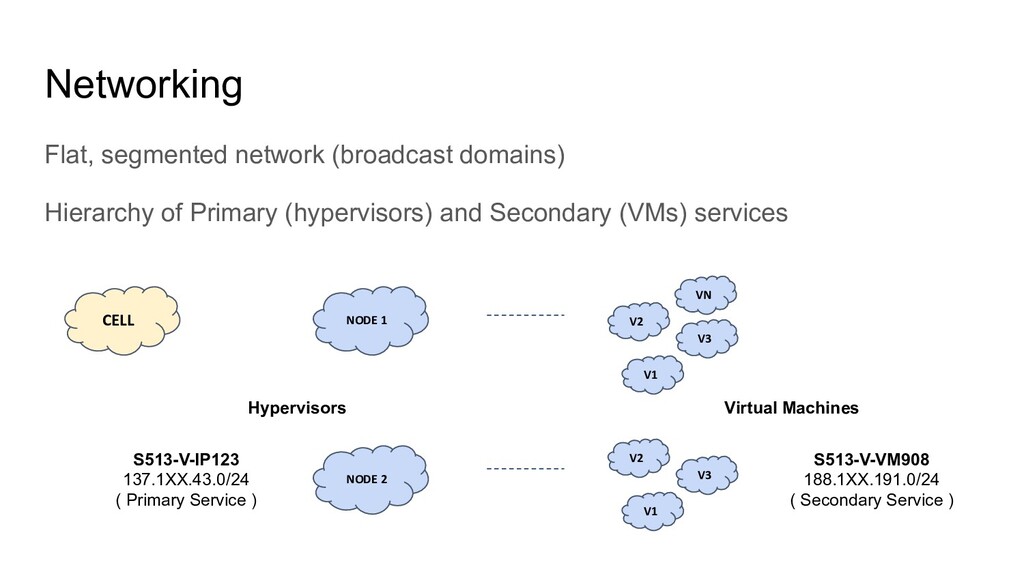
Network, DC, … Batch Systems and Core Physics Services But also campus services: hotel, bike service, wifi, … Common for teams to work on 2 weeks sprints, even for operations Rota system per team ServiceNow for end user support tickets
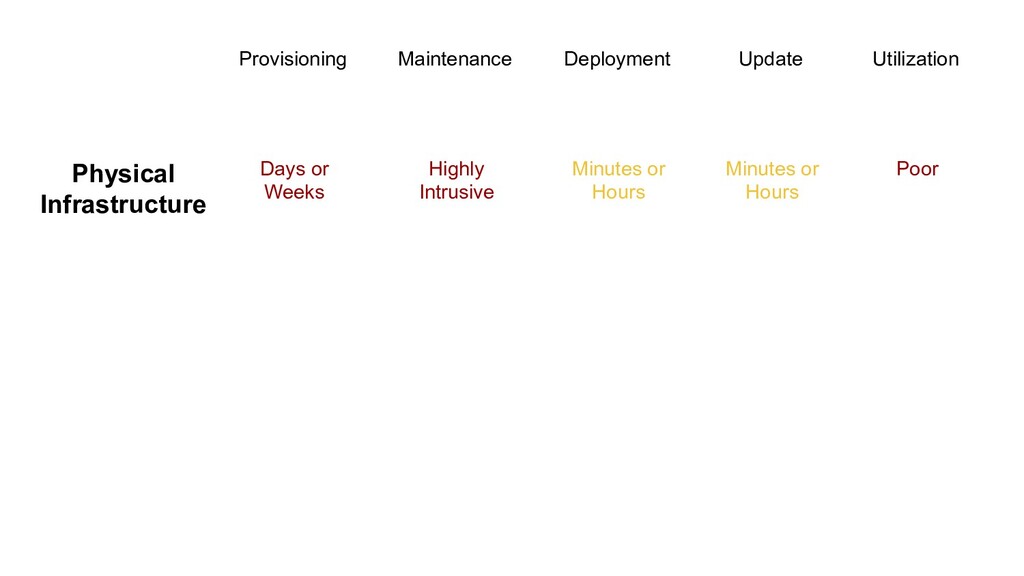
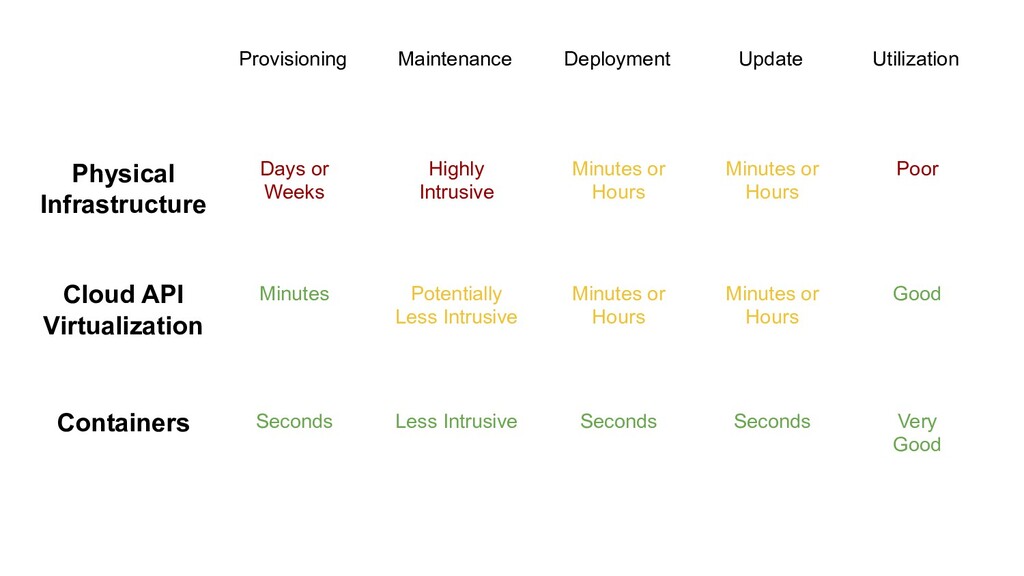
Hours Minutes or Hours Utilization Poor Maintenance Highly Intrusive Cloud API Virtualization Minutes Minutes or Hours Minutes or Hours Good Potentially Less Intrusive
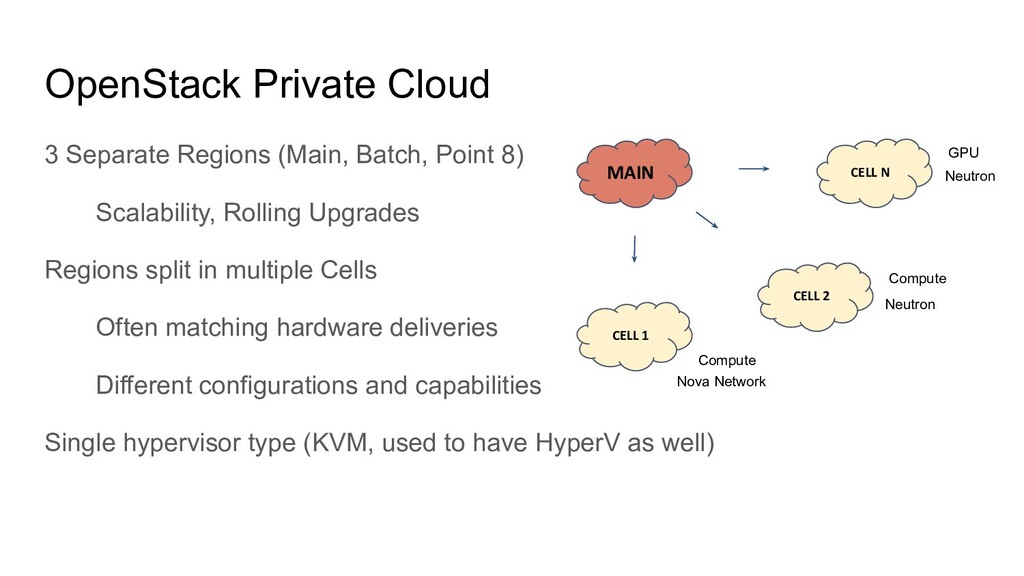
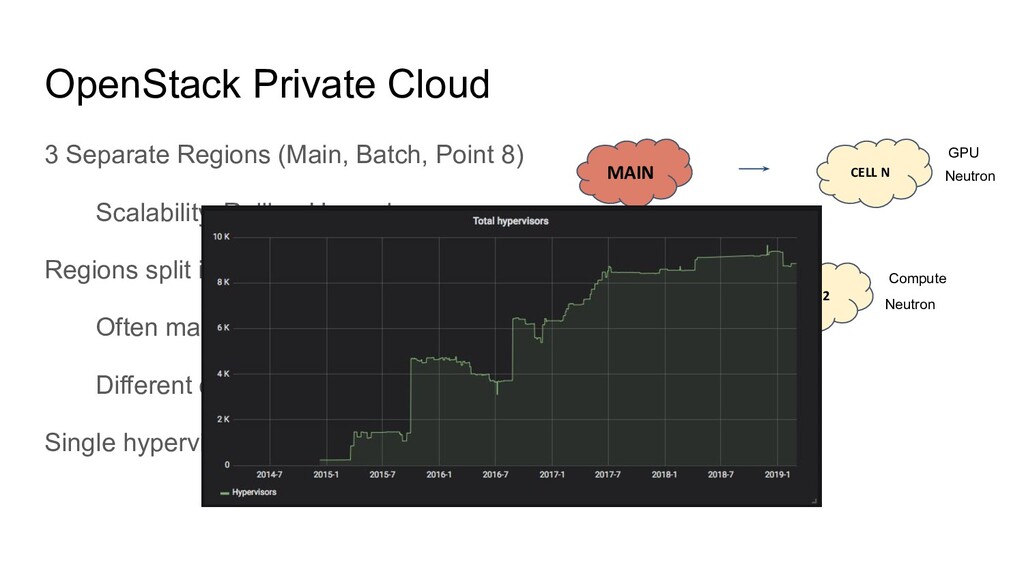
