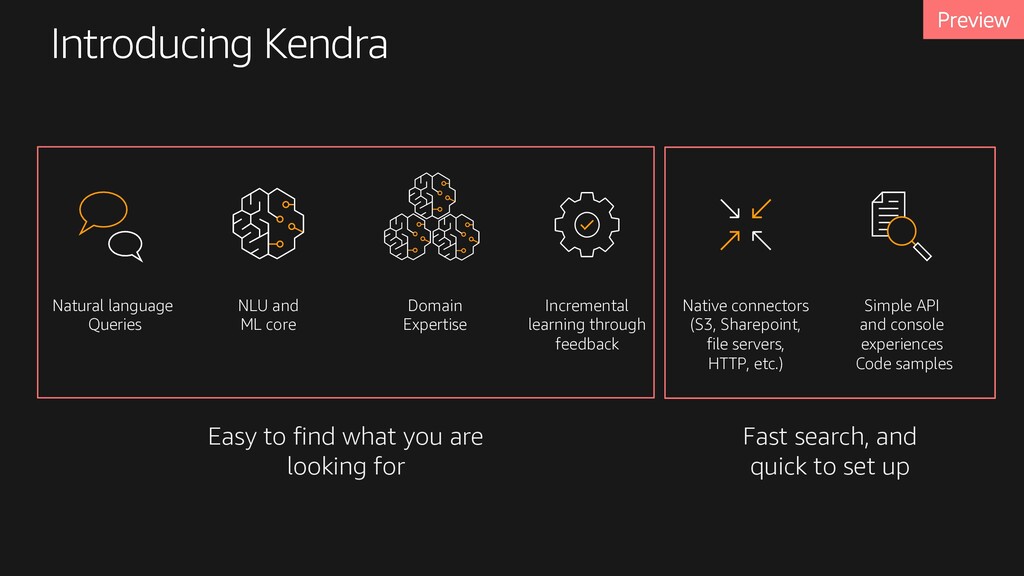
Fast search, and quick to set up Native connectors (S3, Sharepoint, file servers, HTTP, etc.) Natural language Queries NLU and ML core Simple API and console experiences Code samples Incremental learning through feedback Domain Expertise
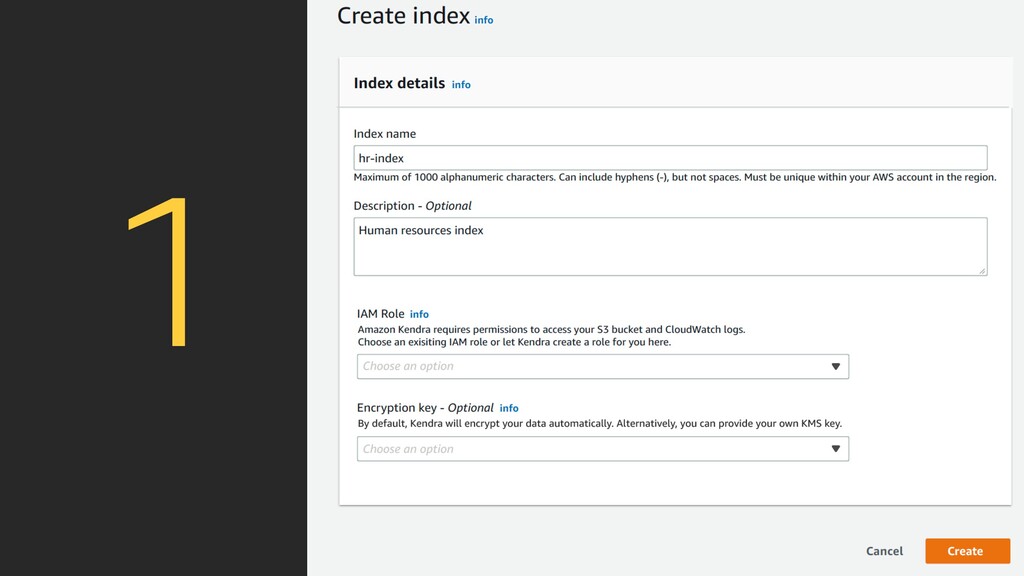
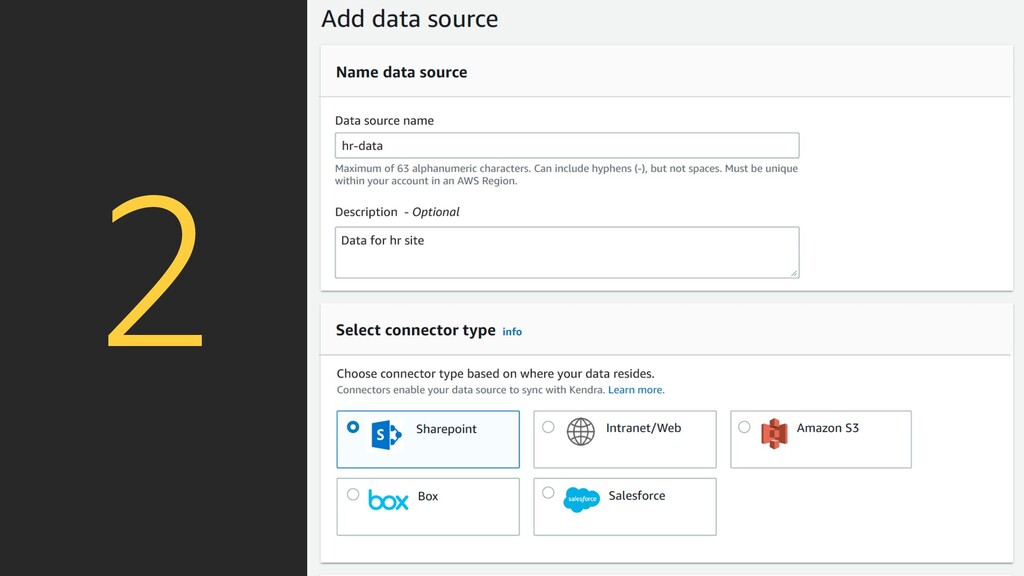
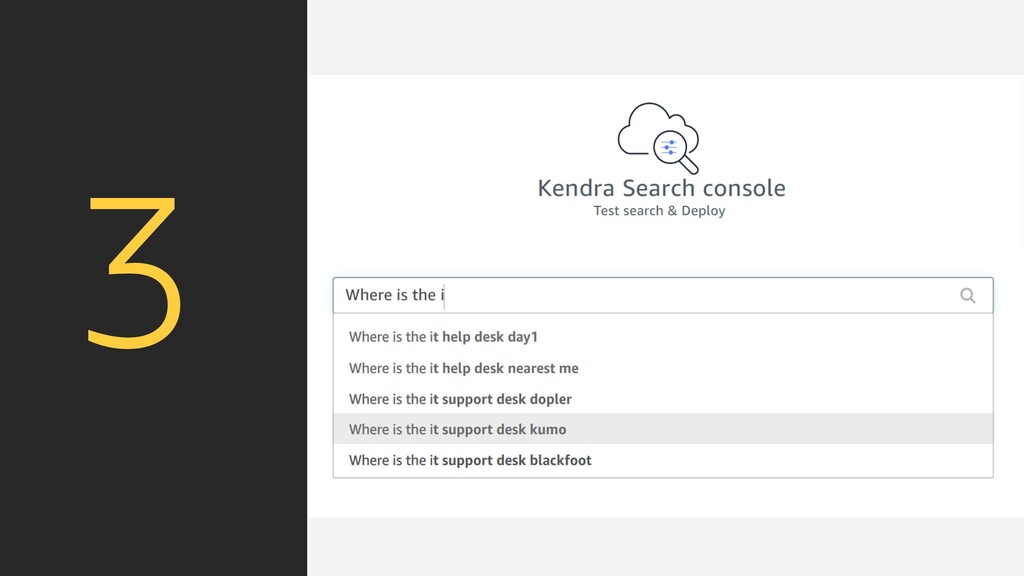
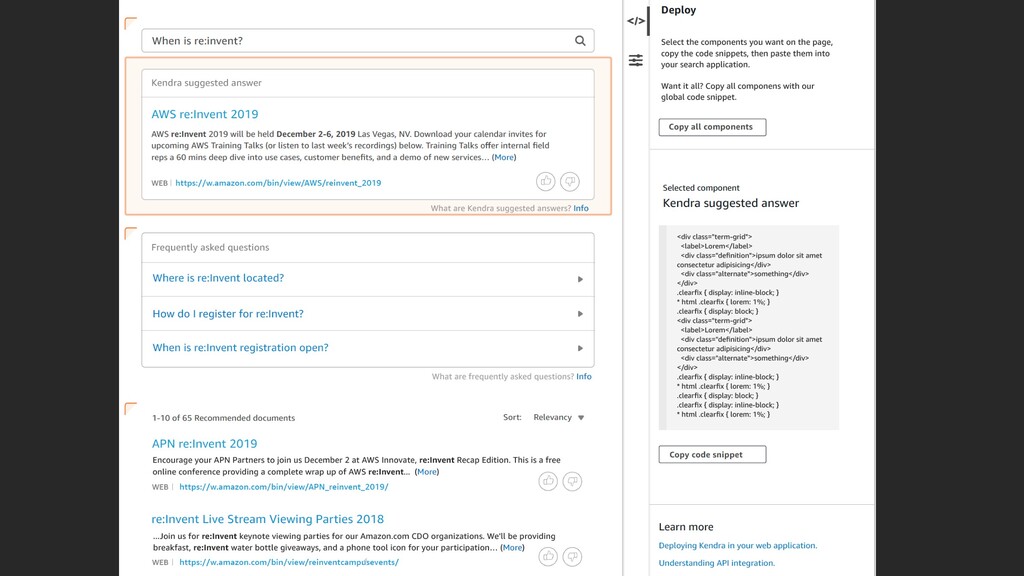
index is the place where you add your data sources to make them searchable in Kendra. Step 2 Add data sources Add and sync your data from S3, Sharepoint, Box and other data sources, to your index. Step 3 Test & deploy After syncing your data, visit the Search console page to test search & deploy Kendra in your search application.
