DevOpsDaysMoscow, 07-12-2019, Сергей Пузырев
Моя команда работает над внутренним сервисом распределенных очередей в Facebook. Мы предоставляем низкоуровневый сервис передачи и сохранения сообщений для множества пользователей внутри Facebook по всей планете.
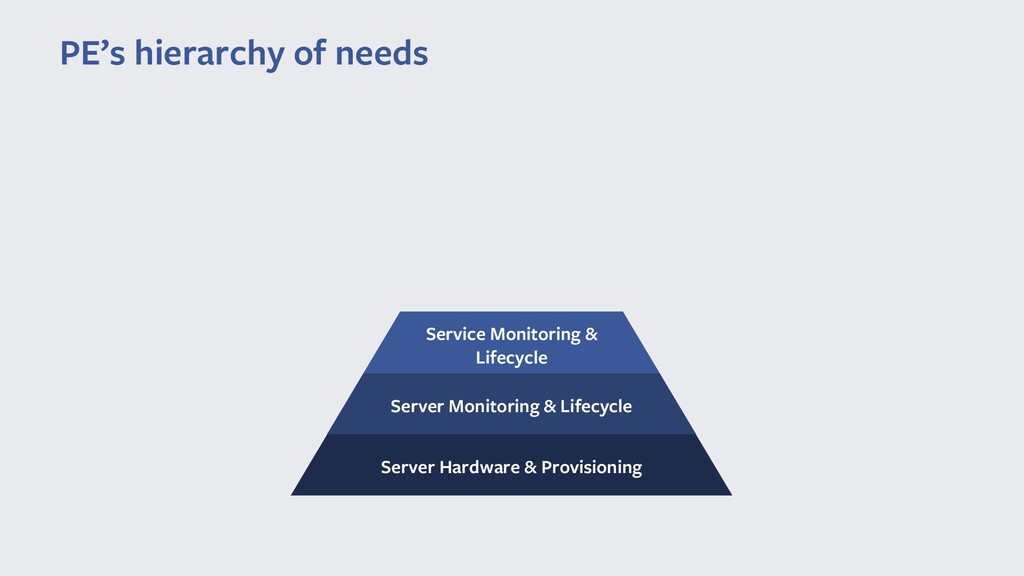
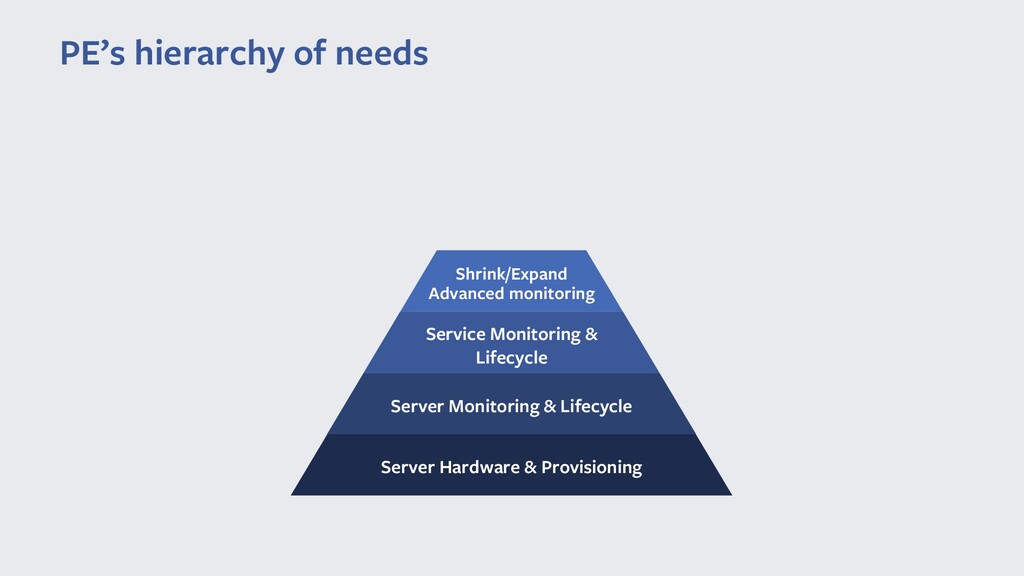
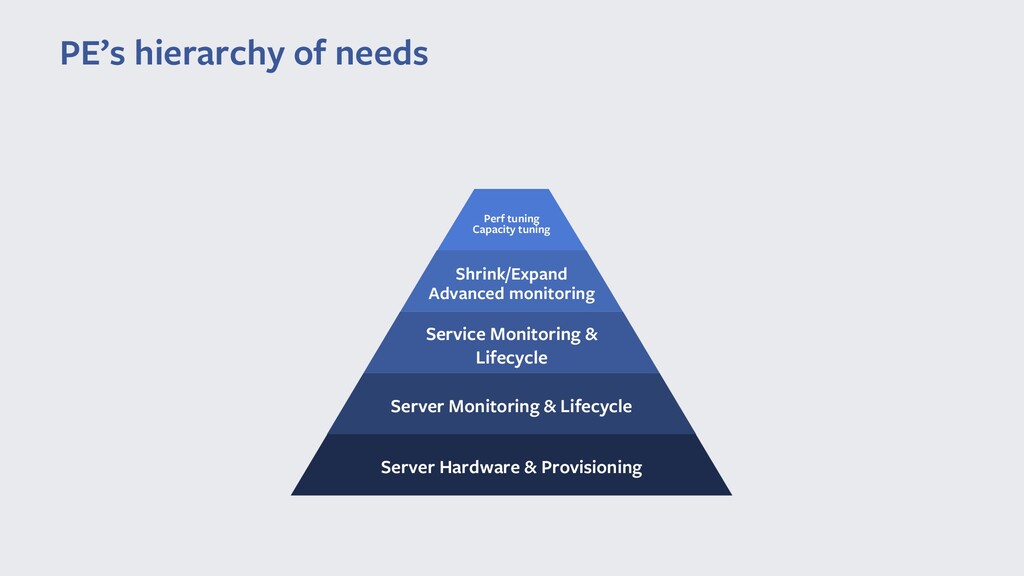
Команда Production Engineer'ов обеспечивает весь жизненный цикл нашего сервиса, поддерживает всю автоматизацию, необходимую для сервиса и изредка тушим пожары.
