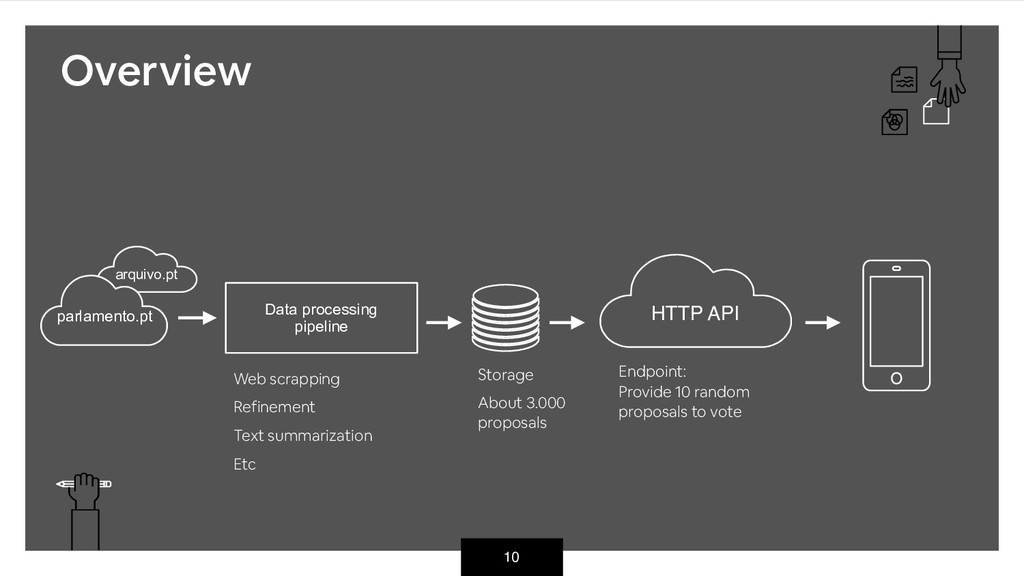
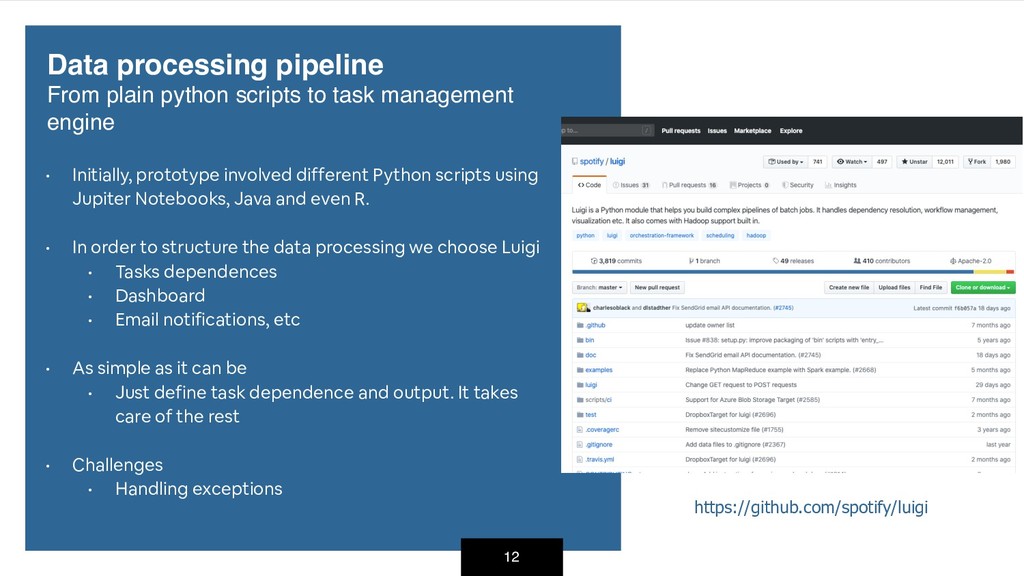
Notebooks, Java and even R. • In order to structure the data processing we choose Luigi • Tasks dependences • Dashboard • Email notifications, etc • As simple as it can be • Just define task dependence and output. It takes care of the rest • Challenges • Handling exceptions Data processing pipeline From plain python scripts to task management engine https://github.com/spotify/luigi
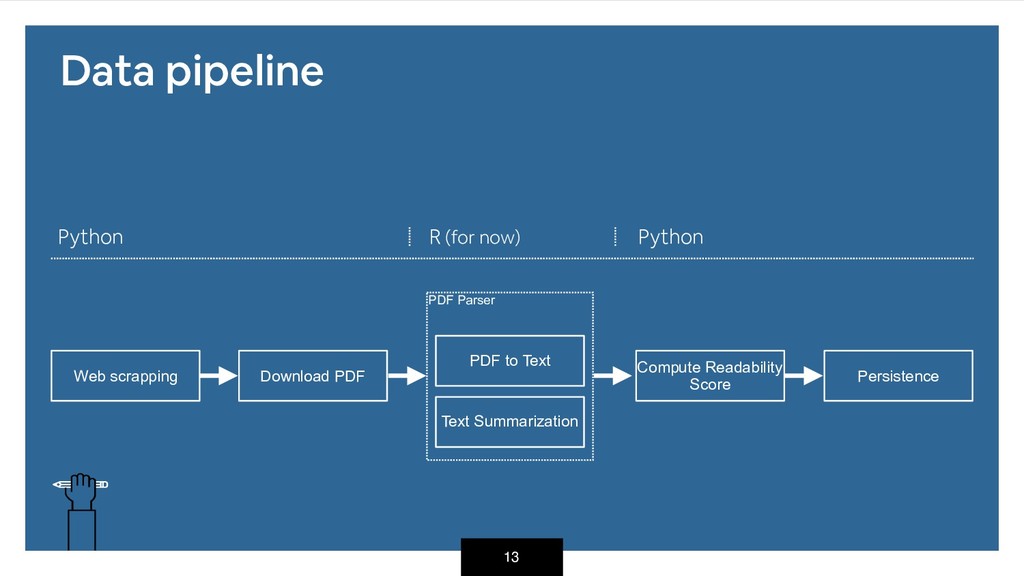
each step as simple as possible • Atomic tasks • Easier to test • If one task fails you can start again from the last one • Keep track of changes • Don’t update data, keep it. • Save every change you made in the data • It also facilitates recovery at any point in the pipeline • Fail gracefully • Handle exceptions properly so it doesn’t break the entire workflow. It can be tricky sometimes, specially with wrappers and loops. • It pays off when things get complicated 14
list of random proposals to vote • It should be • Easy to deploy • Easy to monitor • Cheap to scale • $$$ comes from our pockets meuParlamento API HTTP API JSON
(Cloud) • Pros • Data updates directly from pipeline • Cons • Bottleneck: Heroku’s free tier • Slow processing units, no load balance, etc • Expensive to scale if necessary • Too much trouble for such a simple endpoint 17 Backend API using Flask Flask-based web API
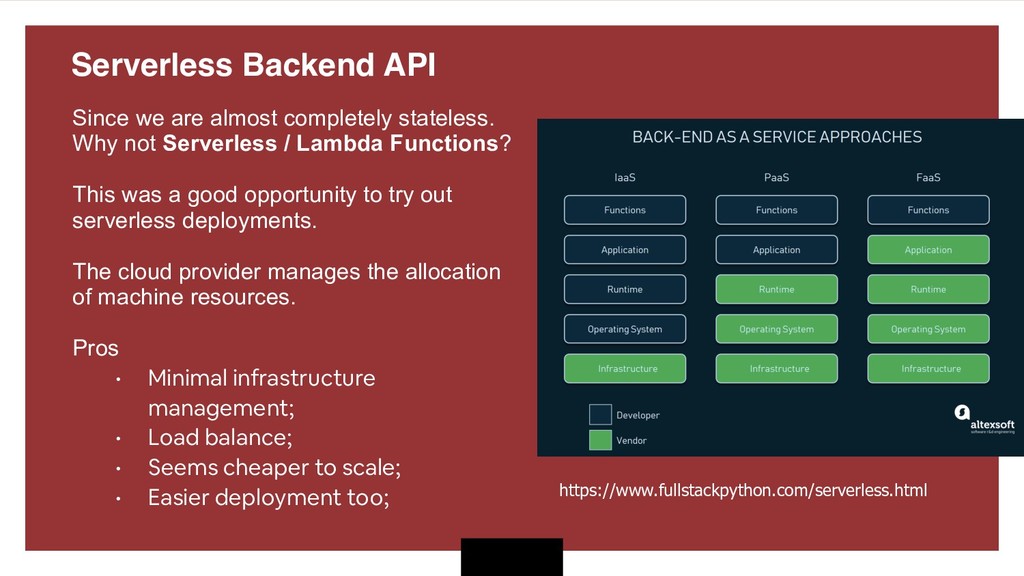
Why not Serverless / Lambda Functions? This was a good opportunity to try out serverless deployments. The cloud provider manages the allocation of machine resources. Pros • Minimal infrastructure management; • Load balance; • Seems cheaper to scale; • Easier deployment too; https://www.fullstackpython.com/serverless.html