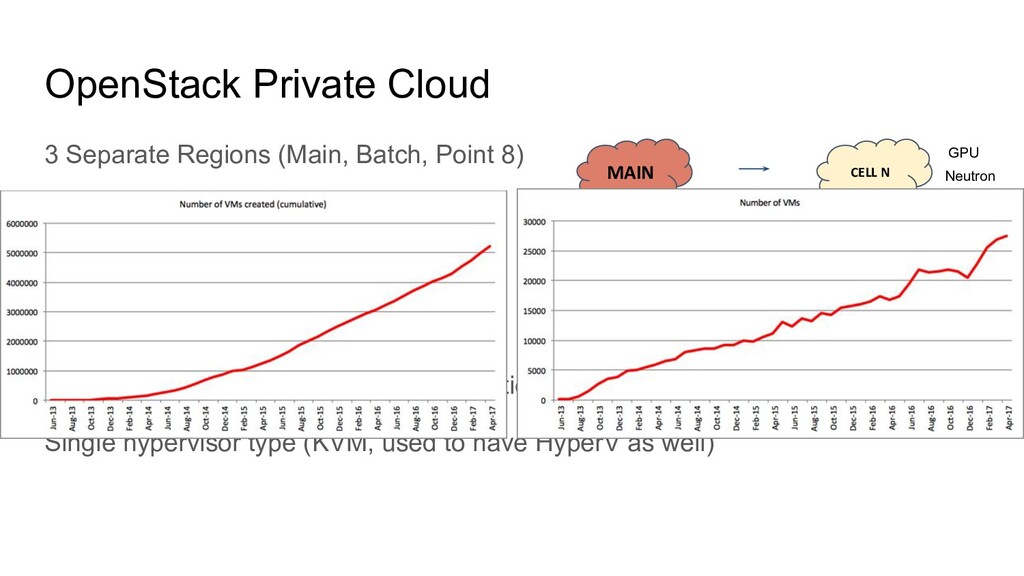
Scalability, Rolling Upgrades Regions split in multiple Cells Often matching hardware deliveries Different configurations and capabilities Single hypervisor type (KVM, used to have HyperV as well) CELL 1 MAIN CELL 2 CELL N Compute GPU Compute Nova Network Neutron Neutron
Scalability, Rolling Upgrades, Regions split in multiple Cells Often matching hardware deliveries Different configurations and capabilities Single hypervisor type (KVM, used to have HyperV as well) CELL 1 MAIN CELL 2 CELL N Compute GPU Compute Nova Network Neutron Neutron