of iterations Multiple tools needed for different phases of the ML workflow Lack of an integrated experience Large number of iterations Cumbersome, lengthy processes, resulting in loss of productivity + + =
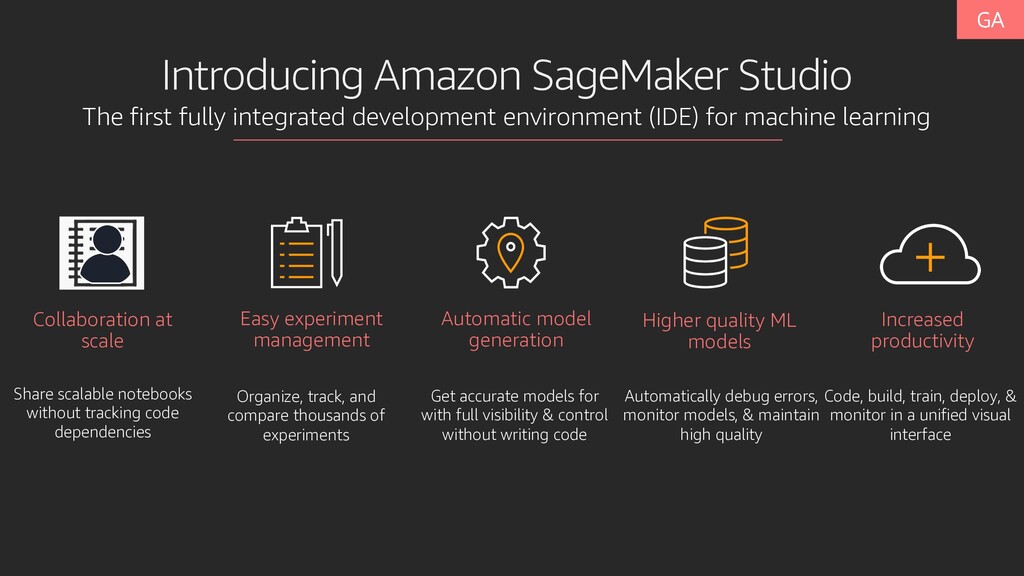
(IDE) for machine learning Organize, track, and compare thousands of experiments Easy experiment management Share scalable notebooks without tracking code dependencies Collaboration at scale Get accurate models for with full visibility & control without writing code Automatic model generation Automatically debug errors, monitor models, & maintain high quality Higher quality ML models Code, build, train, deploy, & monitor in a unified visual interface Increased productivity