• Zappa • python-lambda • Chalice We choose Chalice Pros • Very similar to Flask • Painless migration from previous Flask code • Provided by Amazon (trust) • Pretty decent documentation • Simple command line interface https://github.com/aws/chalice/ Serverless Backend API
tier is quite generous • Single command deployment; • Support different stages (e.g. dev, test, prod, …) • Support api versioning • Good monitoring tools • Advanced log analytics • Alerts (e.g. latency alerts, etc) • Cons • Package size limitation - (50 Mb) • Vendor lock. Chalice supports AWS only • URL may change in some scenarios. Make sure you use a proxy url in front of it 20 AWS Lambda Serverless Backend API From Flask to serverless with AWS Chalice
now the pool of available connections at the database (MongoDB). • Up to 200 for free tier MongoDB • Solution • Query requirements are actually really simple • Remove mongodb and use simpler in memory data structure? • Idea • Pipeline • Save proposals file at Amazon S3 bucket • Backend • Load proposals file from S3 bucket Open question Remove mongodb? AWS Lambda
Improve tests coverage, documentation and website • Pipeline repository is still not open. But it will be soon. Next steps http://github.com/meuparlamento
with notifications • Improve User Interface • Support different public institutions (e.g. European Parliament, city council, etc) Next steps (features) http://github.com/meuparlamento
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}