Scalability, Rolling Upgrades, Regions split in multiple Cells Often matching hardware deliveries Different configurations and capabilities Single hypervisor type (KVM, used to have HyperV as well) CELL 1 MAIN CELL 2 CELL N Compute GPU Compute Nova Network Neutron Neutron
components Including control plane running on VMs Same is true for most CERN services Workflows for all sorts of tasks Onboarding new users, project creation, quota updates, special capabilities Overcommit, Pre-emptible instances, Backfilling workloads
Hours Minutes or Hours Utilization Poor Maintenance Highly Intrusive Cloud API Virtualization Minutes Minutes or Hours Minutes or Hours Good Potentially Less Intrusive Containers Seconds Seconds Seconds Very Good Less Intrusive
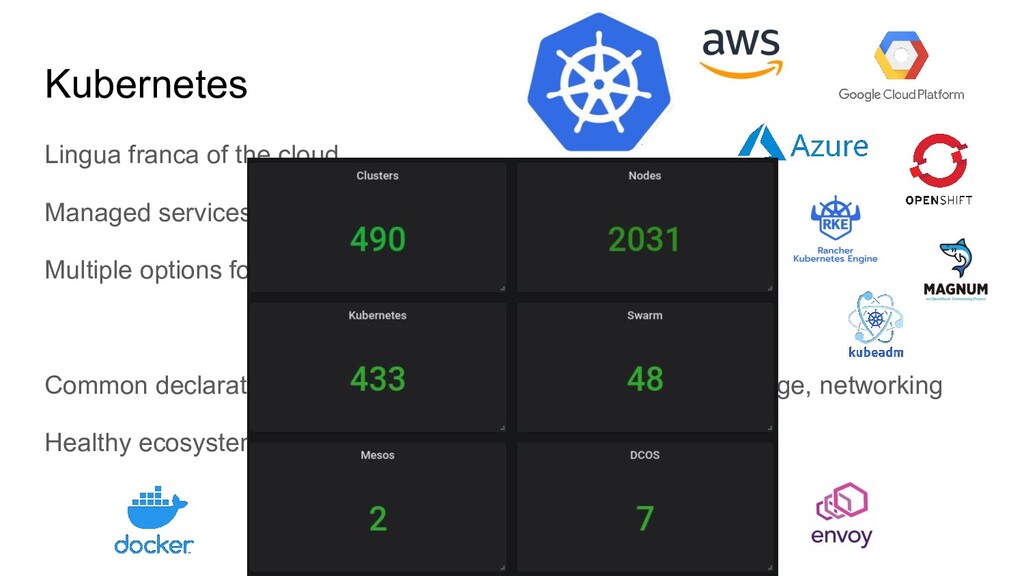
major public clouds Multiple options for on-premise or self-managed deployments Common declarative API for basic infrastructure : compute, storage, networking Healthy ecosystem of tools offering extended functionality Kubernetes
major public clouds Multiple options for on-premise or self-managed deployments Common declarative API for basic infrastructure : compute, storage, networking Healthy ecosystem of tools offering extended functionality Kubernetes