Я расскажу, как мы работаем в целом, как устроен процесс работы с командой разработки, какие инструменты мы используем и какого рода автоматизацию мы создаём и поддерживаем.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
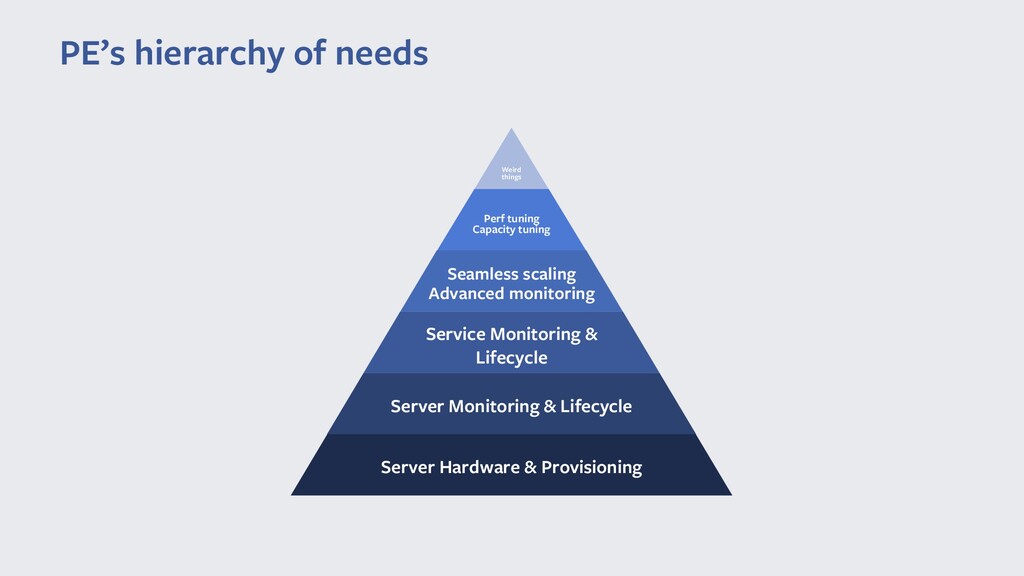{kind=link}
{kind=link}
{kind=link}
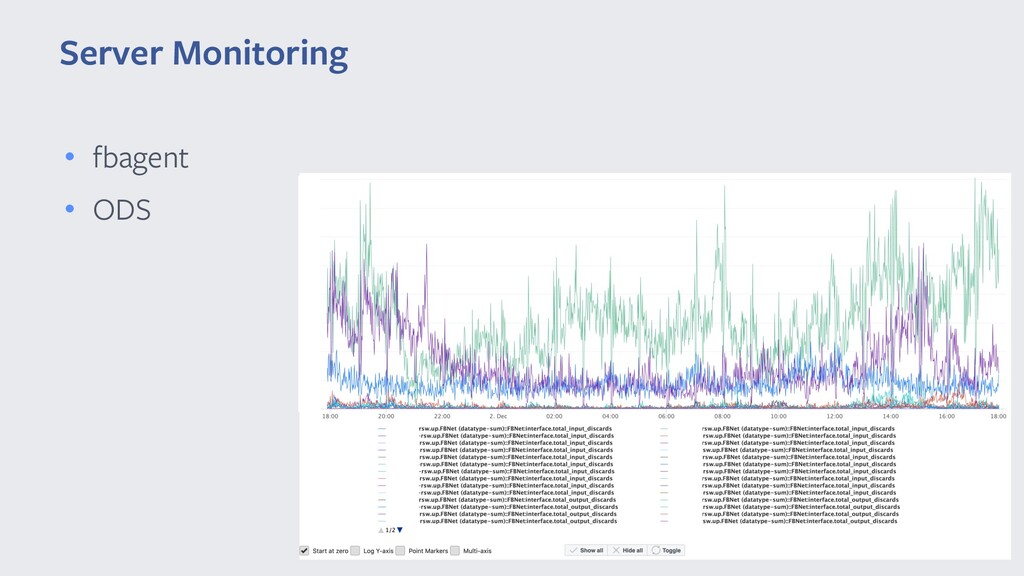{kind=link}
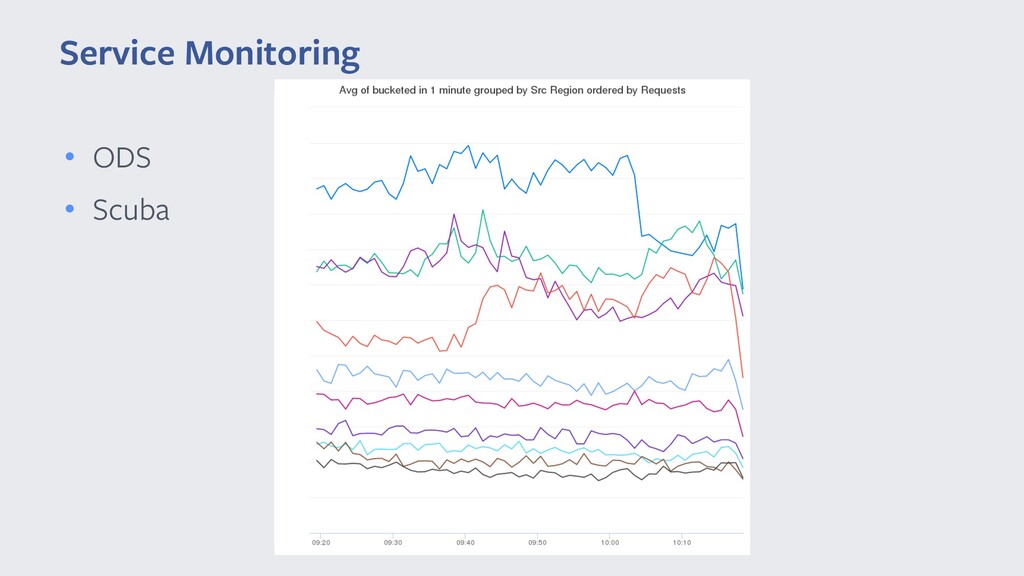{kind=link}
{kind=link}
{kind=link}
{kind=link}
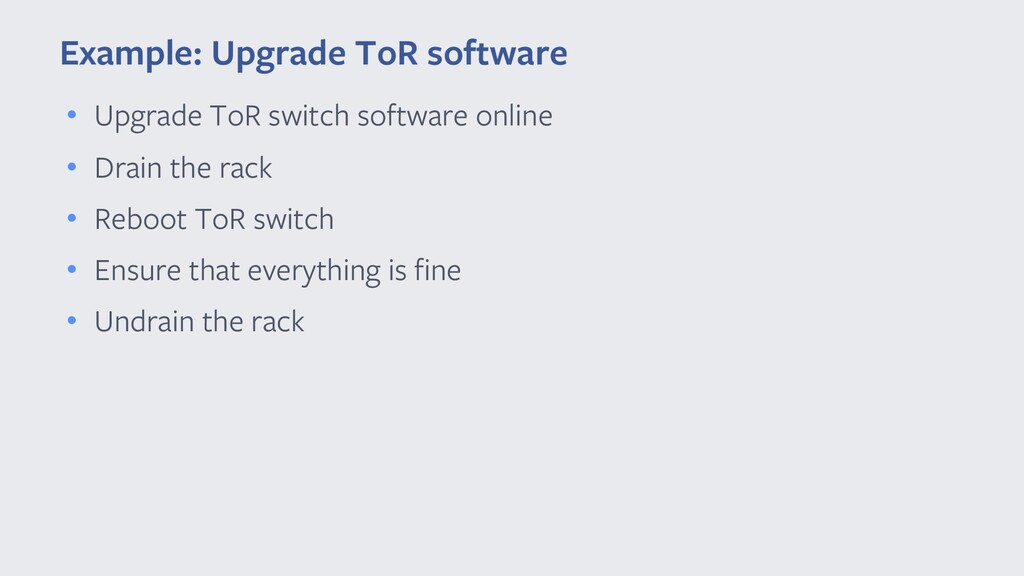{kind=link}