manage resources Collaboration across multiple data scientists Different data science projects have different resource needs Managing notebooks and collaborating across multiple data scientists is highly complicated + + =
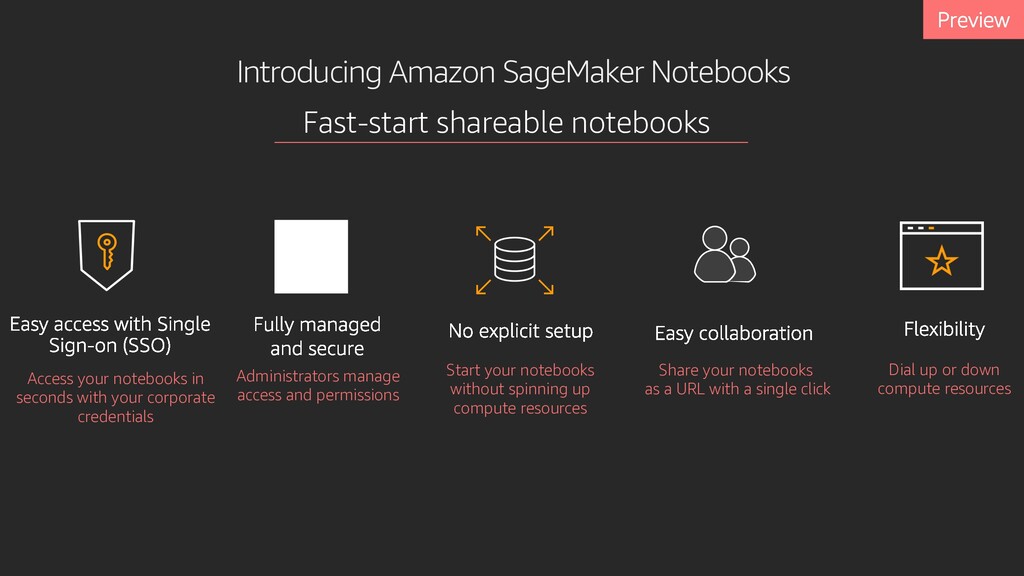
your corporate credentials Fast-start shareable notebooks Administrators manage access and permissions Share your notebooks as a URL with a single click Dial up or down compute resources Start your notebooks without spinning up compute resources
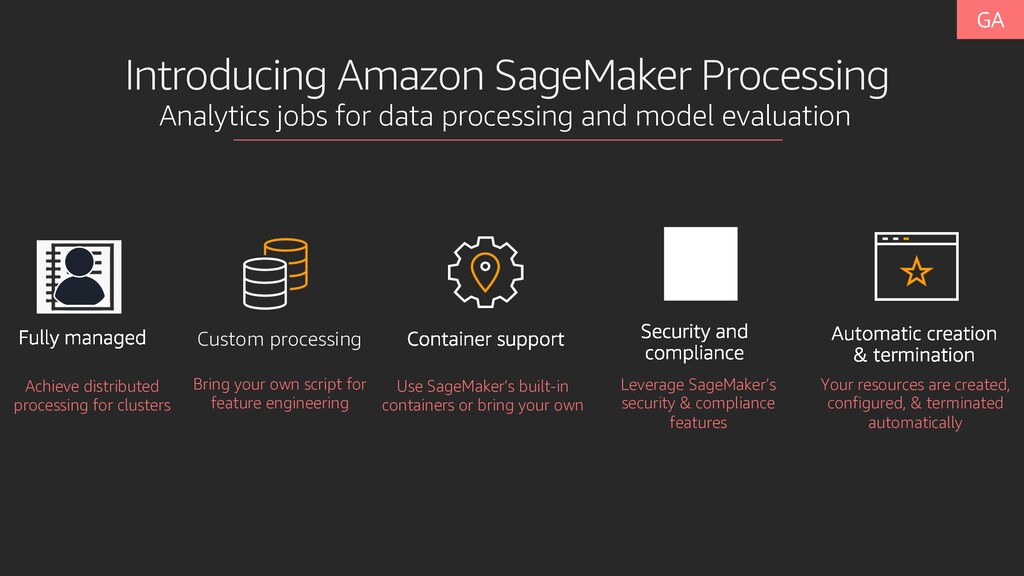