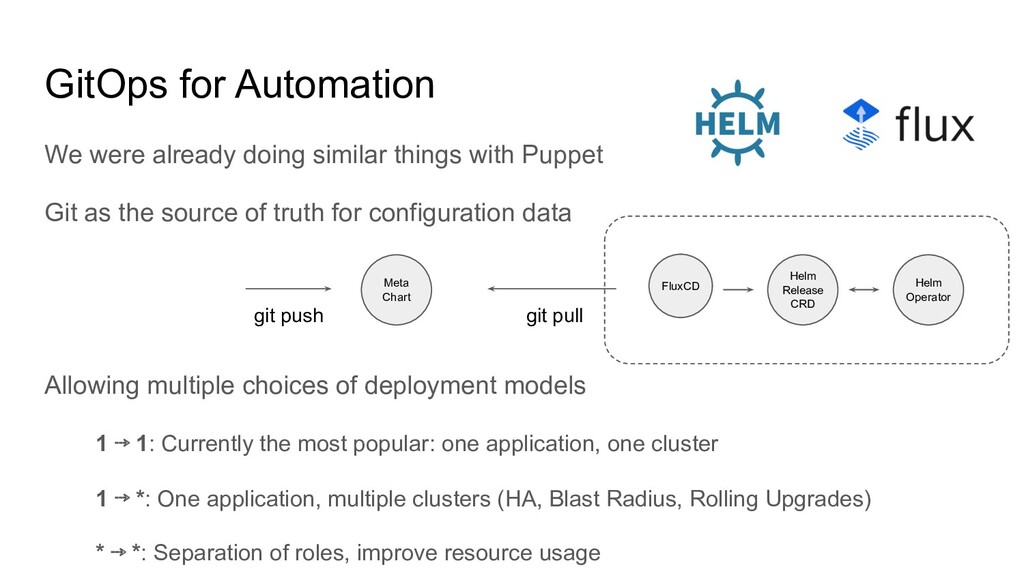
Puppet Git as the source of truth for configuration data Allowing multiple choices of deployment models 1 ⇢ 1: Currently the most popular: one application, one cluster 1 ⇢ *: One application, multiple clusters (HA, Blast Radius, Rolling Upgrades) * ⇢ *: Separation of roles, improve resource usage Meta Chart git push FluxCD git pull Helm Release CRD Helm Operator
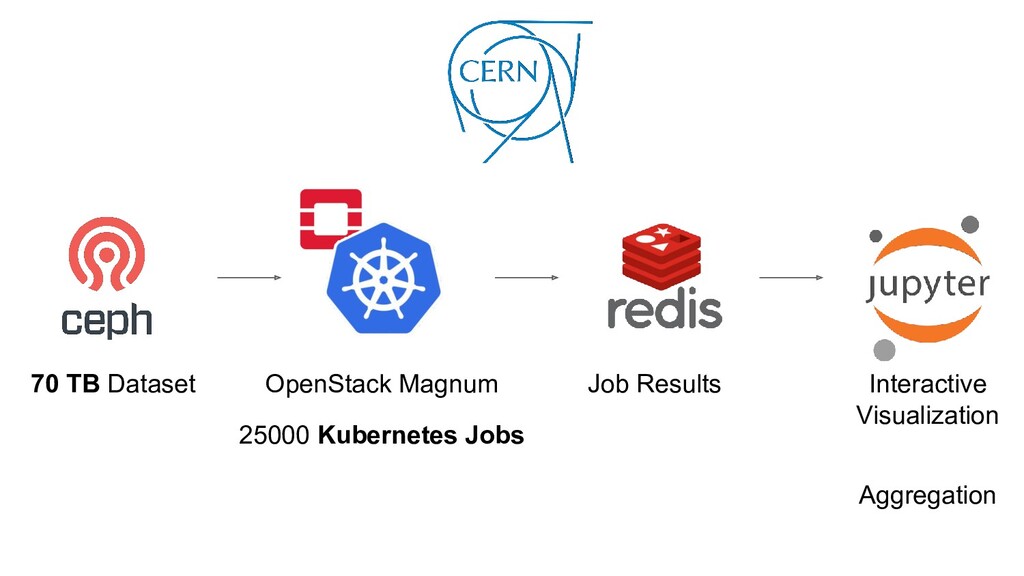
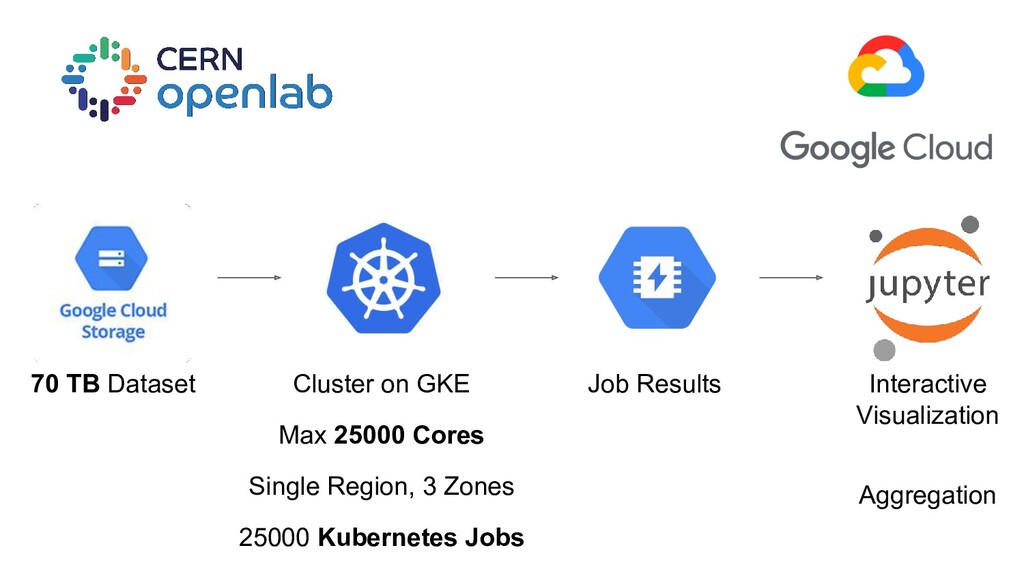
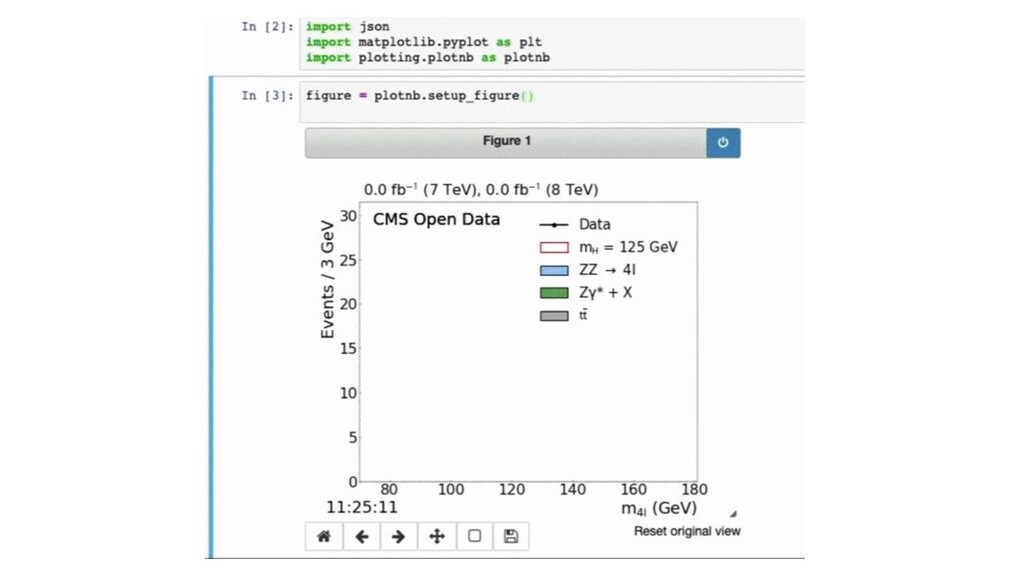
min 4 min 90 sec Kubernetes More than just infrastructure management Potential to ease scaling out data analysis on-demand Challenge: Re-processing the Higgs analysis in under 10min Processing a dataset of ~70TB of data split in ~25000 files
Collider x7 collisions per second, x10 Data and Computing Machine Learning Considered for fast simulation, detector triggers, anomaly detection, … Accommodate accelerators and scale this new type of workload GPUs, TPUs, IPUs, FPGAs, ...
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Questions ? @ahcorporto [email protected] http://visits.cern/](https://files.speakerdeck.com/presentations/77a815b9bbe8463484786ada1664efb2/slide_37.jpg){kind=link}
{kind=link}