{kind=link}
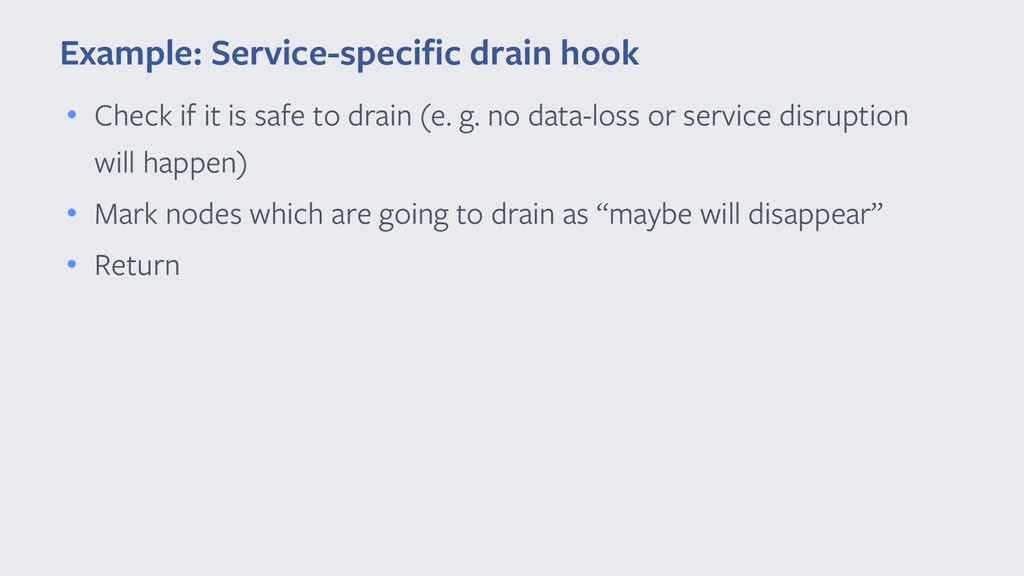{kind=link}
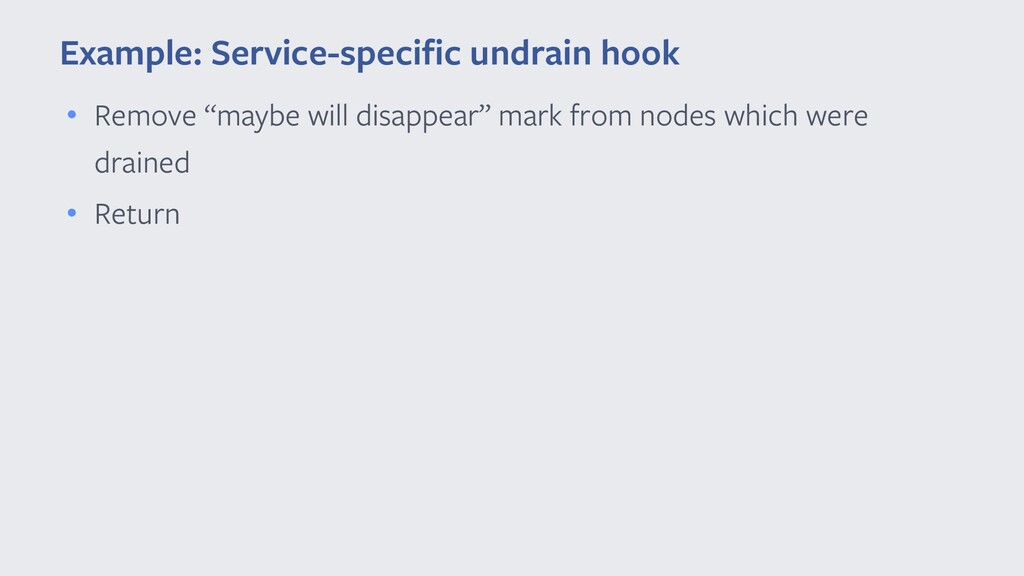{kind=link}
{kind=link}
{kind=link}
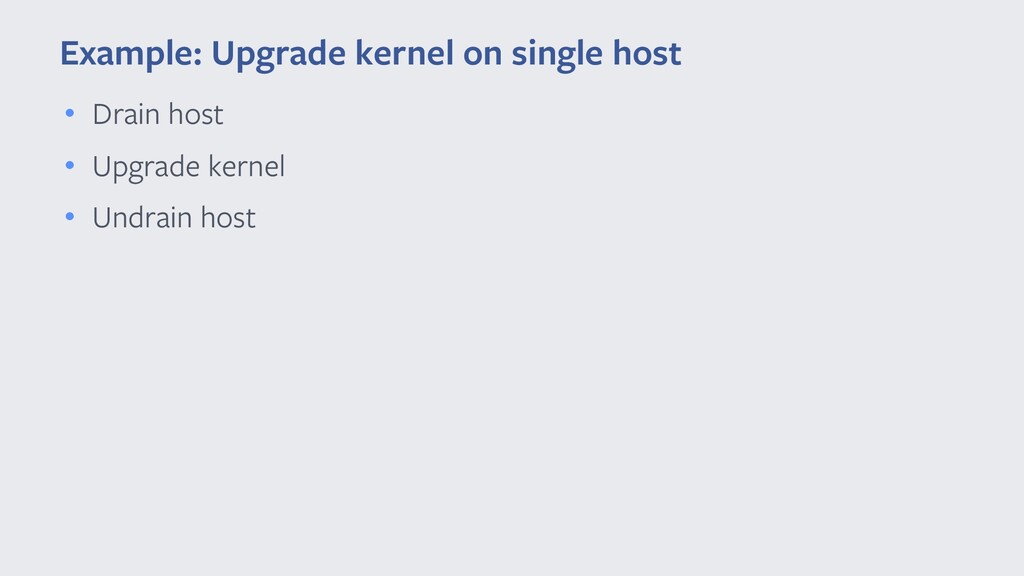{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}