model evaluation Use SageMaker’s built-in containers or bring your own Bring your own script for feature engineering Custom processing Achieve distributed processing for clusters Your resources are created, configured, & terminated automatically Leverage SageMaker’s security & compliance features
best results Flexibility with Python SDK & APIs Iterate quickly Track parameters & metrics across experiments & users Organize experiments Organize by teams, goals, & hypotheses Visualize & compare between experiments Log custom metrics & track models using APIs Iterate & develop high- quality models A system to organize, track, and evaluate training experiments
with many layers Many connections Additional tooling for analysis and debug Extraordinarily difficult to inspect, debug, and profile the ‘black box’ + + =
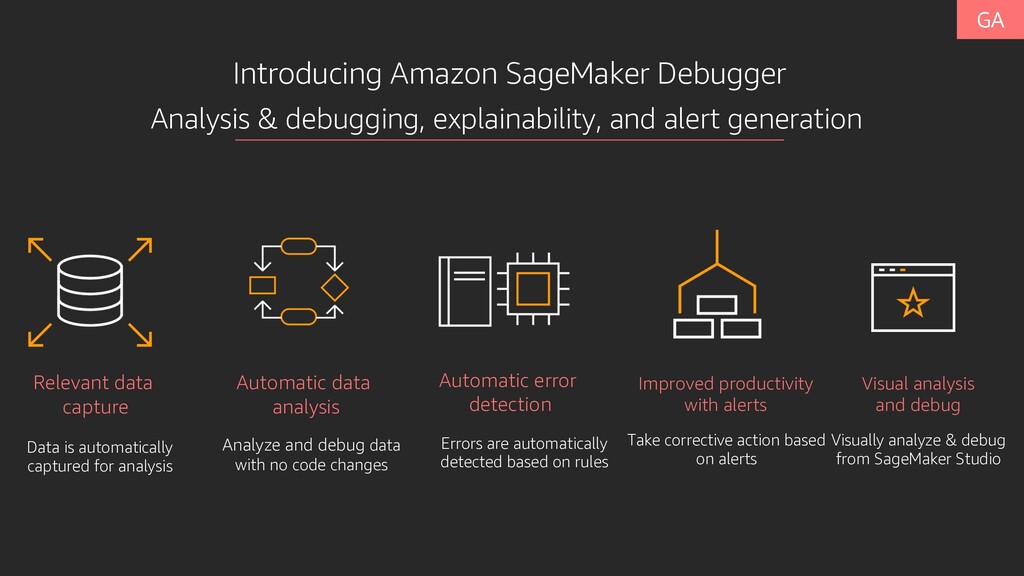
productivity with alerts Visual analysis and debug Introducing Amazon SageMaker Debugger Analyze and debug data with no code changes Data is automatically captured for analysis Errors are automatically detected based on rules Take corrective action based on alerts Visually analyze & debug from SageMaker Studio Analysis & debugging, explainability, and alert generation
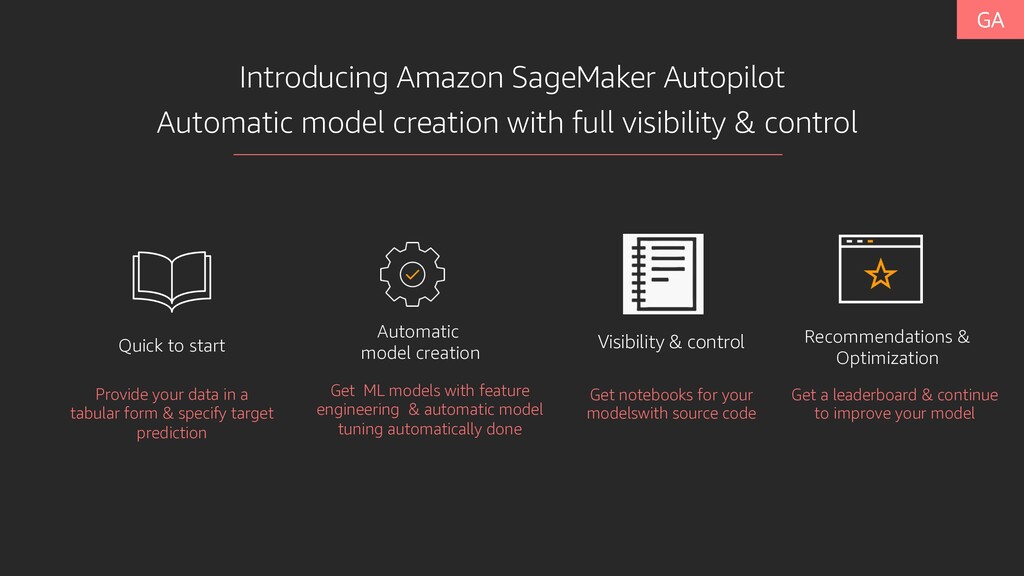
in a tabular form & specify target prediction Automatic model creation Get ML models with feature engineering & automatic model tuning automatically done Visibility & control Get notebooks for your modelswith source code Automatic model creation with full visibility & control Recommendations & Optimization Get a leaderboard & continue to improve your model
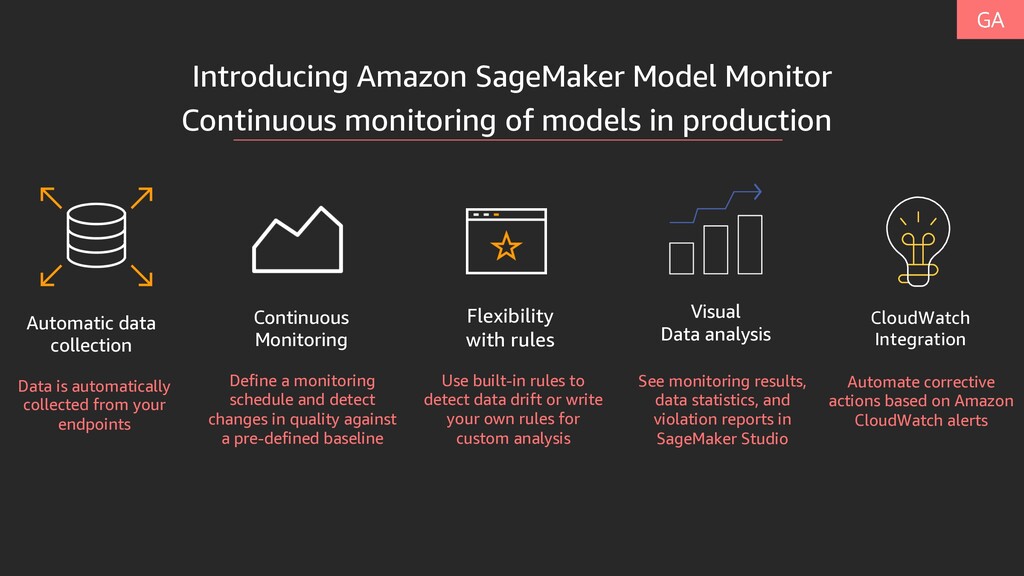
CloudWatch Integration Data is automatically collected from your endpoints Automate corrective actions based on Amazon CloudWatch alerts Continuous monitoring of models in production Visual Data analysis Define a monitoring schedule and detect changes in quality against a pre-defined baseline See monitoring results, data statistics, and violation reports in SageMaker Studio Flexibility with rules Use built-in rules to detect data drift or write your own rules for custom analysis
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}